LevelDB 源码阅读:一步步拆解 SSTable 文件的创建过程
LevelDB 中,内存表中的键值对在到达一定大小后,会落到磁盘文件 SSTable 中。并且磁盘文件也是分层的,每层包含多个 SSTable 文件,在运行时,LevelDB 会在适当时机,合并、重整 SSTable 文件,将数据不断往下层沉淀。
这里 SSTable 有一套组织数据的格式,目的就是保证数据有序,并且能快速查找。那么 SSTable 内部是怎么存储这些键值对的,又是怎么提高数据的读、写性能的。以及整个 SSTable 文件的实现中有哪些优化点?
本文接下来我们会仔细分析 SSTable 文件的创建过程,一步步拆解来看看这里到底怎么实现的。在开始之前,我先给一个大的图,大家可以先留个印象。
SSTable 文件格式设计原因
在开始之前,我们要先搞明白一个关键问题,文件格式该如何设计,才能兼顾高效写入和快速读取? 下面我们从几个基本问题出发,来推测作者是如何设计这里的数据格式。
问题一:键值对该如何存放?
首先,最核心的数据,也就是用户的键值对,得有个地方放。最简单的方法,把所有键值对按顺序放进 SSTable 这整个大文件。这样有什么问题呢?首先读的时候,如果要找一个 key,需要遍历整个大文件。然后写入过程中,每次添加一个键值对就要写磁盘的话,写 IO 压力会很大,吞吐上不去。
既然太大了不行,那就分块吧。计算机科学中的”分而治之”思想,在 LevelDB 中得到了很好的体现。我们把大文件切分成不同的数据块,按照数据块的粒度来存储键值对。每个块默认大约 4KB。当一个块写满了,就把它作为一个整体写入文件,然后再开始写下一个。这样整体写入的时候,就会减少很多磁盘 IO 了。
这里我再多说一点,分块存储不仅减少了写入磁盘的 IO 次数,通过配合
不过查找问题还没解决,还是要遍历所有的块来查找键值。
要是我们能快速定位到键值在哪个 DataBlock 里,那就只用遍历单个块就好了,效率会提升很多。
问题二:如何快速定位到某个 Data Block?
为了解决这个问题,我们需要一个”目录”。计算机中也叫索引,于是 Index Block (索引块) 诞生了。这个块里存放了一系列的索引记录,每个记录都记录一个 Data Block 的信息,根据这个记录,我们能快速知道某个键所在的 DataBlock。
这样查找键值的时候,只需要在 Index Block 中二分查找,就能快速定位到键值可能在的 DataBlock。索引块只包含一些索引数据,所以整体大小会小很多,通常可以加载到内存中去,所以查找会快很多。
有了索引块之后,我们把扫描整个文件变成了”查索引 -> 精准读取一小块”的操作,效率会大大提升。这里索引具体怎么设计我们先不管,后面再详细分析。
问题三:如何避免无效的磁盘读取?
通过索引块,我们其实能找到 key 可能 在哪个块,但它不能百分百确定。为什么呢?因为索引块里记录的只是 key 的区间,并不能保证 key 一定在这个区间里,后面结合代码理解会更清晰。这就导致一个问题,当我们兴冲冲地把 Data Block 从磁盘读到内存后,却发现要找的 key 根本不存在,这不就白白浪费了一次宝贵的磁盘 I/O 吗?尤其是如果业务中,有大量读不存在 key 的场景,那么这种浪费很可观。
这种判断不存在的需求,计算机科学中早就有解法了,常见的就是布隆过滤器。布隆过滤器是位数组和哈希函数的组合,可以快速判断一个元素是否在集合中。本系列之前的文章LevelDB 源码阅读:布隆过滤器原理、实现、测试与可视化 中,有详细介绍布隆过滤器的原理和实现。
LevelDB 中,用同样的解决思路,它支持设置一个可选的过滤块(Filter Block),在读取 Data Block 之前,先通过 Filter Block 确认键是否存在。如果不存在的话,直接返回,如果可能在,再读取 Data Block 进行确认。通过这种方式,我们极大地减少了对不存在的 key 的无效查询。
看起来一切很美好了,不过等下,还有个问题,我们怎么知道 Index Block 和 Filter Block 在 SSTable 文件的哪个位置呢?
问题四:如何定位索引和过滤块?
现在我们有很多数据块、一个 Index Block、一个 Filter Block。问题又来了:当我们打开一个 SSTable 文件时,我们怎么知道 Index Block 和 Filter Block 在文件的哪个位置呢?
最朴素的思路就是可以把这些元信息放到文件的固定偏移位置。不过如果放到文件头的话,这些记录发生变化的话,整个文件的数据都要移动,这显然不行。
那放文件末尾呢?看起来可行,LevelDB 也是这么设计的。在文件尾部,放一个固定 48 字节的 Footer 区域,里面记录了 Index Block 在文件的偏移位置,以及另一个之前没提到过的 Meta-Index Block 的位置。
这里按理说 Footer 记录 Index Block 和 Filter Block 的位置就行了,为啥引入一个 Meta-Index Block 呢?作者在代码注释里有提到过,主要为了扩展性。Footer 的大小固定,不能增加更多信息了,那万一未来有更多种类的元数据块,比如统计块等,要在哪里存偏移。
所以作者增加了一个元数据的索引——Meta-Index Block。这个块的作用就是一张元数据目录,它的键是元数据的名字(如 “filter.leveldb.BuiltinBloomFilter2”),值是对应元数据块(如 Filter Block)的偏移位置。当前只有过滤块信息,后续可以任意增加元数据块。
这样整个查找过程就串起来了,先拿出尾部 48 字节的固定内容。从里面解析出 Index Block 和 Meta-Index Block 的偏移位置,然后从 Meta-Index Block 中拿到 Filter Block 的偏移位置,最后根据偏移位置读取 Filter Block 的内容。有了 Index Block 和 Filter Block,我们就能快速、高效地”按图索骥”去查找键值了。
答案: SSTable 结构图
前面已经把 SSTable 中数据块组织方式分析完了,这里我画一个简单的 ASCII 图来描述 SSTable 中的各个块,方便大家理解:
1 | +-------------------+ |
不过要怎么提供接口,怎么把键值对保存为上面格式,还是有不少工程细节的。这里顺便说下,LevelDB 代码中的分层抽象是做的真好,一层套一层,把复杂逻辑封装起来,方便理解和维护。比如每个块自己是怎么构建数据的,都封装了单独的实现,后面我会在其他文章里详细说明。
本篇文章,咱们重点关注 SSTable 文件构建的工程细节部分。这部分实现在table/table_builder.cc 中,主要就是 TableBuilder 类。
该类只有一个私有成员变量,是一个 Rep* 指针,里面保存各种状态信息,比如当前的 DataBlock、IndexBlock 等。这里 Rep* 用到了 Pimpl 的设计模式,可以看本系列的 LevelDB 源码阅读:理解其中的 C++ 高级技巧 了解关于 Pimpl 的更多细节。
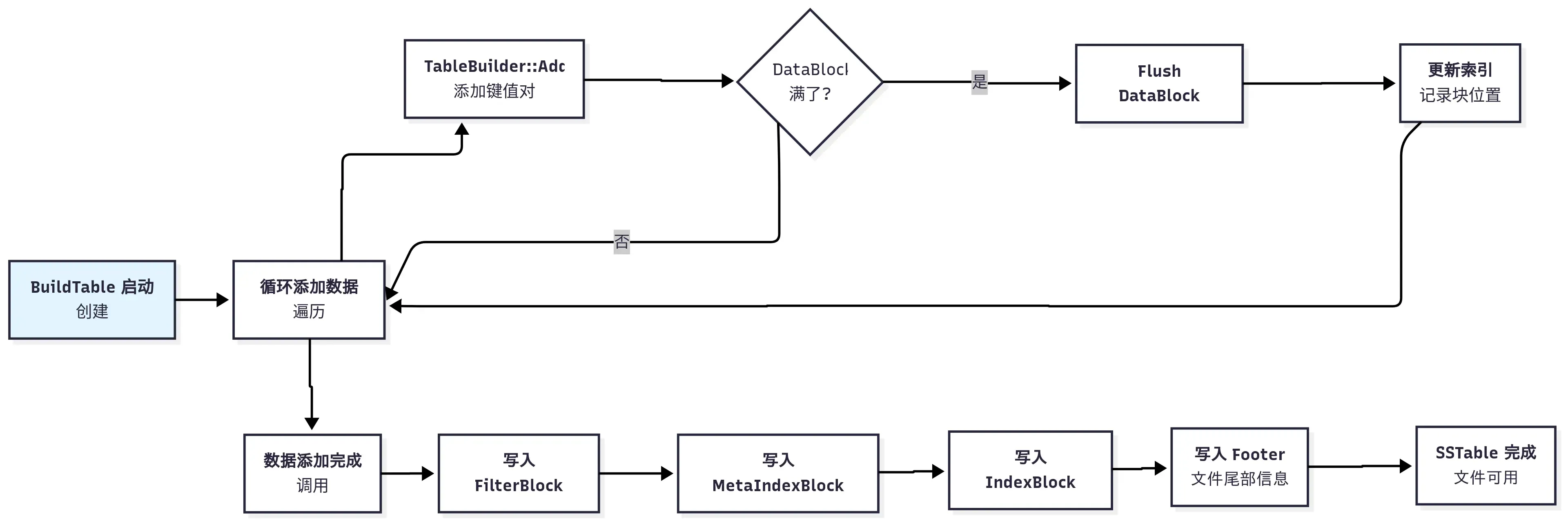
该类最重要的接口有 Add,这个函数会层层调用其他一些封装好的函数,来完成键值对的添加。接下来从这个接口入手,分析 TableBuilder 类的实现。
Add 添加键值对
TableBuilder::Add 方法是向 SSTable 文件中添加键值对的核心函数。添加键值对,需要更改上面提到的 DataBlock、IndexBlock、FilterBlock 等各个块。这里为了提高效率,有不少工程优化细节,为了更好理解,我把它主要分 4 部分,这里一个个来说吧。
1 | void TableBuilder::Add(const Slice& key, const Slice& value) { |
前置校验
在 Add 方法中,首先会先读出来 rep_ 的数据,做一些前置校验,比如验证文件没有被关闭,保证键值对是有序的。
1 | Rep* r = rep_; |
LevelDB 在代码中 加了不少校验逻辑,确保如果有问题,早崩溃早发现,这个理念对于底层库来说,还是很有必要的。Add 方法这里 assert 校验后面插入的键值对永远都是更大的,当然这点需要调用方来保证。为了实现校验逻辑,在每个 TableBuilder 的 Rep 中,都保存了 last_key,用来记录最后一个插入的 key。这个 key 在索引键优化的时候会用到,后面会详细说明。
处理索引记录
接着会在适当时机添加新的索引。我们知道索引记录用来快速查找一个 key 所在的 DataBlock 偏移位置,每一个完整的 DataBlock 对应一个索引记录。我们先看看这里添加索引记录的时机,当处理完一个 DataBlock 时,会将 pending_index_entry 设置为 true,等到下次新的 DataBlock 增加第一个 key 时,再更新上个完整的 DataBlock 对应的索引记录。
这部分的核心代码如下:
1 | if (r->pending_index_entry) { |
这里之所以要等到新 DataBlock 增加第一个 key 的时候才更新索引块,就是 为了尽最大程度减少索引键的长度,从而减少索引块的大小,这也是 LevelDB 工程上的一个优化细节。
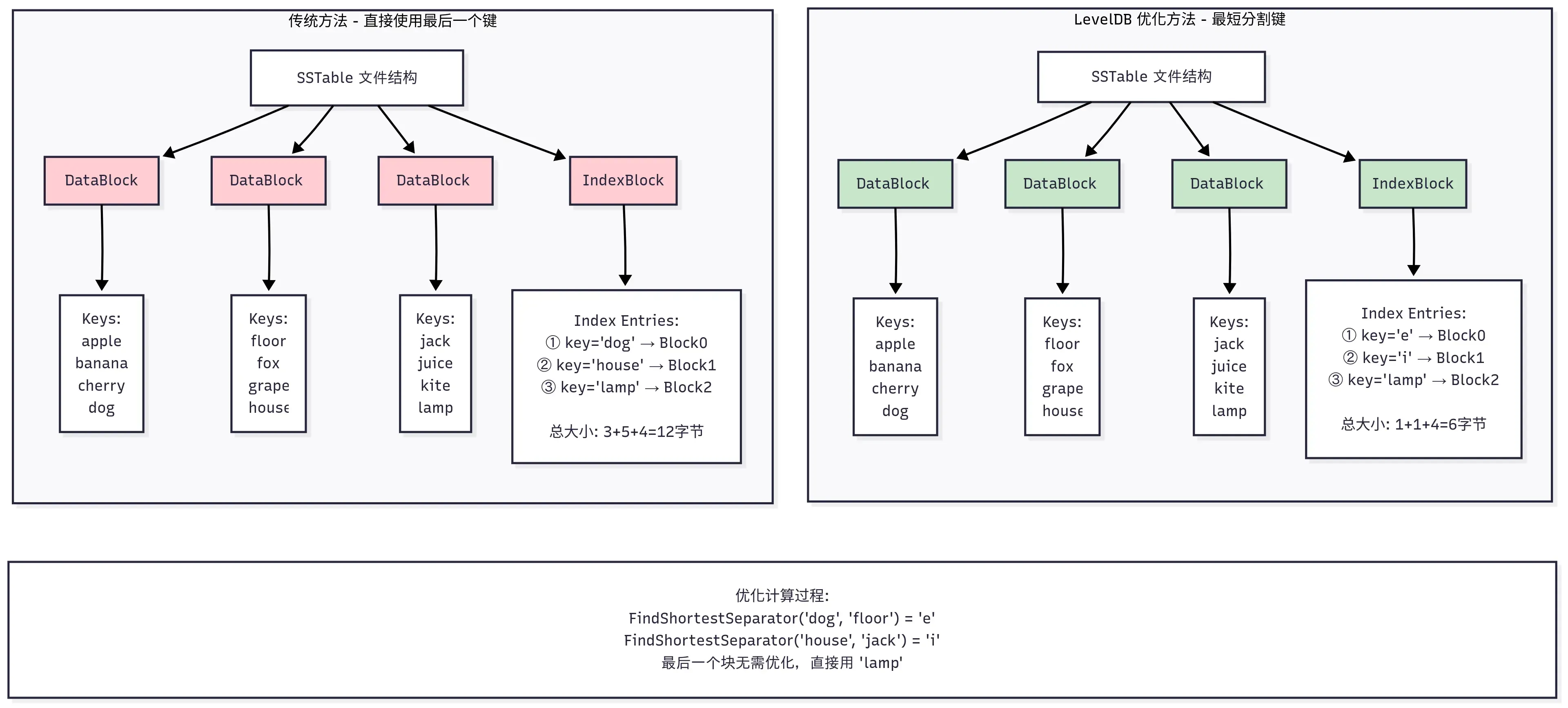
这里扩展讲下背景可能更好理解,SSTable 中每个索引记录都由一个分割键 separator_key 和一个指向数据块的 BlockHandle(偏移量+大小)组成。这个 separator_key 的作用就是划分不同 Datablock 的键空间,对于第 N 个数据块(Block N),它的索引键 separator_key_N 必须满足以下条件:
- separator_key_N >= Block N 中的任何键
- separator_key_N < Block N+1 中的任何键
这样在查找一个目标键的时候,如果在索引块中找到第一个 separator_key_N > target_key 的条目,那么 target_key 如果存在,就必定在前一个数据块(Block N-1)中。
直观上讲,索引最简单的实现是直接用 Block N 的最后一个键(last_key_N)作为 separator_key_N。但问题是,last_key_N 本身可能非常长。这就导致索引项会很长,进而整个索引块变得很大。索引块通常需要加载到内存中,索引块越小,内存占用越少,缓存效率越高,查找速度也越快。
其实我们细想下,我们并不需要一个真实存在的键作为分割索引 key,只需要一个能把前后两个块分开的”隔离键”即可。这个键只需要满足:last_key_N <= separator_key < first_key_N+1。LevelDB 就是这样做的,这里通过调用 options.comparator->FindShortestSeparator,找到前一个块最后的键,和下一个块第一个键之间最短分割字符串。这里 FindShortestSeparator 的默认实现在 util/comparator.cc中,本文不再列出来了。
为了更清楚地理解这个优化过程,下面用一个具体的例子来演示:
最后再聊下这里每条索引记录的 value,它是该块在文件内的偏移和 size,这是通过 pending_handle 来记录的。当通过 WriteRawBlock 将 DataBlock 写文件的时候,会更新 pending_handle 的偏移和大小。然后写索引的时候,用 EncodeTo 将偏移和 size 编码到字符串中,和前面的索引 key 一起插入到 IndexBlock 中。
处理过滤记录
接着处理 FilterBlock 过滤索引块,前面的索引块只是能找到键应该在的块的位置,还需要去读出块的内容才知道键到底存不存在。为了快速判断键值在不在,LevelDB 支持了过滤索引块,可以快速判断某个 key 是否存在于当前 SSTable 中。如果设置用到过滤索引块,则在添加 key 的时候,同步添加索引,其核心代码如下:
1 | if (r->filter_block != nullptr) { |
这里添加 key 之后,只是在内存中存储索引,要等到最后 TableBuild 写完所有的 Block 之后,才会将 FilterBlock 写入文件。FilterBlock 本身是可选的,通过 options.filter_policy 来设置。在初始化 TableBuilder::Rep 的时候,会根据 options.filter_policy 来初始化 FilterBlockBuilder 指针,如下:
1 | Rep(const Options& opt, WritableFile* f) |
这里值得注意的是 filter_block 之所以是指针,主要是因为除了用默认的布隆过滤器,还可以用多态机制使用自己的过滤器。这里用 new 在堆上创建的对象,为了防止内存泄露,在 TableBuilder 析构的时候,先释放掉 filter_block,再接着释放 rep_。
1 | TableBuilder::~TableBuilder() { |
之所以需要释放 rep_,是因为它是在 TableBuilder 构造的时候,在堆上创建的,如下:
1 | TableBuilder::TableBuilder(const Options& options, WritableFile* file) |
关于 LevelDB 默认的布隆过滤器实现,可以参考LevelDB 源码阅读:布隆过滤器的实现。索引块的构建,后面我单独写一篇来详解,这里我们也不深究细节部分。
处理数据块
接着需要将键值对添加到 DataBlock 中。DataBlock 是 SSTable 文件中存储实际键值对的地方,代码如下:
1 | r->last_key.assign(key.data(), key.size()); |
这里调用 BlockBuilder 中的 Add 方法,将键值对添加到 DataBlock 中,关于 BlockBuilder 的实现,后面单独文章来描述。哈哈,这里 LevelDB 分层抽象是做的真好,搞的我们的文章也只能分层了。每次添加键值对后,都会检查当前 DataBlock 的大小是否超过了 block_size,如果超过了,则调用 Flush 方法将 DataBlock 写入磁盘文件。这里 block_size 是在 options 中设置的,默认是 4KB。这个是键值压缩前的大小,如果开启了压缩,实际写入文件的大小会小于 block_size。
1 | // Approximate size of user data packed per block. Note that the |
这里 Flush 怎么写磁盘呢,我们接着往下看。
Flush 写数据块
在前面的 Add 方法中,如果一个块的大小凑够 4KB,就会调用 Flush 方法写磁盘文件。Flush 的实现如下:
1 | void TableBuilder::Flush() { |
开始部分也就是一些前置校验,注意 Flush 只是用来刷 DataBlock 部分,如果 data_block 为空,就直接返回。接着调用 WriteBlock 方法(后面详解)将 DataBlock 写入文件,然后更新 pending_index_entry 为 true,表示下次添加 key 时,需要更新索引块。
最后调用 file->Flush() 将目前内存中的数据调用系统 write 写磁盘,注意这里不保证数据已被同步到物理磁盘。数据可能还在系统缓存中,如果操作系统宕机,那有可能丢失没写入成功的数据。这里写文件刷磁盘,可以参考本系列LevelDB 源码阅读:Posix 文件操作接口实现细节中关于文件操作的更多细节。如果有 filter_block,还需要调用 StartBlock 方法,这个方法也比较有意思,等后面我们专门来写 filter block 的时候再详细说明。
WriteBlock 写文件
上面提到 Flush 中会调用 WriteBlock 方法将 DataBlock 写入文件,该方法在下面要提到的 Finish 中也会被调用,用来在最后写索引块,过滤块等内容。WriteBlock 的实现比较简单,主要用来处理压缩逻辑,然后调用真正的写文件函数 WriteRawBlock 来把块内容写入文件。
压缩并不是必须的,如果调用 leveldb 时设置了需要压缩,并且链接了压缩库,就会选择对应的压缩算法对 Block 进行压缩。LevelDB 这里也做了一点压缩性能和效果的平衡,如果压缩比 (compression_ratio) 小于等于 0.85,就会将压缩后的数据写入文件,否则直接写入原始数据。真正写文件部分,调用 WriteRawBlock 方法,主要代码如下:
1 | void TableBuilder::WriteRawBlock(const Slice& block_contents, |
这里在每个块的尾部放了 5 个字节的 trailer 部分,来对数据准确性进行校验。第一个字节是压缩类型,目前支持的压缩算法有 snappy 和 zstd。后面 4 字节是 crc32 校验和,这里用 crc32c::Value 计算数据块的校验和,然后把压缩类型一起计算进去校验和。这里 crc32 部分,可以参考本系列 LevelDB 源码阅读:内存分配器、随机数生成、CRC32、整数编解码 了解更多细节。
Finish 主动触发落盘
上面的所有操作,主要用来将键值对不断添加到数据块中,这个过程如果达到 DataBlock 的大小限制,会触发 DataBlock 的落盘。但整个 SSTable 文件还有索引块,过滤块等,需要主动触发落盘。那在什么时机触发,又是怎么落盘呢?
LevelDB 中产生 SSTable 文件的时机有很多,这里以保存 immetable 时候触发的落盘时机为例。将 immemtable 保存为 SSTable 文件时,过程如下:首先迭代 immemtable 中的键值对,然后调用上面的 Add 方法来添加。Add 中会更新相关 block 的内容,每当 DataBlock 超过 block_size 时,会调用 Flush 方法将 DataBlock 写入文件。
等所有键值对写完,会主动调用 Finish 方法,来进行一些收尾工作,比如将最后一个 Datablock 的数据写入文件,写入 IndexBlock,FilterBlock 等。
Finish 的实现如下,开始之前先用 Flush 把剩余的 DataBlock 部分刷到磁盘文件中,接着会处理其他块,并且在文件尾部添加一个固定大小的 footer 部分,用来记录索引信息。
1 | Status TableBuilder::Finish() { |
这里构建各个块也比较有意思,都是用一个 builder 来处理内容,同时用一个 handler 来记录块的偏移和大小。我们分别来看下。
BlockBuilder 构建块
先思考一个问题,这里有这么多类型的块,每个块都要一个自己的 Builder 来拼装数据吗?
这里要从每个块的数据结构来看,Data/Index/MetaIndex Block 这三种块都具有以下共同特征:
- 键值对结构:都存储键值对形式的数据,虽然这里每个块里面的键值含义不一样,但都是键值对形式;
- 有序性要求:键必须按顺序排列,因为后面查找的时候,需要支持二分查找或顺序扫描;
所以这 3 类块的构建逻辑是类似的,LevelDB 中共用同一个 BlockBuilder 来处理。这里实现在 table/block_builder.h 中,也有不少优化细节。比如前缀压缩优化,对于相似的键只存储差异部分,节省空间。重启点机制,每隔几个条目设置一个重启点,支持二分查找。后面我会专门用一篇文章来详细说明。封装后用起来比较简单,以 MetaIndex Block 为例,用 Add 添加键值,然后 WriteBlock 落磁盘就好。代码如下:
1 | void TableBuilder::Finish() { |
而 filter block 的数据结构和其他的都不一样,它存储的是布隆过滤器的二进制数据,按文件偏移分组,每 2KB 文件范围对应一个过滤器。所以 filter block 的构建逻辑和其他的都不一样,需要单独处理。这里的实现在 table/filter_block.cc 中,后面我单独再展开分析。这里使用倒是很简单,如下:
1 | // Write filter block |
这里 Finish 方法会返回 filter block 的二进制数据,然后调用 WriteRawBlock 方法将数据写入文件。
BlockHandle 记录偏移和大小
上面用两个 builder 来构建块,但是用同一个 handler 类来记录块的偏移和大小。代码如下:
1 | BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle; |
这里 BlockHandle 的实现在 table/format.h 中,主要告诉系统在文件的第 X 字节位置,有一个大小为 Y 字节的块,仅此而已。不过配合不同块的 handle 信息,就能方便存储不同块的偏移和大小。
至此,我们用两个 builder 来构建各种索引块,同时用一个 handler 来辅助记录块的偏移和大小。就完成了整个块的构建。
创建 SSTable 文件完整步骤
最后我们可以来看看上层调用方,是如何用 TableBuilder 来构造 SSTable 文件的。
在 db/builder.cc 中封装了一个函数 BuildTable 来创建 SSTable 文件,它就是调用 TableBuilder 类的接口来实现的。省略其他无关代码,核心代码如下:
1 | Status BuildTable(const std::string& dbname, Env* env, const Options& options, |
这里用迭代器 iter 来遍历 immemtable 中的键值对,然后调用 TableBuilder 的 Add 方法将键值对添加到 SSTable 文件中。Memtable 的大小限制默认是 4MB(write_buffer_size = 4*1024*1024),在用 TableBuilder 添加键值对时,会根据 block_size(4*1024) 来划分数据块。每当凑够一个 DataBlock,就会拼装相应 block 的数据,然后用 flush 追增内容到磁盘 SSTable 文件中。最后调用 TableBuilder 的 Finish 方法写入其他 Block,完成整个SSTable 文件的写入。
除了这里 BuildTable 将 immemtable 中的数据写入 level0 的 SSTable 文件外,还有一个场景是在 Compact 过程中,将多个 SSTable 文件合并成一个 SSTable 文件。这个过程在 db/db_impl.cc 中的 DoCompactionWork 函数中实现,整体流程稍微复杂,调用比较深入,等后面我们讲 Compact 的时候再详细分析。
不过这里只讲一个点,在 Compact 过程中,会在某些失败场景调用 TableBuilder 的 Abandon 方法,用来放弃当前的 TableBuilder 写入文件过程。
1 | compact->builder->Abandon(); |
Abandon 主要就是把 TableBuilder 的 Rep 中的 closed 设置为 true,调用方之后就会丢掉这个 TableBuilder 实例,不会用它执行任何写入操作了(写入中一堆断言来检查这个状态)。
总结
回到开头我们提出的问题,文件格式该如何设计,才能兼顾高效写入和快速读取?通过深入分析 LevelDB 的 SSTable 文件创建过程,我们可以看到作者是如何一步步解决这个问题的。首先SSTable 数据格式设计有几个重要的设计思想:
- 分块存储:将大文件切分成 4KB 的 DataBlock,既便于管理,又能减少无效的磁盘 I/O,还方便缓存热点数据。
- 索引加速:通过 IndexBlock 将”全文扫描”变成”查目录 + 精准读取”,减少磁盘 I/O 次数。
- 过滤优化:用 FilterBlock 在源头减少不必要的磁盘读取,提高读取性能。
- 元信息集中管理:Footer + Meta-IndexBlock 的设计保证了扩展性,方便后续添加更多元数据块。
在 TableBuilder 的实现中,我们也看到了不少值得学习的工程细节,比如:
- 索引键优化:延迟到下一个块开始时才更新索引,通过 FindShortestSeparator 算法生成最短分割键,大幅减少索引块大小。这个优化看似微小,但在大规模数据下效果显著。
- 错误处理:代码中大量的 assert 断言体现了”早崩溃早发现”的理念,对于底层存储系统来说至关重要。
- 分层抽象:TableBuilder → BlockBuilder → FilterBlockBuilder 的分层设计,让复杂的文件格式构建变得井井有条。每一层都有明确的职责边界。
- 性能平衡:压缩策略中的 0.85 压缩比阈值,体现了对性能与效果的权衡考量。
其实 SSTable 的设计回答了存储系统中的几个根本问题。用顺序写入,来保证写入吞吐,用索引结构来保证读取性能。用分块和按需加载以及缓存,在有限内存下处理海量数据。同时用压缩和过滤器来平衡存储空间与查询效率,用元信息分层来保证系统的可扩展性。这些都是计算机软件系统中沉淀多年的经典设计,值得我们学习。
理解了 SSTable 的创建过程后,你可能会产生一些新的疑问:DataBlock 内部是如何组织数据的?读取 SSTable 时的流程是怎样的?多个 SSTable 文件如何协同工作?
这些问题的答案,构成了 LevelDB 这个精巧存储引擎的完整图景。我会在后面的文章中继续深入分析,敬请期待。

