5 个导致 C++ 进程 Crash 的真实业务案例
只要你写过比较复杂的 C++ 项目,应该都或多或少遇见过进程 Coredump 的问题。Coredump 是程序运行过程中发生严重错误时,操作系统将程序当前的内存状态记录下来的一种机制。
C++ 中导致进程 Coredump 的原因有很多,比如:
- 访问非法内存地址:包括空指针解引用、访问已释放的内存、数组越界访问等;
- 栈溢出:无限递归、大数组分配在栈上;
- 段错误(Segmentation Fault):试图写入只读内存、访问未映射的内存区域;
- 异常未捕获:未处理的异常导致程序终止;
遇到 Coredump 问题时,一般需要打开 core 文件,然后根据 core 文件来进行问题分析和调试。分析 core 文件有时候还是比较难的,需要对 C++ 的内存模型、异常处理机制、系统调用等有深入的理解。
本文不会过多介绍分析 core 文件的方法,而是通过几个真实项目中的案例,来让大家在写代码时候,能够有意识地避免这些错误。
抛异常没有捕获
业务代码中最常见的导致进程 crash 的原因,就是不小心抛出异常却没有捕获。比如一个字符串转整数的函数中,用了 std::stoi 来转换。但是这里万一字符串没法转成数字,就会抛出 std::invalid_argument 异常。如果框架层或者调用方没有捕获异常,就会导致进程 crash 掉。
就拿标准库来说,可能抛出异常的函数还是挺多的,常见的有:
- std::vector::at():如果访问越界,会抛出
std::out_of_range异常。 - std::vector::push_back():如果内存分配失败,会抛出
std::bad_alloc异常。 - std::map::at():如果访问不存在的 key,会抛出
std::out_of_range异常。
在使用这些可能抛出异常的标准库函数的时候,一定要妥善处理好异常。另外如果是自定义类,不建议抛出异常,可以用错误码来处理。当然对使用异常还是错误码这里一直有争论,可以按照自己比较熟悉或者项目中的惯例来处理就好。如果是明确不抛出异常的函数,可以加上 noexcept 来告诉编译器和使用方。
这里再补充说下,有时候有些函数调用不会抛异常,但是会导致未定义行为,也是可能导致进程 crash 的。比如 atoi 函数,如果字符串没法转成数字,这里会导致未定义行为。未定义行为在某些场景下,会导致进程 crash。
平常在使用一些基础函数的时候,如果对该函数不清楚的话,可以查看 cplusplus 的文档,来确定该函数是否会在某些场景抛异常,是否会导致未定义行为。比如对于 vector :
std::vector::front()
Calling this function on an empty container causes undefined behavior.std::vector::push_back()
If a reallocation happens, the storage is allocated using the container’s allocator, which may throw exceptions on failure (for the default allocator, bad_alloc is thrown if the allocation request does not succeed).
数组下标访问越界
除了抛出异常,还有一类问题也比较常见,那就是数组下标访问越界。我们都知道在 C++ 中访问数组的时候如果下标越界,会导致访问非法内存地址,可能导致进程 crash。你可能会觉得,怎么会数组访问越界?我遍历的时候限制长度就行了呀。
别急,看下面来自业务中的真实例子。当然为了演示,这里简化了很多实际业务逻辑,只保留核心部分。
1 |
|
这里刚开始实现的时候,第一次遍历 src 用来初始化 dest。然后中间有一些其他代码,接着后面又遍历 src,根据 src 的内容对初始化后的 dest 再进行某些处理。
刚开始实现的时候,这样没什么问题,然后某天可能加了个需求,需要过滤掉 src 中某些数据,于是就加了 if 判断来跳过某些内容。改动的人,可能没注意到后面对 src 和 dest 的遍历,没意识到过滤会导致 dest 的长度已经变了。
这个场景有时候比较难触发 coredump,可能只有极少场景才会有过滤导致长度不一样。并且这里就算第二轮访问了越界下标,用 [] 访问的话,也可能不会 core。上面示例代码为了必现 core,故意改成用 at 访问,这样下标越界就会抛异常。
访问失效的迭代器
除了下标访问越界,还有一类问题比较常见,那就是访问失效的迭代器。迭代器是一种设计模式,它提供了一种方法来访问容器对象中的元素,而无需暴露该对象的内部表示。在 C++ 中,迭代器是一个非常重要的概念,它是容器和算法之间的桥梁。
C++ 标准库中,很多容器都提供了迭代器,比如 vector、list、map 等。访问这些容器的迭代器时候,如果迭代器已经失效,就会导致未定义行为,可能导致进程 coredump。
导致迭代器失效的原因有很多,比如 vector 扩容,导致之前的迭代器失效。最常见的一个例子就是删除 vector 中偶数位置的元素,很多新手可能像下面这样写:
1 | for (auto it = numbers.begin(); it != numbers.end(); ++it) { |
这里当调用 erase 删除元素时,会导致删除位置和它之后的所有迭代器都失效。所以循环中接着访问 it 就会导致未定义行为。正确做法是使用 erase 的返回值,来更新迭代器,或者使用 remove_if 和 erase 来删除元素。
当然这个示例比较简单,在实际业务中,我们遇见过一些比较隐蔽的迭代器失效问题。背景是这样,我们有个批处理任务,会用协程池来处理一批 IO 密集的任务,并且把结果写回到一个 vector 中。为了示例,这里代码简化如下:
1 | // 模拟异步任务处理函数 |
这里我们保存了 results.back() 的引用,并在异步任务中使用它。在异步任务执行期间,results vector 继续添加新元素。当 vector 需要扩容时,原有的内存会被释放,新的内存会被分配。此时异步任务中持有的引用就变成了悬空引用,访问它会导致未定义行为。
正确的做法应该是使用 reserve 预分配空间,避免扩容。或者保存索引,使用索引值而不是引用。
并发导致的数据竞争
还有一类 crash 问题,是因为并发导致的数据竞争。经常有这么一个场景,就是服务中有一个后台线程,会从某个配置中心拉取配置更新到本地。然后有多个业务线程,会并发读取这里的配置。
因为是经典的读多写少场景,所以一般会用读写锁来实现。多个读线程可以同时持有读锁,写线程必须独占,写的过程需要保证无其他读或写操作。写操作期间,新的读操作需要等待。一个可能的执行序列如下:
1 | Time ──────────────────────────────────────────────────────▶ |
这里 W 代表一次写入,R 代表一次读取。可以看到,写操作期间,新的读操作需要等待。我们在实际场景中,有遇见过一个 crash 就是错误的使用读写锁。整体比较复杂,下面简化下逻辑,给出核心代码。
1 | class DataManager { |
完整的演示代码在 core_share.cpp 中,感兴趣的可以看下。这里 loadData 中,先准备好配置数据,然后用写锁来更新配置。在 readData 中,则用读锁来读取配置。
看起来没啥问题呀?因为当时是很偶发的 crash,这里业务代码也很久没动过了,只能开了 core 文件来分析。结果 core 的堆栈很奇怪,在 loadData 方法里,localdata 的析构过程发生的 crash。这里 localdata 是局部变量,最后析构前交换了 m_data 和 localdata 的值。那就是 m_data 的数据内存布局有问题了,m_data 只有这里会写,其他地方全部是“读“。
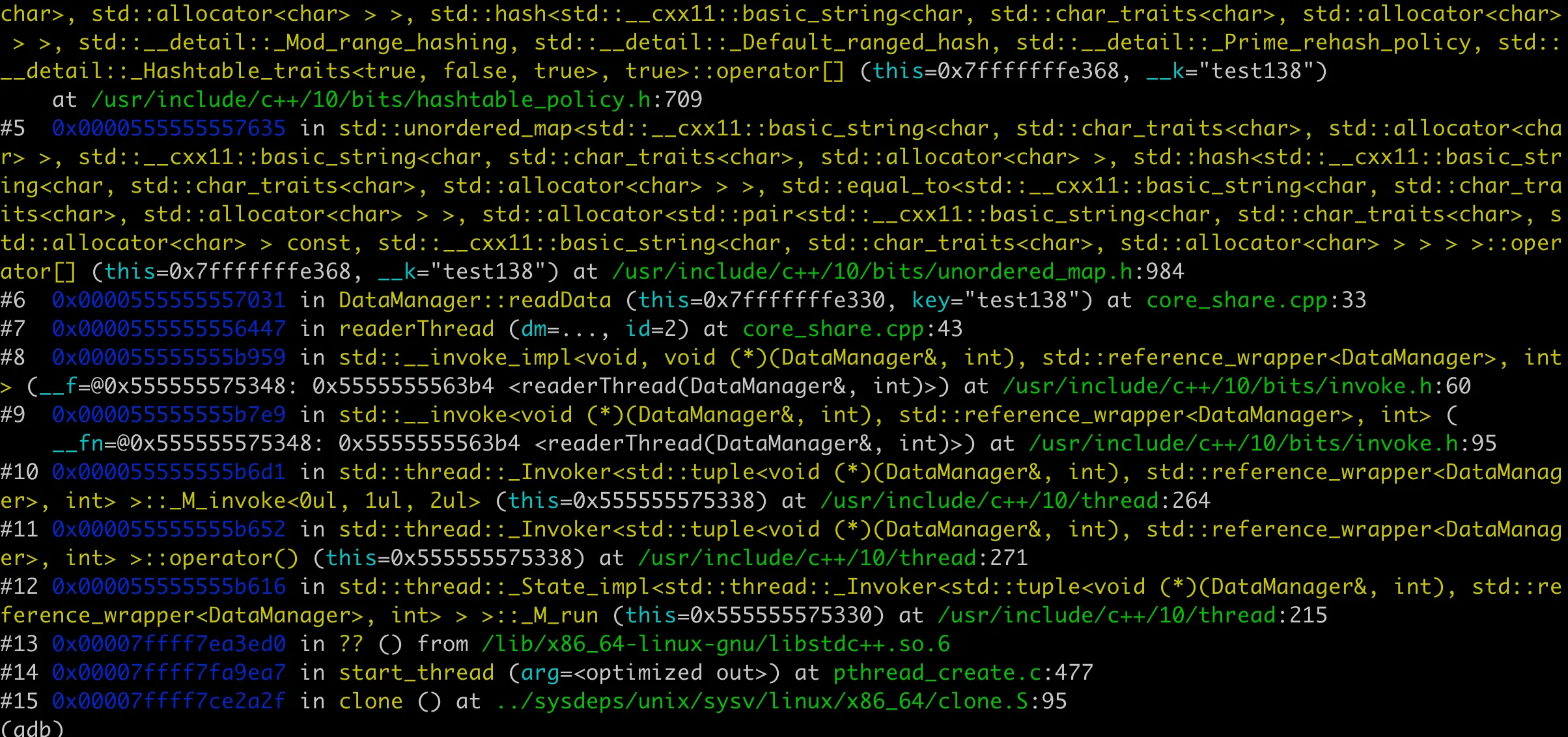
又仔细翻了下业务代码,发现 m_data 读的时候,用了 [] 来拿 unordered_map 的值。对于 unordered_map 来说,如果 key 不存在,[] 会导致插入一个默认值。啊!!这里本来意图是用读锁保护只读操作,结果不小心还执行了写操作。我们知道,并发写 unordered_map 会有数据竞争,怪不得导致 crash。
当然这里 core 的堆栈其实不一定是析构时候,比如示例的代码,堆栈就是在读线程 readData 的时候,如下图:
灾难性回溯导致的栈溢出
上面的示例其实平时多注意的话,还是能避免的。但下面这个,一般人还是很少知道,很容易踩坑。
我们有个地方需要判断字符串中是否有一对括号,于是用了 C++ 的正则表达式。相关代码简化如下:
1 |
|
上面代码中,我构造了一个很长的字符串,然后使用正则表达式来匹配。用 g++ 编译后,运行程序,程序就会 coredump 掉。如果用 gdb 看堆栈的话,如下:
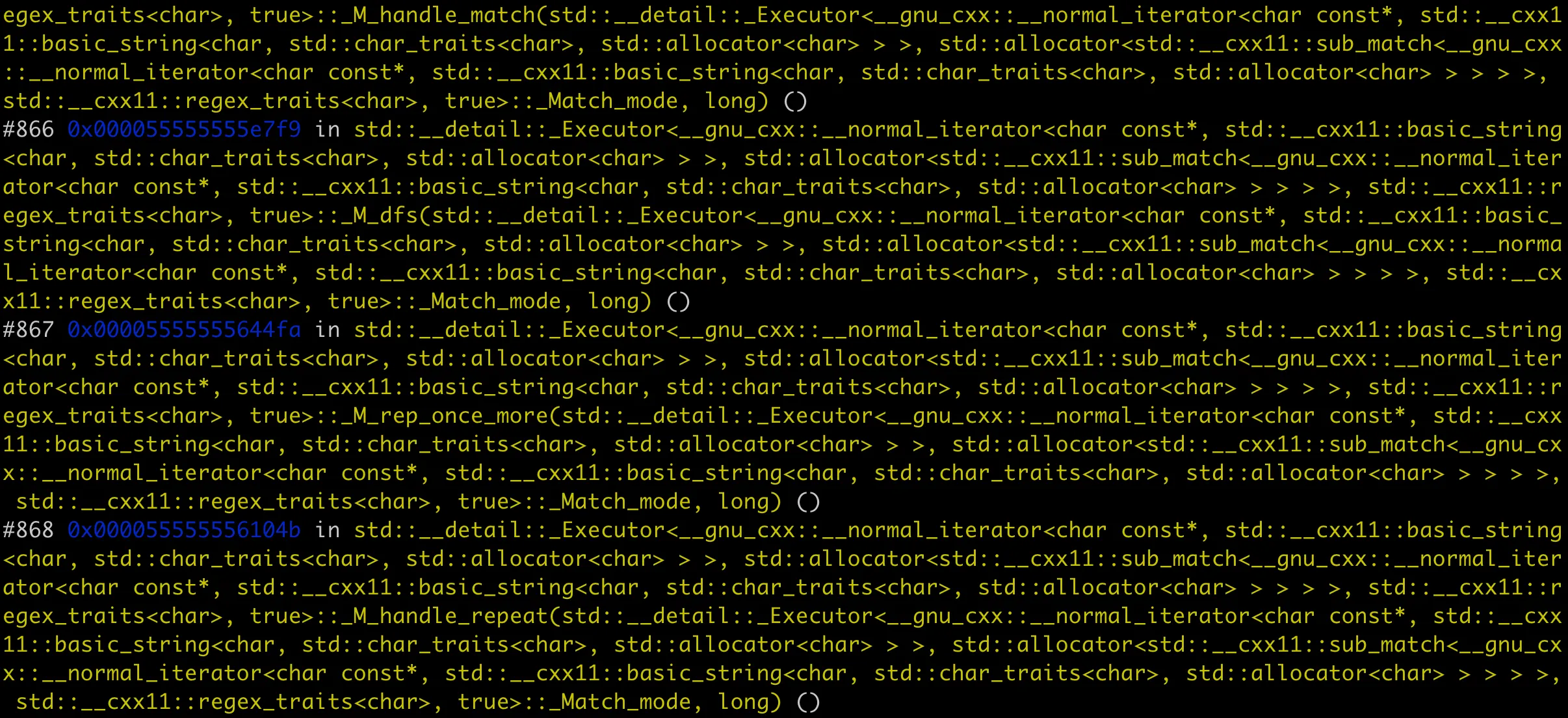
这是因为正则引擎进行了大量的回溯,每次回溯都会在调用栈上创建新的栈帧。导致这里栈的深度特别长,最终超出栈大小限制,进程 coredump 了。
这个就是所谓的灾难性回溯(Catastrophic Backtracking),实际开发中,对于复杂的文本处理,最好对输入长度进行限制。如果能用循环或者其他非递归的方案解决,就尽量不用正则表达式。如果一定要用正则表达式,可以限制重复次数(使用 {n,m} 而不是 + 或 *),另外也要注意避免嵌套的重复(如 (.+)+)。
上面的正则表达式,可以改成:
1 | std::regex re(R"(\([^\)]{1,100}\))"); |
当然除了这里递归回溯导致的栈溢出,还有其他一些场景,比如无限递归、大数组分配在栈上,都可能导致栈溢出。好在栈溢出的话,有 core 文件还是能比较好定位到原因的。
coredump 问题分析
遇到 crash 问题,一般需要打开 core 文件。真实业务环境中,业务进程如果占内存比较大,crash 后保存 core 文件可能会持续比较久的时间。而真实业务中,一般会有守护进程定时拨测业务进程,如果发现业务进程没回应,有的会用 kill -9 来杀死进程并重启。这时候,业务进程的 core 文件可能只写了一半,我们拿到的是不完整的 core 文件。这时候就要修改守护进程,等 core 文件写完再重启进程。
拿到 core 文件后,用 gdb 来分析,如果堆栈比较明确,一般就能很快定位到问题。但很多时候,可能看到的堆栈不完整,是一堆 ??。比如上面访问失效的迭代器,用 gdb 来运行,crash 之后看到堆栈如下:
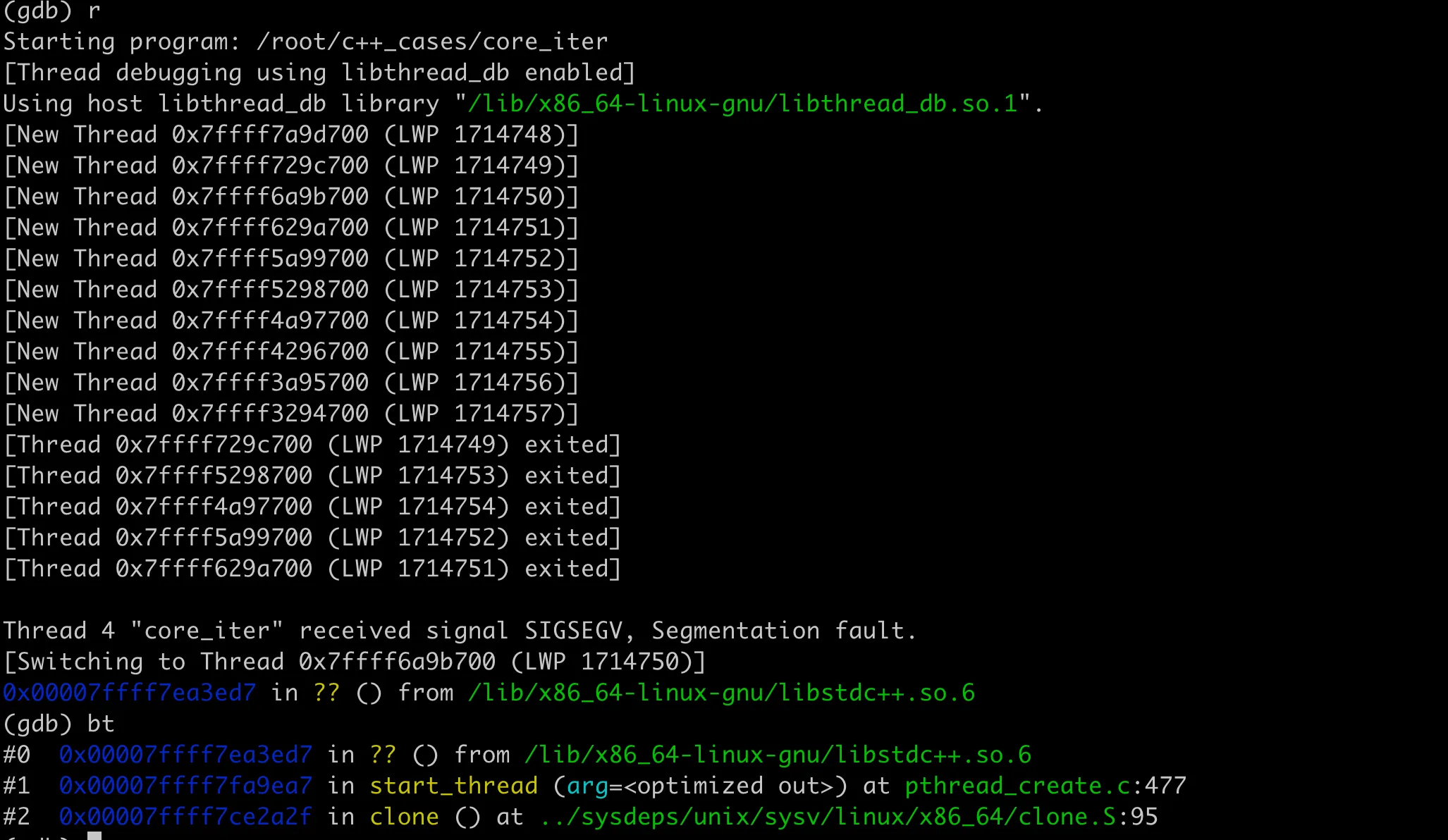
这里堆栈没有什么有用的信息,比较难分析。对于示例这种能稳定复现的问题,使用 Valgrind 来辅助分析,会更容易定位。上面代码分析结果如下:
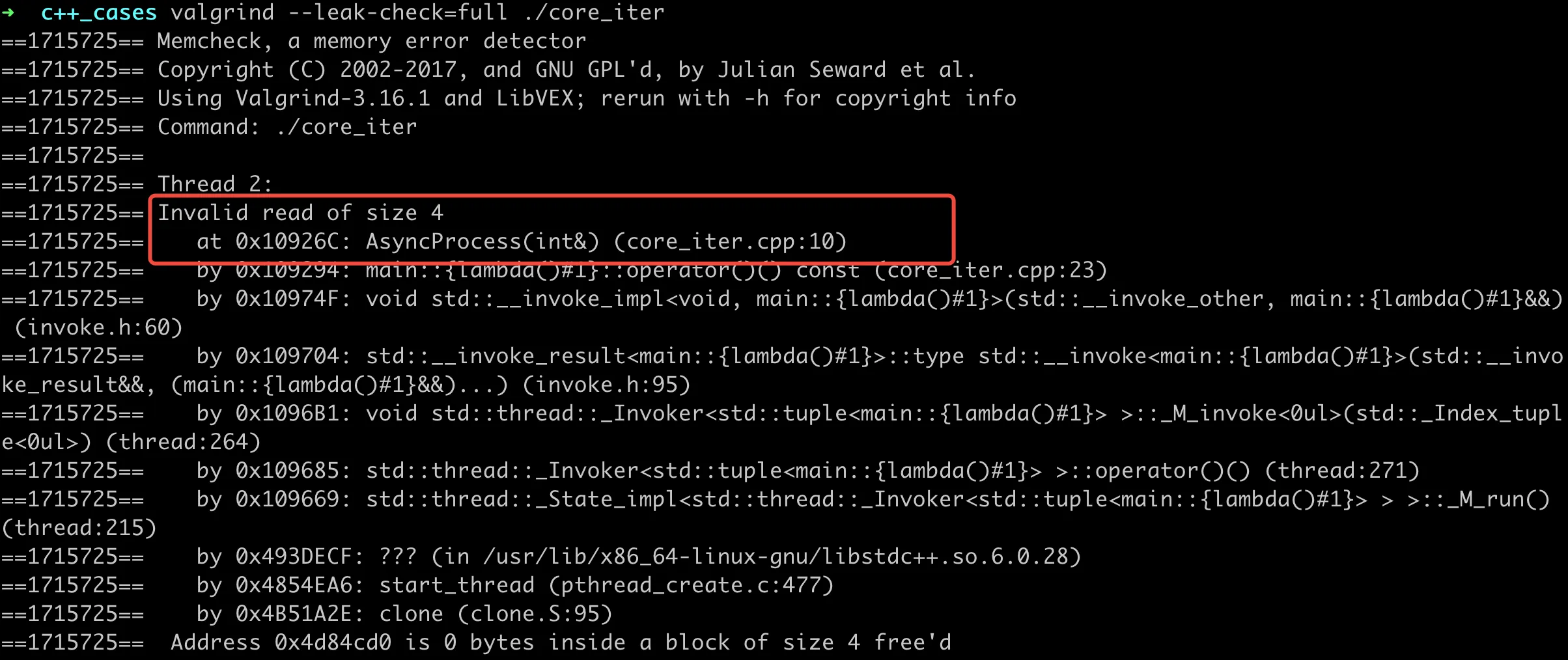
从这里分析结果可以看到,主要有两个问题,无效读取(Invalid read)和无效写入(Invalid write)。发生问题的代码行数这里也有,所以可以很快定位到问题。
总结
本文介绍了 5 个自己遇到过的导致进程 Coredump 的经典案例:
- 抛异常没有捕获:使用标准库函数时,要注意其是否会抛出异常。对于可能抛出异常的函数,需要妥善处理异常。对于自定义类,建议使用错误码而不是异常来处理错误。
- 数组下标访问越界:在使用数组或容器时,要特别注意下标访问的合法性。尤其是在多处遍历同一容器时,要确保容器的大小没有发生变化。可以使用
at()方法来进行带边界检查的访问。 - 访问失效的迭代器:在使用迭代器时,要注意容器的操作(如删除、插入等)可能会导致迭代器失效。对于 vector 来说,扩容会导致所有迭代器失效;对于其他容器,也要了解其迭代器失效的规则。
- 并发导致的数据竞争:在多线程环境下,要特别注意数据的并发访问。即使是看似只读的操作(如 map 的 [] 操作符),也可能会修改容器的内容。使用合适的同步机制(如互斥锁、读写锁等)来保护共享数据。
- 灾难性回溯导致的栈溢出:在使用正则表达式等可能导致大量递归的场景下,要注意输入的限制。对于复杂的文本处理,最好使用非递归的方案,或者限制递归深度。
当然还有些不常见的 core,比如我之前遇到的:Bazel 依赖缺失导致的 C++ 进程 coredump 问题分析。大家有遇见过什么印象深刻的 crash 案例,欢迎留言分享。

