LevelDB 源码阅读:DataBlock 的前缀压缩和重启点机制分析
在 LevelDB 中,SSTable(Sorted Strings Table)是存储键值对数据的文件格式。前面的文章LevelDB 源码阅读:一步步拆解 SSTable 文件的创建过程 介绍了 SSTable 文件的创建过程,我们知道了 SSTable 文件由多个数据块组成,这些块是文件的基本单位。
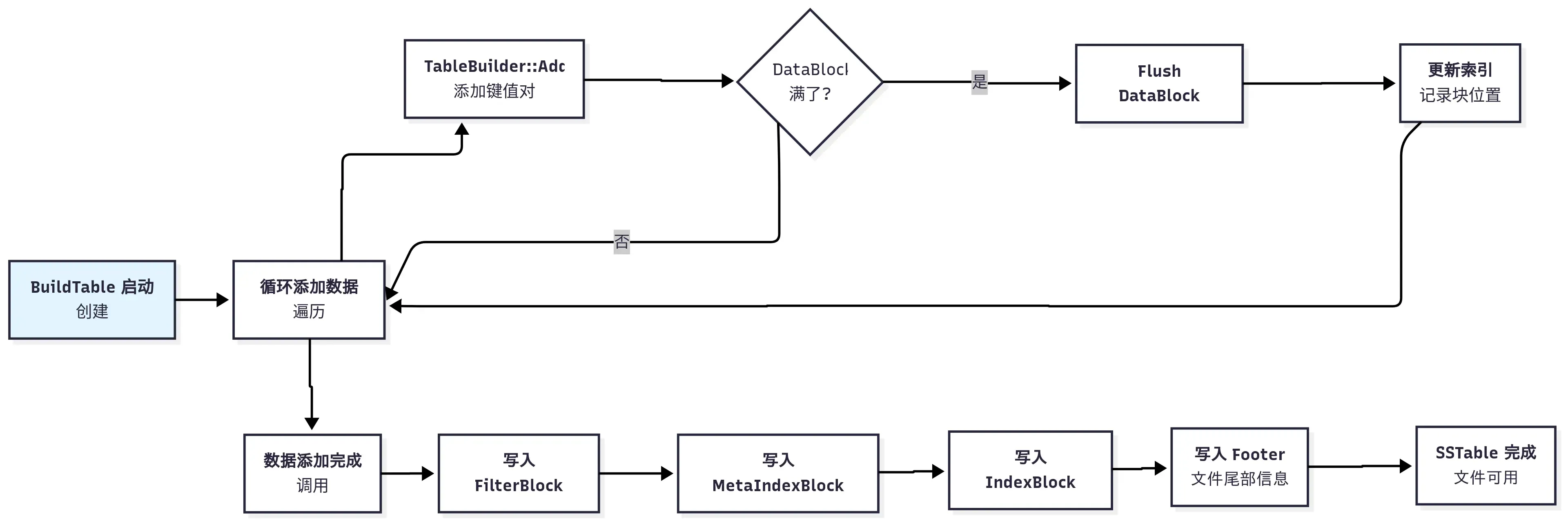
这些数据块起始可以分两类,一种是键值对数据块,一种是过滤块数据块。相应的,为了组装这两类数据块,LevelDB 实现了两类 BlockBuilder 类,分别是 BlockBuilder 和 FilterBlockBuilder。这篇文章,我们来看看 BlockBuilder 的实现。
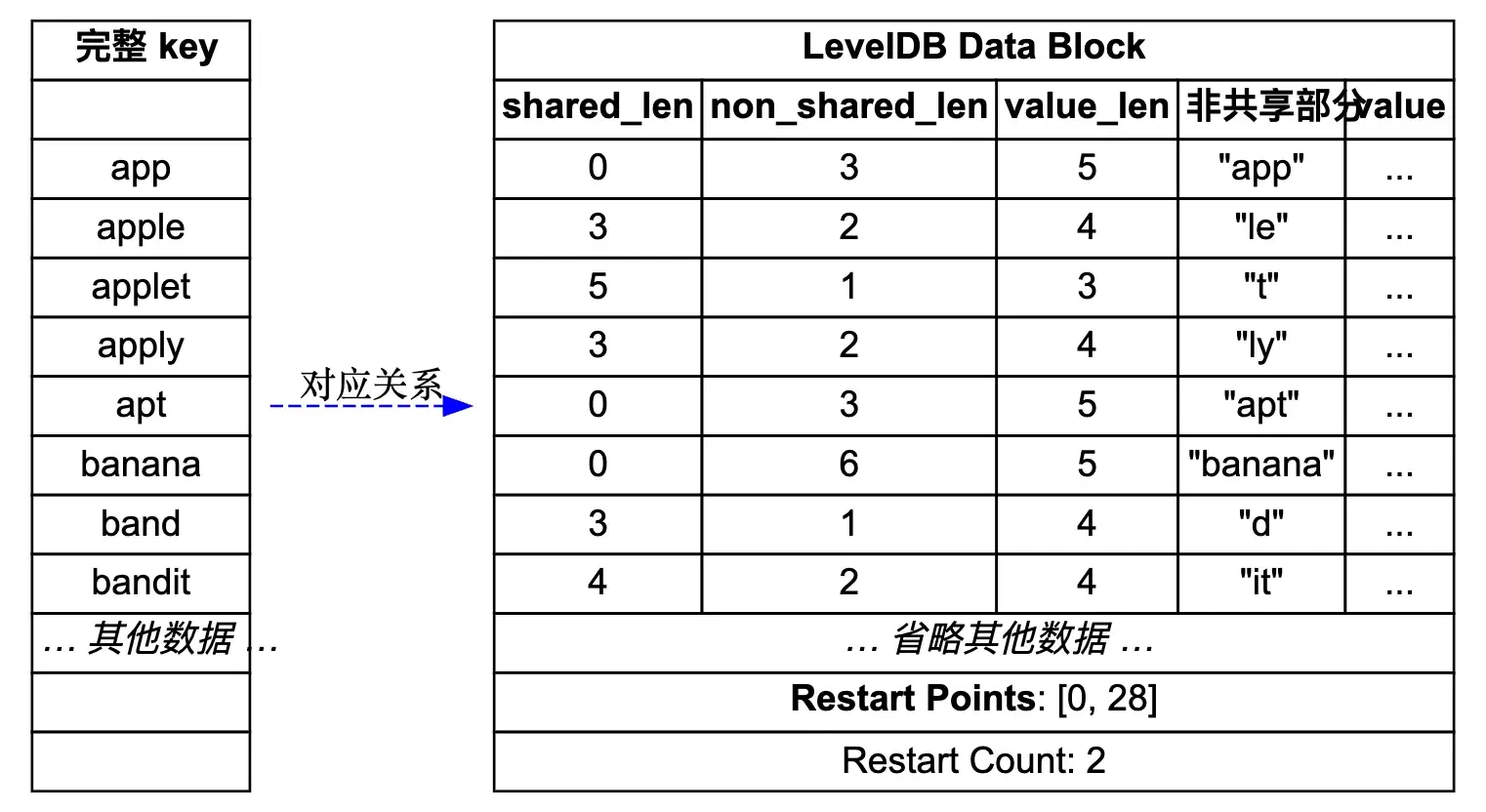
先来看一个简单的示意图,展示了 LevelDB 中 DataBlock 的存储结构,图的源码在 leveldb_datablock.dot。