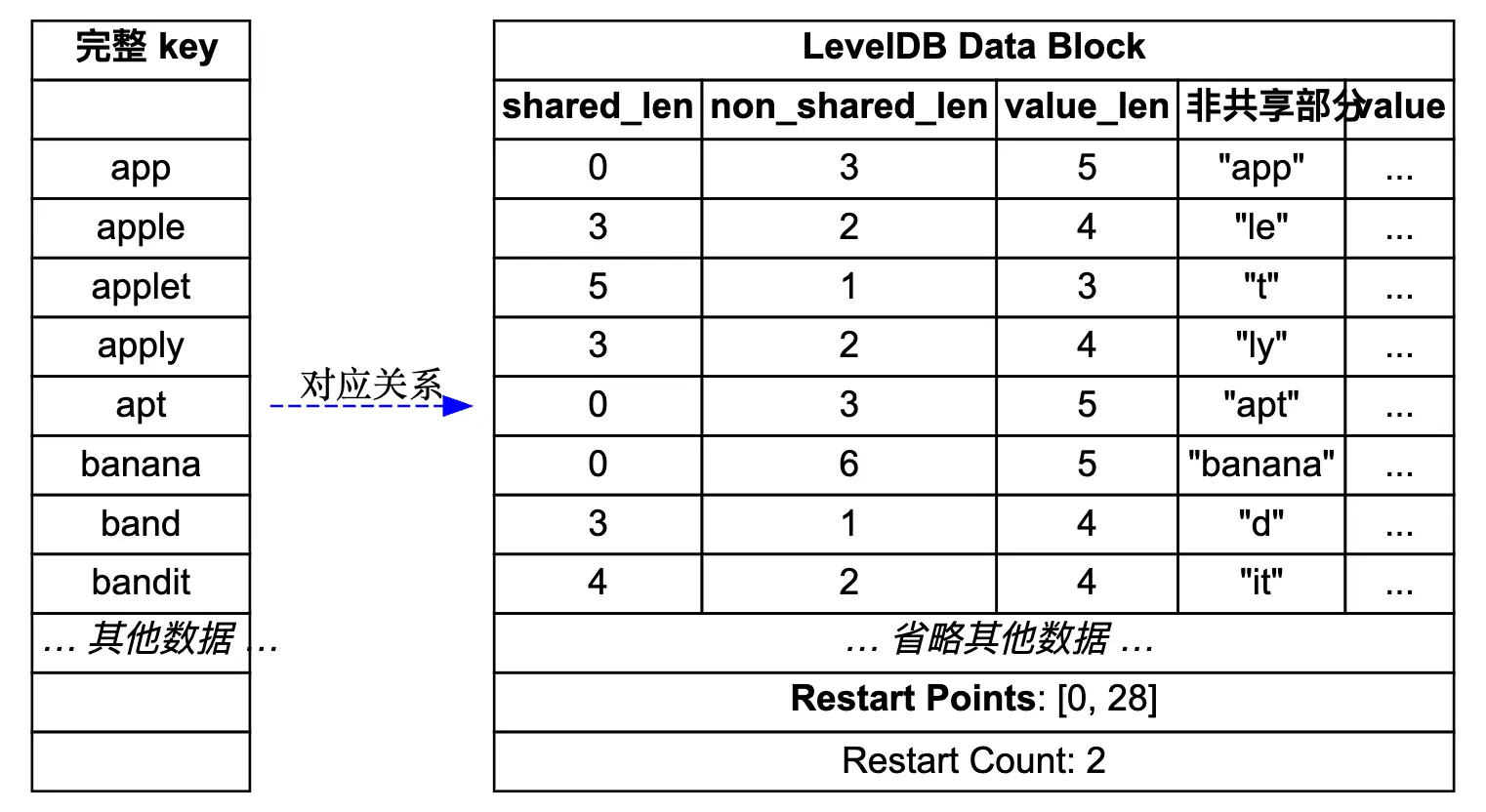
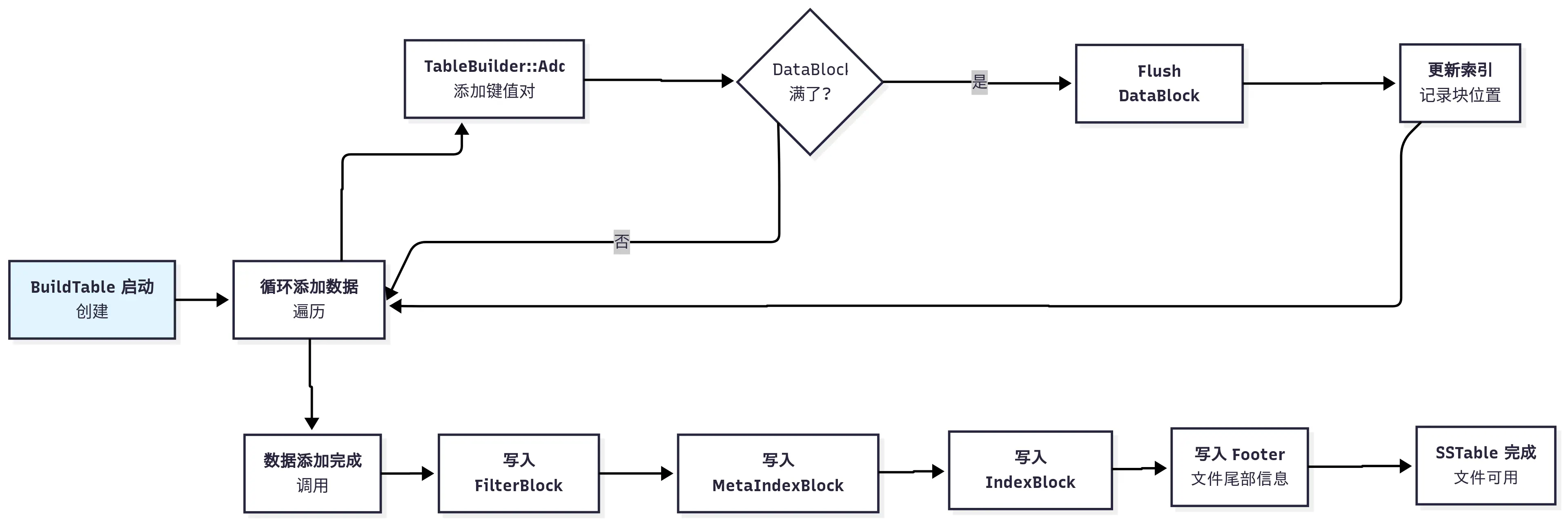
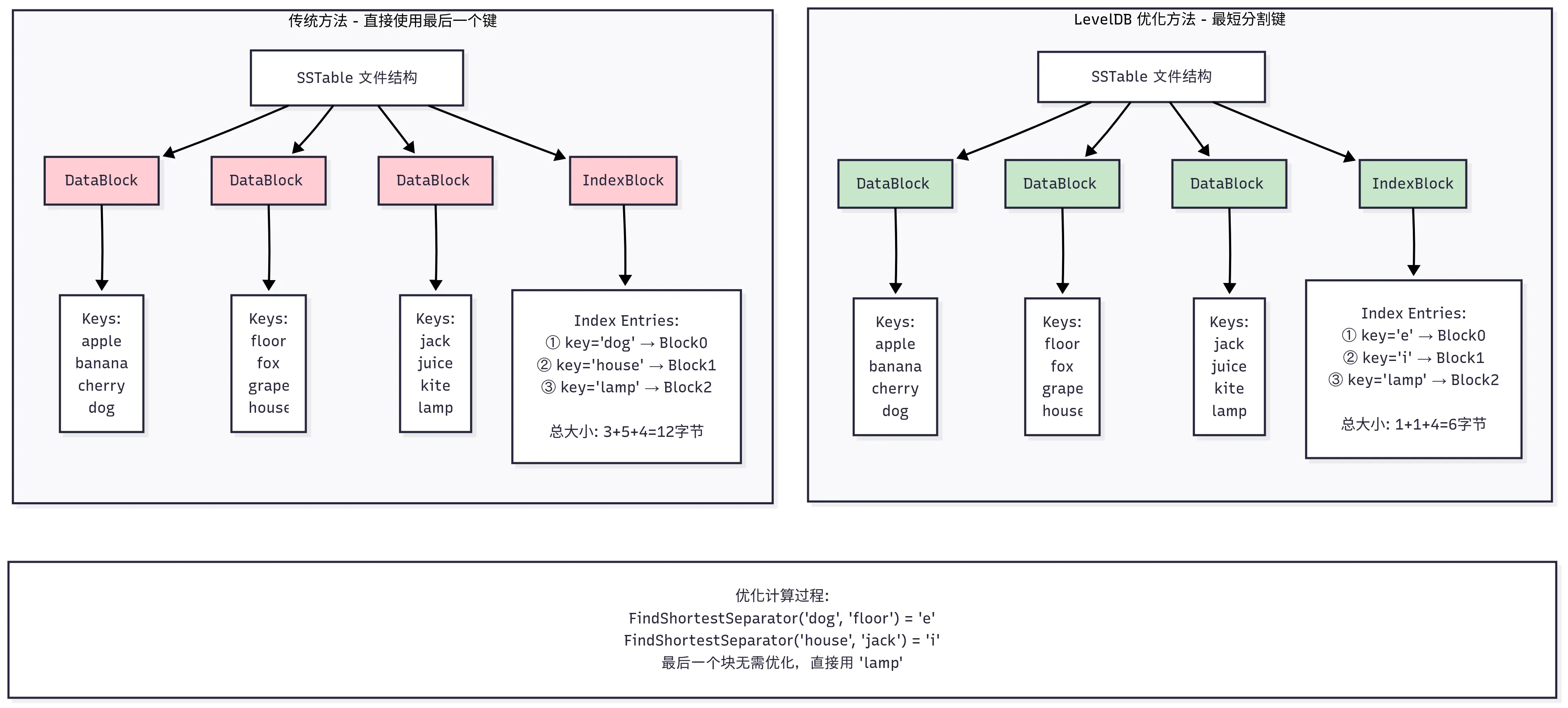
// Number of keys between restart points for delta encoding of keys. // This parameter can be changed dynamically. Most clients should // leave this parameter alone. int block_restart_interval = 16;
// Approximate size of user data packed per block. Note that the // block size specified here corresponds to uncompressed data. The // actual size of the unit read from disk may be smaller if // compression is enabled. This parameter can be changed dynamically. size_t block_size = 4 * 1024;
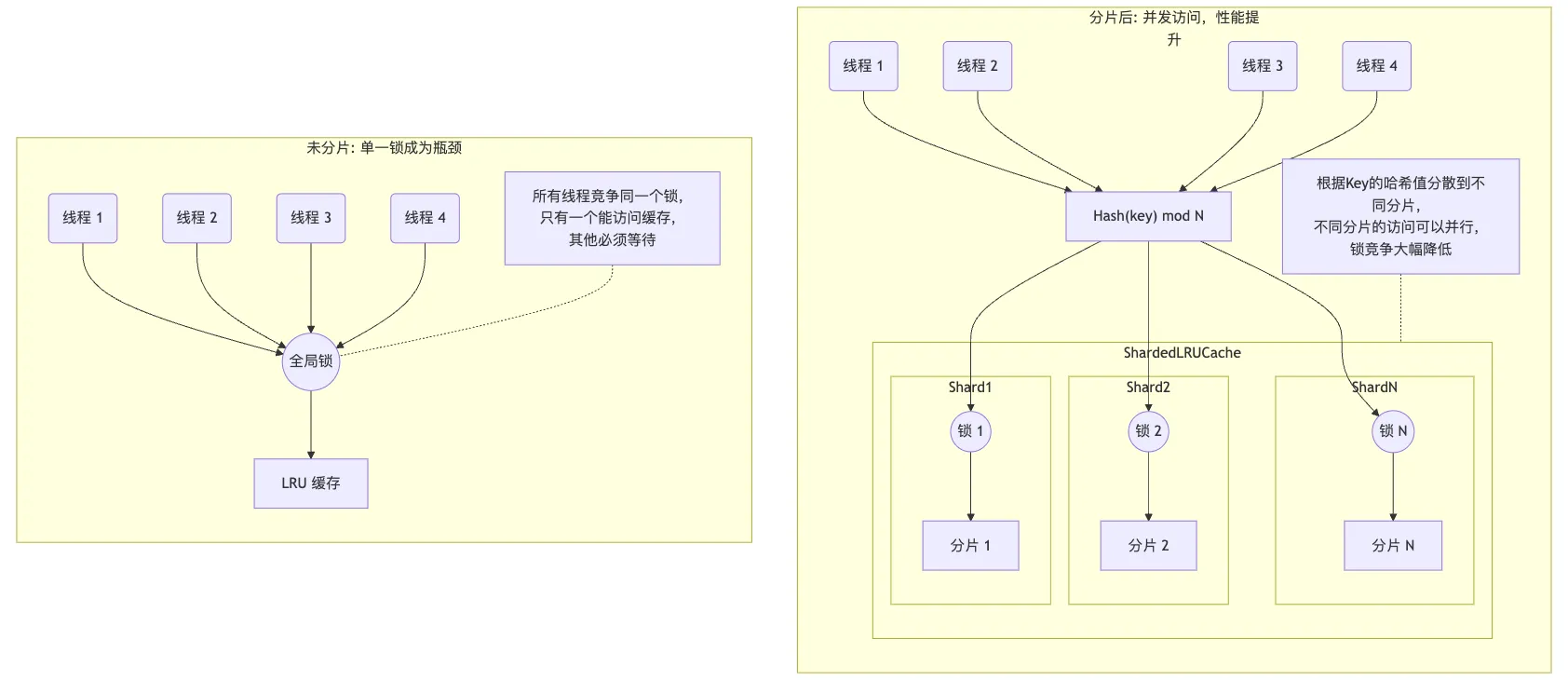
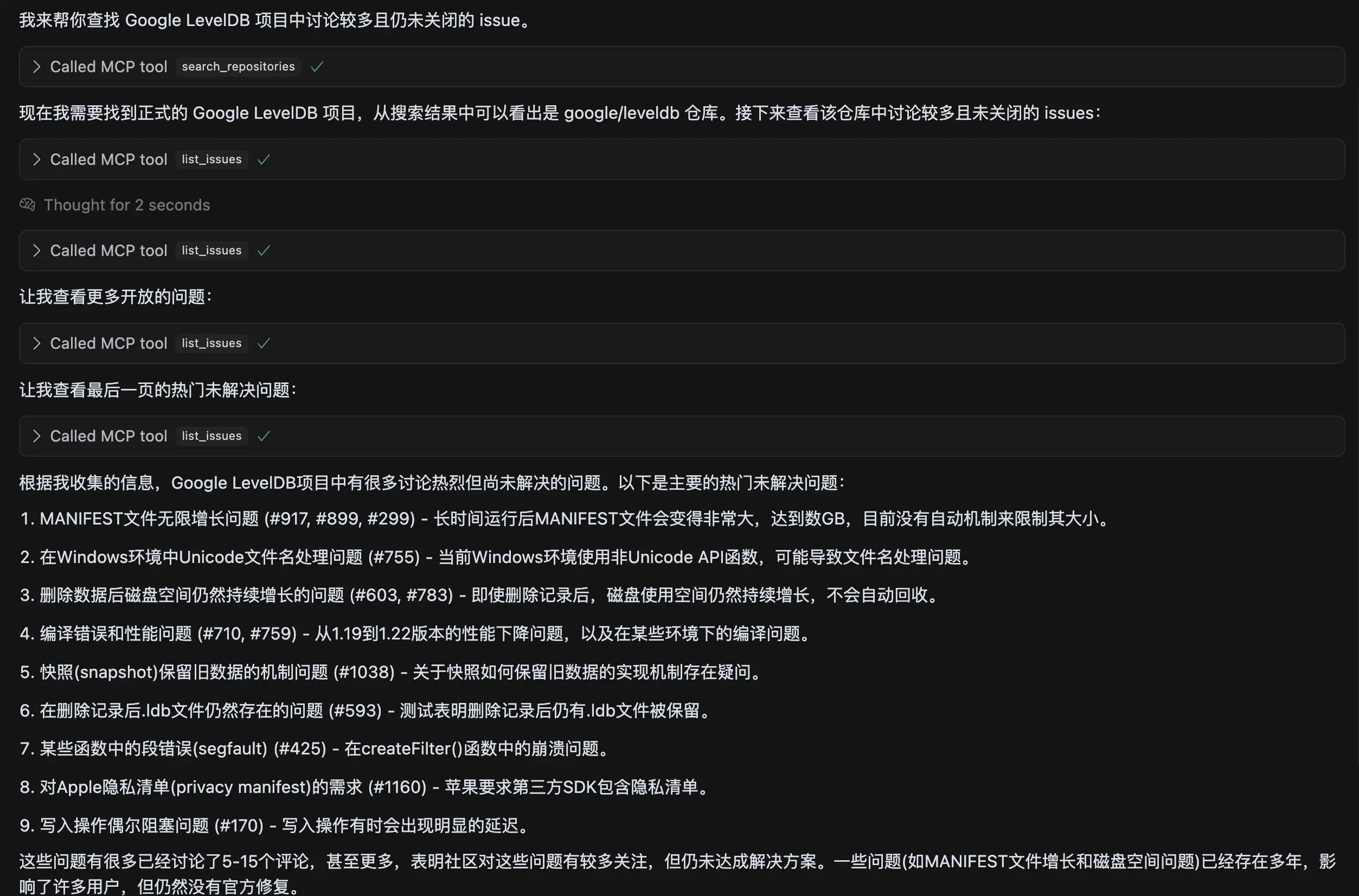
双向链表保证在常数时间内添加和删除节点,哈希表则提供常数时间的数据访问能力。对于 Get 操作,通过哈希表快速定位到链表中的节点,如果存在则将其移动到链表头部,更新为最近使用。对于插入 Insert 操作,如果数据已存在,更新数据并移动到链表头部;如果数据不存在,则在链表头部插入新节点,并在哈希表中添加映射,如果超出容量则移除链表尾部节点,并从哈希表中删除相应的映射。
// The cache keeps two linked lists of items in the cache. All items in the // cache are in one list or the other, and never both. Items still referenced // by clients but erased from the cache are in neither list. The lists are: // - in-use: contains the items currently referenced by clients, in no // particular order. (This list is used for invariant checking. If we // removed the check, elements that would otherwise be on this list could be // left as disconnected singleton lists.) // - LRU: contains the items not currently referenced by clients, in LRU order // Elements are moved between these lists by the Ref() and Unref() methods, // when they detect an element in the cache acquiring or losing its only // external reference.
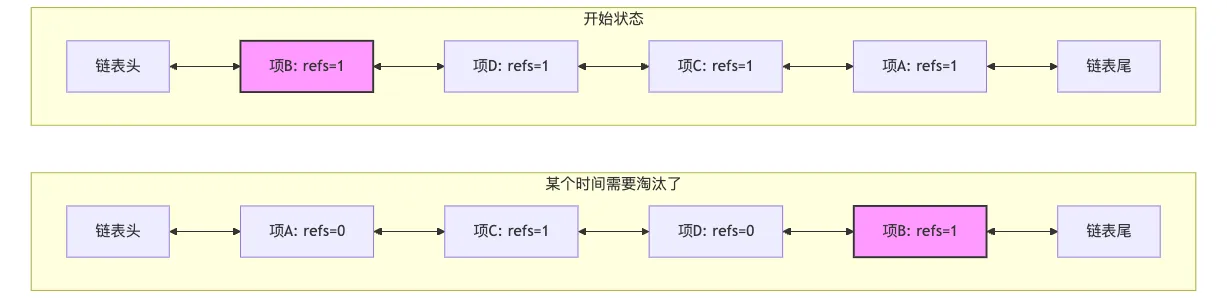
我们依次访问 A, C, D 项,最后访问了 B, B 项被客户端引用(refs=1),位于链表头部,如下图中的开始状态。一段时间内,A、C、D都被访问了,但 B 没有被访问。根据 LRU 规则,A、C、D被移到链表头部。B 虽然仍被引用,但因为长时间未被访问,相对位置逐渐后移。A 和 D 被访问后,很快使用完,这时候没有引用了。当需要淘汰时,从尾部开始,会发现B项(refs=1)不能淘汰,需要跳过继续往前遍历检查其他项。
if (capacity_ > 0) { e->refs++; // for the cache's reference. e->in_cache = true; LRU_Append(&in_use_, e); usage_ += charge; FinishErase(table_.Insert(e)); } else { // don't cache. (capacity_==0 is supported and turns off caching.) // next is read by key() in an assert, so it must be initialized e->next = nullptr; }
// If e != nullptr, finish removing *e from the cache; it has already been // removed from the hash table. Return whether e != nullptr. boolLRUCache::FinishErase(LRUHandle* e){ if (e != nullptr) { assert(e->in_cache); LRU_Remove(e); e->in_cache = false; usage_ -= e->charge; Unref(e); } return e != nullptr; }
// Dummy head of LRU list. // lru.prev is newest entry, lru.next is oldest entry. // Entries have refs==1 and in_cache==true. LRUHandle lru_ GUARDED_BY(mutex_);
// Dummy head of in-use list. // Entries are in use by clients, and have refs >= 2 and in_cache==true. LRUHandle in_use_ GUARDED_BY(mutex_);
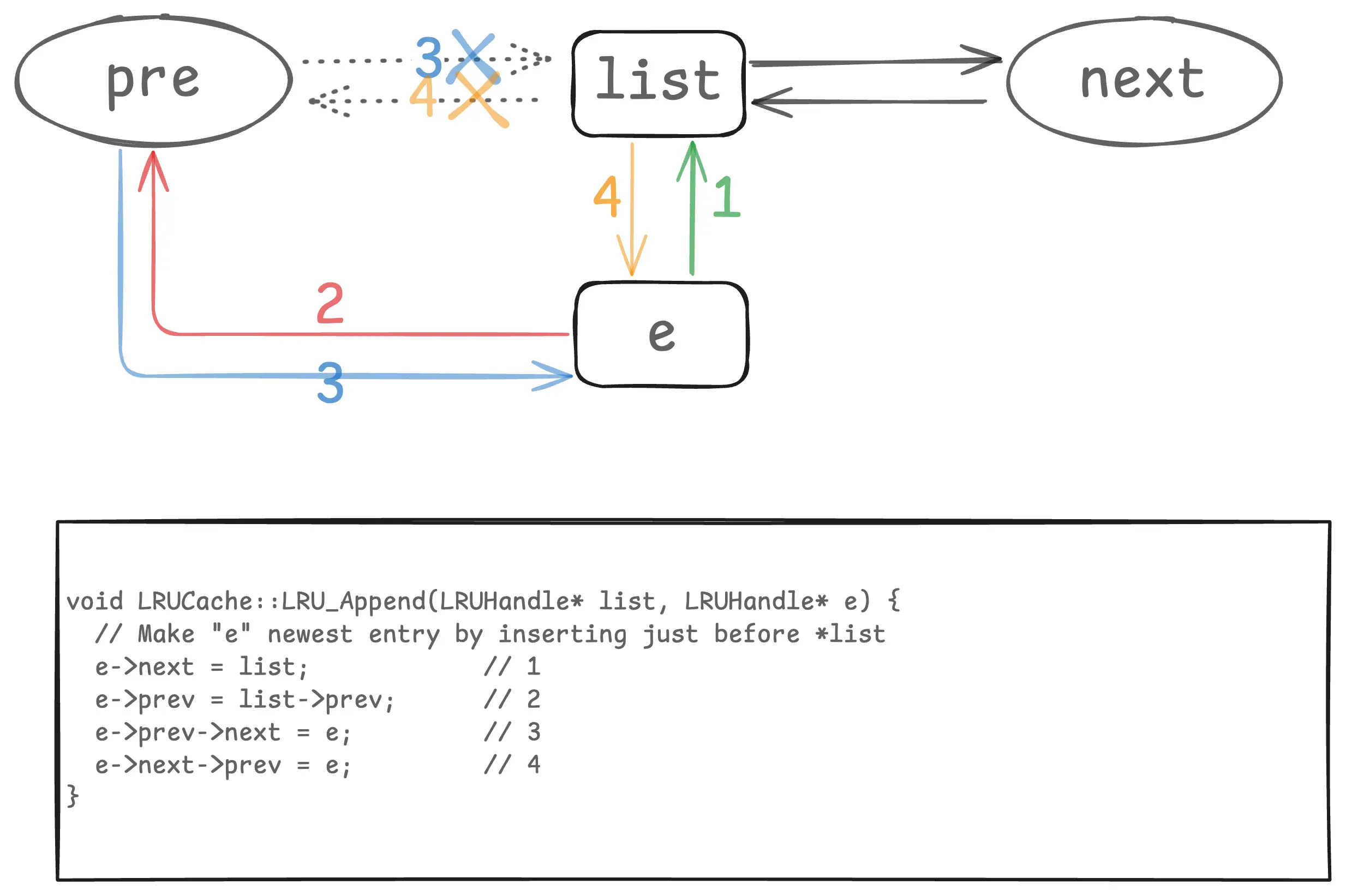
这里 e 是新插入的节点,list 是链表的哑元节点。list 的 pre 和 next 我这里用圆形,表示它可以是自己,比如初始空链表的时候。这里插入是在哑元的前面,所以 list->prev 永远是链表最新的节点,list->next 永远是链表最老的节点。这种链表操作,最好画个图,就一目了然了。
// Return a new numeric id. May be used by multiple clients who are // sharing the same cache to partition the key space. Typically the // client will allocate a new id at startup and prepend the id to // its cache keys. virtualuint64_tNewId()= 0;
voidMemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value){ // Format of an entry is concatenation of: // key_size : varint32 of internal_key.size() // key bytes : char[internal_key.size()] // tag : uint64((sequence << 8) | type) // value_size : varint32 of value.size() // value bytes : char[value.size()] //...
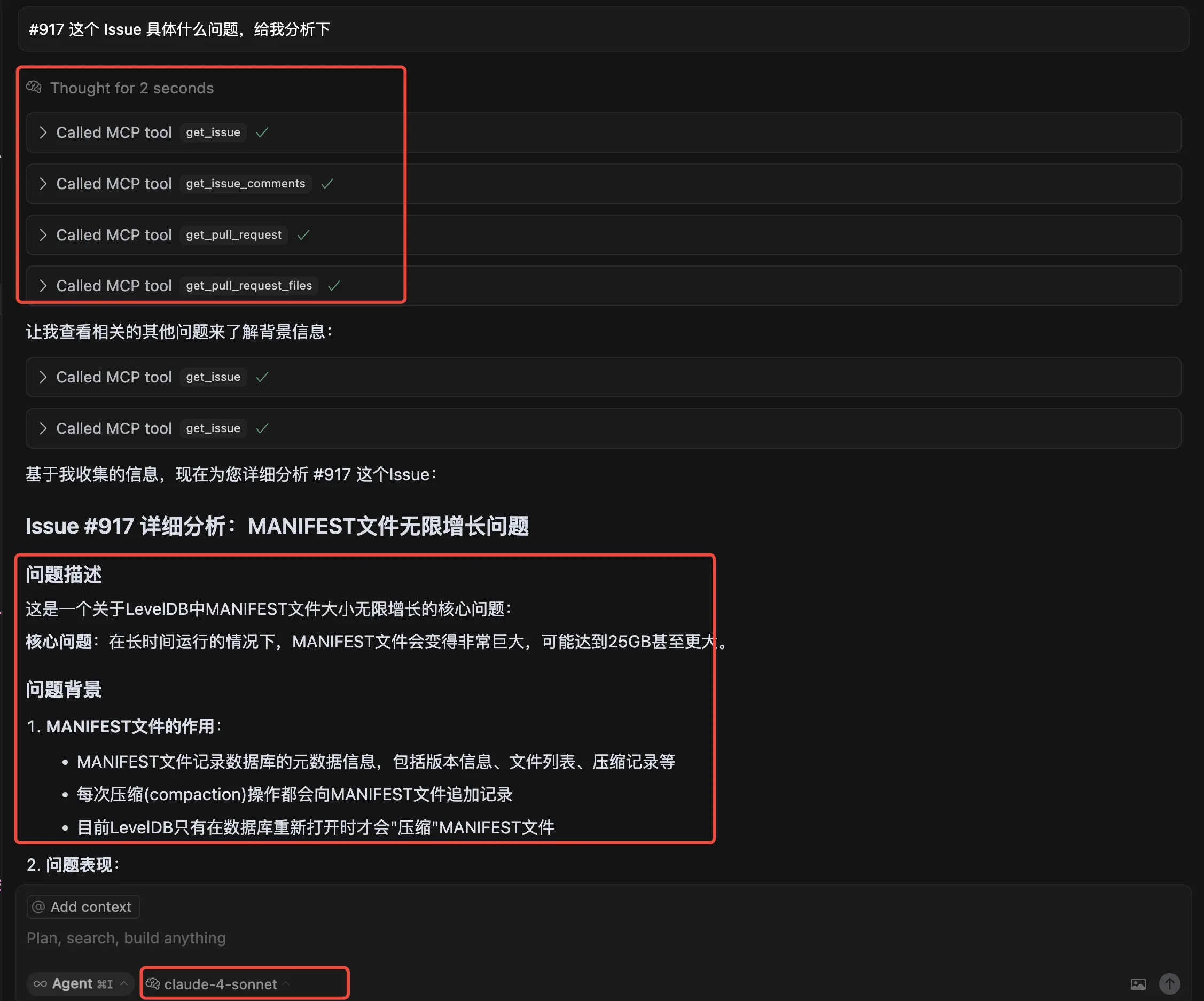
这里的注释十分清楚,Memtable 中存储了格式化后的键值对,先是 internal key 的长度,然后是 internal key 字节串(就是下面的 tag 部分,包含 User Key + Sequence Number + Value Type),接着是 value 的长度,然后是 value 字节串。整体由 5 部分组成,格式如下:
1 2 3 4
+-----------+-----------+----------------------+----------+--------+ | Key Size | User Key | tag | Val Size | Value | +-----------+-----------+----------------------+----------+--------+ | varint32 | key bytes | 64 位,后 8 位为 type | varint32 | value |
这里第一部分的 keysize 是用 Varint 编码的用户 key 长度加上 8 字节 tag,tag 是序列号和 value type 的组合,高 56 位存储序列号,低 8 位存储 value type。其他部分比较简单,这里不再赘述。
// If memtable contains a value for key, store it in *value and return true. // If memtable contains a deletion for key, store a NotFound() error // in *status and return true. // Else, return false. boolGet(const LookupKey& key, std::string* value, Status* s);
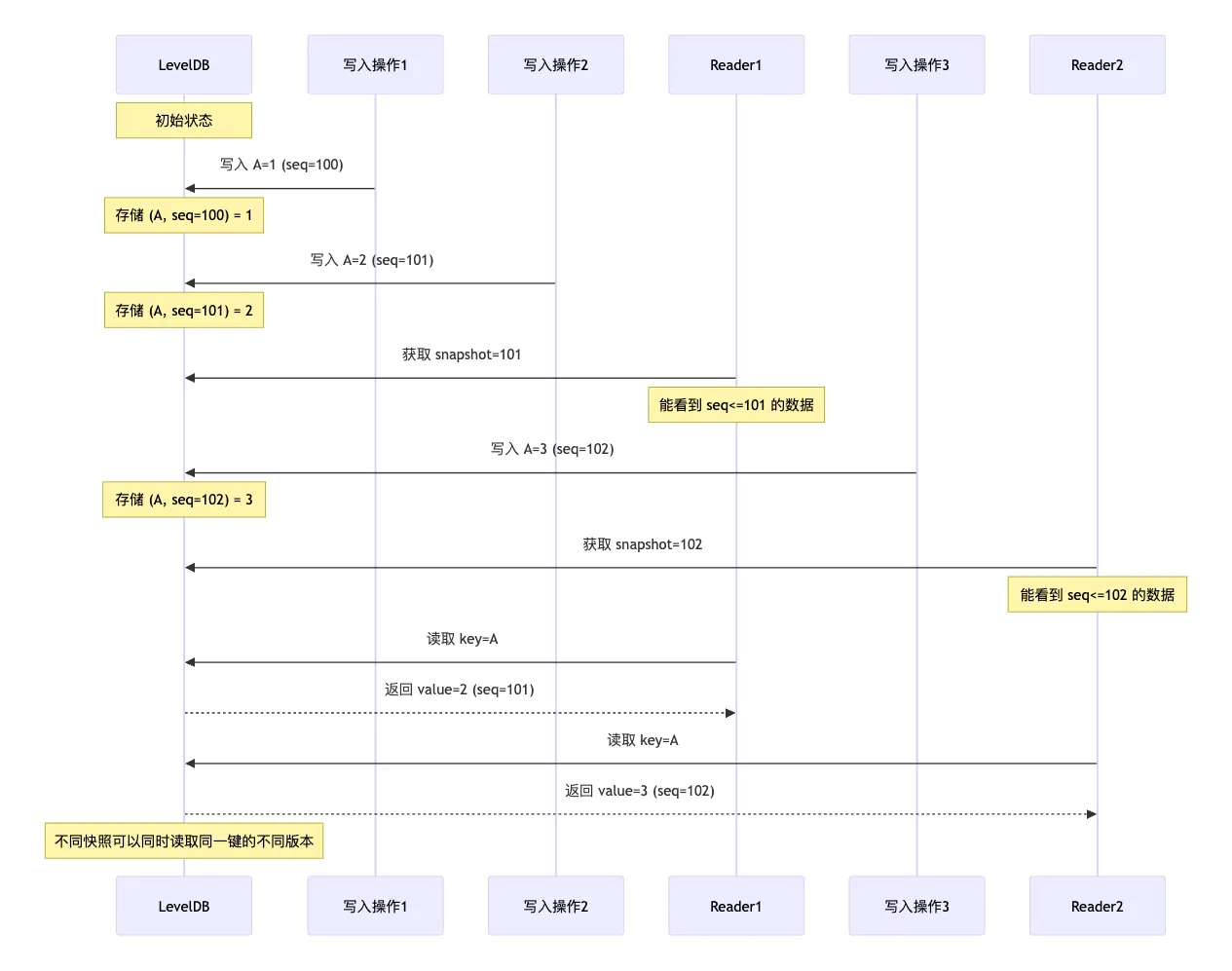
boolMemTable::Get(const LookupKey& key, std::string* value, Status* s){ Slice memkey = key.memtable_key(); Table::Iterator iter(&table_); iter.Seek(memkey.data()); if (iter.Valid()) { // Check that it belongs to same user key. We do not check the // sequence number since the Seek() call above should have skipped // all entries with overly large sequence numbers. constchar* entry = iter.key(); uint32_t key_length; constchar* key_ptr = GetVarint32Ptr(entry, entry + 5, &key_length); if (comparator_.comparator.user_comparator()->Compare( Slice(key_ptr, key_length - 8), key.user_key()) == 0) { // Correct user key constuint64_t tag = DecodeFixed64(key_ptr + key_length - 8); switch (static_cast<ValueType>(tag & 0xff)) { case kTypeValue: { Slice v = GetLengthPrefixedSlice(key_ptr + key_length); value->assign(v.data(), v.size()); returntrue; } case kTypeDeletion: *s = Status::NotFound(Slice()); returntrue; } } } returnfalse; }
所以拿到 internal key 后,不用再检查序列号。只用确认用户 key 相等后,再拿到 64 位的 tag,用 0xff 取出低 8 位的操作类型。对于删除操作会返回”未找到”的状态,说明该键值已经被删除了。对于值操作,则接着从 memtable key 后面解出 value 字节串,然后赋值给 value 指针。
友元类声明
除了前面的 Add 和 Get 方法,MemTable 类还声明了一个友元类 friend class MemTableBackwardIterator;,看名字是逆向的迭代器。不过在整个代码仓库,并没有找到这个类的定义。可能是开发的时候预留的一个功能,最后没有实现,这里忘记删除无效代码了。这里编译器没有报错是因为C++ 编译器在处理友元声明时不要求友元类必须已经定义。编译器仅检查该声明的语法正确性,只有当实际上需要使用那个类(例如创建实例或访问其成员)时,缺少定义才会成为问题。
// Value types encoded as the last component of internal keys. // DO NOT CHANGE THESE ENUM VALUES: they are embedded in the on-disk // data structures. enumValueType { kTypeDeletion = 0x0, kTypeValue = 0x1 };
// A helper class useful for DBImpl::Get() classLookupKey { public: // Initialize *this for looking up user_key at a snapshot with // the specified sequence number. LookupKey(const Slice& user_key, SequenceNumber sequence);
// Return a key suitable for lookup in a MemTable. Slice memtable_key()const{ returnSlice(start_, end_ - start_); } // Return an internal key (suitable for passing to an internal iterator) Slice internal_key()const{ returnSlice(kstart_, end_ - kstart_); } // Return the user key Slice user_key()const{ returnSlice(kstart_, end_ - kstart_ - 8); }
Under the hood, functions are injected into the system message in a syntax the model has been trained on. This means functions count against the model’s context limit and are billed as input tokens. If you run into token limits, we suggest limiting the number of functions or the length of the descriptions you provide for function parameters.
MCP 基于 function calling 能力,所以也有同样的限制。MCP server 如果提供了过多的工具,或者工具描述太复杂,都会影响到实际效果。
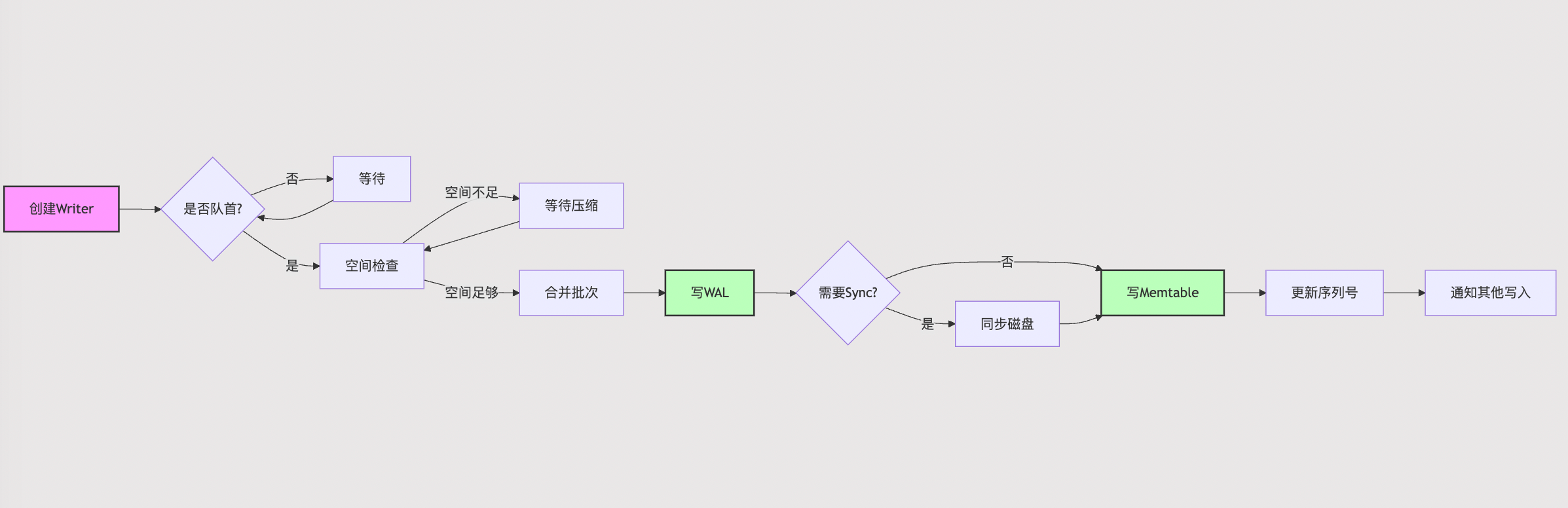
// REQUIRES: this thread is currently at the front of the writer queue Status DBImpl::MakeRoomForWrite(bool force){ mutex_.AssertHeld(); assert(!writers_.empty()); bool allow_delay = !force; Status s; while (true) { if (!bg_error_.ok()) { // Yield previous error s = bg_error_; break; } // ... } }
elseif (allow_delay && versions_->NumLevelFiles(0) >= config::kL0_SlowdownWritesTrigger) { // We are getting close to hitting a hard limit on the number of // L0 files. Rather than delaying a single write by several // seconds when we hit the hard limit, start delaying each // individual write by 1ms to reduce latency variance. Also, // this delay hands over some CPU to the compaction thread in // case it is sharing the same core as the writer. mutex_.Unlock(); env_->SleepForMicroseconds(1000); allow_delay = false; // Do not delay a single write more than once mutex_.Lock(); }
elseif (!force && (mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) { // There is room in current memtable break; }
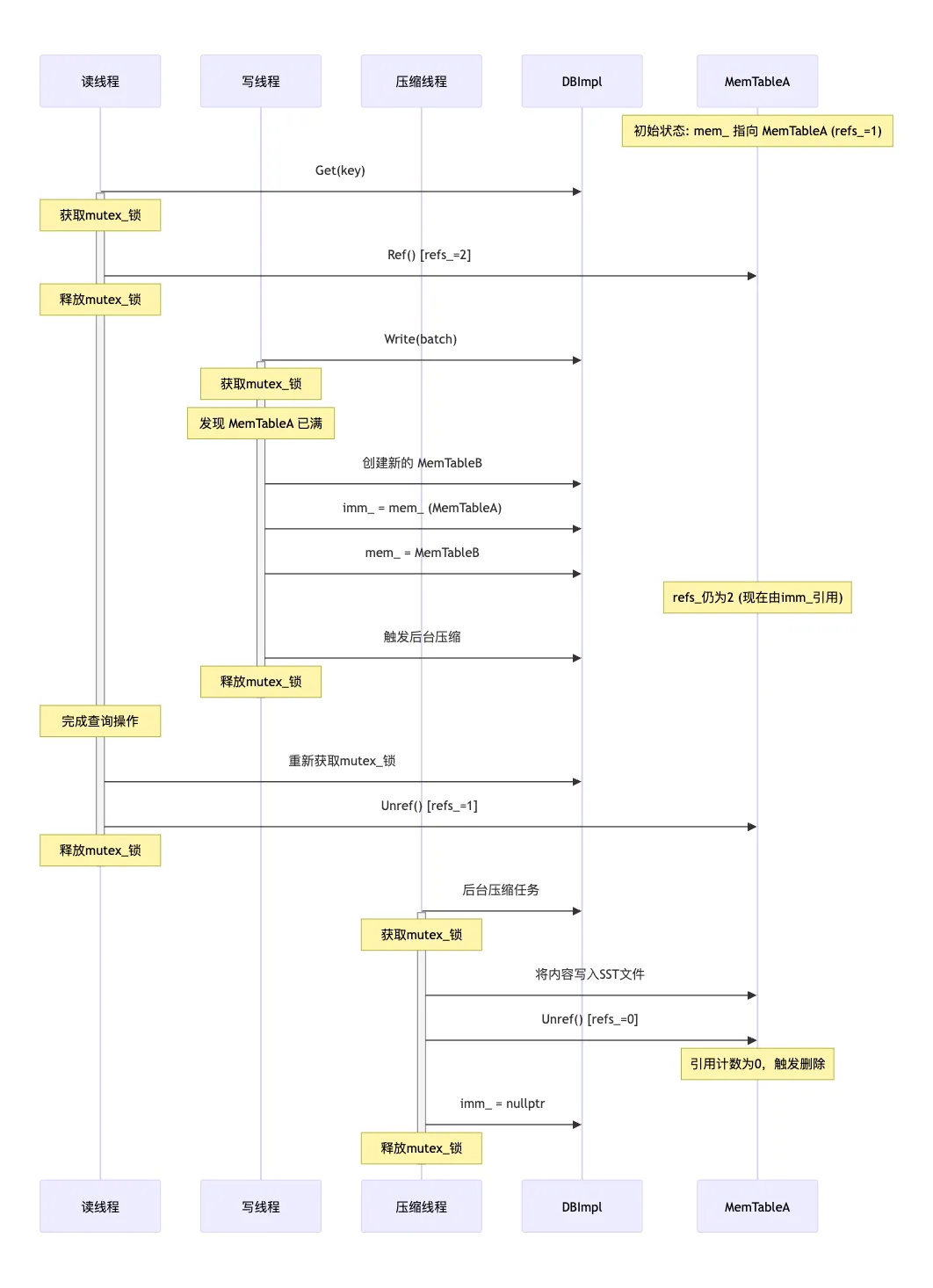
接着这里判断如果当前 memtable 的使用量没超过最大容量,就直接返回了。这里 write_buffer_size 是 memtable 的最大容量,默认是 4MB。这里可以调整配置,如果大一点的话,会在内存缓存更多数据,提高写入的性能,但是会占用更多内存,并且下次打开 db 的时候,恢复时间也会更长些。
接下来有两种情况,是当前没有地方可以写入,因此需要等待了。
1 2 3 4 5 6 7 8 9 10
elseif (imm_ != nullptr) { // We have filled up the current memtable, but the previous // one is still being compacted, so we wait. Log(options_.info_log, "Current memtable full; waiting...\n"); background_work_finished_signal_.Wait(); } elseif (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) { // There are too many level-0 files. Log(options_.info_log, "Too many L0 files; waiting...\n"); background_work_finished_signal_.Wait(); }
// Add to log and apply to memtable. We can release the lock // during this phase since &w is currently responsible for logging // and protects against concurrent loggers and concurrent writes // into mem_. { mutex_.Unlock(); status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); bool sync_error = false; if (status.ok() && options.sync) { status = logfile_->Sync(); if (!status.ok()) { sync_error = true; } } if (status.ok()) { status = WriteBatchInternal::InsertInto(write_batch, mem_); } mutex_.Lock(); if (sync_error) { // The state of the log file is indeterminate: the log record we // just added may or may not show up when the DB is re-opened. // So we force the DB into a mode where all future writes fail. RecordBackgroundError(status); } }
for (; iter != writers_.end(); ++iter) { Writer* w = *iter; if (w->sync && !first->sync) { // Do not include a sync write into a batch handled by a non-sync write. break; } // ... }
// Allow the group to grow up to a maximum size, but if the // original write is small, limit the growth so we do not slow // down the small write too much. size_t max_size = 1 << 20; if (size <= (128 << 10)) { max_size = size + (128 << 10); }
std::vector::front() Calling this function on an empty container causes undefined behavior.
std::vector::push_back() If a reallocation happens, the storage is allocated using the container’s allocator, which may throw exceptions on failure (for the default allocator, bad_alloc is thrown if the allocation request does not succeed).
数组下标访问越界
除了抛出异常,还有一类问题也比较常见,那就是数组下标访问越界。我们都知道在 C++ 中访问数组的时候如果下标越界,会导致访问非法内存地址,可能导致进程 crash。你可能会觉得,怎么会数组访问越界?我遍历的时候限制长度就行了呀。