Redis Deadlock Problem Caused by Stream Data Read and Write (2)
In Redis Issue Analysis: “Deadlock” Problem Caused by Stream Data Read and Write (1), we successfully reproduced the bug mentioned in the Issue, observing that the Redis Server CPU spiked, unable to establish new connections, and existing connections couldn’t perform any read or write operations. With the help of powerful eBPF profile tools, we observed where the CPU time was mainly consumed. Now, let’s take a look at the debugging process and fix for this bug.
Debugging the bug
Considering that the Redis server process is still running, we can use GDB to attach to the process and set breakpoints to see the specific execution process. In the flame graph, we saw that the time-consuming handleClientsBlockedOnKey function contains a while loop statement. Since CPU spikes are usually caused by infinite loops, to verify if there’s an infinite loop in this while statement, we can set breakpoints at line 565 before the while loop and line 569 inside it, then continue multiple times to observe.
1 | while((ln = listNext(&li))) { |
We see that it always pauses at line 569 inside the loop, basically confirming that an infinite loop is occurring here. Looking at the local variables on the current stack frame, we can see the receiver pointer. Specifically: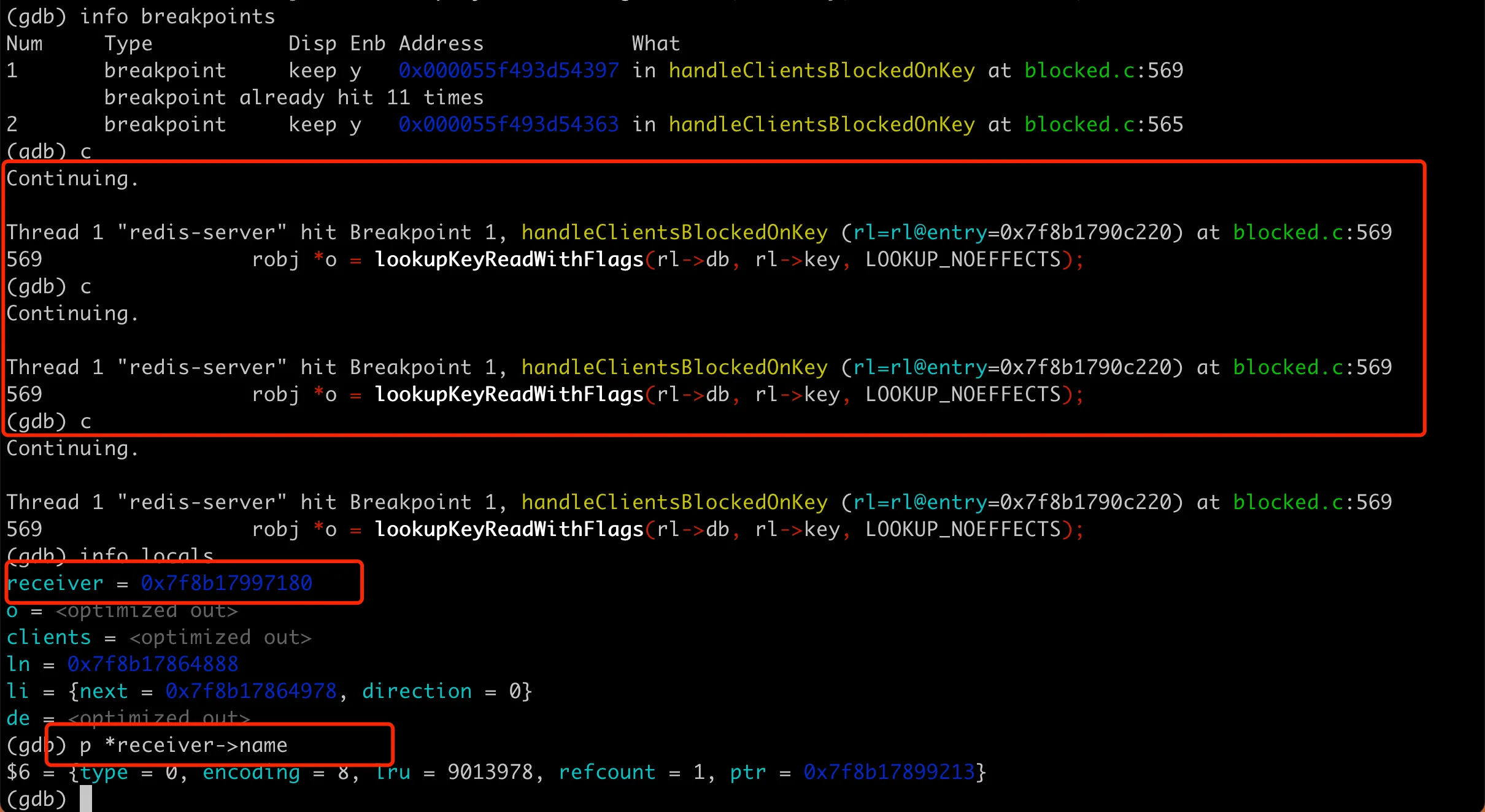
Here, receiver is a struct client declared in server.h, which is the data structure maintained by Redis for each client connection. The problem is now clear: the server process keeps taking out client connections in the while loop and can’t stop. To understand where these clients come from, we can print the name field in the client.
1 | typedef struct client { |
However, this needs to be set when the client connects, so let’s modify our test script from Redis Issue Analysis: “Deadlock” Problem Caused by Stream Data Read and Write (1), restart the server, run the reproduction process, and then re-analyze with GDB.
1 | def subscriber(user_id): |
GDB prints out the receiver’s name as follows:
1 | (gdb) p *receiver->name |
Here, name is a redisObject. Based on type=0 and encoding=8, we know that this name is actually a string, stored in memory at the ptr pointer.
1 | // object.c |
Then we can use p (char *)receiver->name->ptr to print the specific name of the client. Here we need to print the client name multiple times continuously to see what client is taken out each time. To print automatically multiple times, we can use the commands instruction in GDB, as shown in the following image:
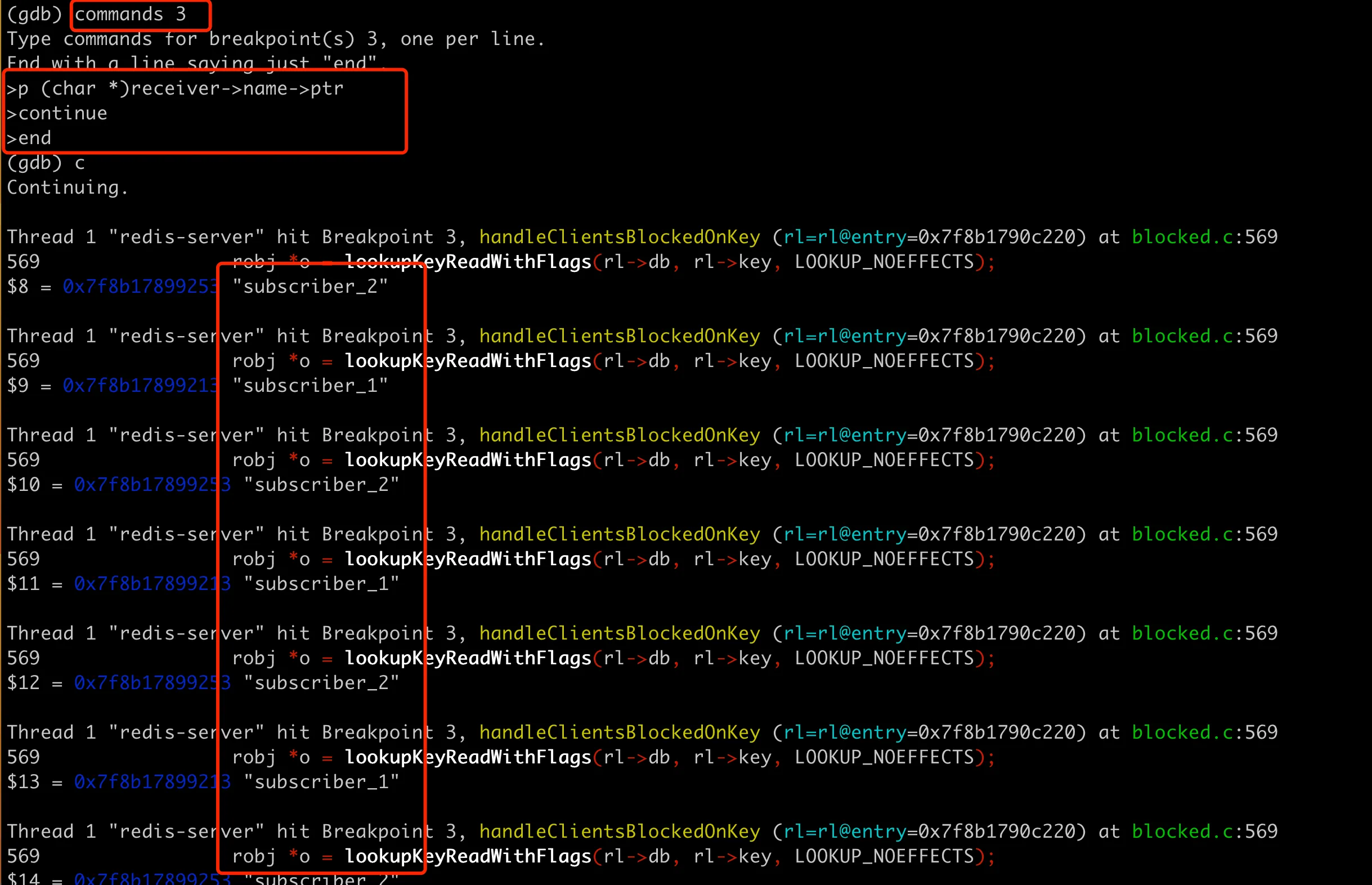
In fact, subscriber_1 and subscriber_2 are always taken out from the queue alternately, endlessly, so it can’t break out of the loop.
Fix the code
The fix used here is a rather tricky method, ensuring that only the clients currently in the queue at this moment are processed, and newly added clients are not processed. The specific commit is commit e7129e43e0c7c85921666018b68f5b729218d31e, and the commit message describes this issue:
Author: Binbin binloveplay1314@qq.com
Date: Tue Jun 13 18:27:05 2023 +0800
Fix XREADGROUP BLOCK stuck in endless loop (#12301)For the XREADGROUP BLOCK > scenario, there is an endless loop.
Due to #11012, it keep going, reprocess command -> blockForKeys -> reprocess commandThe right fix is to avoid an endless loop in handleClientsBlockedOnKey and handleClientsBlockedOnKeys,
looks like there was some attempt in handleClientsBlockedOnKeys but maybe not sufficiently good,
and it looks like using a similar trick in handleClientsBlockedOnKey is complicated.
i.e. stashing the list on the stack and iterating on it after creating a fresh one for future use,
is problematic since the code keeps accessing the global list.Co-authored-by: Oran Agra oran@redislabs.com
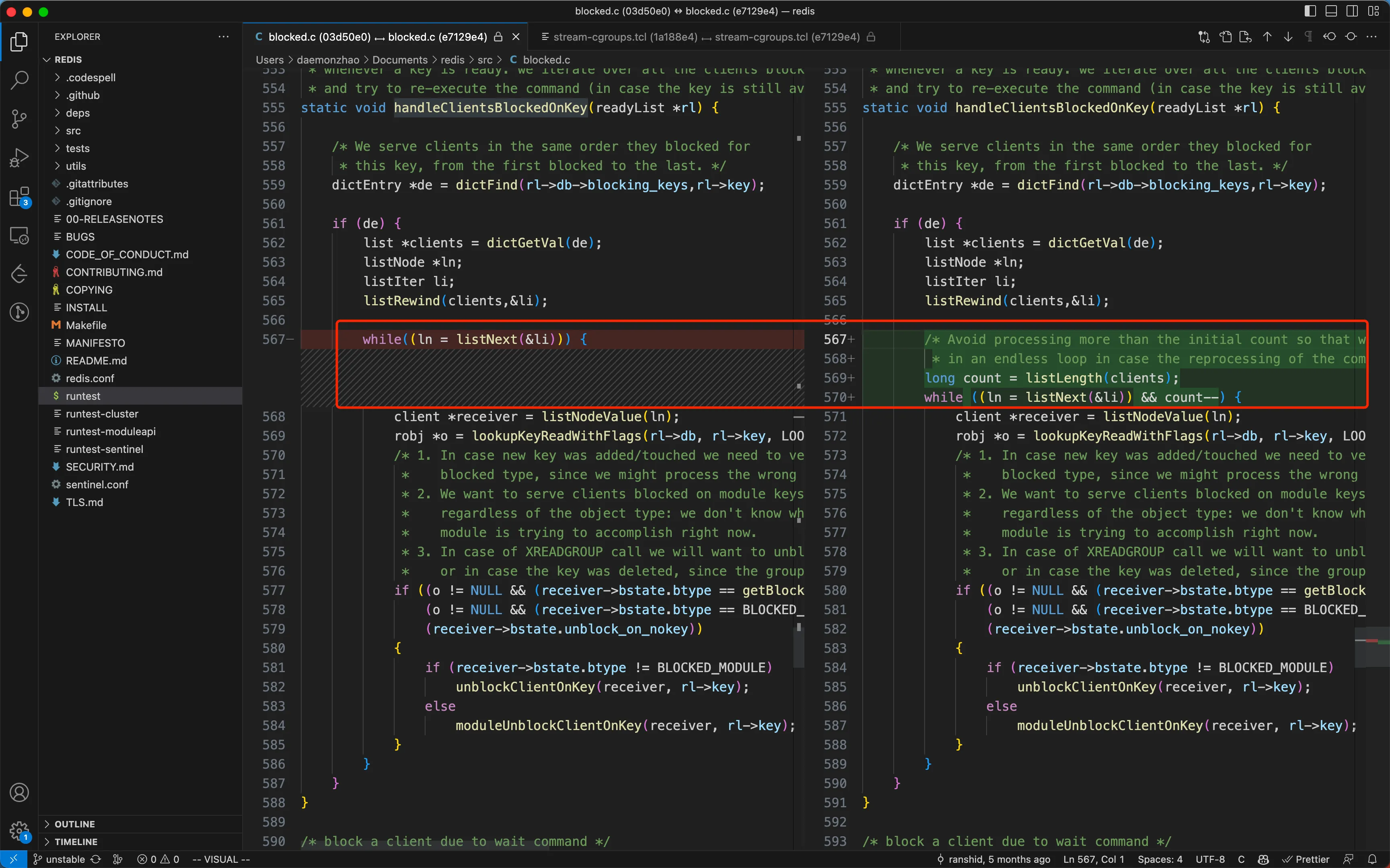
The changes in the commit are relatively minor, as shown below:
When are elements added to the list?
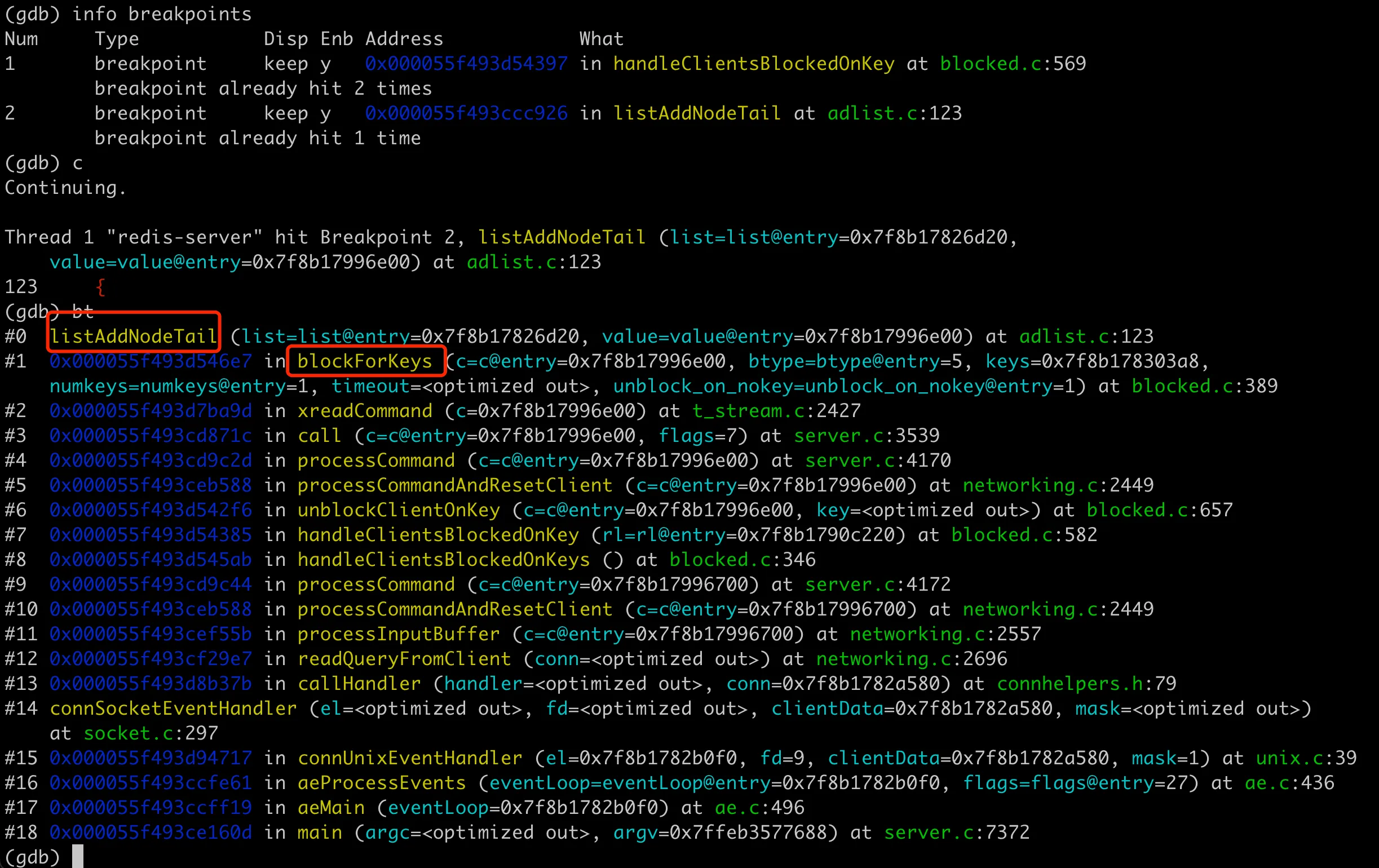
There’s another question that needs to be clarified: when exactly are the clients that have been taken out of the queue put back into the queue? Because I’m not very familiar with the Redis source code, I couldn’t find the relevant code after looking for a while at first. I asked about this on the Issue, and oranagra came out to explain that it’s in blockForKeys (actually, this function is mentioned in the commit message).
When I thought about this later, I realized I could have found it myself. Because the list is definitely continuously adding clients in the loop, and the function for adding elements to the tail of the list in Redis is easy to find, it’s listAddNodeTail:
1 | // adlist.c |
We just need to set a breakpoint on this function, and when it executes here, we can get the function stack and know the call relationship, as shown in the following image:
Is breaking out of the loop enough?
There’s another question: in the fix solution here, during a single handleClientsBlockedOnKey function processing, the client will still be appended to the queue tail (there’s actually no change here). So why won’t these two clients be taken out again in the modified code?
TODO…(To be continued)
Test case
The official team also added a tcl test case script, adding the following case in tests/unit/type/stream-cgroups.tcl:
1 | test {Blocking XREADGROUP for stream key that has clients blocked on list - avoid endless loop} { |
The test logic here is basically the same as the reproduction script, creating 3 clients blocked in xreadgroup, and then using another client to add 3 sets of data. Then it closes the consumer clients and tries to send a ping message with the client that added data to see if there’s a pong reply. If this bug still exists, sending ping would not get any response.
You can run ./runtest --single unit/type/stream-cgroups in the redis-7.2-rc2 directory to test this newly added case group. The execution result is as follows:
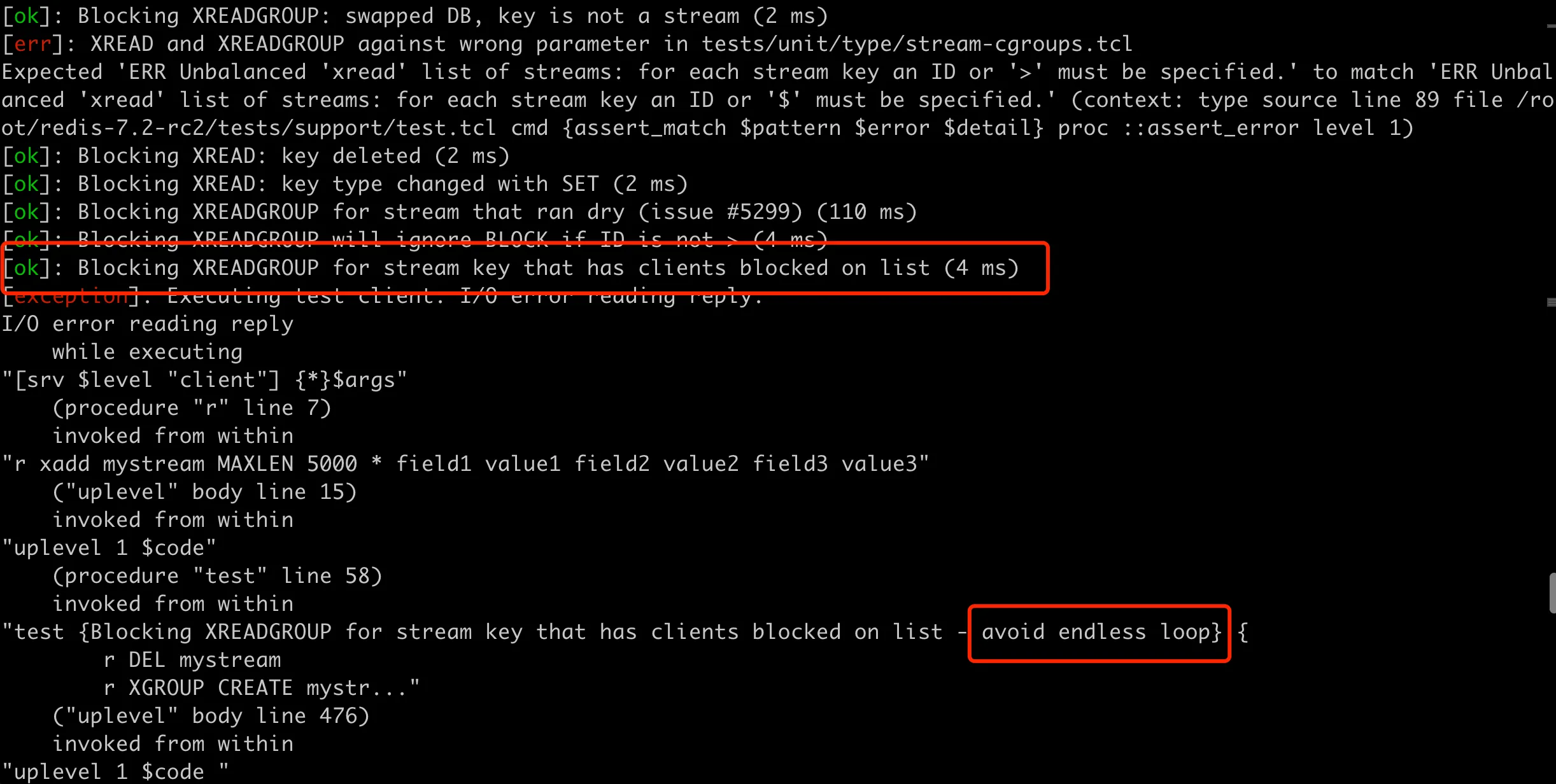
After executing the group of test cases before the newly added one, the test case got stuck, and then we saw that the CPU usage of the Redis process was also 100%, indicating that this test case can fully reproduce this problem. Here’s an additional point: in the TCL test, the Redis binary file used is located in the src subdirectory of the Redis source code directory. Specifically, it’s found through the following command in the TCL script:
1 | set ::redis [file normalize [file join [pwd] ../src/redis-server]] |
It connects the parent directory of the current directory (i.e., the root directory of the Redis source code) with src/redis-server to form the complete path of the Redis binary file. This means it uses the Redis version you compiled yourself, not any version that might already be installed on the system.

