LevelDB 源码阅读:LRU Cache 高性能缓存实现细节
计算机系统中,缓存无处不在。从 CPU 缓存到内存缓存,从磁盘缓存到网络缓存,缓存无处不在。缓存的核心思想就是空间换时间,通过将热点数据缓存到高性能的存储中,从而提高性能。因为缓存设备比较贵,所以存储大小有限,就需要淘汰掉一些缓存数据。这里淘汰的策略就非常重要了,因为如果淘汰的策略不合理,把接下来要访问的数据淘汰掉了,那么缓存命中率就会非常低。
缓存淘汰策略有很多种,比如 LRU、LFU、FIFO 等。其中 LRU(Least Recently Used) 就是一种很经典的缓存淘汰策略,它的核心思想是:当缓存满了的时候,淘汰掉最近最少使用的数据。这里基于的一个经验假设就是”如果数据最近被访问过,那么将来被访问的几率也更高“。只要这个假设成立,那么 LRU 就可以显著提高缓存命中率。
在 LevelDB 中,实现了内存中的 LRU Cache,用于缓存热点数据,提高读写性能。默认情况下,LevelDB 会对 sstable 的索引 和 data block 进行缓存,其中 sstable 默认是支持缓存 990 (1000-10) 个,data block 则默认分配了 8MB 的缓存。
LevelDB 实现的 LRU 缓存是一个分片的 LRU,在细节上做了很多优化,非常值得学习。本文将从经典的 LRU 实现思路出发,然后一步步解析 LevelDB 中 LRU Cache 的实现细节。
经典的 LRU 实现思路
一个实现良好的 LRU 需要支持 O(1) 时间复杂度的插入、查找、删除操作。经典的实现思路是使用一个双向链表和一个哈希表,其中:
- 双向链表用于存储缓存中的数据项,并保持缓存项的使用顺序。最近被访问的数据项被移动到链表的头部,而最久未被访问的数据项则逐渐移向链表的尾部。当缓存达到容量限制而需要淘汰数据时,链表尾部的数据项(即最少被访问的数据项)会被移除。
- 哈希表用于存储键与双向链表中相应节点的对应关系,这样任何数据项都可以在常数时间内被快速访问和定位。哈希表的键是数据项的键,值则是指向双向链表中对应节点的指针。
双向链表保证在常数时间内添加和删除节点,哈希表则提供常数时间的数据访问能力。对于 Get 操作,通过哈希表快速定位到链表中的节点,如果存在则将其移动到链表头部,更新为最近使用。对于插入 Insert 操作,如果数据已存在,更新数据并移动到链表头部;如果数据不存在,则在链表头部插入新节点,并在哈希表中添加映射,如果超出容量则移除链表尾部节点,并从哈希表中删除相应的映射。
上面的实现思路相信每个学过算法的人都知道,Leetcode 上也有 LRU 实现的题目,比如 146. LRU 缓存,需要实现的接口:
1 | class LRUCache { |
不过想实现一个工业界可用的高性能 LRU 缓存,还是有点难度的。接下来,我们来看看 LevelDB 是如何实现的。
缓存设计:依赖倒置
在开始看 LevelDB 的 LRU Cache 实现之前,先看下 LevelDB 中如何使用这里的缓存。比如在 db/table_cache.cc 中,为了缓存 SST table 的元数据信息,TableCache 类定义了一个 Cache 类型的成员变量,然后通过该成员来对缓存进行各种操作。
1 | Cache* cache_(NewLRUCache(entries)); |
这里 Cache 是一个抽象类,定义了缓存操作的各种接口,具体定义在 include/leveldb/cache.h 中。它定义了缓存应该具有的基本操作,如 Insert、Lookup、Release、Erase 等。它还定义了 Cache::Handle 这个类型,作为缓存条目。用户代码只与这个抽象接口交互,不需要知道具体实现。
然后有个 LRUCache 类,是具体的缓存实现类,它实现了一个完整的 LRU 缓存。这个类不直接对外暴露,也不直接继承 Cache。然后还有个 ShardedLRUCache 类,它继承 Cache 类实现了缓存各种接口。它内部包含 16 个 LRUCache “分片”(shards),每个分片负责缓存一部分数据。
这样的设计允许调用方在不修改使用缓存部分的代码的情况下,轻松替换不同的缓存实现。哈哈,这不就是八股文经常说的,面向对象编程 SOLID 中的依赖倒置嘛,应用层依赖于抽象接口(Cache)而不是具体实现(LRUCache)。这样可以降低代码耦合度,提高系统的可扩展性和可维护性。
使用 Cache 的时候,通过这里的工厂函数来创建具体的缓存实现 ShardedLRUCache:
1 | Cache* NewLRUCache(size_t capacity) { return new ShardedLRUCache(capacity); } |
LRUCache 是缓存的核心部分,不过现在我们先不管怎么实现 LRUCache,先来看看缓存项 Hanle 的设计。
LRUHandle 类的实现
在 LevelDB 中,缓存的数据项是一个 LRUHandle 类,定义在 util/cache.cc 中。这里的注释也说明了,LRUHandle 是一个支持堆分配内存的变长结构体,它会被保存在一个双向链表中,按访问时间排序。我们来看看这个结构体的成员有哪些吧:
1 | struct LRUHandle { |
这里还稍微有点复杂,每个字段都还挺重要的,我们一个个来看吧。
- value:存储缓存的实际 value 值,这里是一个 void* 的指针,说明缓存这层不关心具体值的结构,只用知道对象的地址就好;
- deleter:一个函数指针,指向用于删除缓存值的回调函数,当缓存项被移除时,用它来释放缓存值的内存空间;
- next_hash:LRU 缓存实现需要用到哈希表。这里 LevelDB 自己实现了一个高性能的哈希表,在 LevelDB 源码阅读:如何设计一个高性能哈希表 中,我们介绍了 LevelDB 中哈希表的实现细节,里面有介绍过 LRUHandle 的 next_hash 字段就是用来解决哈希表的冲突的。
- prev/next:双向链表的前一个/下一个指针,用来维持双向链表,方便快速从双向链表中插入或者删除节点;
- charge:表示该缓存项占用的成本(通常是内存大小),用于计算总缓存使用量,判断是否需要淘汰;
- key_length:键的长度,用于构造 Slice 对象表示键;
- in_cache:标记该项是否在缓存中,如果为 true,表示缓存拥有对该项的引用;
- refs:引用计数,包括缓存本身的引用(如果在缓存中)和使用方的引用,当计数为0时,可以释放该项;
- hash:键的哈希值,用于快速查找和分片;这里同一个 key 也把 hash 值保存下来,避免重复计算;
- key_data:柔性数组成员,存储键的实际数据,使用 malloc 分配足够空间来存储整个键。柔性数组我们在 LevelDB 源码阅读:理解其中的 C++ 高级技巧 中也有介绍过,这里就不展开了。
这里 LRUHandle 的设计允许缓存高效地管理数据项,跟踪缓存项的引用,并实现 LRU 淘汰策略。特别是 in_cache 和 refs 字段的结合使用,使得我们可以区分”被缓存但未被客户端引用“和”被客户端引用“的项,从而用两个链表来支持高效淘汰缓存。
下面我们详细看看 LRUCache 类的实现细节,就更容易理解上面各个字段的用途了。
LRUCache 类的实现细节
前面看完了缓存的数据项的设计,接着可以来看看这里 LevelDB LRUCache 的具体实现细节了。核心的缓存逻辑实现在 util/cache.cc 的 LRUCache 类中。该类包含了缓存的核心逻辑,如插入、查找、删除、淘汰等操作。
这里注释(LevelDB 的注释感觉都值得好好品读)中提到,用了两个双向链表来维护缓存项,这又是为什么呢?
1 | // The cache keeps two linked lists of items in the cache. All items in the |
为什么用两个双向链表?
我们前面也提到,一般的 LRU Cache 实现中用一个双向链表。每次使用一个缓存项时,会将其移动到链表的头部,这样链表的尾部就是最近最少使用的缓存项。淘汰的时候,直接移除链表尾部的节点即可。比如开始提到的 Leetcode 中的题目就可以这样实现来解决,实现中每个缓存项就是一个 int,取的时候直接复制出来就好。如果要缓存的项是简单的值类型,读的时候直接复制值,不需要引用,那单链表的实现足够了。
但在 LevelDB 中,缓存的数据项是 LRUHandle 对象,它是一个动态分配内存的变长结构体。在使用的时候,为了高并发和性能考虑,不能通过简单的值复制,而要通过引用计数来管理缓存项。如果还是简单的使用单链表的话,我们考虑下这样的场景。
我们依次访问 A, C, D 项,最后访问了 B, B 项被客户端引用(refs=1),位于链表头部,如下图中的开始状态。一段时间内,A、C、D都被访问了,但 B 没有被访问。根据 LRU 规则,A、C、D被移到链表头部。B 虽然仍被引用,但因为长时间未被访问,相对位置逐渐后移。A 和 D 被访问后,很快使用完,这时候没有引用了。当需要淘汰时,从尾部开始,会发现B项(refs=1)不能淘汰,需要跳过继续往前遍历检查其他项。
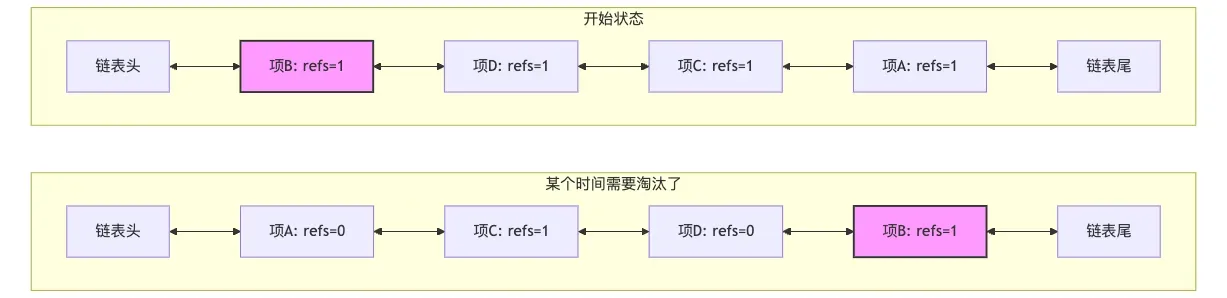
也就是说在这种引用场景下,淘汰节点的时候,如果链表尾部的节点正在被外部引用(refs > 1),则不能淘汰它。这时候需要遍历链表寻找可淘汰的节点,效率较低。在最坏情况下,如果所有节点都被引用,可能需要遍历整个链表却无法淘汰任何节点。
为了解决这个问题,在 LRUCache 实现中,用了两个双向链表。一个是in_use_,用来存储被引用的缓存项。另一个是lru_,用来存储未被引用的缓存项。每个缓存项只能在其中的一个链表中,不能同时在两个链表中。但是可以根据当前是否被引用,在两个链表中互相移动。这样在需要淘汰节点的时候,就可以直接从 lru_ 链表中淘汰,而不用遍历 in_use_ 链表。
双链表介绍就先到这里,后面可以结合 LRUCache 的核心实现继续理解双链表具体怎么实现。
缓存插入,删除,查找节点
先来看插入节点,实现在 util/cache.cc 中。简单说,这里先创建 LRUHandle 对象,然后把它放到 in_use_ 双向链表中,同时更新哈希表。如果插入节点后,缓存容量达到上限,则需要淘汰节点。但是实现中,还是有不少细节部分,LevelDB 的代码也确实精简。
可以看下这里的入参,key 和 value 是客户端传入的,hash 是 key 的哈希值,charge 是缓存项占用的成本,deleter 是删除缓存项的回调函数。这里因为 LRUHandle 最后成员是柔性数组,所以我们先手动计算 LRUHandle 对象的大小,然后分配内存,之后开始初始化各种成员。这里 refs 初始化为 1,因为返回了一个 Handle 指针对象。
1 | Cache::Handle* LRUCache::Insert(const Slice& key, uint32_t hash, void* value, |
接着这里也比较有意思,LevelDB 中的 LRUCache 实现,支持缓存容量设为 0,这时候就不缓存任何数据。要缓存的时候,更新 in_cache 为 true,增加 refs 计数,因为把 Handle 对象放到了 in_use_ 链表中。接着当然还要把 Handle 插入到哈希表中,注意这里有个 FinishErase 调用,值得好好聊聊。
1 | if (capacity_ > 0) { |
我们前面将哈希表实现的时候,这里插入哈希表,如果已经有同样的 key,则返回旧的 Handle 对象。这里 FinishErase 函数就是用来清理这个旧的 Handle 对象。
1 | // If e != nullptr, finish removing *e from the cache; it has already been |
清理操作有几个吧,首先从 in_use_ 或者 lru_ 链表中移除,这里其实不确定旧的 Handle 对象具体在哪个链表中,不过没关系,LRU_Remove 不用知道在哪个链表也能处理。LRU_Remove 函数实现很简单,也就两行代码,大家不理解的话可以画个图来理解下:
1 | void LRUCache::LRU_Remove(LRUHandle* e) { |
接着更新 in_cache 为 false,表示已经不在缓存中了。后面还要更新缓存容量,减少 usage_。最后调用 Unref 减少这个 Handle 对象的引用计数,这时候这个 Handle 对象可能在其他地方还有引用。等到所有引用都释放了,这时候才会真正清理这个 Handle 对象。Unref 函数 其实也有点意思,我把代码也贴出来:
1 | void LRUCache::Unref(LRUHandle* e) { |
首先减少计数,如果计数为 0,则表示完全没有外部引用,这时候可以大胆释放内存。释放也分两部分,先用回调函数 deleter 来清理 value 部分的内存空间。接着用 free 来释放 LRUHandle 指针的内存空间。如果计数为 1 并且还在缓存中,表示只有来自缓存自身的引用,这时候需要把 Handle 对象从 in_use_ 链表中移除,并放到 lru_ 链表中。如果后面要淘汰节点,这个节点在 lru_ 链表中,就可以直接淘汰了。
接下来就是插入节点操作的最后一步了,判断缓存是否还有剩余空间,没有的话,要开始淘汰节点了。这里只要空间还是不够,然后就会从 lru_ 链表中取出队首节点,然后从哈希表中移除,接着调用 FinishErase 清理节点。这里判断双向链表是否为空也比较有意思,用到了哑元节点,后面再介绍。
1 | while (usage_ > capacity_ && lru_.next != &lru_) { |
整个插入节点函数,包括这里的淘汰逻辑,甚至是整个 LevelDB 代码中,都有大量的 assert 断言,用来做一些检查,保证有问题进程立马挂掉,避免错误传播。
看完插入节点,其实删除节点就不用看了,代码实现很简单,从哈希表中移除节点,然后调用 FinishErase 清理节点。
1 | void LRUCache::Erase(const Slice& key, uint32_t hash) { |
查找节点也相对简单些,直接从哈希表中查找,如果找到,则增加引用计数,并返回 Handle 对象。这里其实和插入一样,只要返回了 Handle 对象,就会增加引用计数。所以如果外面如果没有用到的话,要记得调用 Release 方法手动释放引用,不然内存就容易泄露了。
1 | Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) { |
此外,这里的 Cache 还实现了 Prune 接口,用来主动清理缓存。方法和插入里面的清理逻辑类似,不过这里会把 lru_ 链表中所有节点都清理掉。这个清理在 LevelDB 中也没地方用到过。
双向链表的操作
我们再补充讨论下这里双向链表相关的操作吧。前面我们其实已经知道了分了两个链表,一个 lru_ 链表,一个 in_use_ 链表。这里结合注释看更清晰:
1 | // Dummy head of LRU list. |
lru_ 成员是链表的哑元节点,next 成员指向 lru_ 链表中最老的缓存项,prev 成员指向 lru_ 链表中最新的缓存项。在 LRUCache 的构造函数中,lru_ 的 next 和 prev 都指向它自己,表示链表为空。还记得前面插入节点的时候,怎么判定还有可以淘汰的节点的吧,就是用 lru_.next != &lru_。
1 | LRUCache::LRUCache() : capacity_(0), usage_(0) { |
哑元(dummy node)在很多数据结构的实现中被用作简化边界条件处理的技巧。在 LRU 缓存的上下文中,哑元主要是用来作为链表的头部,这样链表的头部始终存在,即使链表为空时也是如此。这种方法可以简化插入和删除操作,因为在插入和删除操作时不需要对空链表做特殊处理。
例如,当向链表中添加一个新的元素时,可以直接在哑元和当前的第一个元素之间插入它,而不需要检查链表是否为空。同样,当从链表中删除元素时,你不需要担心删除最后一个元素后如何更新链表头部的问题,因为哑元始终在那里。
删除链表中节点 LRU_Remove 我们前面看过,两行代码就行了。往链表添加节点的实现,我整理了一张图,配合代码就好理解了:
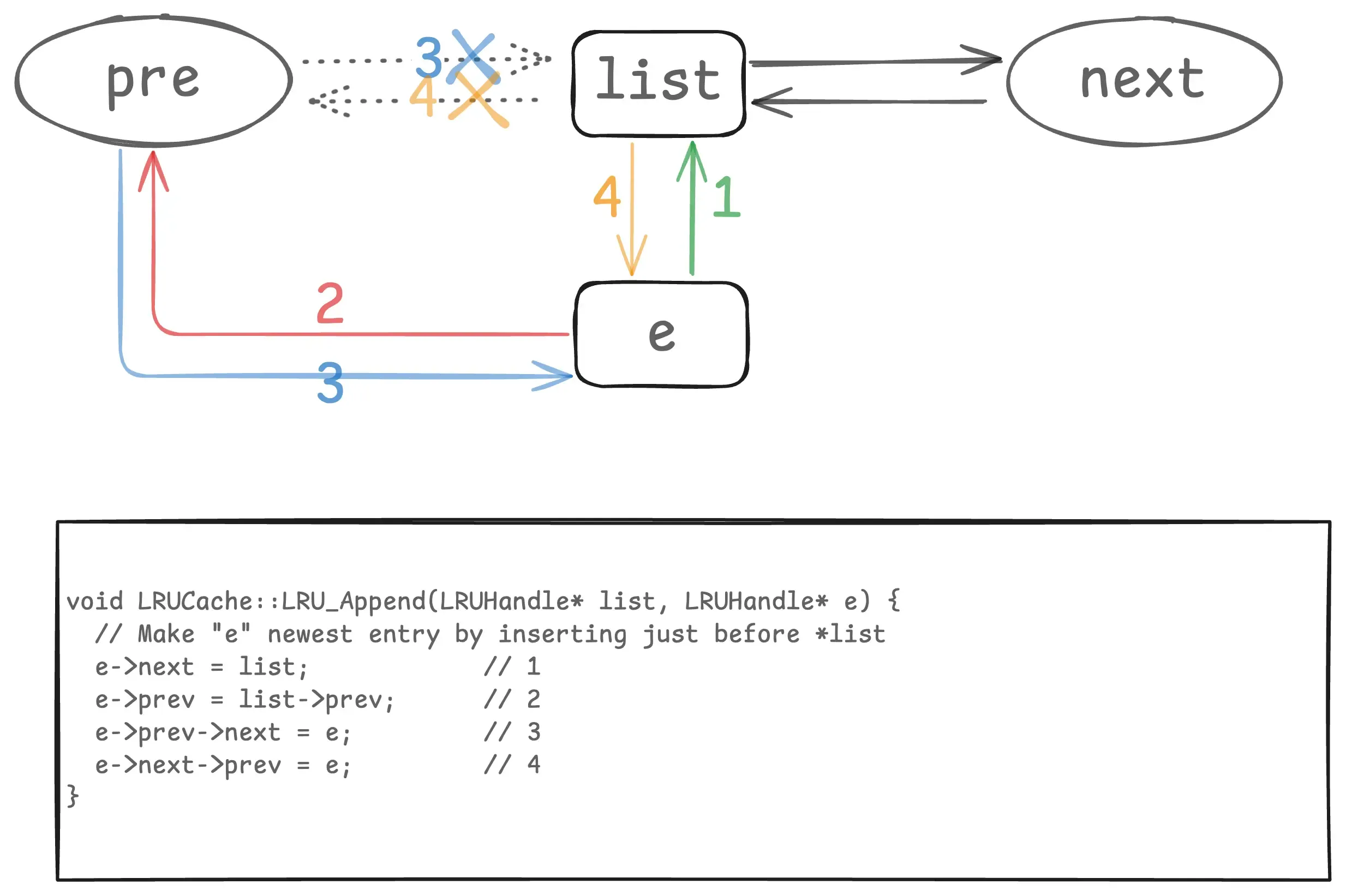
这里 e 是新插入的节点,list 是链表的哑元节点。list 的 pre 和 next 我这里用圆形,表示它可以是自己,比如初始空链表的时候。这里插入是在哑元的前面,所以 list->prev 永远是链表最新的节点,list->next 永远是链表最老的节点。这种链表操作,最好画个图,就一目了然了。
reinterpret_cast 转换
最后再补充说下,上面代码中有不少地方用到了 reinterpret_cast 来在 LRUHandle* 和 Cache::Handle* 之间转换类型。reinterpret_cast 将一种类型的指针强制转换为另一种类型的指针,而不进行任何类型检查。它不进行任何底层数据的调整,只是告诉编译器:”请把这个内存地址当作另一种类型来看待”。其实这种操作比较危险,一般不推荐这样用。
但 LevelDB 这样做其实是为了将接口和实现分析。这里将具体的内部数据结构 LRUHandle* 以一个抽象、不透明的句柄 Cache::Handle* 形式暴露给外部用户,同时又能在内部将这个不透明的句柄转换回具体的数据结构进行操作。
在这种特定的、受控的设计模式下,它是完全安全的。因为只有 LRUCache 内部代码可以创建 LRUHandle。任何返回给外部的 Cache::Handle* 总是指向一个合法的 LRUHandle 对象。任何传递给 LRUCache 的 Cache::Handle* 必须是之前由同一个 LRUCache 实例返回的。
只要遵守这些约定,reinterpret_cast 就只是在指针的”视图”之间切换,指针本身始终指向一个有效的、类型正确的对象。如果用户试图伪造一个 Cache::Handle* 或者将一个不相关的指针传进来,程序就会发生未定义行为,但这属于 API 的误用。
ShardedLRUCache 分片实现
前面 LRUCache 的实现中,插入缓存、查找缓存、删除缓存操作都必须通过一个互斥锁来保护。在多线程环境下,如果只有一个大的缓存,这个锁就会成为一个全局瓶颈。当多个线程同时访问缓存时,只有一个线程能获得锁,其他线程都必须等待,这会严重影响并发性能。
为了提高性能,ShardedLRUCache 将缓存分成多个分片(shard_ 数组),每个分片都有自己独立的锁。当一个请求到来时,它会根据 key 的哈希值被路由到特定的分片。这样,不同线程访问不同分片时就可以并行进行,因为它们获取的是不同的锁,从而减少了锁的竞争,提高了整体的吞吐量。画个图可能更清晰些,mermaid 代码在这里。
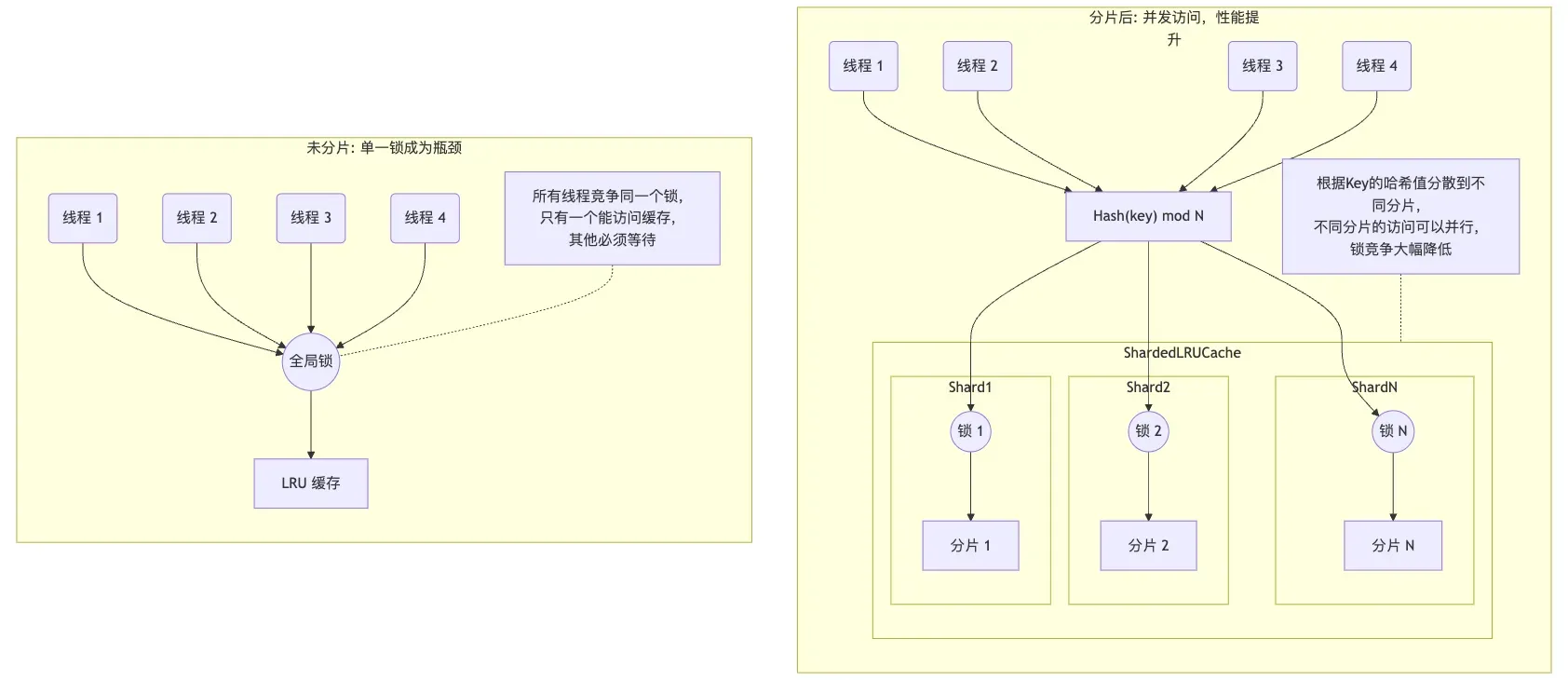
那么需要分多少片呢?LevelDB 这里硬编码了一个 $ kNumShards = 1 << kNumShardBits $,计算出来是 16,算是一个经验选择吧。如果分片数量太少,比如2、4个,在核心数很多的服务器上,锁竞争依然可能很激烈。分片太多的话,每个分片的容量就会很小。这可能导致一个”热”分片频繁淘汰数据,而另一个”冷”分片有很多空闲空间的情况,从而降低了整个缓存的命中率。
选择 16 的话,对于典型的 8 核或 16 核服务器,已经能提供足够好的并发度,同时又不会带来过大的额外开销。同时选择 2 的幂次方,还能通过位运算 $ hash >> (32 - kNumShardBits)$ 快速计算分片索引。
加入分片后,包装了下原始的 LRUCache 类,构造的时候需要指定分片数,每个分片容量等,实现如下:
1 | public: |
然后其他相关缓存操作,比如插入、查找、删除等,都是通过 Shard 函数来决定操作哪个分片。这里以插入为例,实现如下:
1 | Handle* Insert(const Slice& key, void* value, size_t charge, |
求 Hash 和计算分片的 Shard 函数没什么难点,这里就忽略了。这里也提下,ShardLRUCache 这里还要继承 Cache 抽象类,实现 Cache 中的各种接口。这样才能被其他调用 Cache 接口的地方使用。
最后这里还有一个小细节,也值得说下,那就是 Cache 接口还有个 NewId 函数。在其他的 LRU 缓存实现中,没见过有支持 Cache 生成一个 Id。LevelDB 为啥这么做呢?
Cache 的 Id 生成
LevelDB 其实提供了注释,但是只看注释似乎也不好明白,我们结合使用场景来分析下。
1 | // Return a new numeric id. May be used by multiple clients who are |
这里补充些背景,我们在打开 LevelDB 数据库时,可以创建一个 Cache 对象,并传入 options.block_cache,用来缓存 SSTTable 文件中的数据块和过滤块。当然如果不传的话,LevelDB 默认也会创建一个 8 MB 的 SharedLRUCache 对象。这里 Cache 对象是全局共享的,数据库中所有的 Table 对象都会使用这同一个 BlockCache 实例来缓存它们的数据块。
在 table/table.cc 的 Table::Open 中,我们看到每次打开 SSTTable 文件的时候,就会用 NewId 生成一个 cache_id。这里底层用互斥锁保证,每次生成的 Id 是全局递增的。后面我们要读取 SSTTable 文件中偏移量为 offset 的数据块 block 时,会用 <cache_id, offset> 作为缓存的 key 来进行读写。这样不同 SSTTable 文件的 cache_id 不同,即使他们的 offset 一样,这里缓存 key 也不同,不会冲突。
说白了,SharedLRUCache 提供全局递增的 Id 主要是用来区分不同 SSTTable 文件,免得每个文件还要自己维护一个唯一 Id 来做缓存的 key。
总结
好了,LevelDB 的 LRU Cache 分析完了,我们可以看到一个工业级高性能缓存的设计思路和实现细节。最后总结下几个关键点:
- 接口与实现分离:通过抽象的 Cache 接口,将缓存的使用方与具体实现解耦,体现了面向对象设计中的依赖倒置原则。用户代码只需要跟 Cache 接口打交道,不用关心具体实现。
- 精心设计的缓存项:LRUHandle 结构体包含了引用计数、缓存标志等元数据,通过柔性数组成员存储变长的 key,减少内存分配次数,提高性能。
- 双链表优化:通过两个双向链表(in_use_ 和 lru_)分别管理”正在使用”和”可以淘汰”的缓存项,避免了在淘汰时遍历整个链表,提高了淘汰效率。
- 哑元节点技巧:使用哑元节点简化了链表操作,不需要处理空链表的特殊情况,代码更简洁。
- 分片减少锁竞争:ShardedLRUCache 将缓存分成多个分片,每个分片有独立的锁,大幅提高了多线程环境下的并发性能。
- 引用计数管理内存:通过精确的引用计数,确保缓存项在仍被外部引用时不会被释放,同时在不再需要时及时回收内存。
- 断言保证正确性:大量使用断言来检查代码的前置条件和不变量,确保错误能够及早被发现。
这些设计思路和实现技巧都值得我们在自己的项目中借鉴。特别是在需要高并发、高性能的场景中,LevelDB 的这些优化手段可以帮助我们设计出更高效的缓存系统。

