实际例子上手体验 OpenAI o1-preview,比预期差一点?
OpenAI 半夜悄咪咪推出了新的模型,introducing-openai-o1-preview。放出了系列视频,展示新模型的强大,网上也是普天盖地的文章来讲新模型测评有多厉害。不过见惯了 AI 界的放卫星,怀着怀疑的态度,第一时间上手体验一把。
汉语新解
刚好最近李继刚有个提示词很火,可以生成很好玩的汉语新解。用 Claude3.5 试了效果特别好,下面是一些 Claude 生成的 SVG 图:

这个提示词特别有意思,用经典编程语言 Lisp 来描述要执行的任务,大模型居然能理解,还能生成稳定、美观的 SVG 图。这个提示词很考验模型的理解和生成能力,试了 GLM 和 GPT-4o,都不能生成符合要求的 SVG 图。目前只有在 Claude3.5 上稳定输出,效果也很好,那么 OpenAI 的最新 o1-preview 模型如何呢?
我们直接输出提示词,接着输入词语,结果如下图:

这里没有输出 svg,给出了一个 markdown 格式的输出。然后新的模型有个比较有意思的地方,这里有个“思考”,会显示思考多长时间,然后点击后可以看到思考的过程。
看起来模型也能理解提示词,只是输出有点问题。Claude3.5 是因为有 Artifacts 能力,所以可以直接输 SVG 格式图片。这里我们可以直接提示 o1-preview 生成 SVG 源码,于是提示词稍详细下,约束下输出格式,如下:
生成 svg 源码:宇宙
这次终于给出了一个 SVG 源码,生成了“宇宙”的汉语新解图。接着我想着模型已经理解了我的意图,于是直接输入“数学”,结果模型还是给了一开始的 markdown 输出了。每次必须在词语前面明确提示”生成 svg 源码” ,才能输出想要的 SVG 格式。下图是三个词的输出效果,可以对比前面 claude3.5 的结果。
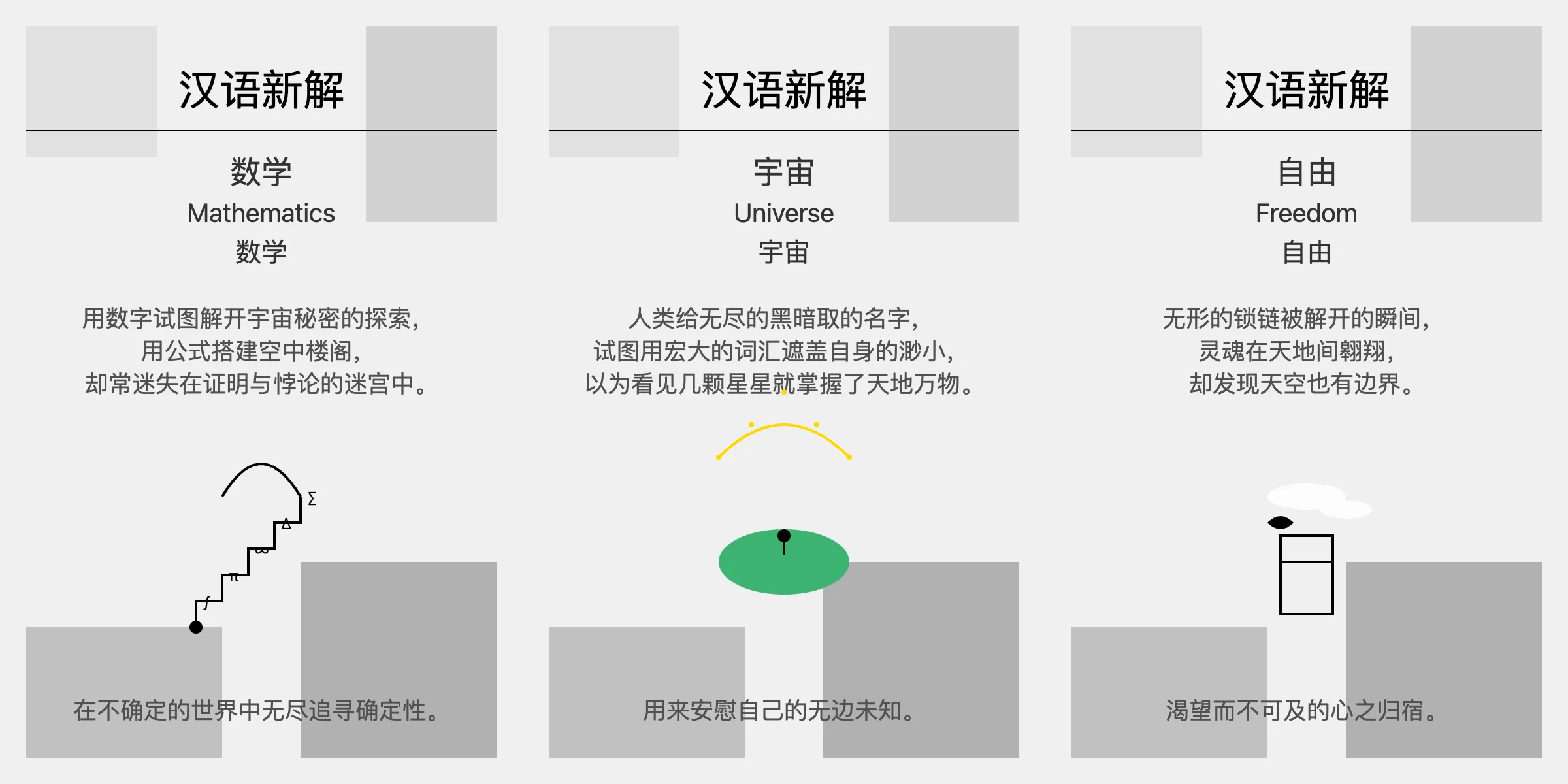
个人感觉 Claude3.5 生成的图更简洁美观些,o1-preview 生成的图有点粗糙。并且文字内容上,Claude3.5 的也更有深意,gpto1 的有点直白。
代码理解能力
OpenAI 的新模型着重强调说写代码和理解代码能力很强,这个我可是太需要了。最近刚好在看 LevelDB 源码实现,跳表这里的测试用例写的有点复杂,代码虽然不多,但是理解起来有点费劲。
之前试过用 GPT4 和 Claude3.5 来解读,虽然也给了不少帮助,但是有些疑问还是没能得到让我信服的解答。刚好可以拿来给 o1-preview 模型来解读下。开始解决疑问之前,先让他读了这里并发测试的代码,看他怎么理解。提示词:
这里是 LevelDB 跳表的并发测试代码,帮我分析这段代码,然后告诉我这里的测试实现优点。
// We want to make sure that with a single writer and multiple
// concurrent readers (with no synchronization other than when
…
提示的时候是给了完整代码,这里先省略后面的代码部分。模型给的结果还算可以,比之前 Claude3.5 的稍微好一点。分为几个部分分析了这里的代码,包括关键数据结构和概念,核心方法,并发测试的执行流程,最后总结了测试代码的优点。这里摘录小部分:
1 | 3. 并发测试的执行流程 |
然后就是我的疑问:
这里 K 的值现在是 4,为什么设计这么小的 1 个值呢? 这个值会影响到测试的哪部分
接下来 gpto1 就开始胡说八道了。
1 | K 的值被设置为 4,这是一个很小的值,目的是为了在测试中增加对同一组键的访问冲突,从而更有效地检测并发环境下可能出现的问题。 |
这里接着提示:
不对不对吧!这里 K 只是影响最终键值的前 24 位而已,插入链表的键值还有其他gen 和 hash位,这些都不会重复的呀
这次模型思考时间比较久,思考过程比较有意思,如下:

但是给的结果也并不能说服我,又接着继续追问:
为什么一定要引入 K 值呢? 直接用 gen 和 hash 不就能测试了吗?
另外,就算引入 K 值,取值 0 到 4,为啥要给 24 位呢?
回答似乎又回到前面的套路上了,始终没有给出有价值的观点。当然这里的疑问,Claude3.5 也不能给出很好的答案,我自己暂时也还没想出一个很好的解释。可能只是 LevelDB 作者随手设计的,并没有什么道理在里面?欢迎评论区留下自己的看法哈。
这里还没来得及测试代码生成能力,已经没有额度了。根据 OpenAI 的文档,目前 o1-preview 每周是限制 30 条消息,o1-mini 每周 50 条。后面有额度后,会继续尝试这里的新模型,更新本文,争取给出全面的测评。
再谈模型效果
最近这一年以来,不断有各种新模型涌现出来,时不时声称在评测集上评分又创新高。但是从实际体验来看,不少模型的能力还是比较一般,有些甚至是不能用。大模型公司似乎热衷于跑分,热衷于夸大模型的能力,就算是 Google 和 OpenAI 也不能免俗。Google 之前放出的 Gemini 宣传视频被爆是剪辑过的,OpenAI 的 GPT4o 多模态很多官方例子我现在都不能复现。
评价一个模型的能力,最后还是得靠自己上手多体验才行。最近我已经很少用 GPT 了,写代码和日常任务都是用 Claude3.5,不管是代码生成,还是文本理解等,感觉比其他模型要好不少。写代码的话,用 cursor 搭配 Claude3.5,体验好了不少。作为一个 0 基础前端,用 Claude3.5 都能很快做出不少算法可视化,放在 AI Gallery 上,大家可以去体验下。

