溢出、异常、线程池、阻塞,奇怪的服务重启问题定位
最近在业务中遇见一个很奇怪的服务重启问题,定位过程比较有曲折,本文来复盘下。这个问题涉及到 C++ 线程池、整数溢出、异常捕获、阻塞等多个方面,还是挺有意思的。
接下来我会按照问题排查的过程来组织本文内容,会先介绍问题背景,接着列出初步的排查思路,定位异常请求的方法。然后,通过代码分析,以及复现问题的一些简单用例,来揭开服务重启的神秘面纱。
问题背景
我们有个模块 A 对外提供 RPC 服务,主调方 B 会调用 A 的服务。模块 A 的服务分为 2 个进程,mesh 进程和业务进程,这两个进程都是多线程的。mesh 进程类似 Sidecar 的作用,每当接收到主调方发来的 1 个 rpc 请求,就分配一个 worker 线程负责该请求。worker 会通过 unix socket 把请求包发给业务进程,然后等业务进程处理完后回复主调方。业务进程则专门用来做业务逻辑,拿到请求包处理完成后,把响应包给 mesh 进程里的 worker。整体如下图所示:
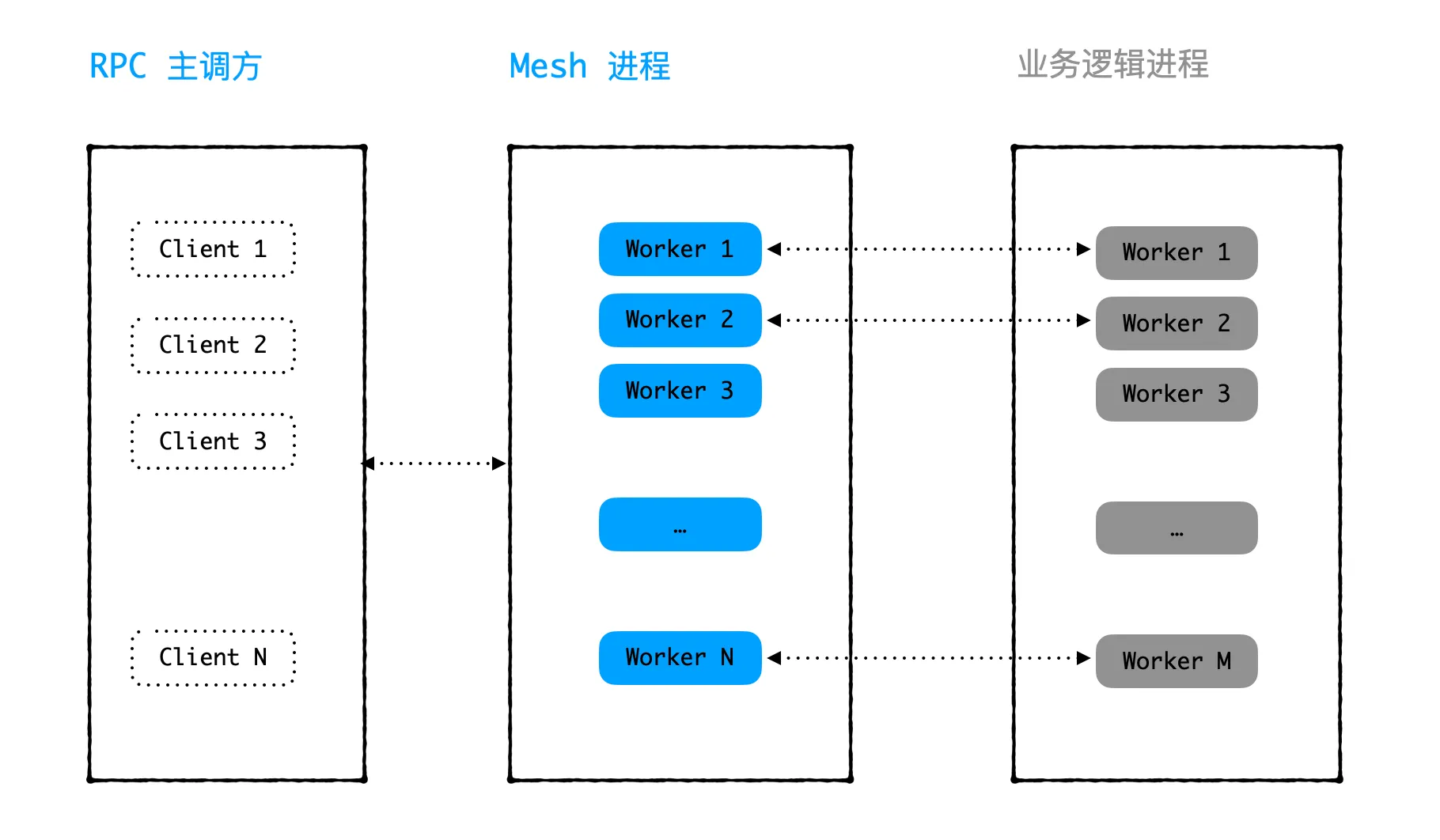
最近,主调方 B 通过监控发现每天会有几次连不上模块 A 的服务端口,每次持续时间也不长,过一会就自动恢复了。
简单看了下模块 A 的日志,发现在对应时间点,监控脚本拨测 A 服务失败,于是重启服务。这里的监控脚本每隔固定时间,会拨测模块 A 的 存活探测 rpc(就是简单回复一个 hello),来检测服务是否正常。如果连续的几次拨测都失败,则认为服务有问题,就尝试重启服务。这次模块 A 的偶现重启,就是脚控脚本发现一直没法拿到存活探测 rpc 的回复,于是重启服务。
那么**什么时候开始出现这个问题呢?**把模块 A 的监控时间拉长,发现 7 天前才开始有偶现的诡异重启。模块 A 的每台服务器都有重启,重启频次很低,所以模块 A 也没有告警出来。
按照经验,拨测失败一般是服务进程挂了,比如进程 coredump 退出或者内存泄露导致 OOM 被系统杀了。但是查了下模块 A 的日志,发现并不是上面两种情况。模块 A 没看到 coredump 相关的日志,内存使用在重启时间段都是正常的。那会不会是代码中有死循环导致 worker 线程被占着一直没法释放呢?看了下重启时间段的 CPU 使用率,也是正常水平。当然如果死循环中一直 sleep,那么 CPU 使用率也不高,不过业务中并没有什么地方用到 sleep,所以这里初步排查不是死循环。
这就有点奇怪了,接着仔细看服务日志来排查吧。
初步排查
找了一台最近有重启的机器,先看看重启时间点服务进程的日志。模块 A 里 mesh 进程是一个 C++ 多线程服务,一共有 N 个 worker 线程并发处理业务的 RPC 请求。框架每隔一段时间,会打印日志,记录当前 worker 中有多少是空闲(idle)的,多少正在处理请求(busy)。正常情况下,打印出来的日志中,大部分线程是 idle 的,只有少部分是 busy。
但是在进程重启前,发现日志中的 worker 线程数有点异常,1 分钟内 idle 线程越来越少,直到为 0。假设总 worker 数为 200,重启前的相关日志大概如下:
1 | worker idle 100, busy 100; |
怪不得监控脚本会拨测失败,此刻服务的所有 worker 都被占用,没有空闲 worker 处理新来的请求,所有新来的请求都会排队等待 worker 直到超时失败。
那么是什么原因导致 worker 一直被占用没有释放出来呢?服务是最近才出现这个问题的,所以首先想到可能和最近的变更有关。把最近的代码变更看了下,没发现什么问题。
接下来其实有两个排查思路,第一个是等服务进程再次卡住的时候,通过 gdb attach 进程,或者 gcore 转储 coredump 文件,这样就可以查看 worker 线程的调用栈,看看是什么函数导致 worker 一直被占用。首先排除掉 gdb attach,第一是出现概率比较低,监控脚本会很短时间内重启服务,不太好找到时机,并且现网服务也不太适合 attach 上去排查问题。gcore 的话,需要改动下监控脚本,在拨测有问题的时候,保存下进程 coredump 文件。不过当时考虑到需要改监控脚本,并且通过 coredump 文件不一定能发现问题,所以暂时没采用。
第二个思路就是找到可以复现的请求,通过复现问题来定位,毕竟如果一个问题能稳定复现,相当于已经解决了一大半。这里其实基于这样一个假设,一般偶发的问题,都是由某类特殊的请求触发了一些边界条件导致。
对于我们的 RPC 模块来说,如果有一个特殊的请求导致 worker 一直被占用,那么这个请求一定是没有回包的。因此,我们可以在模块接收到请求包以及给出响应包的时候,分别打印出相关日志。然后在服务卡住的时间段,就可以过滤出日志中那些只有请求没有响应的 RPC 请求。
加了日志上线后,刚好又一次出现了服务重启,通过日志,终于找到了可疑请求。结合这个可疑请求,发现了一段有问题的代码,正是这段有问题的代码,成为解决问题的突破口。
问题代码分析
我们先来看下这段有问题的代码,简化后并隐去关键信息,大致如下:
1 | int func() { |
聪明如你,一定发现这段代码的问题了吧。
这里 i 是无符号整数,posVec.size() 返回的也是无符号整数类型 size_t。当 posVec.size() 小于 gramCount 时,posVec.size() - gramCount 会溢出,变成一个很大的正整数。接着在循环中,会用这个很大的正整数来遍历 posVec,就会导致数组越界。这里用 operator[] 访问数组的时候,当下标越界就是未定义行为,一般会导致程序 crash 掉。写了一个简单测试代码,发现确实 segmentation fault 了。这里补充说下,如果是用 at 访问数组的话,下标越界会抛出 out_of_range 异常,如果被捕获异常,肯定会 crash。
但是模块 A 中这里的代码却没有 crash,而是导致 worker 线程一直被占用,这又是为什么呢?一个可疑的地方就是,上面的代码其实是在一个新开的线程池中跑的。再补充说下这里的背景,模块 A 收到 RPC 请求后,会在一个 worker 线程中处理业务逻辑。有部分业务逻辑比较耗时,为了提高处理速度,会把耗时的部分放到一个额外的线程池来并发执行。
这里线程池的实现稍微有点复杂,大致思路就是一个任务队列 + 配置好的 N 个 worker 线程。任务队列用来存放需要执行的任务,worker 线程从任务队列中取任务执行。线程池对外提供了一个接口 RunTask(concur, max_seq, task); 其中 concur 是并发执行的线程数,max_seq 是任务总数,task 是任务函数。RunTask 会用 concur 个线程并发执行这个任务函数 task,直到 max_seq 个任务全部完成。
在任务开始前,RunTask 里面定义了一个管道,用来在主线程和任务线程池之间同步消息。一旦所有线程完成任务,最后一个退出的线程会向管道写入一个字符以通知主线程。主线程会等待管道中的字符,然后返回。
上面有整数溢出的代码,就是放在这个额外的线程池执行的,难道是线程池导致的问题?为了快速验证猜想,写了个简单的测试脚本,把上面代码放到线程池执行,进程果真卡住没反应了。首先猜想,会不会是线程池中的线程因为数组越界导致 crash 掉,没有写 pipe,导致主线程一直阻塞在 pipe 的读操作上呢?
下面来验证下。
多线程:thread
为了验证上面的猜想,写了一个简单的测试程序,模拟业务中线程池的工作流程。这里用 C++11 的 thread 来开启 5 个新线程,并且让这些线程 sleep 一段时间模拟执行任务。当所有线程都执行完任务后,最后一个完成的线程向管道写入一个字符,主线程阻塞在管道读取上。测试代码如下:
1 |
|
运行后发现这里是符合预期的,5 个线程并发执行 1s,主线程等最后一个线程执行完,就会从管道中读到结果继续往下执行。结果如下:
1 | Main thread started Thread ID: 140358584862528 - 2024-06-12 11:40:51 |
现在让最后一个子线程直接抛出异常,来看看主线程是否阻塞。在上面代码基础上改动如下:
1 | //... |
重新编译运行发现整个进程直接 crash 掉了,结果如下:
1 | Main thread started Thread ID: 140342189496128 - 2024-06-12 11:46:23 |
看来前面的猜想失败了!在多线程下,单个线程抛出异常导致整个进程 abort 掉了。为什么会这样?这里不得不提一下C++ 的异常处理机制了?
C++ 异常处理
在 C++ 中,当程序遇到一个无法自行解决的问题时,它可以抛出(throw)一个异常。异常通常是一个从标准异常类派生的对象,如 std::runtime_error。编程时,可以把可能抛异常的代码放到 try 块里面,然后在后面跟一个或多个 catch 块,用来捕获和处理特定类型的异常。
如果在当前作用域内没有捕获异常,异常将被传递到调用栈中较高层的 try-catch 结构中,直到找到合适的 catch 块。如果整个调用栈都没有找到合适的 catch 块,会调用 std::terminate(),具体执行操作由 std::terminate_handler 指定,默认下是调用 std::abort。如果没有设置信号处理程序捕获 SIGABRT 信号,那么程序就会被异常终止。
对于上面的示例多线程代码来说,最后一个线程抛出异常,但是没有地方捕获,所以最终调用 std::abort() 终止整个进程。从上面的输出也可以看到,最后一行是 abort。
其实 C++ 之所以这样设计,是因为一个未捕获的异常通常意味着程序已经进入一个未知的状态,继续运行可能会导致更严重的错误,如数据损坏或安全漏洞。因此,立即终止程序被认为是一种安全的失败模式。
thread 对象生命周期
这里再提一个地方,上面示例程序,主线程最后会对每个子线程的 thread 对象调用 thread.join(),如果把这里注释掉,运行程序会发生什么呢?进程还是会 crash 掉,并且也是调用的 terminate()。这又是为什么呢?
其实前面 terminate 的文档里有提到,下面这种情况也会调用 terminate:
- A joinable std::thread is destroyed or assigned to.
接着继续查看 std::thread::joinable 的文档,发现如下解释:
A thread that has finished executing code, but has not yet been joined is still considered an active thread of execution and is therefore joinable.
我们知道,子线程在执行完相关代码后会自动退出。但是,这并不意味着与该线程相关联的 std::thread 对象会自动处理这个线程的所有资源和状态。在 C++ 中,操作系统线程的结束和 std::thread 对象的生命周期管理是两个相关但又相对独立的概念:
- 操作系统的线程:当线程执行完代码后会自动停止,此时线程的系统资源(如线程描述符和堆栈)通常会被操作系统回收。
- std::thread 对象的管理:虽然线程已经结束,但是 std::thread 对象依然需要正确地更新其状态来反映线程已经不再活跃。这一点主要是通过 join() 或 detach() 方法来实现的。如果没有调用这些方法,std::thread 对象在被销毁时将检测到它仍然“拥有”一个活跃的线程,这将导致调用 std::terminate()。
前面示例代码中主线程调用 join() 方法,会阻塞等待子线程执行完(其实就这里的例子来说,管道写入字符已经确保执行完了的),然后标记 std::thread 对象状态为“非活跃”。
那么回到前面的问题,为啥业务代码中线程池中的线程抛出异常,主线程会卡住呢?接着仔细看了下线程池的实现代码,发现这里并不是用 thread 来创建线程,而是用的 std::async。async 是什么?它是怎么工作的,这里线程卡死会和 async 有关吗?
接着一起来验证吧。
多线程:async
C++11 引入了 std::async,这是一个用于简化并发编程的高级工具,它可以在异步的执行上下文中运行一个函数或可调用对象,并返回一个 std::future 对象来访问该函数的返回值或异常状态。
哈哈,看完这里的介绍,是不是一头雾水、不知所云?没事,先抛开这些,直接看代码先。我们在前面 thread 示例代码的基础上,稍加改动,用 async 来并发执行,完整代码如下:
1 |
|
运行后发现,主线程卡住了!!运行结果如下:
1 | Main thread started Thread ID: 140098007660352 - 2024-06-12 21:06:00 |
成功复现了业务中的问题。在继续深入分析前,先来看看 async 的用法,主要如下:
1 | int totalThreads = 5; |
上面代码用 std::async 函数来启动一组异步任务,这些任务由 threadFunction 定义。每个任务在创建时都被配置为在新线程上执行,并且使用 std::launch::async 策略来确保它们会立即启动。这些任务的执行结果(或状态)被封装在 std::future
GDB 分析
我们用 GDB 来看看进程运行过程发生了啥。这里 run 之后,可以看到新创建了 5 个线程来执行 async 任务,接着有 4 个线程都打印了任务输出,然后 5 个线程又全部被系统销毁。之后 GDB 控制台会卡住,这时候用 Ctrl+C 来暂停程序执行,然后就可以用 GDB 控制台了。
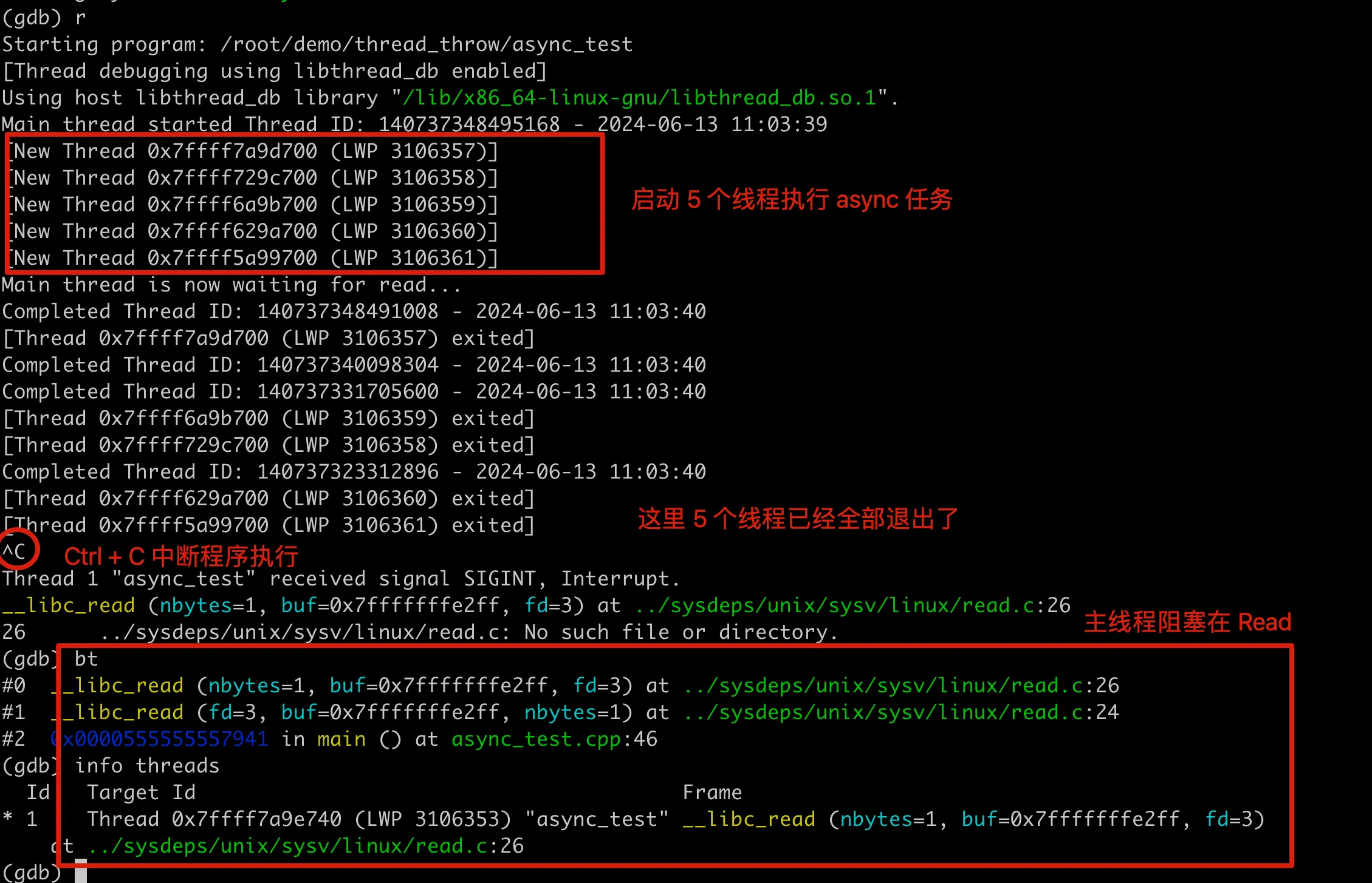
进程卡住后看堆栈,发现阻塞在主线程 main 函数的 read 上。这时候进程只剩下主线程,可以用 info threads 确认,这里 0x7ffff7a9e740 其实就是进程开始打印出的 Thread ID: 140737348495168 的十六进制。从 GDB 的结果来看,最后一个子线程在要 write 前抛出异常,然后直接退出,没有往管道写入字符,主线程一直阻塞在管道的 read 中。
问题来了,整个进程不是应该 abort 终止吗?在前面 thread 的示例 中,线程抛出的异常没被捕获导致进程 abort 掉,主线程也随之结束。而这里 async 创建的线程抛出的异常似乎不见了,没看到有捕获的地方,也没有触发进程 abort,这是为什么呢?
async 异常处理
先来看看 async 的文档里有没有说是怎么处理异常的吧。
If the function f returns a value or throws an exception, it is stored in the shared state accessible through the std::future that std::async returns to the caller.
可以看到,使用 std::async 启动的线程如果抛出了异常,这些异常会被捕获并存储在返回的 std::future 对象中。再查看 future 的文档,发现可以用 future::get 来拿到任务的执行结果,如果任务抛出异常,调用 get 的时候会重新抛出异常。
If an exception was stored in the shared state referenced by the future (e.g. via a call to std::promise::set_exception()) then that exception will be thrown.
至此上面示例程序没有 abort 的原因找到了,就在于 async 的异常处理机制。在 async 中,线程抛出的异常会被存储在 std::future 对象中,而不会直接导致进程 abort。子线程抛出异常后没有往管道写入字符,主线程就一直阻塞在 read 上等待,导致整个进程看起来就跟卡住一样。
这里我们可以在示例程序 read 前调用 get 来捕获异常,然后打印出来验证下。
1 | // ... |
可以看到这里确实捕获到了一个 out_of_range 异常。
async 的优势
关于 async 再补充一点思考,C++11 引入的 async 和传统的 thread 比有什么优点呢?
首先 std::async 提供了一种比直接使用 std::thread 更简单的方法来创建并执行异步任务。它自动处理线程的创建和管理,使得开发者可以专注于业务逻辑而非线程管理的细节。std::async 可以自动管理任务的生命周期,包括适时地启动和终止线程。使用 std::async 不需要显式地调用 join() 或 detach()。
另外,如前面所述,使用 std::async 启动的任务可以在执行中抛出异常,这些异常会被捕获并存储在返回的 std::future 对象中。通过调用 std::future::get(),可以在主线程中捕获和处理这些异常。
此外,调用 std::async 可以指定启动模式(std::launch::async 或 std::launch::deferred),其中 std::launch::async 强制立即在新线程中运行任务,而 std::launch::deferred 则延迟任务的执行直到调用 std::future::get() 或 std::future::wait()。
一般来说,当需要并行执行且彼此之间没有依赖关系的任务时,用 std::async 不需要关注线程的管理,会简单很多。或者需要在将来的某个时间点获取并行任务的执行结果,可以将 std::async 与 std::future 结合起来用,也会方便很多。
现网服务复盘
好了,现在回到现网服务的讨论,通过前面分析已经能确定问题所在了,不过还有几个和现网服务相关的细节这里也需要搞清楚。第一个就是这里出问题的代码早就上线了,为什么最近才出问题?回到问题代码分析这里的示例,如果数组大小大于等于 gramCount,就不会溢出,也不会导致 crash。最近这里数组的长度有了变化,所以才出现上面的问题。
第二个疑问就是,每次遇到异常的数据,只会卡住当前的 1 个工作 worker,短时间也不会有很多异常请求数据。但是前面初步排查的时候观察日志,在极短时间内,所有 worker 都耗尽。这又是为什么呢?
前面问题背景有提到过,mesh 进程和业务进程都是多线程,日志中看到短时间极速减少的 idle worker,是 mesh 进程的。实际业务逻辑在业务进程处理,业务进程中的所有线程共用一个 async 单例实现的全局线程池。async 实现的线程池在创建单例对象的时候会指定一共有多少个线程,这些线程供所有业务进程 worker 线程使用。整体如下图所示:
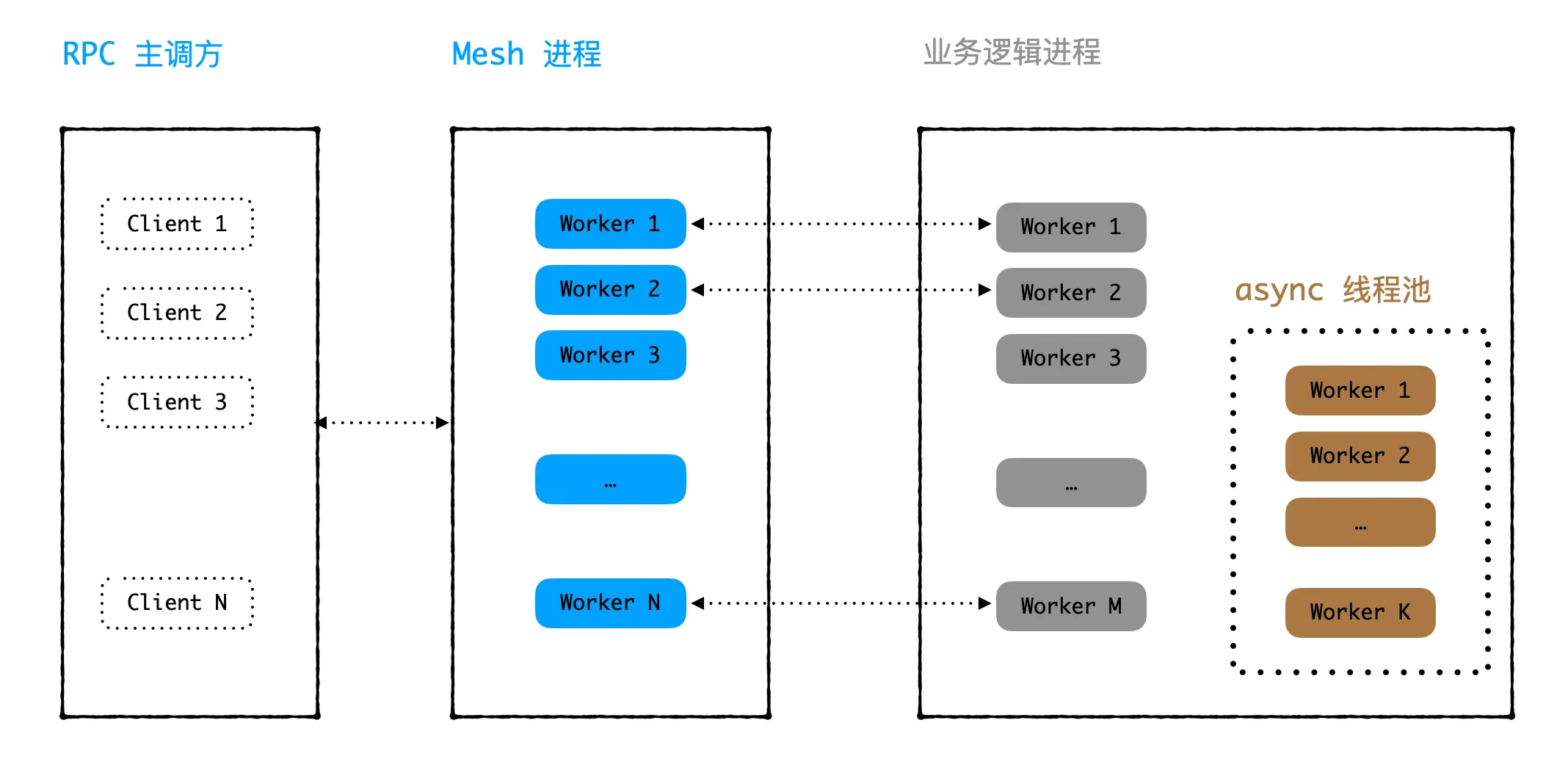
每当有一个异常数据,就会导致 async 线程池中的 1 个线程退出,同时阻塞业务进程中的 1 个线程。随着时间推移,积累足够多异常数据后,会出现下面 2 种情况:
- async 线程池中的线程因为异常全部退出,这时候还没有阻塞的业务线程只要使用线程池处理数据,不管数据是否异常,都会阻塞在 read 上,因为根本没有 async 线程来计算。这种情况发生在业务进程的线程数大于 async 线程池中的线程数时。
- async 线程池中还有可以工作的线程,不过业务进程中所有线程都因为曾经出现的异常数据导致阻塞在 read 上。这种情况发生在业务进程的线程数小于 async 线程池中的线程数时。
不管是哪种情况,都会在某一刻,因为最后的一个异常请求数据,导致业务进程所有工作线程阻塞,无法处理 mesh 来的请求。从这一刻起,每当 mesh 接收到一个请求,mesh 进程的一个 worker 就会被占用,短时间内的请求积压,导致 mesh 进程所有 worker 被占用,也就无法处理新来的请求,最终导致监控脚本检测到服务异常。
至此,整个重启的原因水落石出,修复方法也跃然纸上了。最简单的方法就是在 async 线程中执行业务函数时,加上 try-catch 块,如果捕获到异常,直接调用 abort 来中止整个业务进程。这样如果代码中有导致抛出异常的 bug,上线后一旦触发进程就会立马终止,出问题早发现,也方便从 coredump 文件中分析问题。

