结合实例理解流式输出的几种实现方法
如果有用过 ChatGPT 等大语言模型,可能就会发现在聊天对话中,AI 的输出文本是一批批“蹦出来”的,这就是所谓的流式输出。在浏览器上,是怎么实现这种效果呢?
本篇文章会介绍 4 种常见方法来实现流式输出效果,每种方法都会结合实际例子来演示。在业务中选择哪种方法,取决于具体的需求和场景。
- 客户端轮询:客户端定时(如每几秒)发送请求到后端服务,获取新的数据。
- 分块传输:HTTP/1.1 支持,服务器一次可以只发送部分响应内容,客户端接收到部分数据后就可以开始处理。
- Server-Sent Events:服务器向浏览器推送信息,浏览器创建一个到服务器的单向连接,服务器通过这个连接可以发送多个消息。
- Web Socket:建立一个持久的、全双工的连接,允许服务器和客户端之间进行实时、双向的通信。
简单轮询
首先是最简单的轮询方法,客户端每隔一段时间向服务器发送请求,获取新的数据。实现轮询的时候,客户端和服务器需要用 HTTP 请求参数和回包约定数据更新或者结束的方式。比如简单的用一个请求字段 cnt 来约定这是第几次请求,返回中用 400 错误码来约定本次轮询结束。
下面用 Python 的 FastAPI 写一个简单示例,每次带一个下标来请求一段文本中的内容,如果超过文本长度,就返回 400。
1 | async def polling(cnt: int = 1): |
这里是轮询的交互式展示:
点击开始后,即可看到数据不断更新,直到结束。如果打开控制台,就能看到浏览器每隔100ms发起一个 HTTP 请求,同时用参数 cnt 表示这是第几次请求。
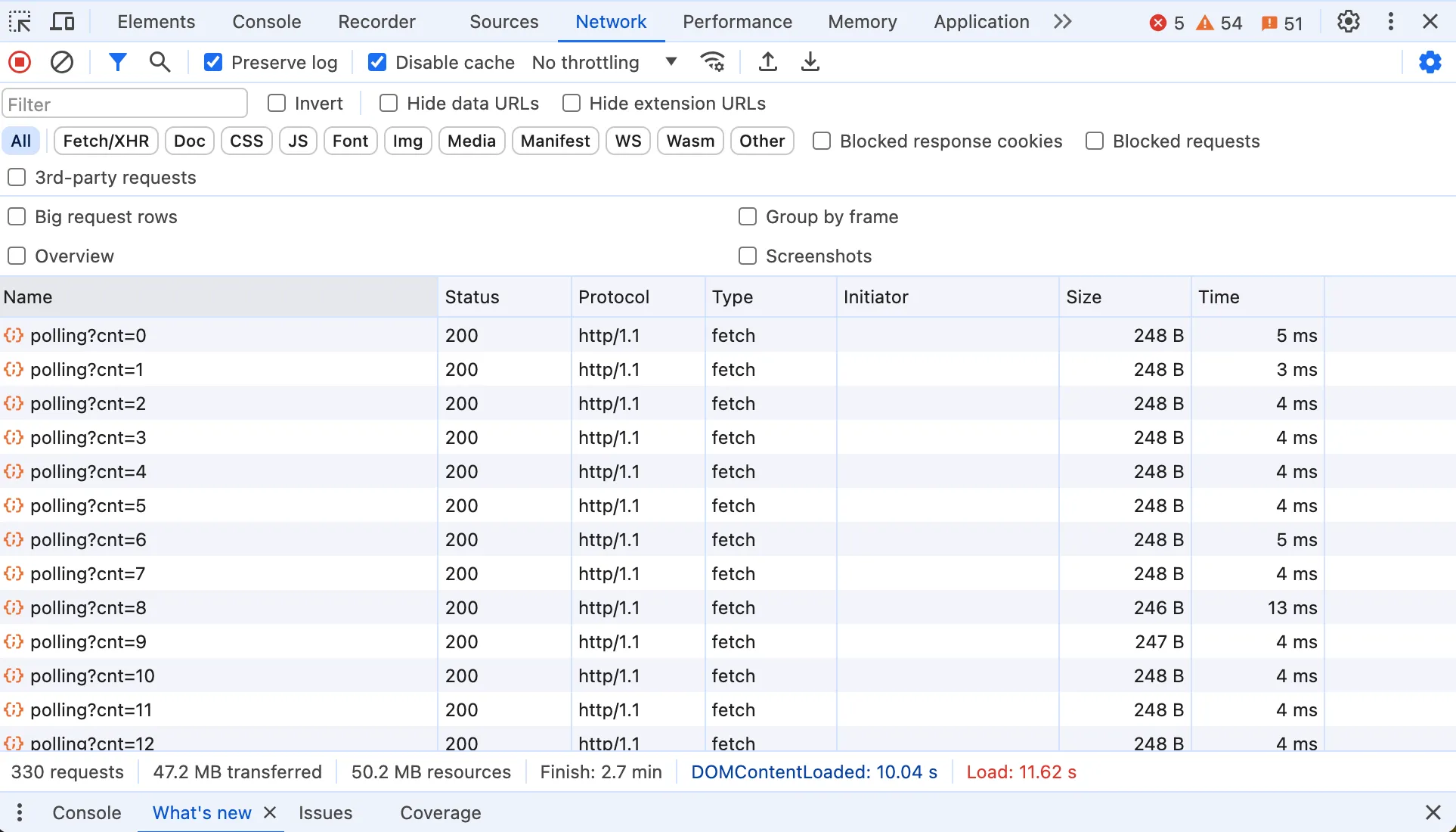
这种方式的优点就是比较容易理解,实现起来比较简单。但是缺点也很明显,就是频繁的 HTTP 请求,会增加服务器的负担,同时也会增加网络传输的开销。如果是 HTTP/1.1 的话,每次请求都需要建立 TCP 连接,开销会更大。另外轮询的时间间隔也不太好控制,如果时间间隔太短,可能数据还没更新,白白浪费多次请求。如果时间间隔太长,用户体验又不好。
分块传输编码
上面轮询机制的缺点显而易见,主要是因为需要很多 HTTP 连接来更新数据。其实在 HTTP/1.1 中,还有一种更好的方式,就是利用分块传输编码。分块传输编码实现流式输出更加高效,客户端只用请求一次,服务器以多个“块”的形式响应,直到所有数据都发送完毕。分块传输适用于响应体很大或由于内容是实时生成的而无法预知大小的情况,常见于大文件下载、视频流或实时数据流的传输。目前如果想在微信小程序中实现流式输出,最方便就是分块编码。
分块传输编码的协议稍微复杂一点,在响应头中用 Transfer-Encoding: chunked 表明响应将以分块的形式发送。每个块开始前,服务器发送一行包含当前块大小的数据,后跟一个回车换行(CRLF),紧接着是实际的块数据,再后面是一个CRLF。传输结束时,服务器发送一个大小为0的块,表示没有更多的数据块,通常后跟一个 CRLF。
在 Python 中用 FastAPI 实现分块编码协议也比较简单,下面是一个简单的示例,隔 100ms 输出内容然后分块编码传输:
1 |
|
这里是分块传输编码的交互式展示:
点击开始后,同样可以看到数据不断更新,直到所有内容打印出来。如果打开控制台,看到浏览器只发送了一个 HTTP 请求,这个请求的响应中 Header 中有 Transfer-Encoding: chunked,响应数据大小随着时间不断更新。下面是动态图:
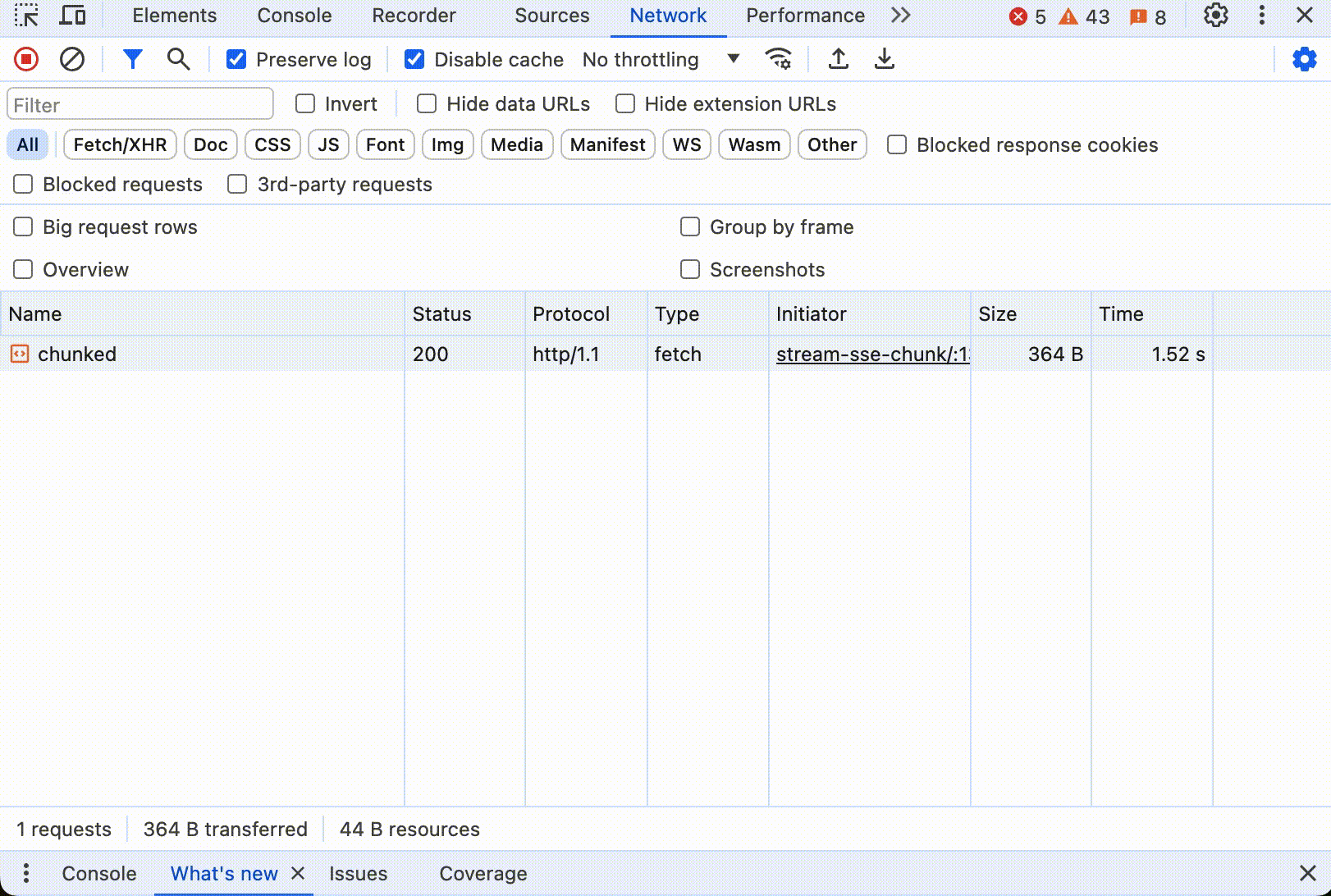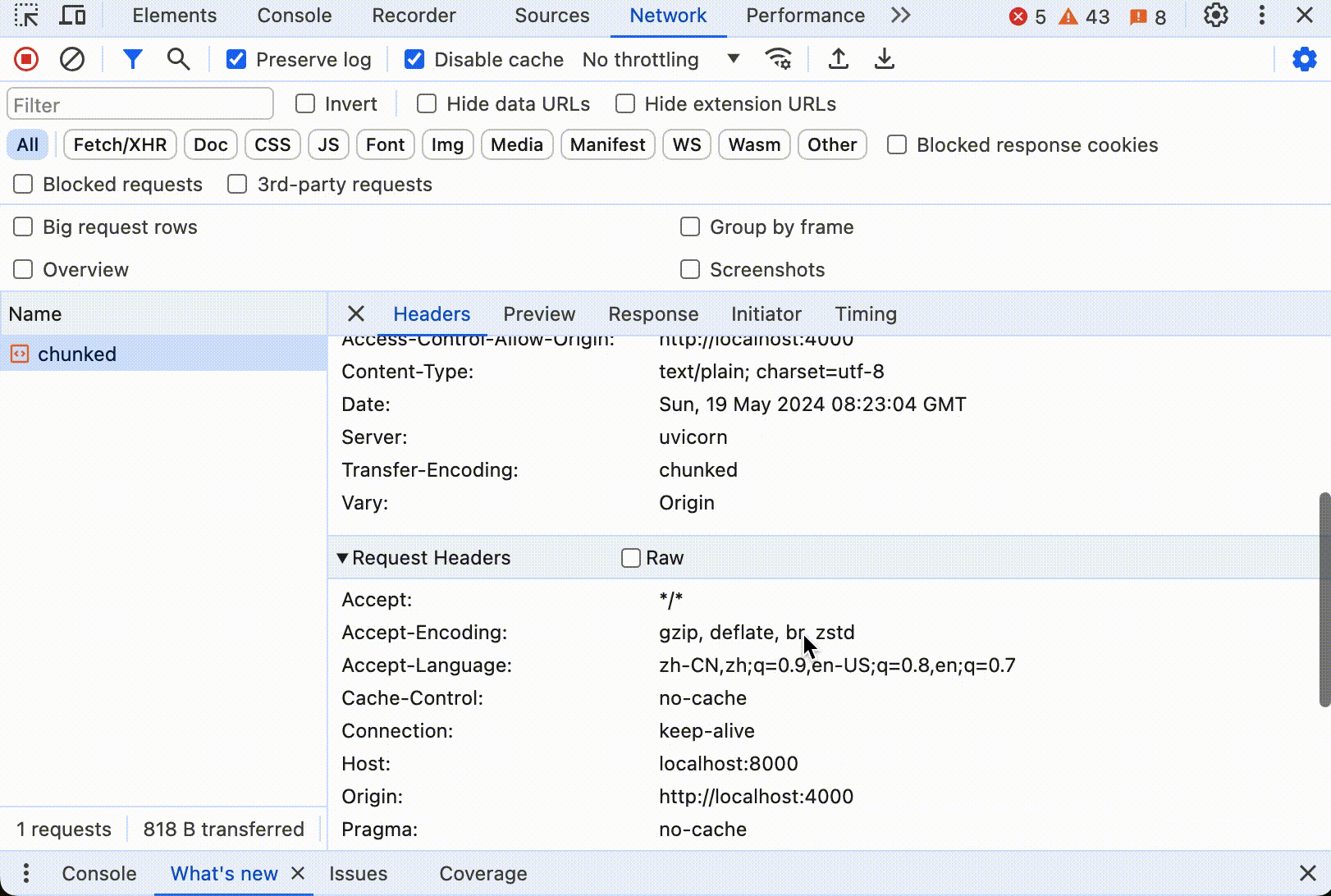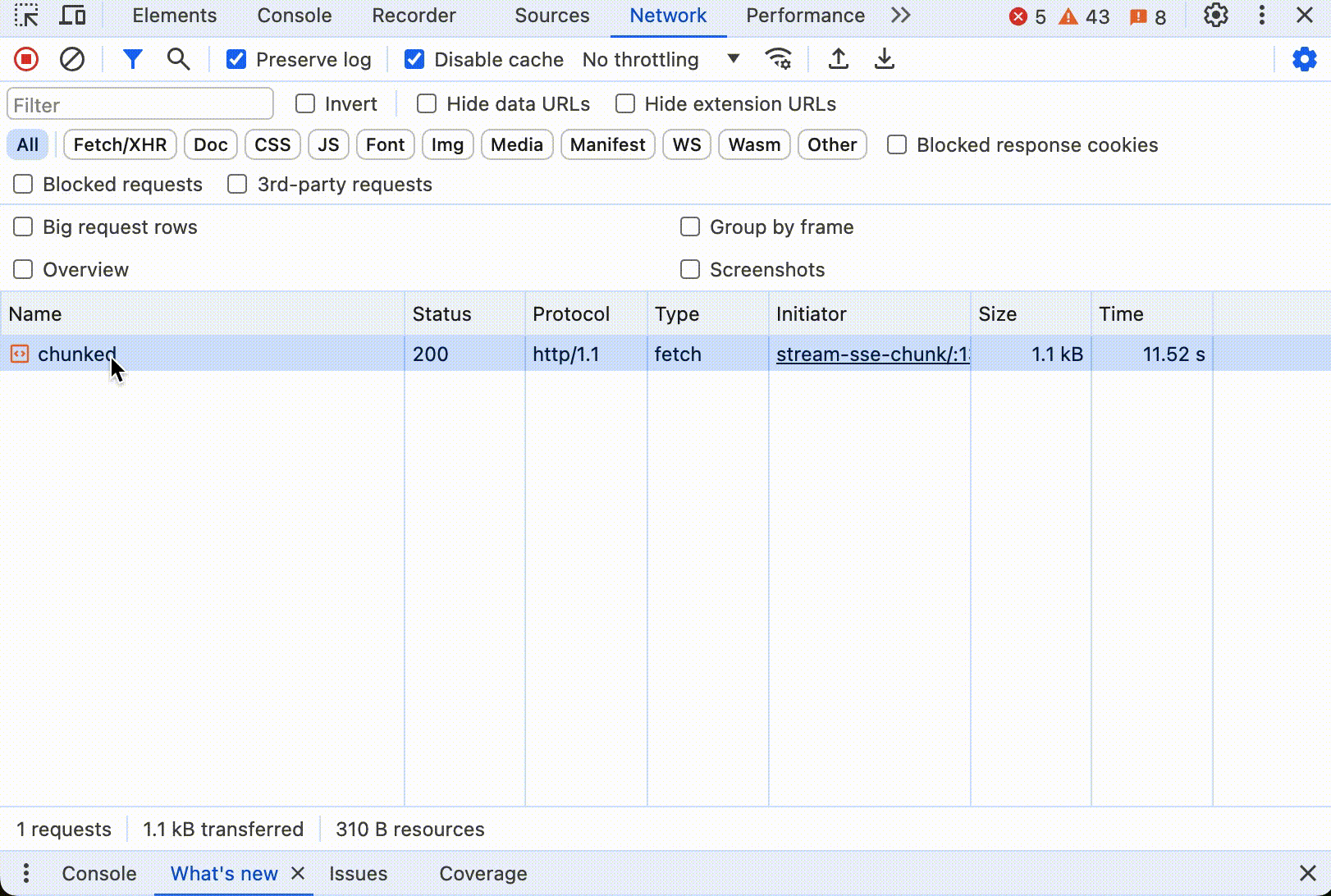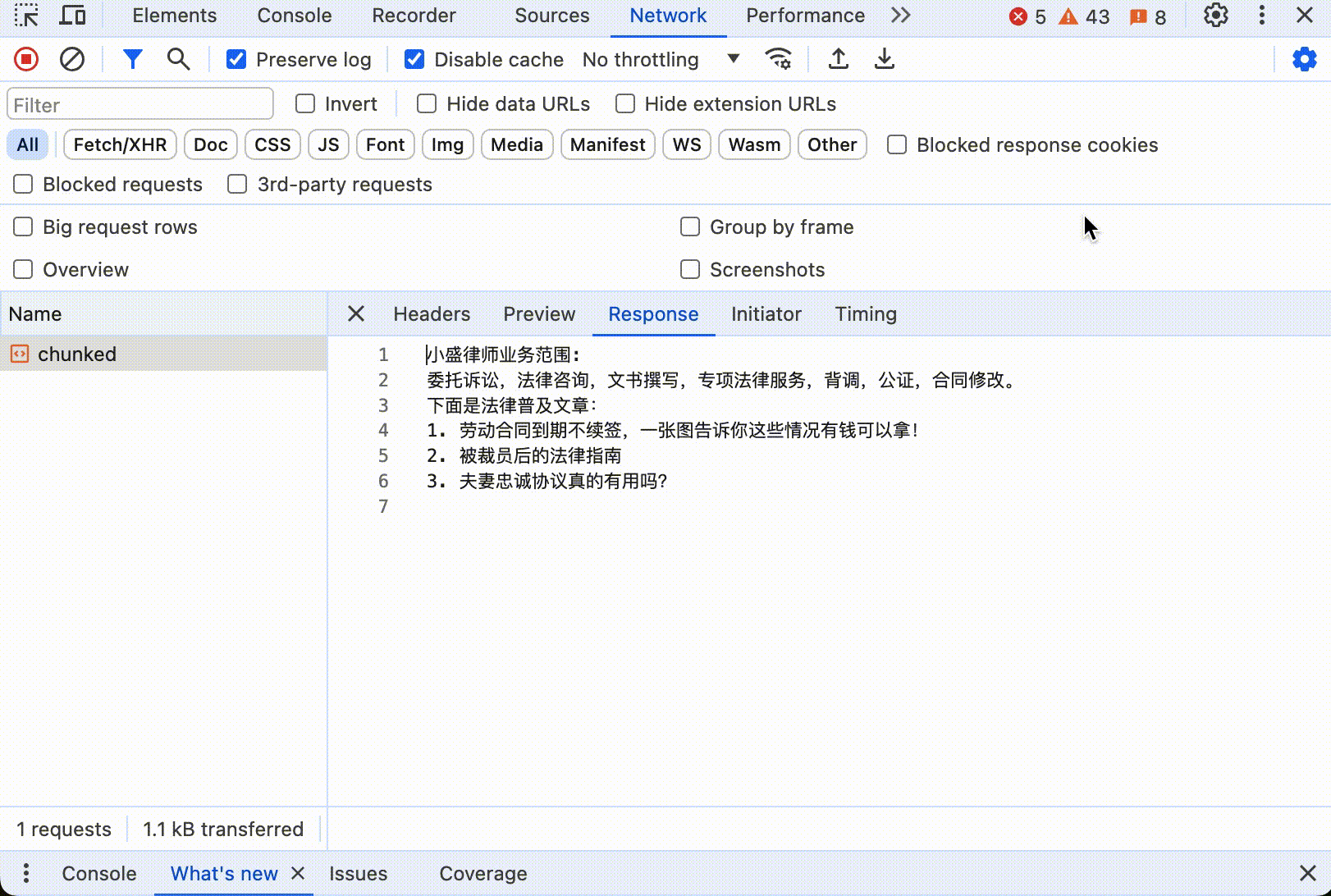
值得注意的是,分块传输编码只在 HTTP/1.1 中支持。在 HTTP/2 中,分块传输编码的概念已经不存在了,这主要是因为 HTTP/2 的工作方式有很大的不同。HTTP/2 引入了多路复用(multiplexing)、二进制帧(binary framing)和流控制(stream prioritization)等新的机制来提高效率和性能。 在 HTTP/2 中,所有通信都在单一的 TCP 连接上通过帧进行。数据帧(DATA frames)被用来传输消息体数据。服务器可以根据需要连续发送多个数据帧,每个帧携带一部分消息内容。客户端按接收顺序重新组装这些帧来重建完整的消息。
不过我这里的示例,在 HTTP/2 下仍然是流式输出的,这是因为这里前端用的 Fetch API 和流处理 response.body.getReader().read(),它提供了一致的接口来处理流数据,不论底层协议是 HTTP/1.1 还是 HTTP/2。当调用的是 HTTP/2 接口时,也能正常从数据帧中读取数据。
Server-Sent Events
OpenAI 在聊天工具 ChatGPT 中没有使用上面两种方式,而是用了 Server-Sent Events(SSE)来实现流式输出。SSE 允许服务器主动向浏览器或其他客户端推送事件。SSE的设计主要是为了简化从服务器到客户端的单向实时数据流,尤其适用于需要快速、持续更新数据的Web应用,如实时新闻更新、股票行情、或社交媒体实时消息等。
SSE 基于 HTTP 协议,使用标准的HTTP请求来开始连接。首先客户端发起标准的 HTTP GET 请求开始一个SSE连接。请求的头部通常包含Accept: text/event-stream,这告诉服务器客户端希望开启一个SSE连接。服务器响应这个请求,并保持连接打开,响应的 Content-Type 被设置为text/event-stream。随后,服务器可以发送形式为纯文本的事件流。每个事件以一个可选的事件名和必须的数据字段组成。事件以data:开始,后跟具体的消息数据,事件之间以两个换行符\n\n分隔。整个过程中 HTTP 连接保持打开状态,服务器可以随时发送新事件,客户端在接收到每个事件后处理数据。SSE连接一旦建立,服务器可以持续不断地发送数据更新到客户端,直到连接被关闭。
在 Python 中用 FastAPI 实现 SSE 比较简单,下面是一个简单的示例,隔 100ms 向客户端返回内容,等所有内容输出完,服务器结束本次连接。
1 |
|
这里是 SSE 的交互式展示:
点击开始后,可以看到数据不断更新,直到所有内容打印出来。如果打开控制台,看到浏览器只发送了一个 HTTP 请求,这个请求的响应中 Header 中有 Content-Type: text/event-stream,响应数据大小随着时间不断更新。下面是整个过程动态图:
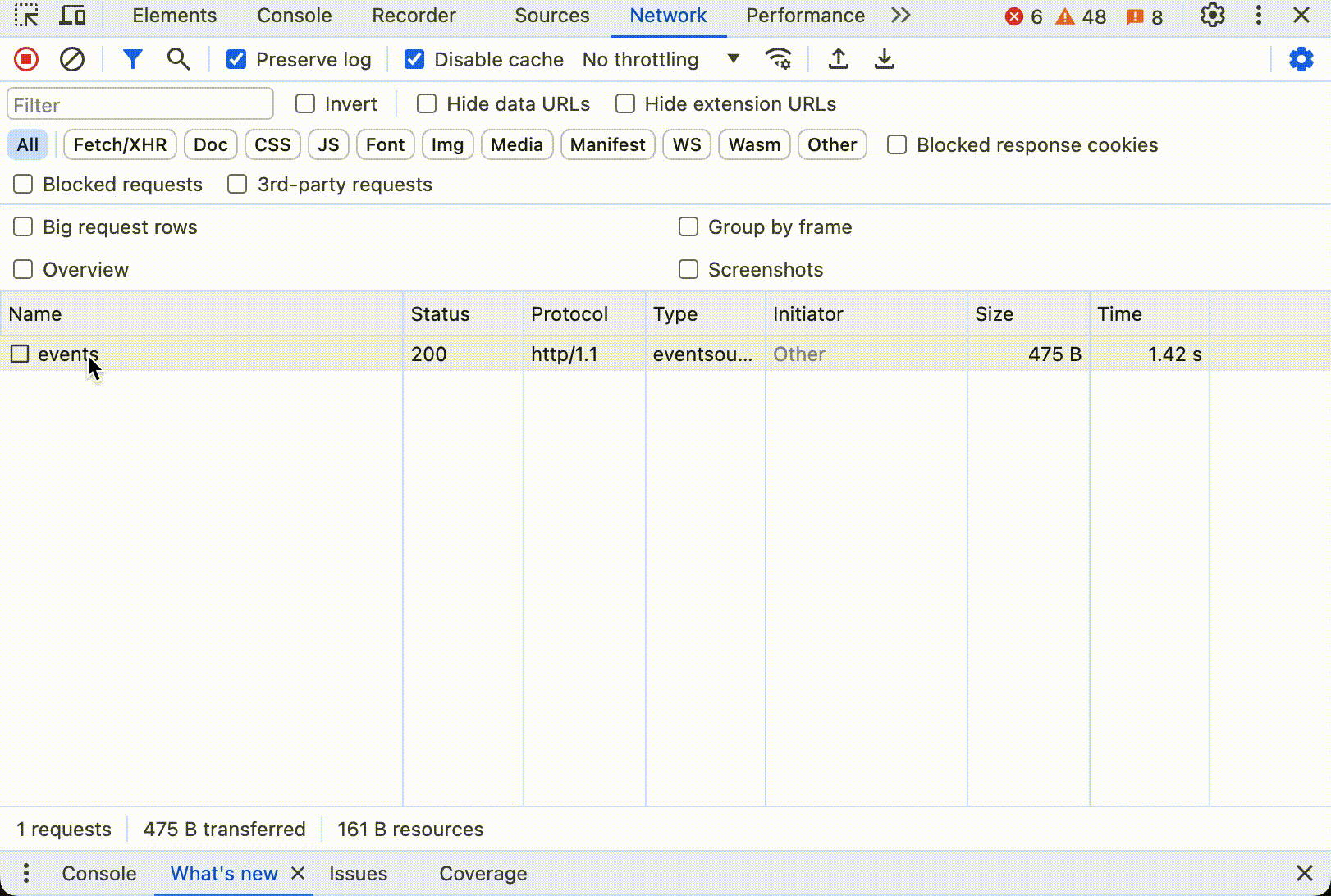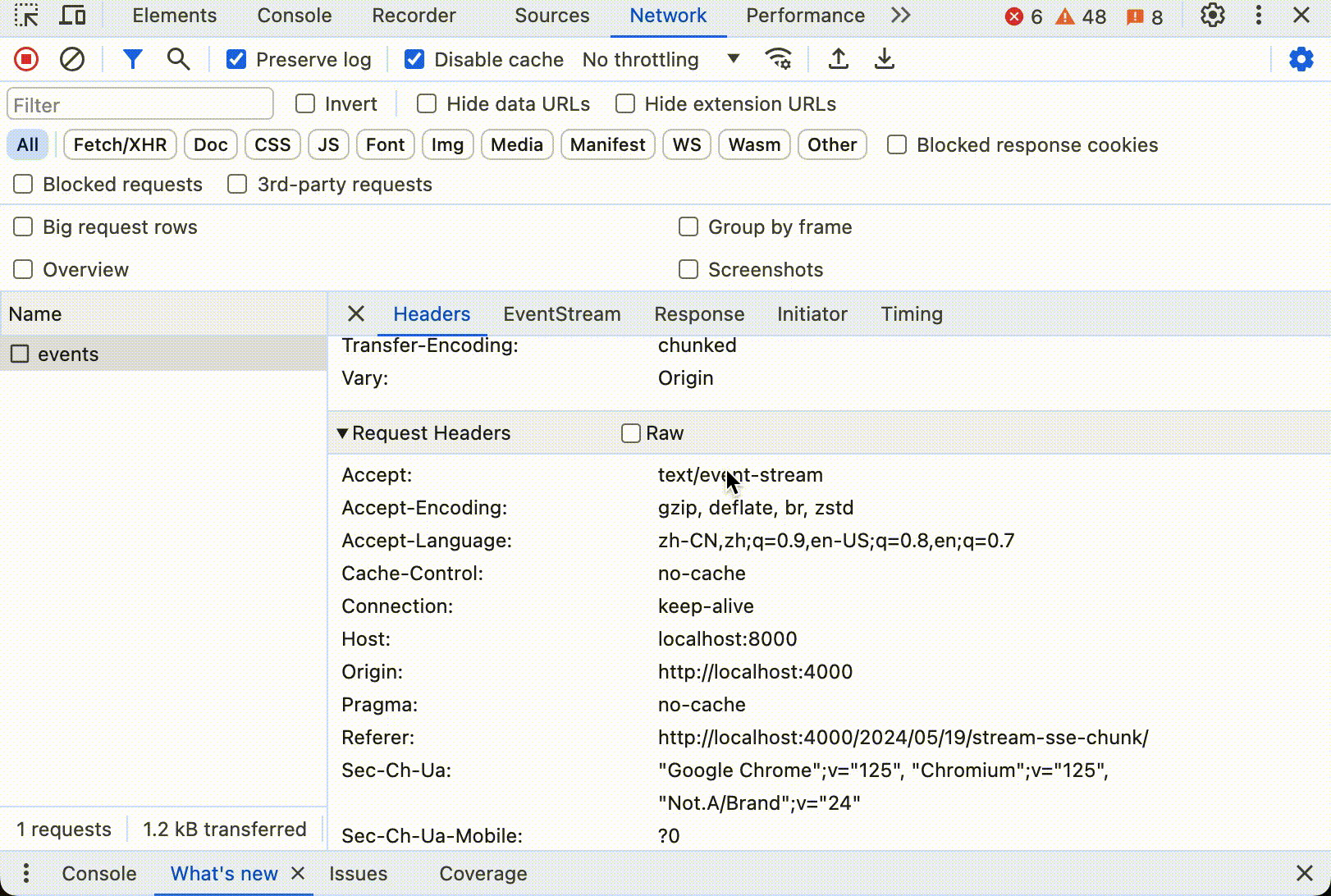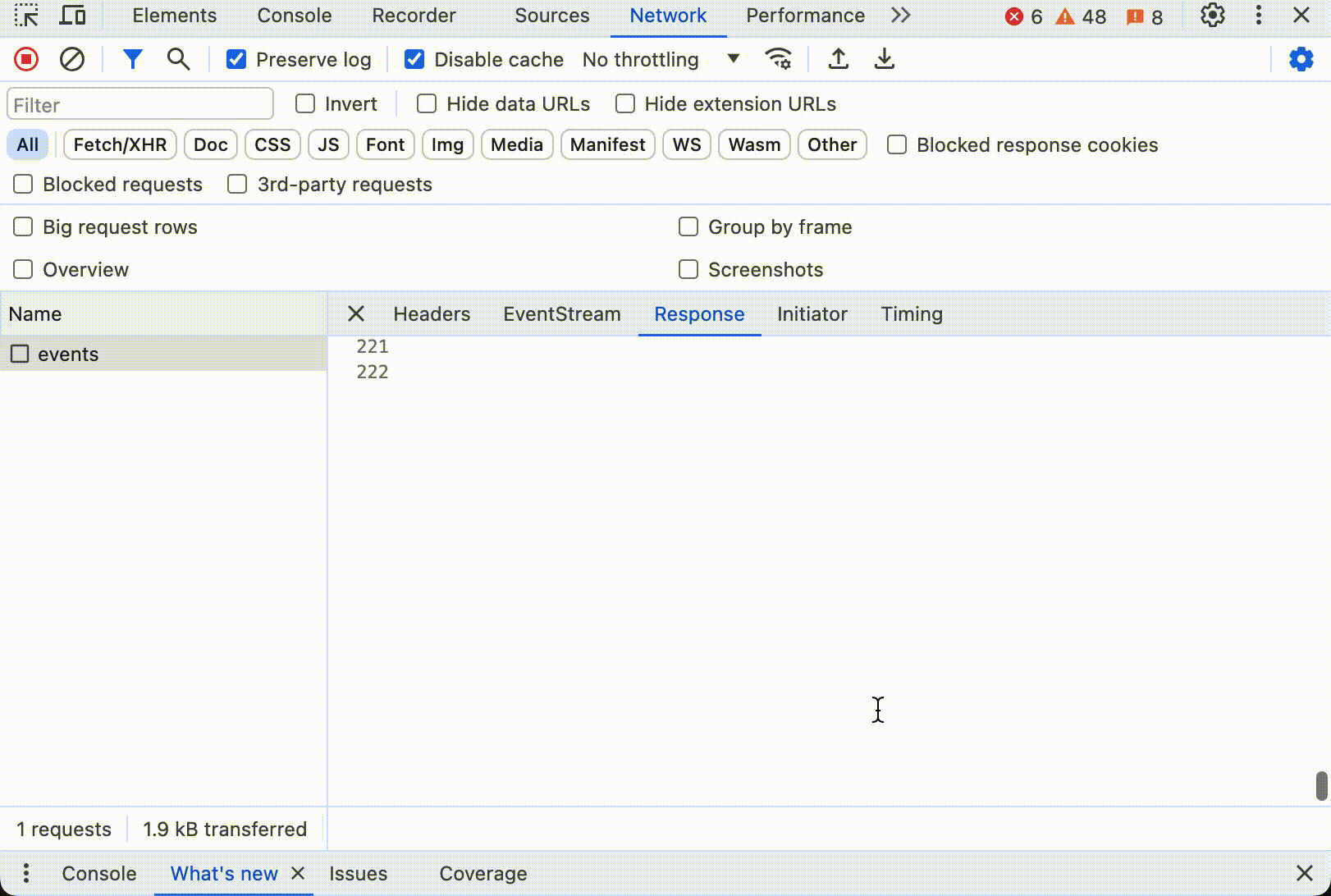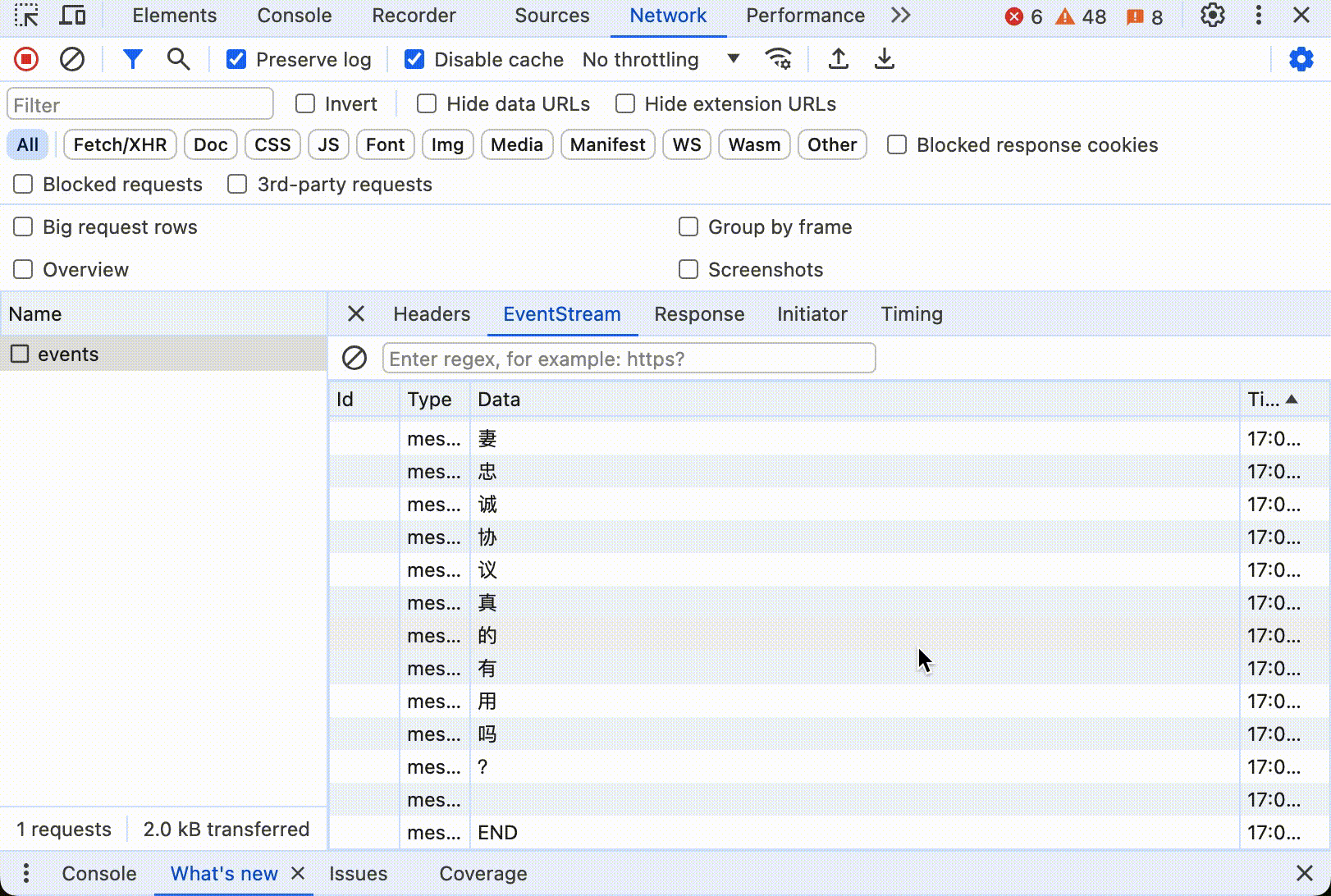
大多数现代浏览器都支持SSE,使用 SSE 用户体验比较好,也十分节省资源。不过 SSE 有一个缺点,就是只能从服务器到客户端单向传输,客户端不能向服务器发送数据。如果需要双向通信,就需要使用 Web Socket。
Web Socket
前面的三种方法都是基于 HTTP 协议的,主要是为了解决服务器向客户端推送数据的问题。而 Web Socket 是一种独立的协议,它是一种全双工通信协议,允许客户端和服务器之间进行实时、双向的通信,从而有效地支持复杂的交互式应用,例如在线游戏、交易平台和协作工具。
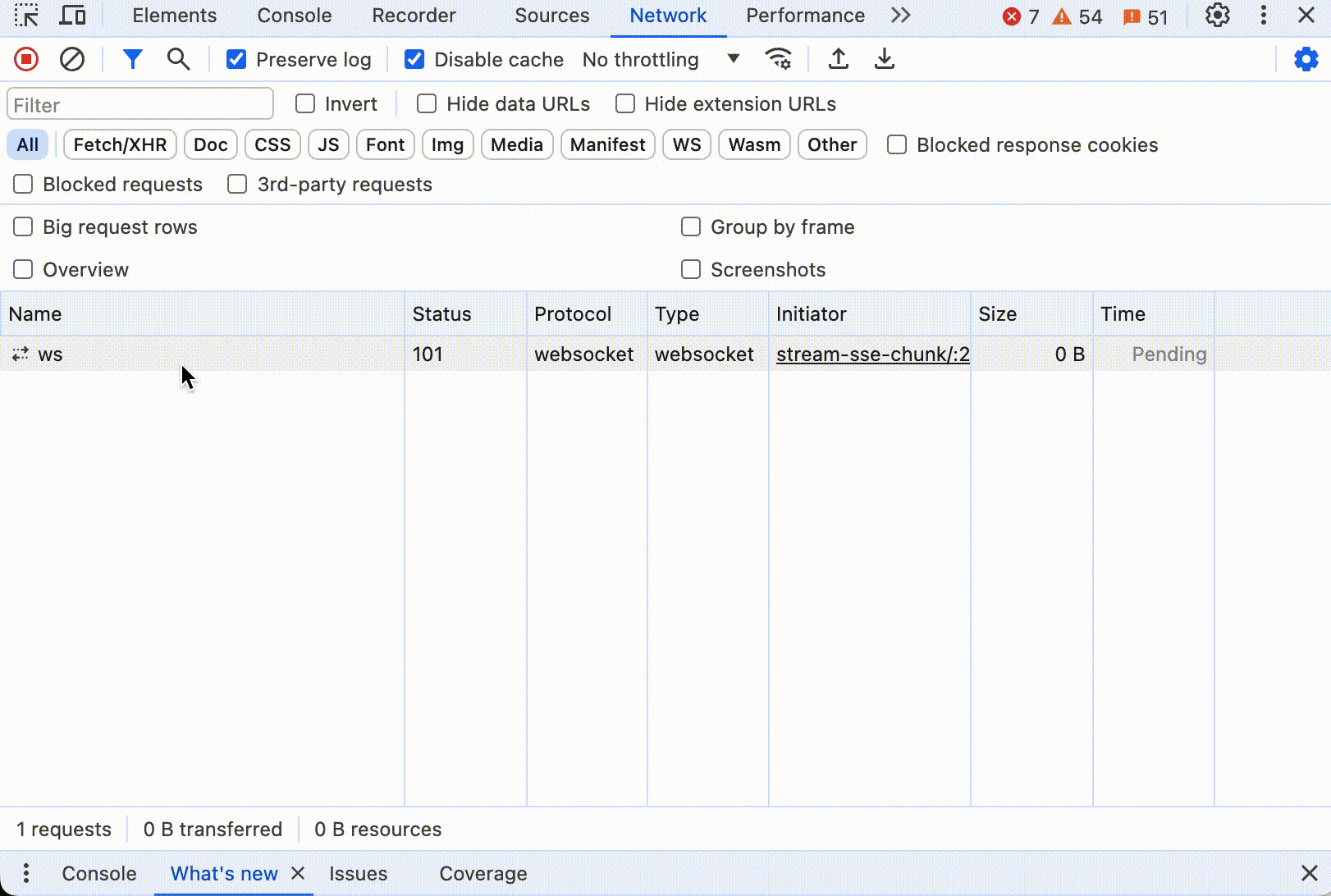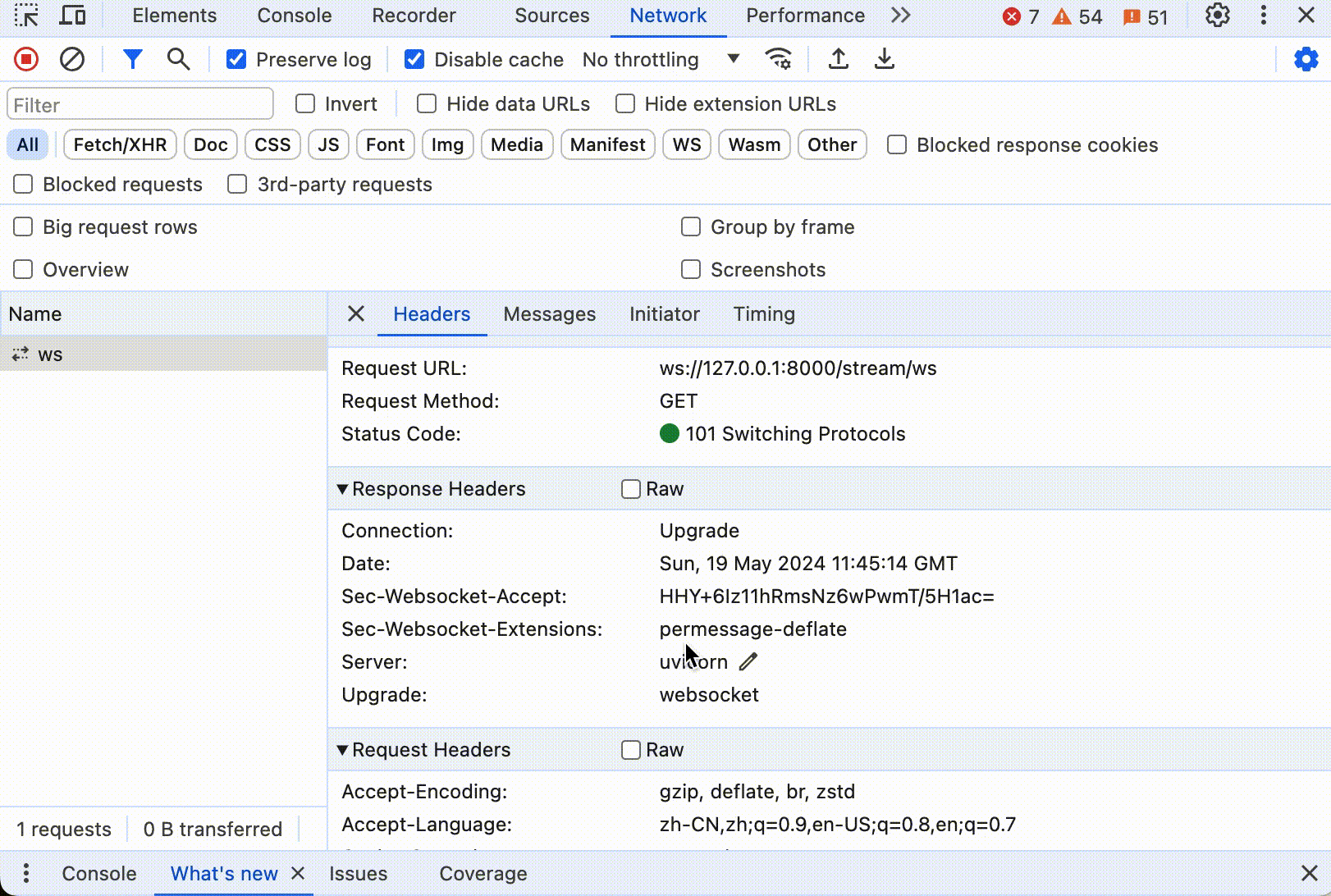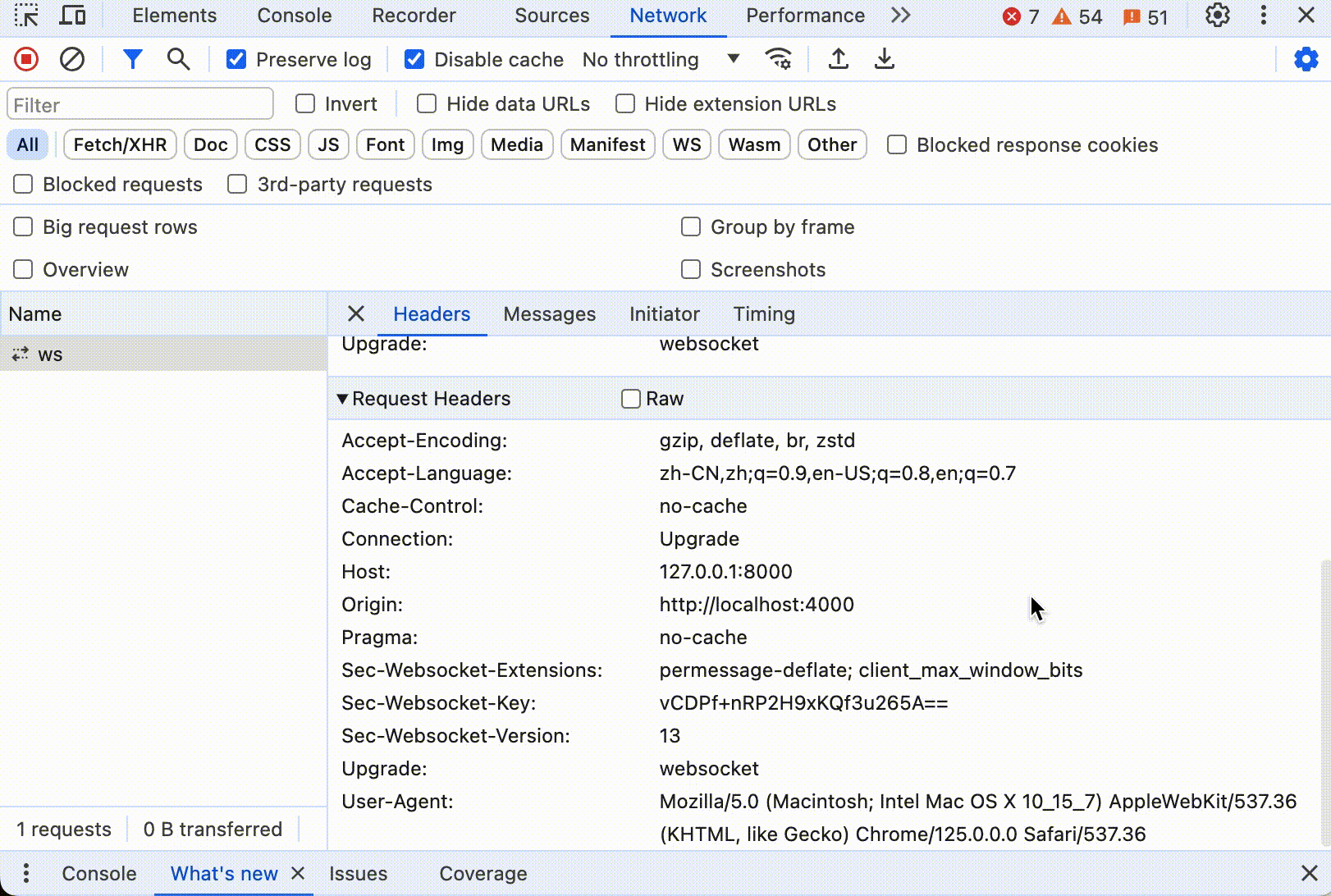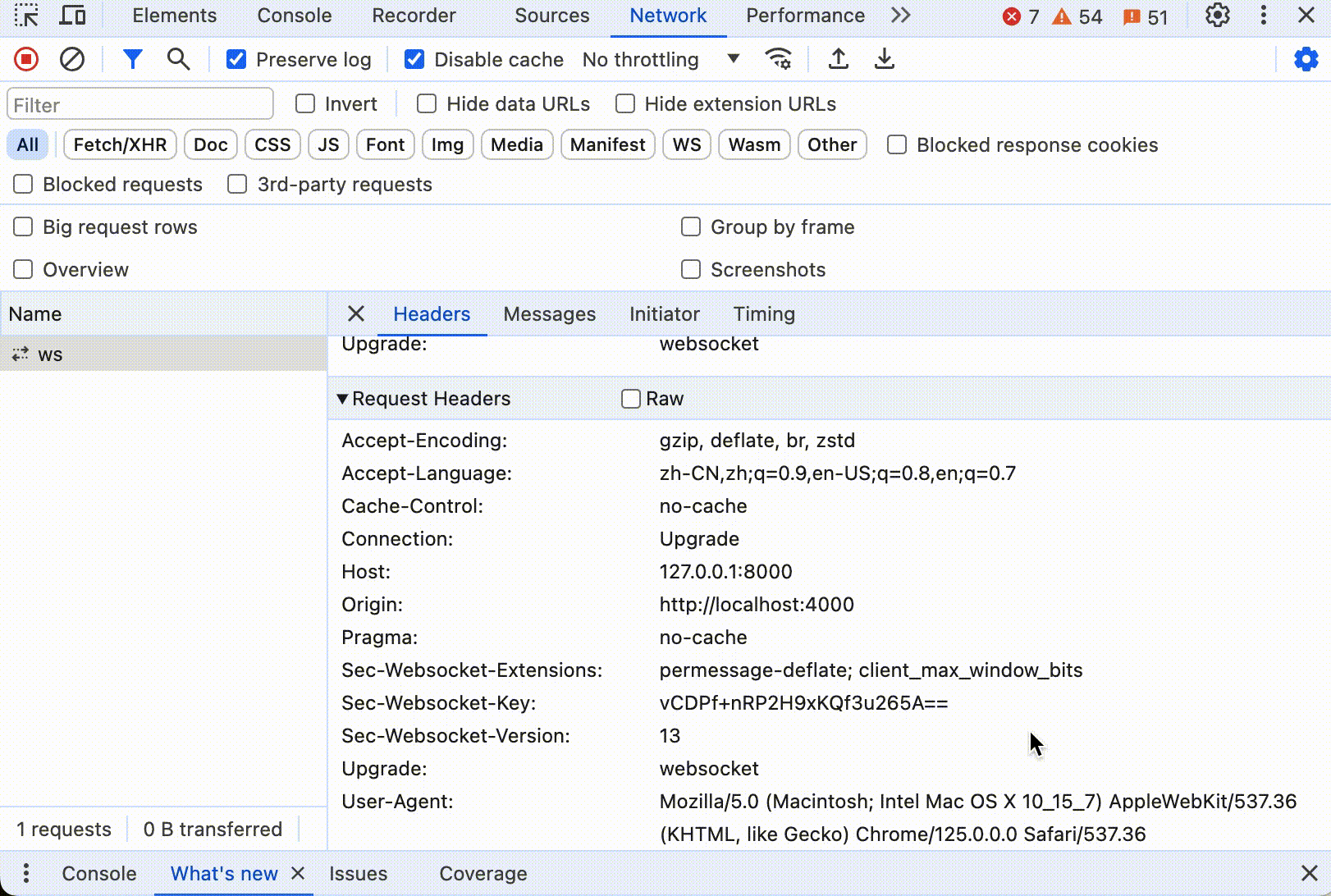
WebSocket 也是基于 TCP 协议实现,具体的协议由 IETF 的 RFC 6455 定义。首先是握手阶段,WebSocket 连接首先通过 HTTP 协议发起,需要客户端发送一个特殊的 HTTP 请求,包含 Upgrade: websocket 和 Connection: Upgrade 头部,请求服务器切换到 WebSocket 协议。如果服务器支持 WebSocket,它会返回一个HTTP响应码 101 Switching Protocols,表示同意切换到 WebSocket。
一旦握手成功,连接就升级到 WebSocket,双方就可以开始通过帧来发送数据。WebSocket协议定义了多种帧类型,用于传输数据、关闭连接、ping/pong等。WebSocket协议支持文本和二进制消息,允许消息在一个帧内发送完或者分片发送。
在 Python 中用 FastAPI 实现 Web Socket 服务端如下:
1 |
|
这里是 Web Socket 的交互式展示:
这里开始后,在控制台可以看到 WebSocket 中传输的数据。Chrome 的开发者工具,有个 message 状态栏,可以看到整个全双工通信过程中的数据内容。下面是整个过程动态图:
当然,WebSocket 协议相对 HTTP 更复杂,需要服务器和客户端都实现更多的逻辑。
本文结合具体的例子,介绍了 4 种常见的实现流式输出的方法,每种方法都有自己的优缺点,适用于不同的场景。以下是一些建议:
- 针对简单的单向推送场景,如新闻实时更新、股票行情等,可以考虑使用 Server-Sent Events。实现简单,支持主流浏览器,且能有效节省服务器资源。
- 对于需要双向通信的交互场景,如即时通讯、协作办公、在线游戏等,WebSocket 是更合适的选择。全双工通信,支持文本和二进制数据,延迟较低。但需要客户端和服务器端均实现 WebSocket 协议逻辑。
- 如果对延迟要求不太高,可以考虑使用轮询或分块传输编码。轮询实现最简单,但频繁请求会增加服务器负担。分块传输编码效率更高,无需频繁建立连接。
- 对于需要向老旧浏览器提供支持的应用,轮询可能是唯一可选方案,因为旧版本浏览器可能不支持 WebSocket 或 Server-Sent Events。
总的来说,流式输出在现代 Web 应用中得到了越来越广泛的应用。特别是大语言模型兴起之后,几乎所有的文本生成应用,都是用流式输出来提升用户体验。

