Dive into the ChatGPT Data Leak caused by Redis Bug
On March 20, 2023, OpenAI’s ChatGPT service was interrupted for a period of time. Subsequently, OpenAI published an announcement March 20 ChatGPT outage: Here’s what happened explaining the ins and outs of this incident. In the announcement, OpenAI detailed the scope of impact, remediation strategies, some technical details, and improvement measures for this incident, which is quite worth learning from.
The specific timeline of this incident handling is also publicly available on ChatGPT Web Interface Incident, as shown in the following image:

This fault was caused by a bug in Redis’s Python client, and there are discussions about this bug on Github. The fixing process of this bug was not smooth, with many discussions and fix attempts, such as Issue 2624, PR 2641, Issue 2665, PR 2695. After reading these, I still couldn’t fully understand the fix here, so I had to delve into the code to see what exactly happened with the bug’s cause and fixing process, and organize it into this article.
Public Disclosure of the Incident
Before starting to analyze the Python bug, I’d like to talk about OpenAI’s incident dashboard. OpenAI provides a status check page where you can see the current health status of various services. This is done quite well in foreign countries, with many services having status dashboards, such as Github and Google Cloud.
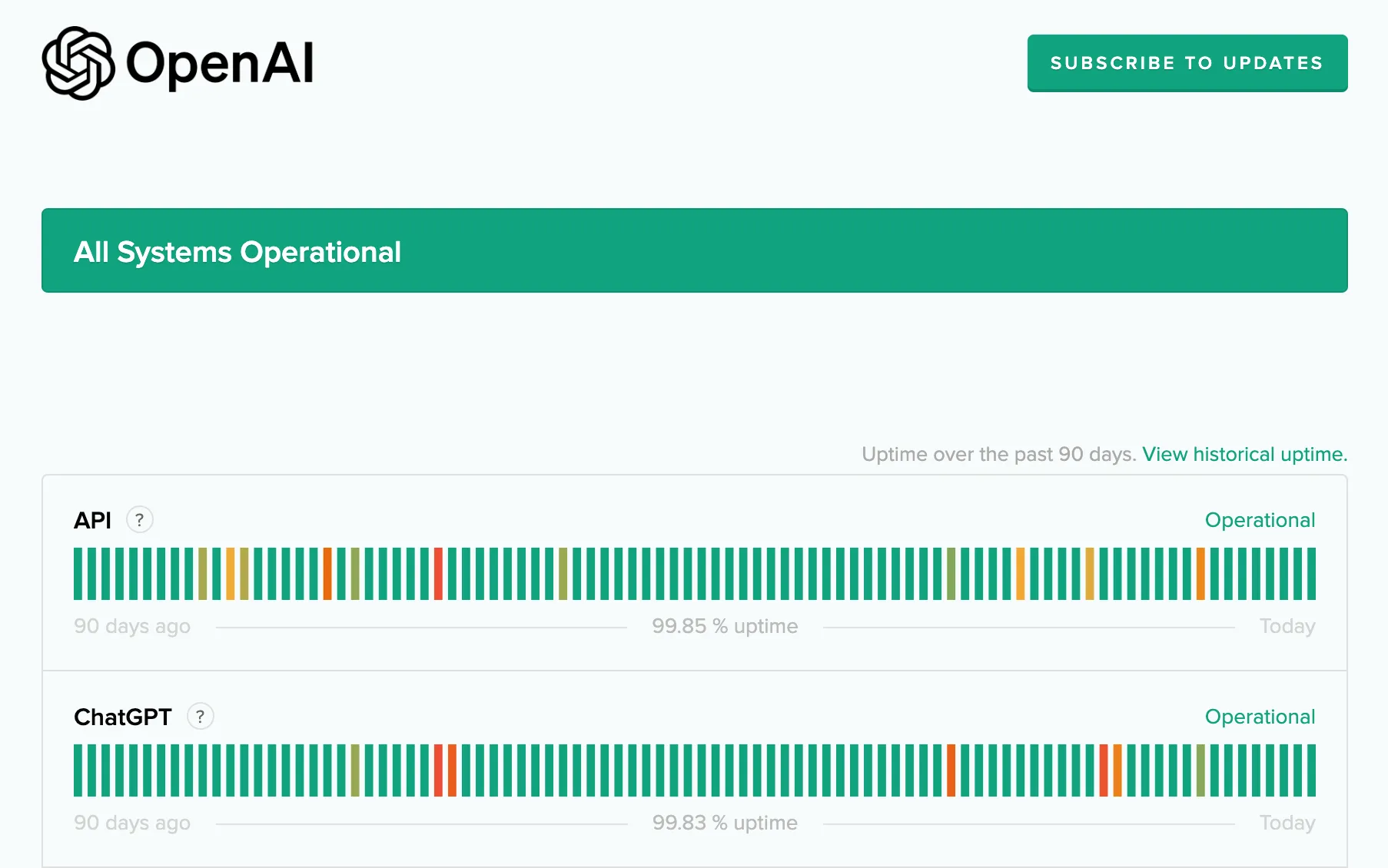
When encountering ChatGPT not working, you can come here first to check the current service status. If the service has no problems, it’s generally your own network or account issues. Once there’s a service problem, you can see the progress of the incident here. In contrast, many services in China tend to cover up problems if possible, fearing that users will know about the fault.
This incident was quite serious, and OpenAI CEO Sam Altman also made a brief statement:
we had a significant issue in ChatGPT due to a bug in an open source library, for which a fix has now been released and we have just finished validating.
a small percentage of users were able to see the titles of other users’ conversation history.
we feel awful about this.
Incident Details
OpenAI later wrote an article: March 20 ChatGPT outage: Here’s what happened detailing this incident. Initially, it was discovered that some users could view titles from other users’ chat conversations, and if two users were active at the same time, the first message of a new conversation might also be seen by others. Later, it was found that during a specific 9-hour period, about 1.2% of active ChatGPT Plus users had their payment information seen by others. This payment information included: name, email address, payment address, credit card type and the last four digits of the credit card number, and credit card expiration date.
Of course, the number of people whose payment information was leaked was actually extremely small, as the trigger conditions were quite strict, only in the following two situations:
- Opening the subscription confirmation email sent by OpenAI between 1 am and 10 am on March 30, 2023, which might contain other people’s credit card type and the last four digits of the card number (fortunately not the full card number).
- Clicking on “My Account” on the ChatGPT chat page between 1 am and 10 am on March 30, 2023, and entering “Manage My Subscription”. At this time, one might see other Plus users’ first and last names, email addresses, payment addresses, credit card types and the last four digits of the credit card number (only), as well as credit card expiration dates.
The entire incident handling timeline is publicly available at ChatGPT Web Interface Incident.
Cause of the Incident
OpenAI provided some technical details about how this incident occurred:
- User information was cached in Redis to avoid querying the database each time.
- Redis was deployed in cluster mode, with the load distributed across many Redis instances.
- The service was developed in Python, using the Asyncio asynchronous I/O library and the redis-py library to access Redis.
- The service maintained a connection pool to the Redis cluster using the redis-py library, reusing connections to handle requests.
- When using Asyncio to asynchronously handle redis-py requests, requests and responses can be viewed as two queues, with each request and response corresponding one-to-one in the two queues.
- If a request has already been queued to the Redis server but is cancelled before the response is dequeued, the correspondence between requests and responses in this connection will be confused. Subsequent requests may read responses from completely unrelated previous requests.
- In most cases, because the read data is inconsistent with the expected request, an error will be returned.
- In some coincidental cases, the erroneously read data happens to be consistent with the expected data type of the request, and although it’s not information from the same user, it will be displayed normally.
- At 1 am on March 20, 2023, after a service change, the number of redis request cancellations surged, leading to instances of returning incorrect data (with a very low probability);
The key points are in the 5th and 6th points, and we’ll delve deeper into the reproduction and fixing process of this bug in redis-py later.
Incident Handling
OpenAI’s handling of this incident is also worth learning from. First, they emphasized protecting users’ privacy and data security, acknowledged that they failed to do so this time, sincerely apologized, and sent emails to notify all affected users (not sure if there was any substantial compensation).
On the technical side, after finding the specific cause, they also reinforced the protection here. Specifically:
- Tested whether the fix was effective;
- Added data validation to ensure that the requested user and the user in the Redis cache are the same;
- Analyzed logs to ensure messages are not seen by unauthorized people;
- Accurately identified affected users through multiple data sources, then notified them;
- Added some logs to ensure the problem was thoroughly resolved, and if this problem occurs again, it can be discovered immediately;
- Improved the robustness of the Redis cluster to reduce connection errors under extreme load conditions.
Next, we will focus on this bug in redis-py to see how to reproduce and fix it.
Bug Reproduction
drago-balto reported this bug in the redis-py client on March 17 in Issue 2624. Simply put, if the Redis client sends an asynchronous request and cancels it before receiving and parsing the response, subsequent commands on this connection will fail.
If async Redis request is canceled at the right time, after the command was sent but before the response was received and parsed, the connection is left in an unsafe state for future commands.
To reproduce this issue, we first need a redis server, which can be installed locally and started with the default configuration. Note that if your local redis is not configured with a password and ssl, you need to change the redis connection part to the commented code. Then create a Python virtual environment using conda, install version 4.5.1 of redis-py with pip install redis==4.5.1. After that, you can use the following script to reproduce the bug:
1 | import asyncio |
The above script uses the same client connection to execute multiple commands in succession. Among them, it asynchronously executes r.get('foo') and calls cancel to cancel this query during execution, then executes other commands. By observing the results of subsequent commands, we can know if there’s a problem here. Note that when await t, it tries to catch the exception asyncio.CancelledError. If this exception is caught, it means the asynchronous task was successfully cancelled before r.get('foo') completed. If there’s no exception, it means the redis read task has already completed, and cancel did not successfully cancel the asynchronous task. A key point here is asyncio.sleep(0.001), which waits for a period of time to allow the asynchronous read request to be received and executed by the server, but be successfully cancelled before receiving the server’s response.
If the Redis server is in a cloud environment with latency > 5ms, then sleep(0.001) here can reproduce the problem. My Redis client and server are both on the same machine, so network latency can be ignored. Through continuous experimentation, I found that asyncio.sleep(0.000001) here can stably reproduce the issue. Below are the execution results with different sleep times on my local machine:

We can see that in the case of sleep(0.000001), all subsequent Redis command results are incorrect, with each command being the result of the previous command. Going back to OpenAI’s fault description, this explains why one person saw another person’s data. Because there were cancelled redis asynchronous request tasks in between, causing the results to be mixed up and read incorrectly.
Source Code Analysis
I hadn’t really understood the implementation of redis-py before, so to quickly locate the cause of this bug, the best way is to add logs. To immediately see the effect of code changes, first clone the redis-py repository locally, then use the git checkout v4.5.1 command to switch to the 4.5.1 branch. Then create a new virtual environment with conda, install the local library in this new environment using pip install -e ., with -e ensuring that local code changes will take effect immediately.
The official redis-py library is written quite clearly, and starting from client.py, we can quickly find some clues. For example, the execute_command function should be executing a specific command, and we can confirm this by adding a log print("execute_command finally", *args) in the finally code block.
Command Parsing Process
The next critical part should be in _send_command_parse_response, where we can see that it first sends the command and then parses the response.
1 | async def _send_command_parse_response(self, conn, command_name, *args, **options): |
There’s no problem with the part that sends the command, it’s irrelevant to our bug, so we can skip it and mainly look at the response parsing part. Looking directly at the code, there are too many interfering factors, and it’s difficult to see all the branches. We can combine the code while continuously adding debug logs to organize the processing steps of a request. Finally, by printing the function stack in _read_response, the specific code is as follows:
1 | import traceback |
Through the stack, we can see that the processing chain of an asynchronous redis get request is as follows:
- blog_script/redis_bug.py (line 29) -
main - redis-py/redis/asyncio/client.py (line 514) -
execute_command - redis-py/redis/asyncio/retry.py (line 59) -
call_with_retry - redis-py/redis/asyncio/client.py (line 488) -
_send_command_parse_response - redis-py/redis/asyncio/client.py (line 535) -
parse_response - redis-py/redis/asyncio/connection.py (line 840) -
read_response - redis-py/redis/asyncio/connection.py (line 256) -
_parser.read_response - redis-py/redis/asyncio/connection.py (line 267) -
_read_response
Note that the line numbers in the connection.py part may not match the actual code because some debug code was added, affecting the line number calculation. When cancelling an asynchronous task, we can see that an asyncio.CancelledError exception is thrown, so where exactly is this exception thrown?
Exception Throwing Location
Still through continuous addition of logs, we located connection.py, intuitively it should be in data = await self._stream.readline(), where _stream is an asyncio.StreamReader object, which threw an exception when reading a line of content. How to confirm this? We can try to add a try here to catch the exception, but initially when trying to catch the Exception exception here, it couldn’t be caught. Later I asked ChatGPT and learned that in Python 3.8 and higher versions, asyncio.CancelledError no longer derives from the Exception base class, but directly from BaseException. So I changed to the following code, which verified the guess.
1 | # redis/asyncio/connection.py |
Reason for Data Confusion
The execution flow of a request is now very clear, but we haven’t resolved our question, why does cancelling a task cause subsequent requests to read incorrectly. Let’s continue to add logs here, print the request command at the beginning of each request (add logs in execute_command), and then print the parsed response (_read_response add logs), the result after execution is as follows:
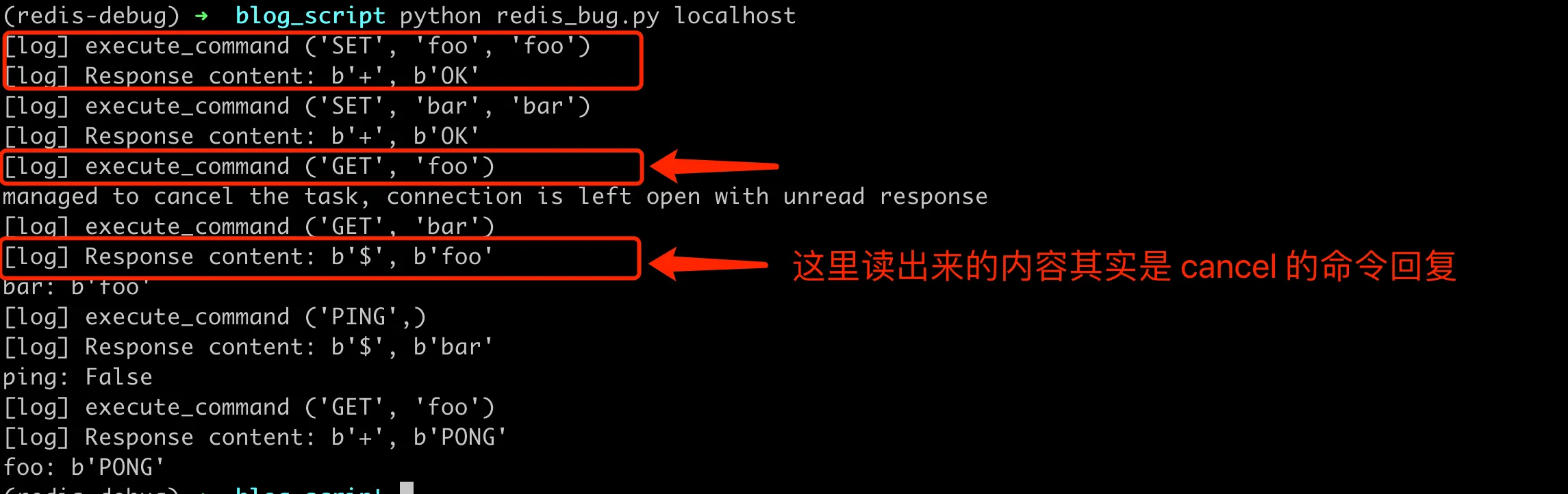
This involves parsing the Redis reply protocol. Redis uses the RESP (Redis Serialization Protocol), which is a simple, efficient, and human-readable text-based protocol. It supports various data types, including strings, arrays, and integers. Both client command requests and server responses follow this protocol. For specific format technical details, you can refer to the official documentation RESP protocol spec.
From the above screenshot, we can see that the root cause of this bug is that if an asynchronous request is successfully processed by the server, an exception is thrown before the reply is read by readline. Subsequent requests will read the reply of this cancelled request when calling readline.
Bug Fix
As I’m not very familiar with the implementation details of Python’s asyncio library and redis-py, I’ll directly look at the official fix code here. However, the official fixing process wasn’t very smooth either, with some problematic fix code and test code in between. Let’s take a look.
Incorrect Fix Attempt
The first fix attempt was in PR 2641, where someone submitted a fix proposal. The key part is:
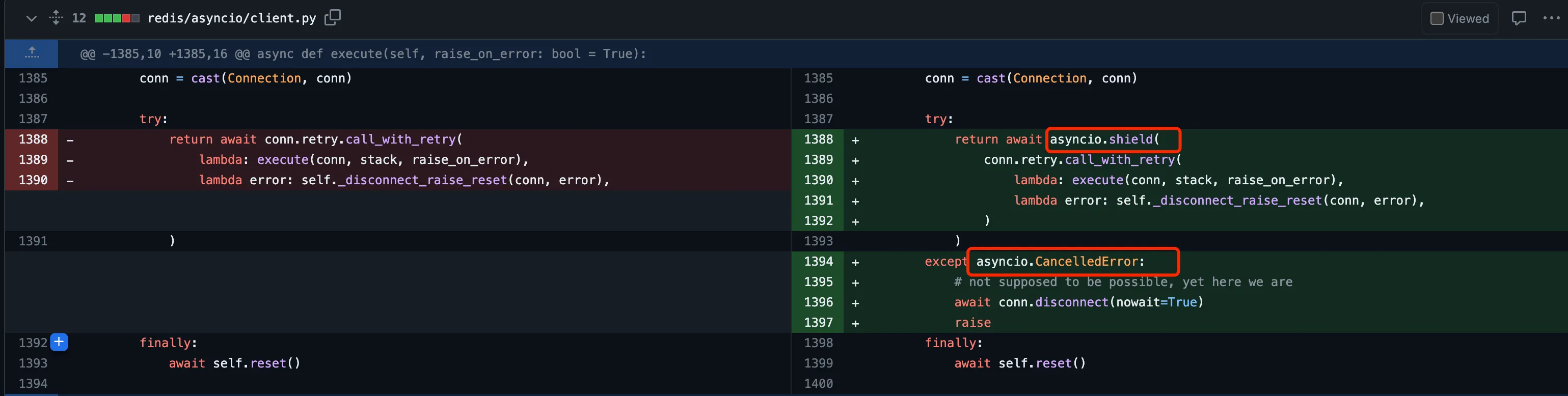
The core idea here is that since cancelling an asynchronous operation would cause the server’s reply to be missed, we should ensure that once we enter the read operation, we don’t allow the asynchronous task (which is actually a coroutine) to be cancelled until this part of the reply is read out. This uses the asyncio.shield function, which is used to protect an asynchronous operation from being cancelled. If an operation is in progress within the asyncio.shield function and other parts attempt to cancel this operation, the cancellation operation will be ignored until the operation within the asyncio.shield function completes and then throws an exception. For a detailed explanation of asyncio.shield, you can refer to the official documentation Shielding From Cancellation.
This fix was merged into version v4.5.3, but the bug could still be reproduced under this version. Looking at the code, the reason is that this fix only added protection for cancellation of the execute function, but not for execute_command in the reproduction script’s execution path. Moreover, this protection scheme itself is problematic, as the modification prevents cancelling a blocked asynchronous request, which in severe cases could even cause read requests to get stuck.
The submitter of this solution also provided test cases, but there were problems with the test cases, which failed to detect this bug.
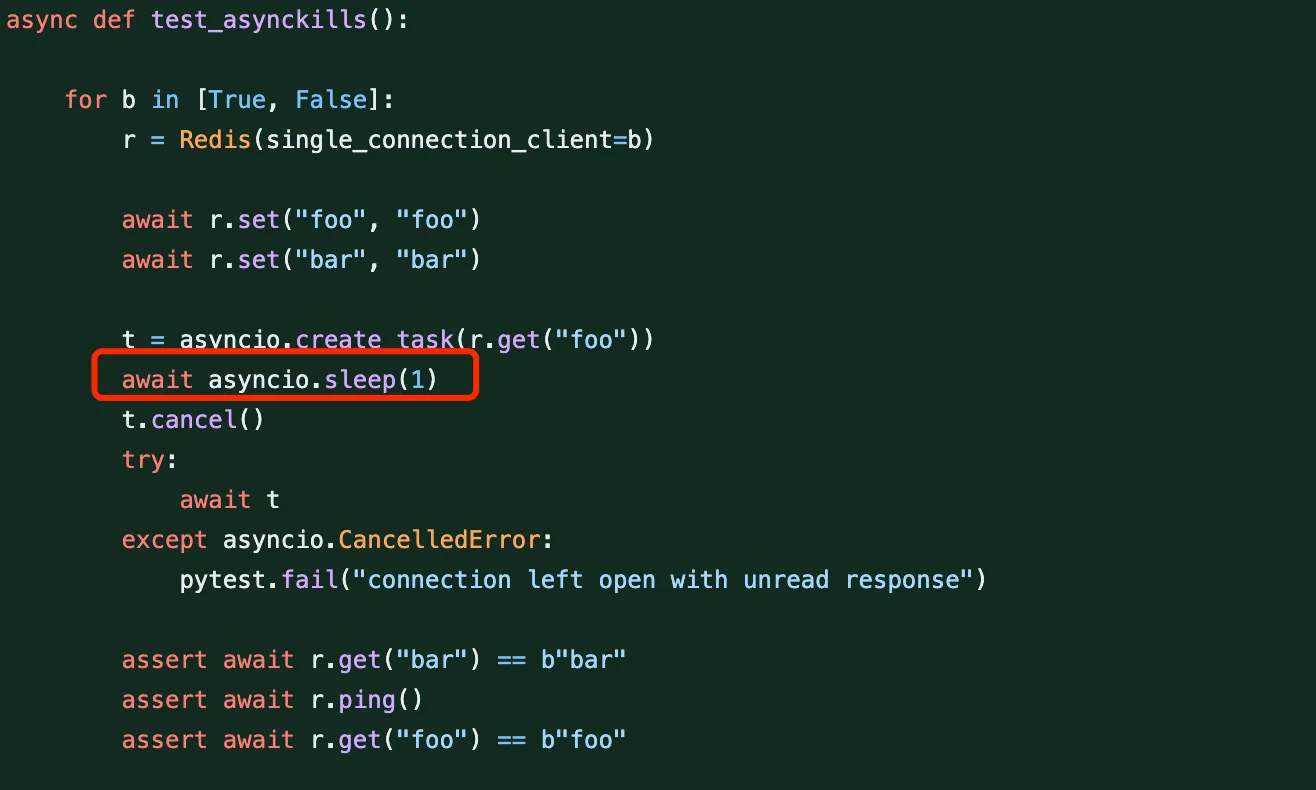
The sleep time here is 1s, by which time this read request has already completed, so the cancellation operation doesn’t actually take effect. A key point in reproducing this is to hit a very precise time point, ensuring that the request is processed but the reply content hasn’t been parsed yet. This raises an important question: how should the test hit this time point to make the bug stably reproducible in problematic versions?
Stable Reproduction and Improvement
Subsequently, a developer raised a new Issue 2665 to discuss how to stably reproduce this issue. The approach is simple: start a proxy server to relay communication between the client and server. During the relay, both requests and responses are delayed by 0.1s. This is equivalent to simulating a network environment with a communication delay of 0.1s, and then the timing of cancelling asynchronous operations can be stably controlled.
The code for the relay proxy part is as follows:
1 | class DelayProxy: |
The complete reproduction code can be found at redis_cancel.py.
In response to this reproduction, chayim submitted PR 2666, corresponding to commit 5acbde3 which was placed in v4.5.4, using asyncio.shield to prohibit cancellation operations in all command operation scenarios. The key part of the change is as follows:
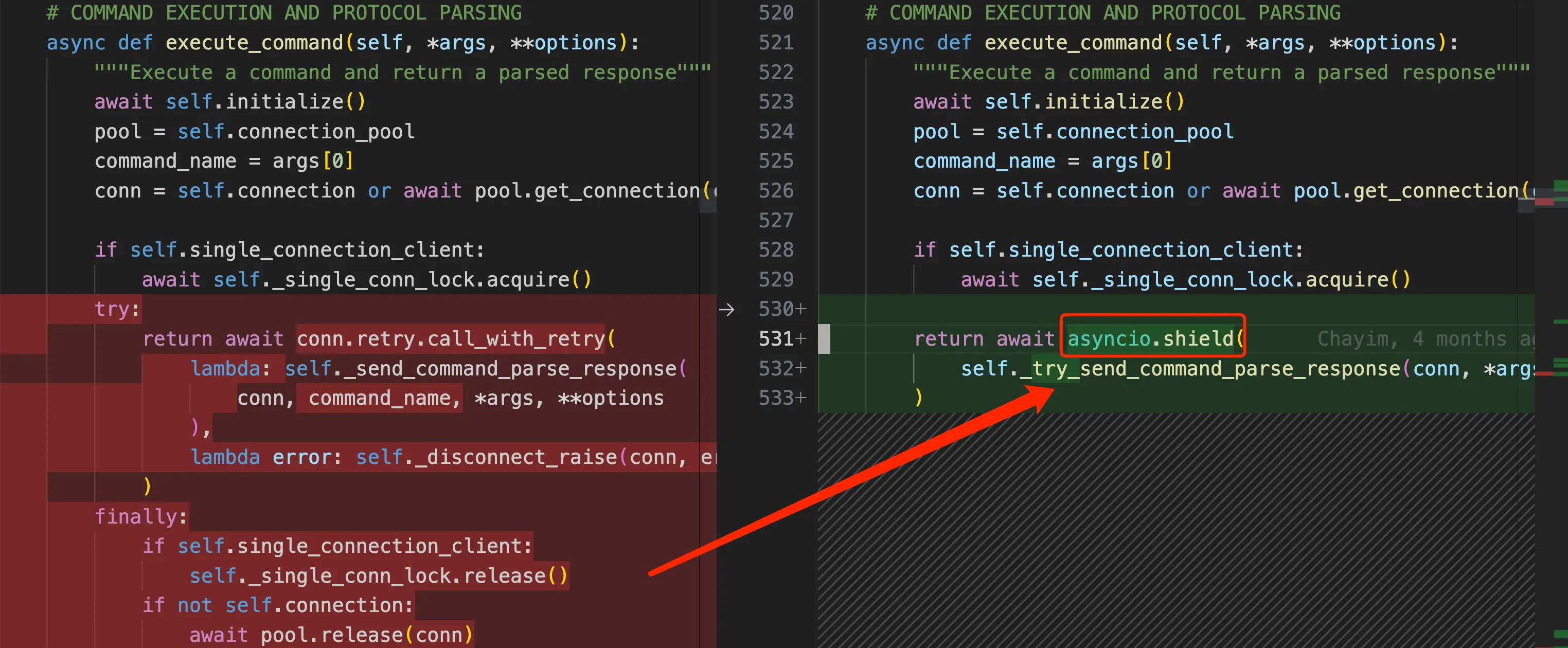
This is essentially a patch for the previous fix, which indeed fixes the bug of reading jumbled data, and the new test script can’t reproduce it. We can slightly modify the fix code below to better understand the principle of this fix. Let’s extract the asyncio.shield part from the code, print the result, and try to catch exceptions. The modified part is as follows:
1 | async def execute_command(self, *args, **options): |
Re-running the test script, we can see that for the request part where the asynchronous read is cancelled, the output is as follows:
[EXCEPTION] (‘GET’, ‘foo’)
try again, we did not cancel the task in time
We can see that after adding asyncio.shield, the asynchronous task didn’t throw an exception at the original data = await self._stream.readline() position (see the previous explanation of this), but instead normally completed the asynchronous get operation, got the result ‘foo’, and then finally threw the asyncio.CancelledError exception at await asyncio.shield. This PR also submitted test cases that can stably reproduce the issue, in tests/test_asyncio/test_cwe_404.py, with the basic idea still being to use a proxy to simulate delay time.
Background and Final Fix
The above fix seemed to solve the problem, but kristjanvalur was very dissatisfied with this fix solution and directly commented on PR 2666. As mentioned earlier, this approach of delaying exception throwing makes it impossible to truly cancel an asynchronous request, and in some scenarios, it can even lead to deadlock. kristjanvalur also provided an example code in this PR to prove that deadlock is entirely possible.
To finish the job, kristjanvalur then submitted a new PR 2695. This PR contains quite a lot, including rolling back the shield-related code in v4.5.3 and 4.5.4, then fixing Issue 2624 that caused ChatGPT to read incorrect data, and providing a unit test.
To provide a bit more background, kristjanvalur contributed a lot of code to asyncio/client.py in 2022, including PR 2104: Catch Exception and not BaseException in the Connection, which only closes the connection when encountering an Exception situation. It was this change that led to connections containing erroneous data being put back into the connection pool in certain scenarios. The specific discussion can be seen in Issue 2499: BaseException at I/O corrupts Connection, and this bug was also brought about by this change.
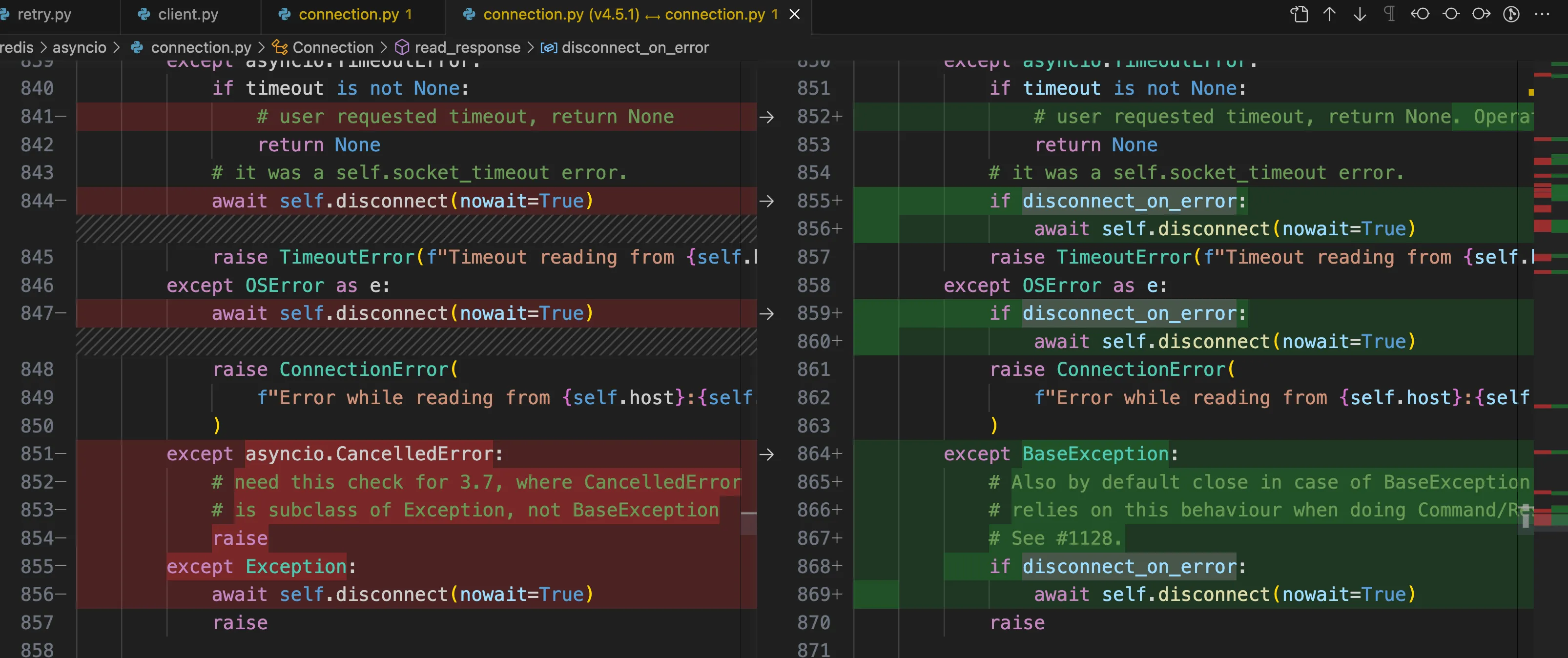
The core code of the specific fix solution is as follows, adding exception handling for BaseException in read_response, with the default being to directly disconnect the connection.
Final Verification Process
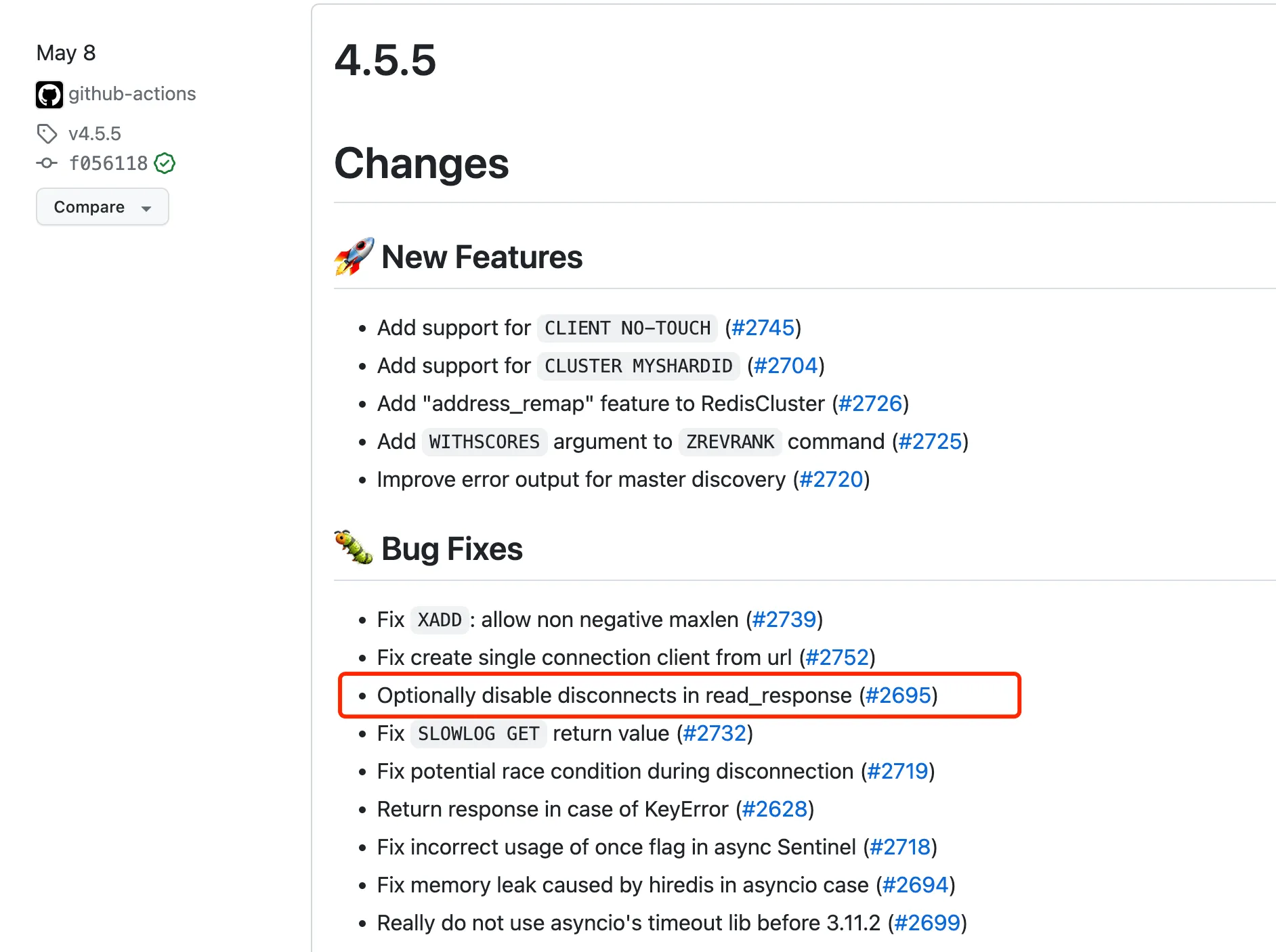
According to the version log on the Release page, we can see that version 4.5.5 merged PR 2695, as shown in the following image:
Switch to the v4.5.5 branch, and then try to verify again using the reproduction script above, obtaining the following result:
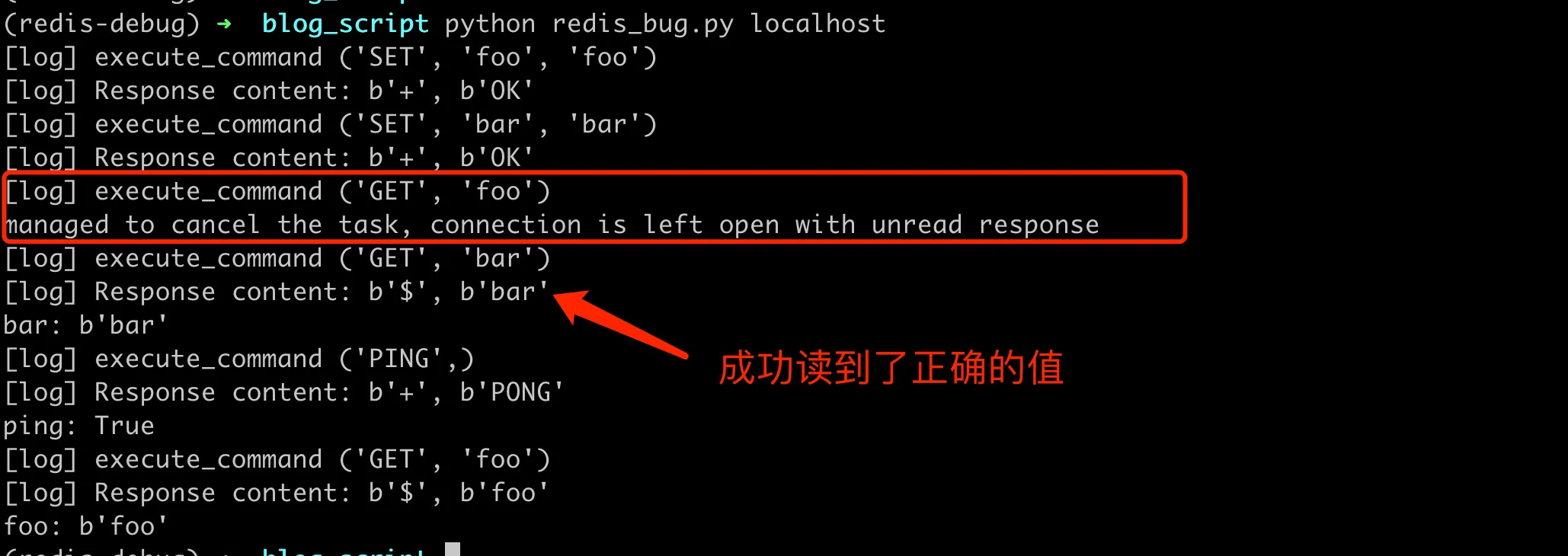
At this point, the bug has been thoroughly fixed. Let’s add some logs to verify our understanding process above, such as:
- When cancelling a task, the connection will be disconnected here;
- The next time a connection is obtained, a new connection will be used;
Here, add logs at the places where the connection is about to be disconnected and a new connection is created, using id(self._reader) to verify that a new asyncio.StreamReader object is indeed created. As follows:
1 | --- a/redis/asyncio/connection.py |
The output obtained is as follows, we can see that when cancelling a task, the connection is immediately disconnected, at which point the stream read with id=4388303056 is destroyed. The next redis operation creates a new connection and allocates a new stream read with id=4388321104.
[log] New Connection 4388303056 4385849616
[log] disconnecting 4388303056 4385849616
managed to cancel the task, connection is left open with unread response
[log] New Connection 4388321104 4385849616
bar: b’bar’
ping: True
foo: b’foo’
The overall fix idea is clear, which is to directly close the connection for abnormal request clients, which will clear the read and write streams. The next time there’s a new request, a new stream is used, avoiding the problem of misreading.
Brief Summary
OpenAI has made public a status page that displays the real-time operational status of various services. When ChatGPT is unavailable, users can immediately confirm this on the status page, rather than blindly guessing that the problem is on their end. This high-transparency approach is worth learning from. Firstly, it demonstrates respect and responsibility towards users, not easily blocking information. Secondly, it also helps the company proactively address issues rather than avoiding or concealing them.
The technical details published by OpenAI are quite comprehensive, which also reflects their highly transparent attitude. The report also specifically stated that the problem only existed within a very short window, and listed various remedial and preventive measures, including adding new verification logic, log recording, improving fault tolerance, etc. These details all show OpenAI’s high regard for user privacy and product quality. Then, through a detailed analysis of the technical reasons for this ChatGPT service interruption, we can gain the following insights:
First, this fully demonstrates the greatness of the open-source community’s power. From the initial problem report, to the submission of error fix proposals, to providing stable reproduction methods, and finally to the implementation of reasonable fix solutions, the entire process involved contributions from open-source community participants. It is because of such collaboration that a serious bug could be systematically analyzed and fixed in a short time.
Secondly, this also reflects that locating bugs that are difficult to reproduce stably requires skill. Using a proxy server to simulate network delay and create a time window for triggering errors provided important support for confirming and locating bugs. This approach has reference significance for handling various types of intermittent anomaly issues.
Additionally, this also demonstrates the difficulties of asynchronous programming. Understanding the execution of an asynchronous task flow requires a very strong grasp of code details. Printing logs and adding breakpoints are necessary means, and a thorough understanding of language and library behaviors is needed to analyze the root cause of the problem.
Finally, this case also highlights the value of excellent open-source projects. Not only do they need to provide reliable functional implementations, but they also need comprehensive documentation, comments, and test code. This is the cornerstone for the long-term development of open-source projects. Readers can master techniques for locating difficult problems and improve their programming skills through this kind of source code-level debugging analysis. It is also hoped that this article will provide inspiration and help for readers who need to deeply understand the implementation of open-source projects.
The final summary part was written by claude2, and it feels okay? Although it has a bit of a preachy feel.

