利用 eBPF BCC 无侵入分析服务函数耗时
我们都知道,在开发和维护后台服务时,监控函数的执行时间是至关重要的。通过监控,我们可以及时发现性能瓶颈,优化代码,确保服务的稳定性和响应速度。然而,传统的方法通常涉及在代码中添加统计信息并上报,这种方法虽然有效,但往往只针对那些被认为是关键路径的函数。
假设在某个时刻,我们突然需要监控一个并非重点关注的函数的执行时间。在这种情况下,修改代码并重新部署服务可能是一项繁琐且耗时的任务。这时,eBPF(扩展的伯克利数据包过滤器)和 BCC(BPF 编译器集合)就派上了用场。通过使用 eBPF,我们可以在不修改代码和不重新部署服务的情况下,动态地插入探针来监控函数的执行时间。这不仅大大简化了监控过程,还减少了对服务性能的影响。
在接下来的文章中,将详细介绍如何利用 eBPF BCC 来无侵入地分析服务函数耗时,并通过实际示例来展示其强大的功能。
eBPF 函数耗时分析原理
eBPF 是一种非常强大的技术,它允许开发者在 Linux 内核中执行自定义代码,而无需修改内核或加载内核模块。这种灵活性使得 eBPF 可以应用于各种场景,包括网络监控、安全和性能分析。
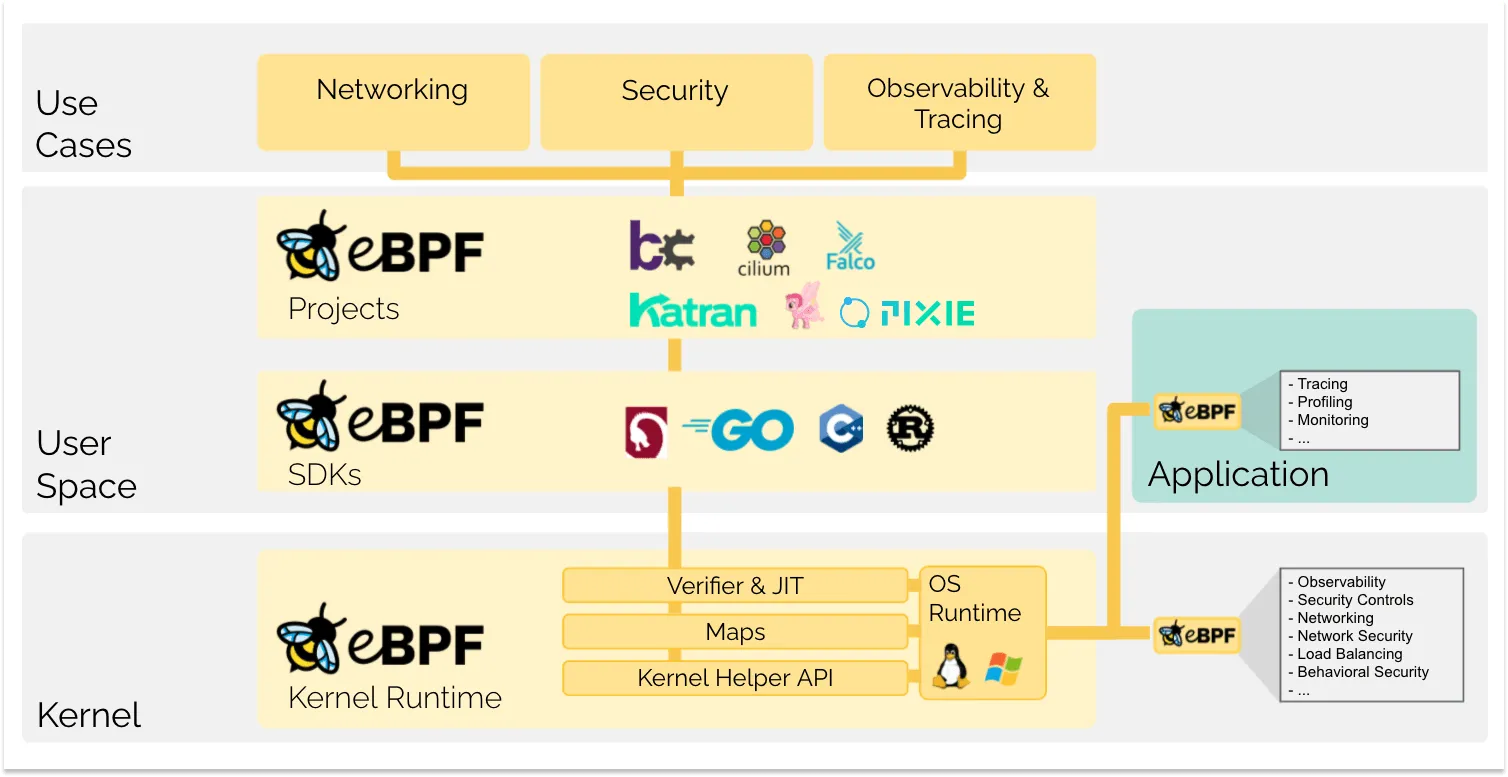
eBPF 支持用户空间追踪 (uprobes),允许我们附加 eBPF 程序到用户空间应用程序,这意味着我们可以非常精细地监控和分析用户空间应用程序的行为,而无需修改应用程序代码。我们可以在函数入口和退出时定义要执行的代码,当函数被调用时,入口探针(kprobe/uprobe)被触发,当函数返回时,退出探针被触发。
为了计算函数的耗时,可以在函数入口的 eBPF 程序中,记录当前的时间戳。在函数退出的 eBPF 程序中,再次记录时间戳,并计算两者之间的差异,这就是函数的执行时间。然后将函数的执行时间存储在 BPF Maps 中,在用户空间中对其进行进一步的分析和可视化,以帮助我们理解函数的性能特征。
直接写 ebpf 有点麻烦,好在我们可以用 BCC 来简化开发难度。BCC (BPF Compiler Collection) 是一个开发工具集,它简化了编写和编译 BPF 程序的过程,允许开发人员使用 Python、C 等语言编写脚本来控制 eBPF 程序的行为。
模拟耗时函数
为了使用 eBPF BCC 来分析函数耗时,我们首先需要创建一个测试进程,在该进程中使用一个特定的函数来模拟实际场景中函数的耗时情况。在常见的业务中,函数的耗时分布通常是不均匀的,因此这里有意设计了一个函数,使其 P99 耗时显著大于平均耗时。这样可以模拟实际的业务场景,大多数请求都能快速处理,但在某些情况下(如数据量大、缓存未命中或资源争用等),处理时间会显著增加。
补充说一下 P99 耗时是一种性能指标,它描述的是一个系统或函数中,99% 的执行时间都小于这个 P99 分位值。可以这样简单理解:如果你有100个请求,P99 耗时就是这100个请求中耗时最长的那一个。不过不同工具计算 P99 的算法可能不太一致,如果函数执行 100 次,99 次的耗时都分布在 1ms 到 2ms之间,有一次耗时 100ms,那么 P99 可以是 2ms,也可以是 100ms,取决于具体的算法实现,这里不影响我们对于 P99 指标的理解。
这里模拟耗时的函数实现如下:
1 | void someFunction(int iteration) { |
为了提供一个耗时的计算基准,在测试代码中我们也添加了耗时统计,计算函数的平均耗时和 P99 耗时。具体方法是,在一个无限循环中,它每次调用函数并记录执行时间。每当累计执行时间超过一秒,它就计算并输出这段时间内函数执行的平均时间和P99 时间。然后,它清除所有已记录的执行时间,准备开始下一轮的数据收集和分析,如下实现:
1 | int main() { |
完整的代码 func_time.cpp 在 gist 上。在我的服务器上得到执行结果如下,函数耗时和机器性能以及负载都有关系:
Average execution time: 3.95762 ms
P99 execution time: 190.968 ms
Average execution time: 3.90211 ms
P99 execution time: 191.292 ms
…
BCC 函数耗时直方分布
注意这里的耗时监控脚本需要依赖 BCC 工具,可以在 BCC 的 GitHub 页面找到安装指南。此外需要保证你的系统内核支持BPF,对于 Linux内核版本,通常需要4.8或以上版本,以获取最佳的BPF功能支持。
BCC 提供了方便的方法,便于我们统计函数的耗时分布。首先通过解析命令行参数获取目标进程的 PID 和待追踪的函数名,然后构建并加载一个 BPF 程序,使用用户态探针(uprobes)和用户态返回探针(uretprobes)附加到指定的进程和函数,以便在函数开始和结束时获取时间戳。
探针函数 trace_start 在每次函数调用开始时捕获当前的时间戳,并将其与表示当前进程的键一起存储在 BPF 哈希映射 start 中。当函数调用结束时,trace_end 探针函数查找起始时间戳,并计算出函数执行的时间差。这个时间差被记录到 BPF 直方图 dist 中,用于后续的性能分析。完整的脚本 func_time_hist.py 在 gist 上。
1 | int trace_start(struct pt_regs *ctx) { |
我们用 -g 编译前面的 func_time.cpp ,用 nm 拿到 C++ 名称修饰(name mangling)后的函数名字。运行程序,然后拿到进程 pid,就可以用工具来查看耗时分布了。
1 | g++ func_time.cpp -g -o func_time |
当按下 Ctrl-C 中止程序时,会打印出 dist 直方图,以对数尺度显示函数执行时间的分布情况。这使得我们可以快速了解函数执行性能的大致情况,如最常见的执行时间,以及时间的分布范围,具体如下图:
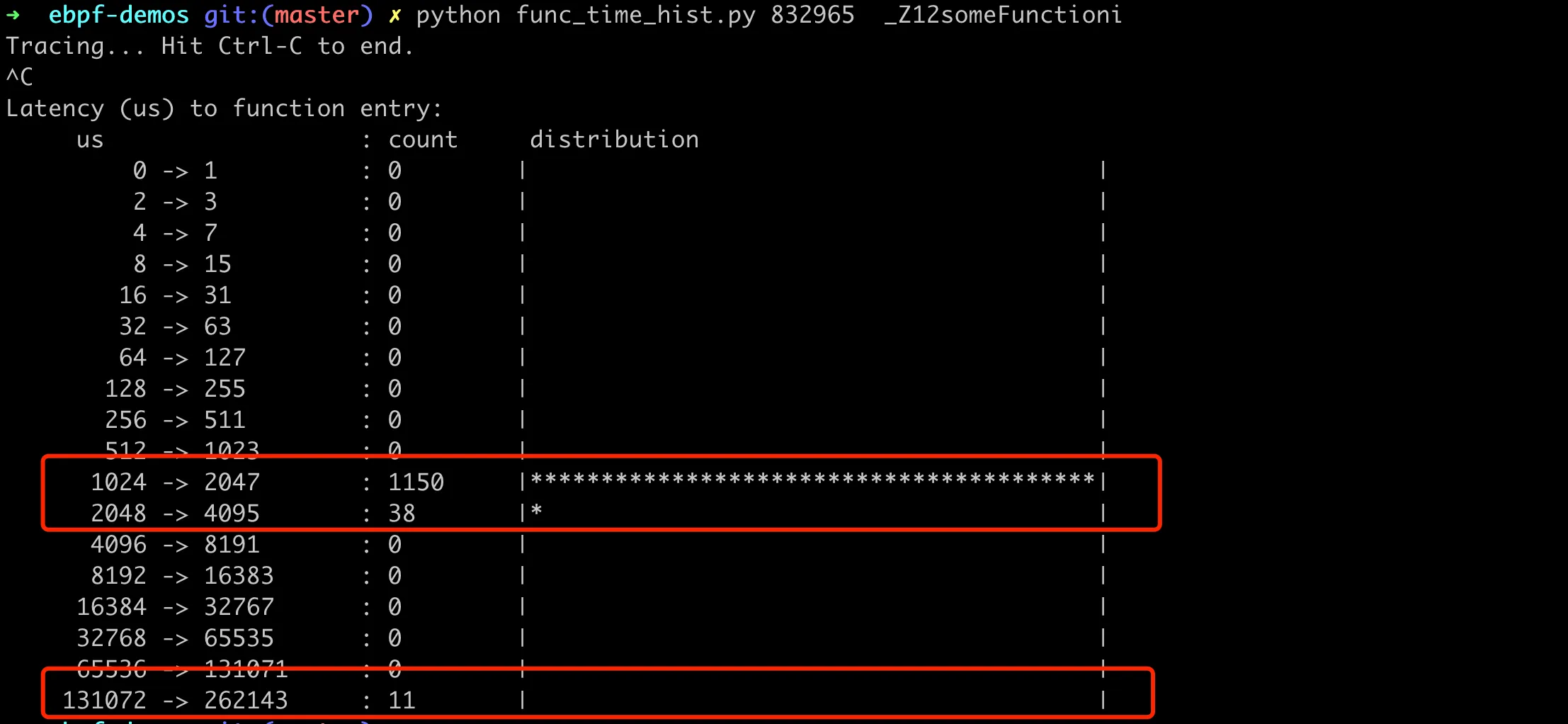
可以看到大部分函数调用的耗时分布在 1024-2047us 之间,有 11 次函数调用的耗时分布在 131702-262143us 之间。这个函数占比大概是 1%,符合我们模拟的函数特征。
BCC 函数平均耗时
很多时候我们不只想看到函数耗时分布,还想知道平均耗时和 P99 耗时,只需要对上面的 BCC 脚本稍作改动即可。每次函数执行后,使用 BPF 的 PERF 输出接口来收集执行时间到用户空间。具体通过在 BPF 程序的 trace_end 函数中使用 perf_submit 助手函数来实现。
1 | int trace_end(struct pt_regs *ctx) { |
接下来,在用户空间的 Python 脚本中,在每个指定的时间间隔内计算平均值和 P99。完整的代码 func_time.py 在 gist 上,执行结果如下:
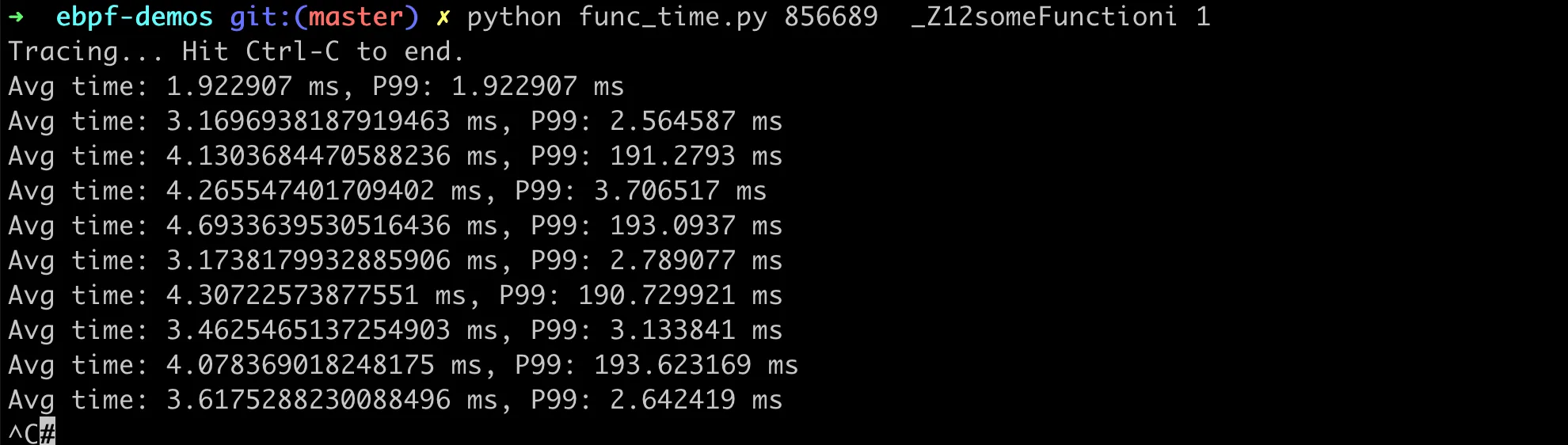
总的来说,使用 eBPF 和 BCC 来进行这种无侵入性的性能分析,对于生产环境中的故障排除和性能优化具有巨大的价值。它允许我们在不中断服务或重新部署代码的情况下,实时收集和分析关键性能指标。这种能力对于维护高性能和高可用性的系统至关重要。

