LevelDB 源码阅读:写入键值的工程实现和优化细节
读、写键值是 KV 数据库中最重要的两个操作,LevelDB 中提供了一个 Put 接口,用于写入键值对。使用方法很简单:
1 | leveldb::Status status = leveldb::DB::Open(options, "./db", &db); |
LevelDB 最大的优点就是写入速度也非常快,可以支持很高的并发随机写。官方给过一个写入压力测试结果:
1 | fillseq : 1.765 micros/op; 62.7 MB/s |
可以看到这里不强制要求刷磁盘的话,随机写入的速度达到 45.0 MB/s,每秒支持写入 40 万次。如果强制要求刷磁盘,写入速度会下降不少,也能够到 0.4 MB/s, 每秒支持写入 3700 次左右。
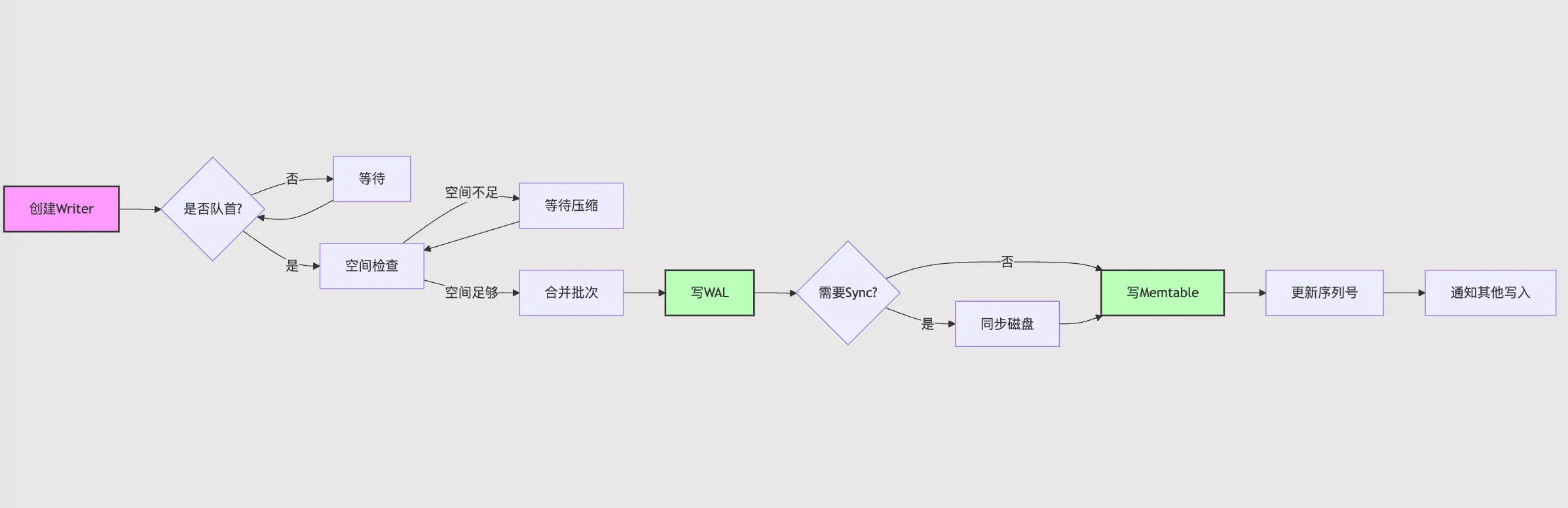
这里 Put 接口具体做了什么?数据的写入又是如何进行的?LevelDB 又有哪些优化?本文一起来看看。开始之前,先看一个大致的流程图: