Troubleshooting HTTP Request Timeout Issues Caused by HTTP Headers
0 CommentIn actual business, we encountered a very strange problem: when service A accessed Go language service B through HTTP requests, a small portion of the requests would time out. Further analysis revealed that if a request timed out, its retry would definitely time out as well, indicating that for specific request content, the timeout was an inevitable problem. By checking the processing logs of service B, it was found that for timed-out requests, the processing time of the business logic was normal.
Initially, we used the process of elimination to analyze, gradually replacing suspected problematic modules, but we couldn’t locate the problem. Later, through packet capture, we analyzed the differences between normal packets and timeout packets, made reasonable guesses about the problematic parts, and verified them. We finally located that it was the Expect: 100-continue request HTTP header that caused the timeout here. The entire troubleshooting and fixing process encountered many pitfalls, which are recorded here for everyone’s reference.
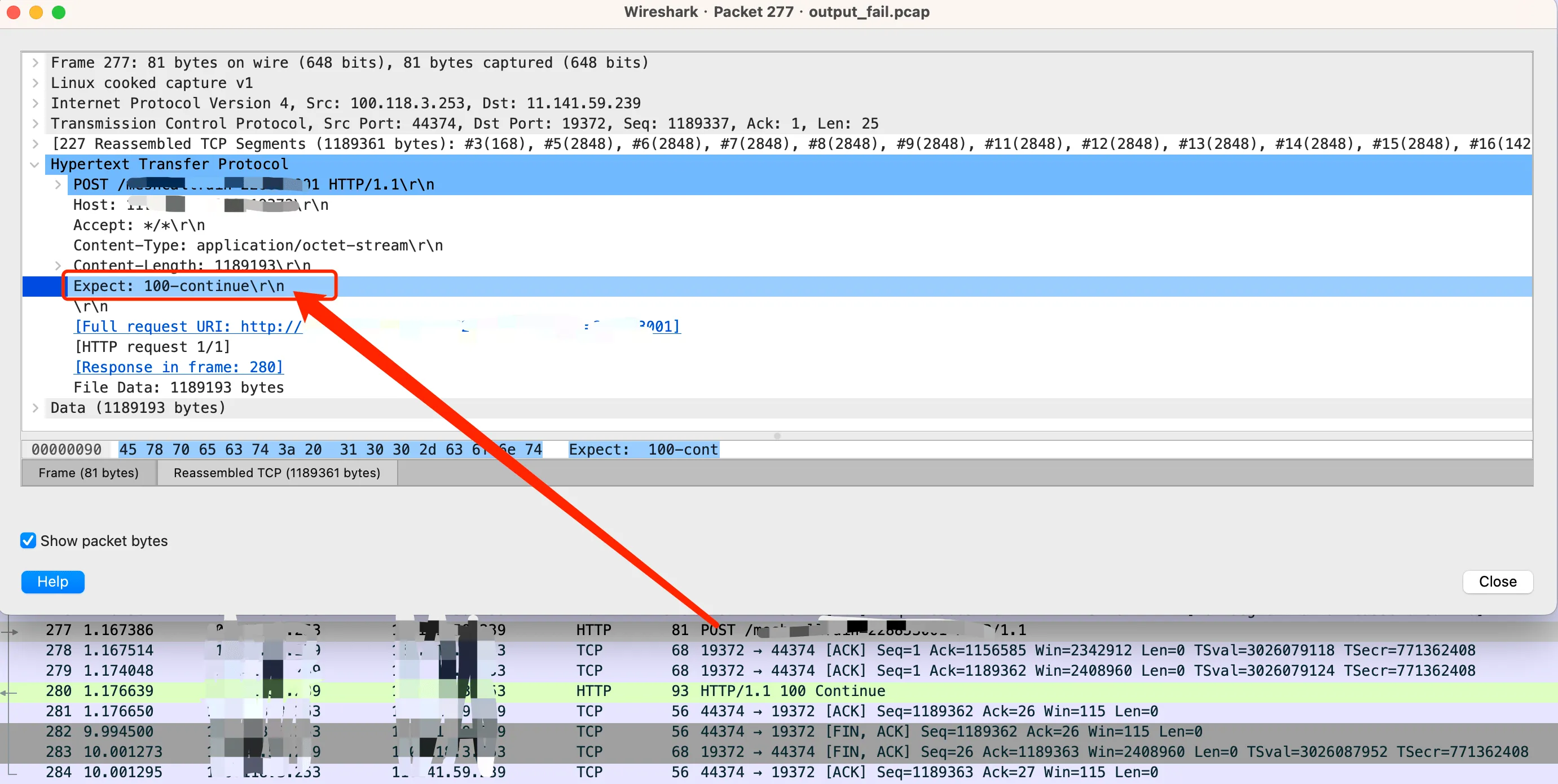 WireShark packet capture of HTTP expect: 100-continue
WireShark packet capture of HTTP expect: 100-continue
Process of Elimination
The business usually develops in C++, and the HTTP Client library used here is libcurl, which has been quite stable and hasn’t had any problems. So at first, we suspected it was a problem with Go service B. The Go service is actually quite simple, it’s an HTTP protocol proxy implemented using the gin framework, used to unpack business requests and then repackage them according to third-party protocols before forwarding to the third party. By adding logs and other methods, we ruled out problems with the business logic part of the code and initially suspected that we were using gin incorrectly. To quickly verify, I wrote a simple go server using gin and used the business client to request the mock server.
Replacing the Go Server
Writing a simple HTTP server with gin is quite simple. To simulate the business scenario as much as possible, we read the content from the request package and then reply with a relatively long random content. The complete code is in gist: mock_server.go, and the core part of the code is as follows:
1 | func MeshCall(meshPath string, c *gin.Context) { |
The above mock server code includes the core logic in business service B, such as using ReadAll to get request data and c.Writer to write back package content. After starting the service on port 8089, whether using the command-line curl tool directly or using the C++ client to call, we could get a normal HTTP reply. It seems that the usage of gin in the business go service is not a problem, and we can basically rule out issues with gin itself. After replacing the server and not finding any problems, should we replace the client next?
Replacing the Go Client
The C++ client logic is very simple: it sets an image to a field in protobuf, serializes it, and then uses libcurl to initiate an HTTP request, and then waits for the response. With the help of ChatGPT, we quickly wrote a client in go with the same request logic. The complete code is in gist: mock_client.go, omitting the proto part here. The core code is as follows:
1 | { |
Using this go client to request the previously mocked go server, we could normally parse the response. Then, when requesting the problematic business service B, we found that it no longer timed out and could normally read the response. This was a bit confusing. Let’s summarize the results of the previous experiments:
| Caller | Callee | Result |
|---|---|---|
| C++ Client A | Go Server B | Specific requests always timeout |
| C++ Client A | Go Mock Server | Everything normal |
| Go Client | Go Server B | Everything normal |
| Go Client | Go Mock Server | Everything normal |
Only when C++ Client A and Go Server B are together, specific requests would timeout. There were no good ideas left to investigate, so we could only try to capture packets and see what differences there were between TCP/HTTP packets in normal situations and timeout situations.
Tcpdump Packet Capture Analysis
Packet capture under Linux is simple, just use tcpdump directly, although it usually requires root privileges. The following command filters packets for specified IP and port and saves them in pcap format for later analysis with Wireshark.
1 | sudo tcpdump -i any -s 0 -w output.pcap 'host 11.**.**.** and port 1***' |
First, we captured packets between the go client (IP ending with 143) and Go Server B (IP ending with 239). The entire request-response was completely as expected. We could see that around 0.35s, the TCP request was fully sent, and then around 1.8s, it started receiving the response. The HTTP request took about 1.5s, and the response content was also completely correct.
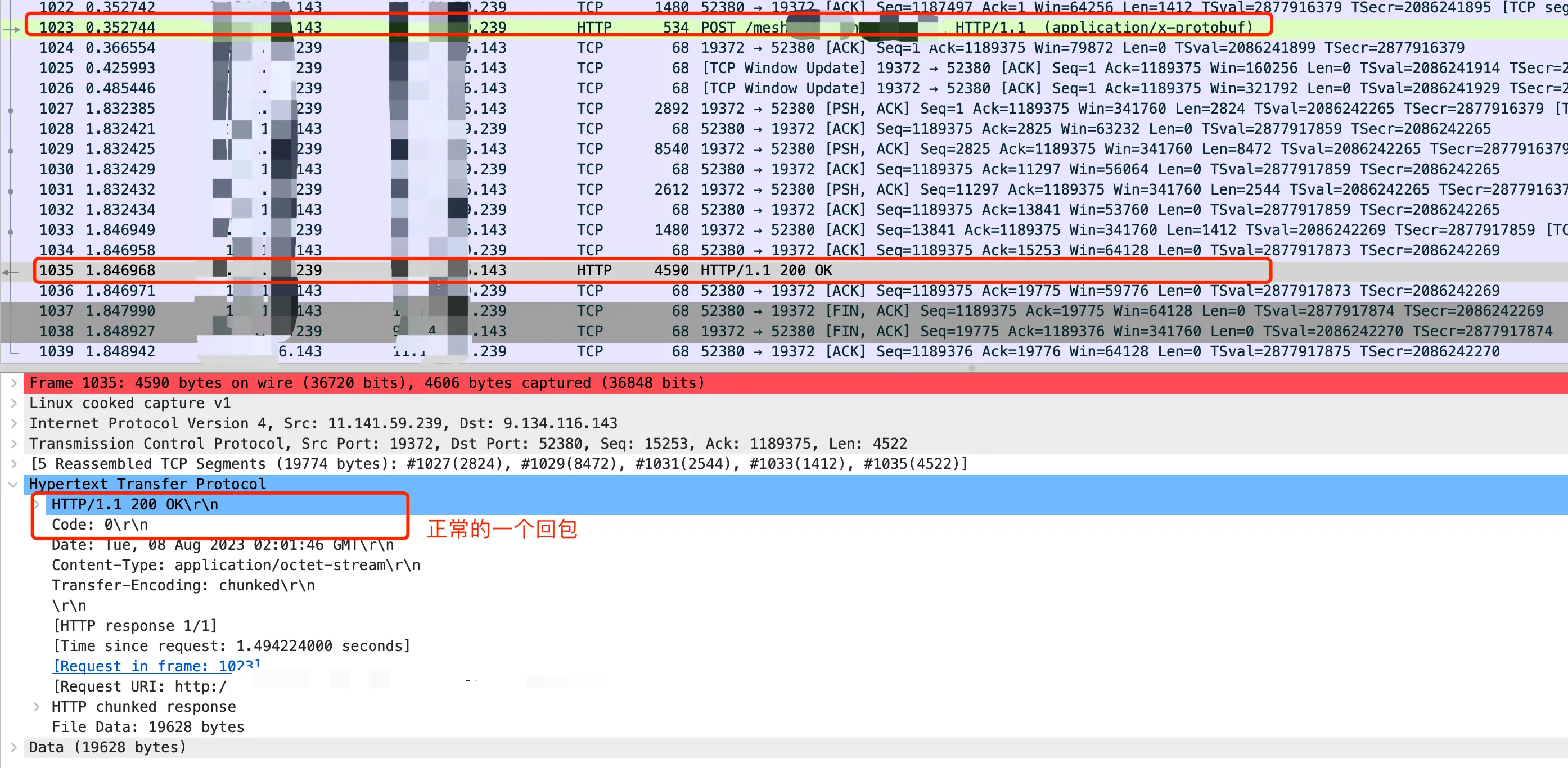 WireShark capturing normal response packets
WireShark capturing normal response packets
Next were the packets between the C++ client and Go Server B. Here, the C++ client’s timeout was set to 10 seconds. We could see that a 100 continue HTTP response was received in the middle, and then after 10s, the client closed the TCP connection.
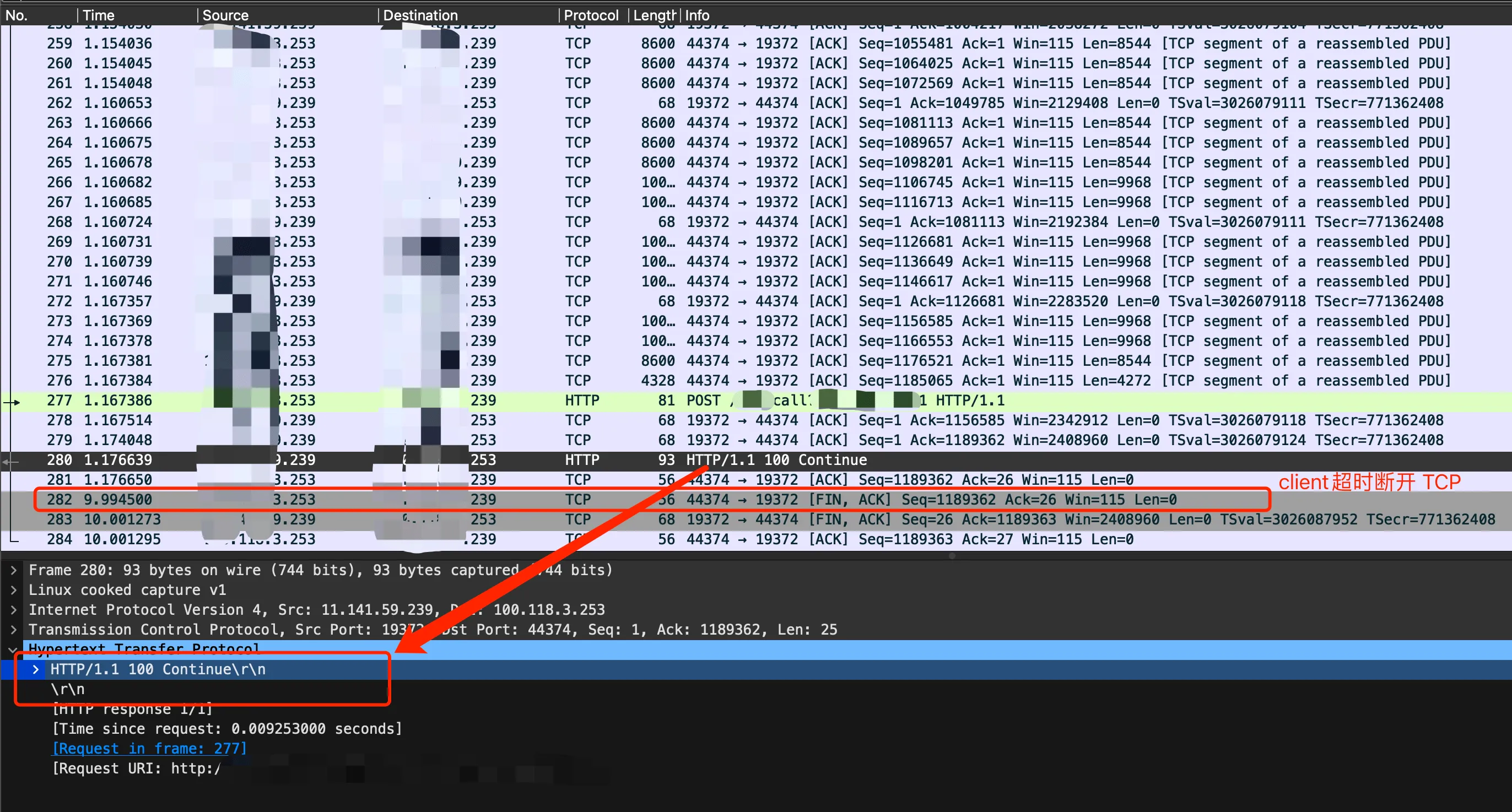 WireShark capturing timeout packets
WireShark capturing timeout packets
Where did this 100 continue come from? Why didn’t the Go client request to the service have it, while the C++ client request did?
Header Comparison
Different responses are usually due to different requests. Comparing the header parts of these two requests, we found that the Content-Type was different, but this generally doesn’t have much effect, at most affecting server parsing, and wouldn’t cause a timeout. In addition to this, the C++ request header also had an extra Expect: 100-continue, which matched the continue in the above response. It seems that there’s a high probability that this header is the problem.
1 | # Go client header part |
To quickly verify, we added this header in the go client and then initiated a request, which also timed out. It seems that it was indeed caused by this header, but what exactly does this header do? Why does it cause the request to timeout?
Expect: 100-continue
To answer the above questions, we need to have a further understanding of HTTP headers. In the HTTP protocol, when a client wants to send a request containing a large amount of data (usually a POST or PUT request), if the server cannot handle this request (for example, because the format of the requested data is incorrect or there is no permission), then the client would waste a lot of resources sending this data. To solve this problem, HTTP/1.1 introduced the Expect: 100-continue header, allowing the client to ask the server if it’s willing to receive the request before sending the request body. If the server cannot handle the request, the client can avoid sending a large amount of data, thus saving resources.
The specific implementation principle here is to send a complete HTTP request in two phases. The first phase only sends the header of the HTTP request, and the second phase only sends the body of the HTTP request after receiving server confirmation. From the HTTP perspective, it’s still a single HTTP request, just changing the way the request is sent.
This is generally implemented by the network library and the underlying TCP protocol. When using the “Expect: 100-continue” header, the network library (such as libcurl) will first only send the TCP data of the Expect part, and then wait for the server’s 100 Continue response. After receiving the TCP reply, the network library will continue to send the TCP data packets of the request body. If the server doesn’t return a 100 Continue response, the network library might choose to wait for a while, then send the request body, or close the connection.
libcurl Implementation
Specifically in the libcurl network library, there’s a detailed explanation in Expect 100-continue. When using Post or Put methods, if the request body exceeds a certain size (generally 1024 bytes), libcurl automatically adds the “Expect: 100-continue” request header. For the packet capture above, there was a relatively large image in the request body, so the C++ libcurl client request included this header.
Now there’s only one question left: why does having this header cause the request to timeout? The libcurl documentation mentions the following:
Unfortunately, lots of servers in the world do not properly support the Expect: header or do not handle it correctly, so curl will only wait 1000 milliseconds for that first response before it will continue anyway.
We can see that many services don’t support the Expect: 100-continue header well, but libcurl has also considered this situation and will continue to send the body after waiting for a 1s timeout. This can also be verified from the previous packet capture:
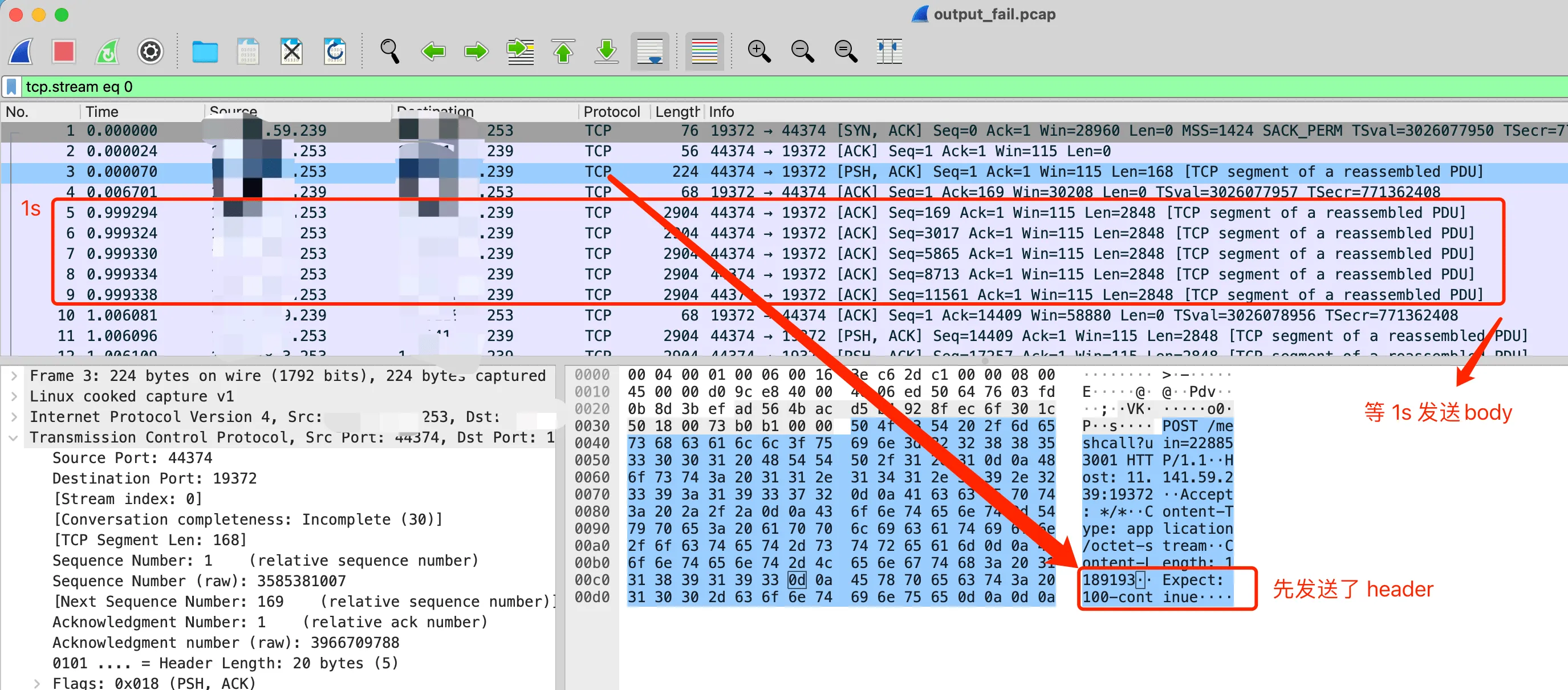 WireShark Expect: 100-continue waiting for 1s
WireShark Expect: 100-continue waiting for 1s
Here, after the libcurl client (IP ending with 253) sent the header, it didn’t receive a reply from the server, so it waited for about 1s before continuing to send the request body. Under normal circumstances, the server would process and then respond after receiving the complete response, at most wasting 1s of waiting time. However, our server behaved quite peculiarly here. After receiving the complete package, it first replied with 100-continue, and then had no reaction. This caused the client to keep waiting until it timed out after 10s. What caused this?
Timeout Cause and Fix
Let’s first review the experiments we’ve done. We already know that when C++ Client A requests Go Mock Server with the Expect:100-continue header, the HTTP server of the gin framework can respond normally. The entire request and response process is as follows:
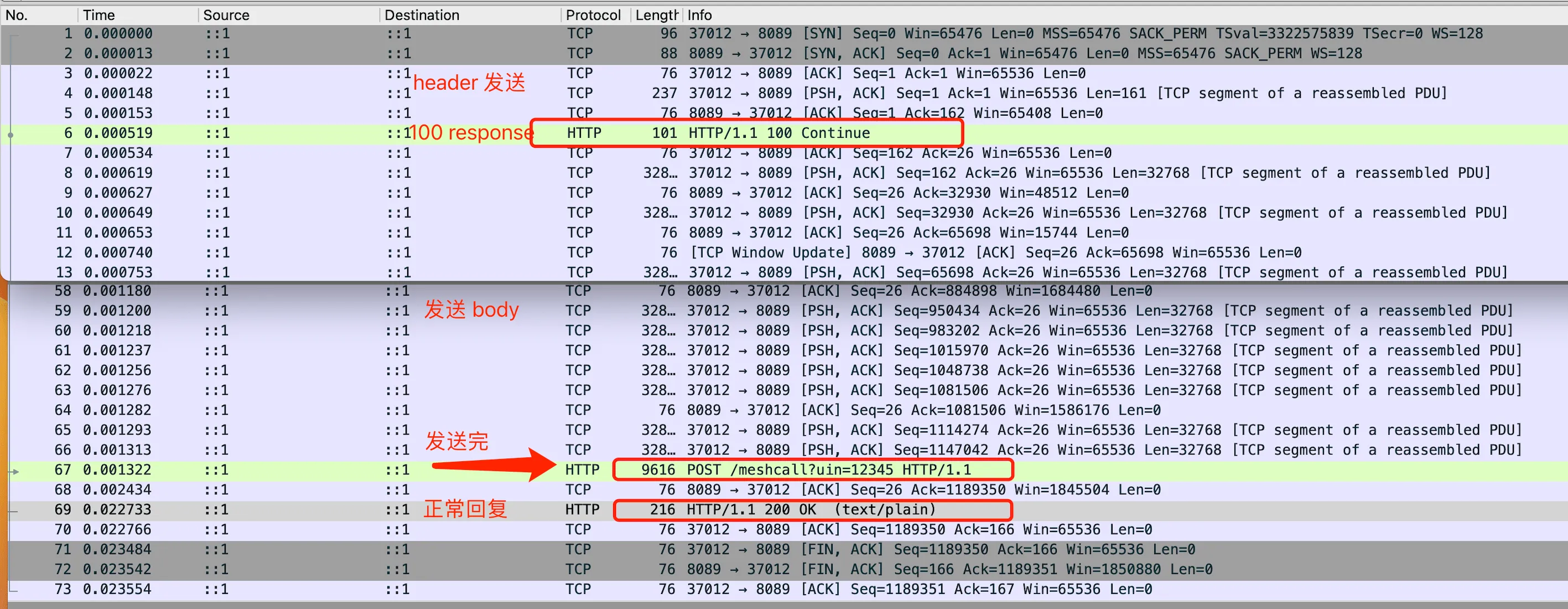 WireShark Expect: 100-continue normal processing flow
WireShark Expect: 100-continue normal processing flow
We can see that after receiving the header, the gin service directly replied with 100-continue, then the client continued to transmit the body. After the gin service received it completely, it also gave a normal 200 response. Why does requesting our business Go service B timeout when it’s the same gin service?
After careful consideration, we found that there are differences between these two. The gin service mocked in this experiment was opened on a port on the local machine, and requests were directly processed at this port. However, the traffic of the business Go service is taken over and forwarded by the mesh, and if the mesh layer doesn’t handle 100-continue well, there could indeed be problems (we can analyze the implementation of mesh later to see where the problem is).
Problem Fix
The code at the Mesh layer is maintained by dedicated personnel, and it’s difficult to determine when it can be fixed after submitting an Issue, while the business urgently needs to solve this problem. So we had no choice but to change the libcurl calling method to remove this request header when making requests. I asked ChatGPT how to remove this header when sending network requests using libcurl, and got the following method.
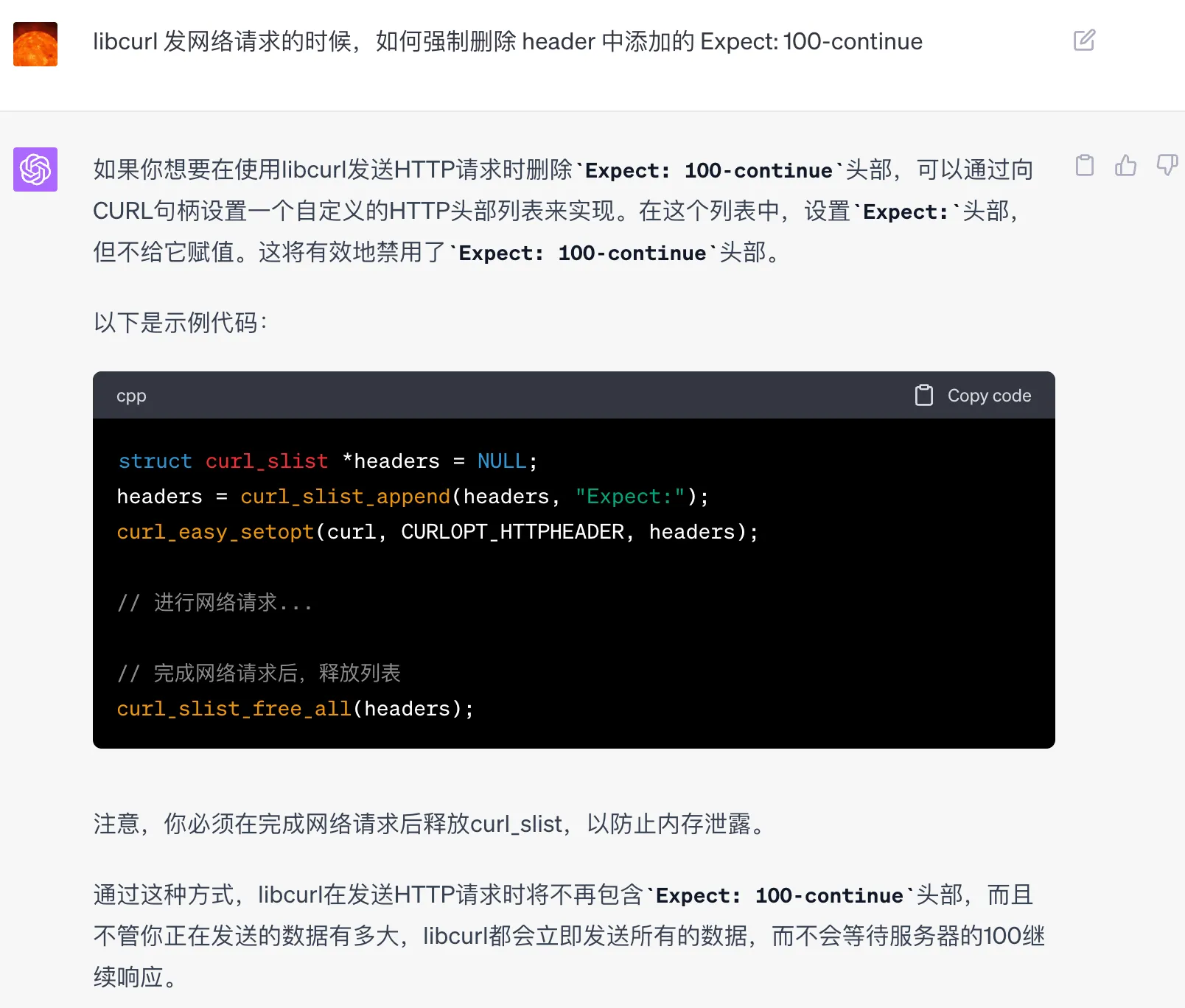 C++ libcurl request removing Expect: 100-continue header
C++ libcurl request removing Expect: 100-continue header
So I happily went to change the code for the business request part, setting the header before initiating the network request. The changes are as follows:
1 | { |
After making the changes, I verified that the HTTP request to service B could indeed receive a normal response. However, when deploying, we found parameter error alerts for network requests to other third parties. After rolling back, the failures disappeared, so it seems to be related to the changes in this HTTP request. Looking carefully at the CURLOPT_HTTPHEADER part of libcurl settings here, we found that the business also sets it, and this modification would completely overwrite the previously set header.
ChatGPT told me that I could clear this Expect header, and even reminded me to be careful about memory leaks, but ChatGPT couldn’t consider everything comprehensively and didn’t consider that this method would directly overwrite my original header. ChatGPT can indeed provide us with very useful suggestions and solutions, but its answers are based on the context given by the user. It doesn’t know the details of the entire system and can’t predict all business scenarios. Therefore, when accepting and applying its suggestions, we need to be very cautious and ensure that its suggestions are combined with actual business scenarios.

