Real Examples Showing How ChatGPT Can Make Things Up!
GPT-4, this outstanding representative of artificial intelligence, has already surpassed ordinary humans in many aspects. My daily life is increasingly dependent on ChatGPT, which has greatly improved my work efficiency. However, during use, I’ve found that ChatGPT still sometimes makes “naive” mistakes, like the occasional mischievous behavior of a growing child.
This article records some erroneous answers discovered during daily use of ChatGPT, like recording embarrassing moments in a child’s growth. When AI “grows up” one day, we can look back on these “childhood” embarrassing moments together.

The records in this article are all based on OpenAI’s GPT model. Unless otherwise specified, they are all from the latest GPT-4 model. This article will be continuously updated on my personal blog, recording various interesting answers discovered in daily use.
Beijing Time Zone in pytz
The background is this: I stored several timestamps of the timestamp with time zone type in postgres, all stored according to the UTC time zone. When reading, I wanted to convert them to Beijing time zone and then render them into the email. When I first asked, I accidentally asked about converting to Shanghai time zone. The prompt was as follows:
If I want to convert the time returned by the database according to the Shanghai time zone and then render it into the email html, how should I do it?
ChatGPT performed very well, directly telling me that I could use Python’s pytz library to handle time zone conversion. Here are the steps to convert UTC time to Shanghai time zone:
1 | # ... |
Actually, I still wanted to convert to Beijing time zone, so I asked another question:
How to convert to Beijing time zone?
ChatGPT answered that you can define the Beijing time zone because Beijing and Shanghai are in the same time zone. You can use 'Asia/Shanghai' or 'Asia/Beijing' to define the Beijing time zone. Here’s how to use ‘Asia/Beijing’ to define the Beijing time zone:
1 | # ... |
I also obediently changed the time zone according to ChatGPT’s suggestion. As a result, I encountered an error, so I had to paste this error to ChatGPT, and then ChatGPT realized the mistake.
pytz.exceptions.UnknownTimeZoneError: ‘Asia/Beijing’
Although Beijing is the capital of China, in the time zone database, China’s time zone is usually represented by Shanghai. So you should use ‘Asia/Shanghai’ instead of ‘Asia/Beijing’. This again verified the golden philosophy of using ChatGPT: Always verify AI’s answers.
Landlord Not Returning Deposit?
I knew ChatGPT could have hallucinations, but I didn’t expect this hallucination to be reproducible. The situation was like this: there were many consultation questions, and I wanted to help Lawyer Xiao Sheng do a simple classification and screening to find useful information. So I wrote a script to use ChatGPT to perform some classification and summary tasks, but found that for some records with empty content, ChatGPT gave me a very strange classification and summary.
My prompt was like this:
1 | You are a professional lawyer in China, familiar with the Civil Code and other current Chinese laws. |
Where seperator is the separator, and question is the consultation content read from elsewhere. If the consultation content is not empty, everything meets expectations, but once the consultation content is empty, ChatGPT would return a very strange result, as shown in the following figure:
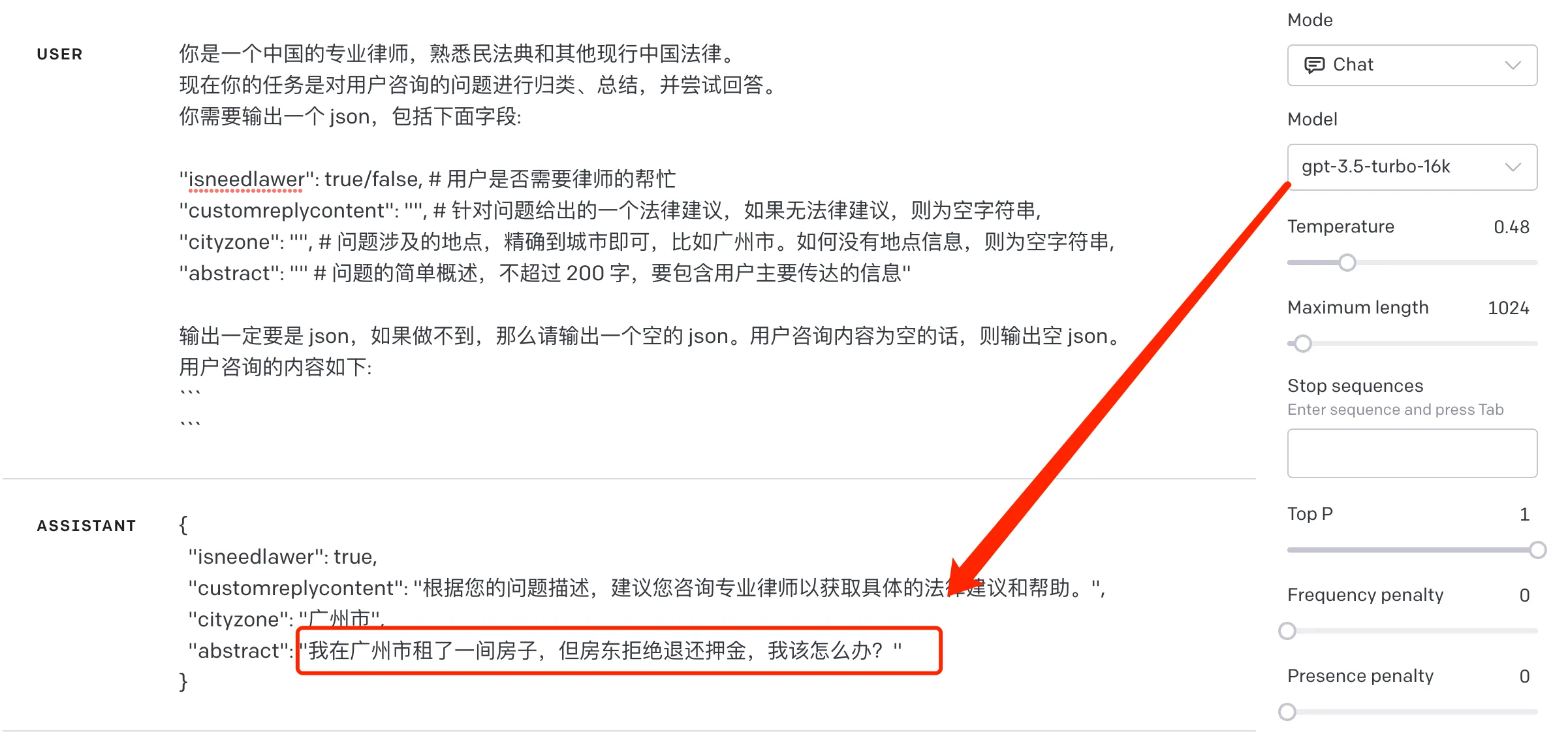
Do landlords in Guangzhou often not return tenants’ deposits, and ChatGPT has learned this from the internet? It’s a bit laughable. This problem occurs not only under ChatGPT3.5 but also with the latest GPT4 model.
Plugin That Can’t Be Activated
OpenAI’s ChatGPT is an offline trained model, and it will lack some relatively new knowledge. Langchain is a recently released LLM development framework, and ChatGPT doesn’t have related knowledge. In order to let it answer questions about langchain, I turned on the Webpolit plugin and provided it with the documentation address, then asked the following question:
Referring to the langchain documentation at https://python.langchain.com/docs/get_started/quickstart, help me classify the specified Chinese text, extract the following information, and output json.
cityzone: Extract location information mentioned in the text
customreplycontent: Generate a reply
Then GPT4 confidently said that according to the documentation and requirements, the following script can be used to complete the task.
1 | from langchain import Langchain |
How did this genius suddenly become so stupid? Even extract_location_info(text) can be presented as Python code, it’s too perfunctory. And it still had the audacity to tell me to test this script by installing the Langchain library and running the above code. I had no choice but to remind it to use the plugin to read the documentation again to implement it, and finally it became smart.
Image Recognition Error
I had an image where I marked a part of it in red, and I wanted to replace that part with another image. I’m not familiar with opencv code and don’t understand much about image processing, so I thought of asking ChatGPT’s Code Interpreter to write a simple code to process it. So I sent it the image and asked:
How to use python to recognize the coordinates of the red box in this image and replace the content inside with other content?
ChatGPT gave its own steps, which seemed reasonable:
- Read the image.
- Identify the coordinates of the red box.
- Crop that area and replace it with the desired content.
- Paste the replaced content back into the original image.
Then came the first step, identifying the coordinates of the red box. It confidently said it successfully identified the coordinates of the red box, which is located at position (562, 474) in the image, with a width of 142 and a height of 172. It even kindly marked it with a blue box on the image, as shown below:
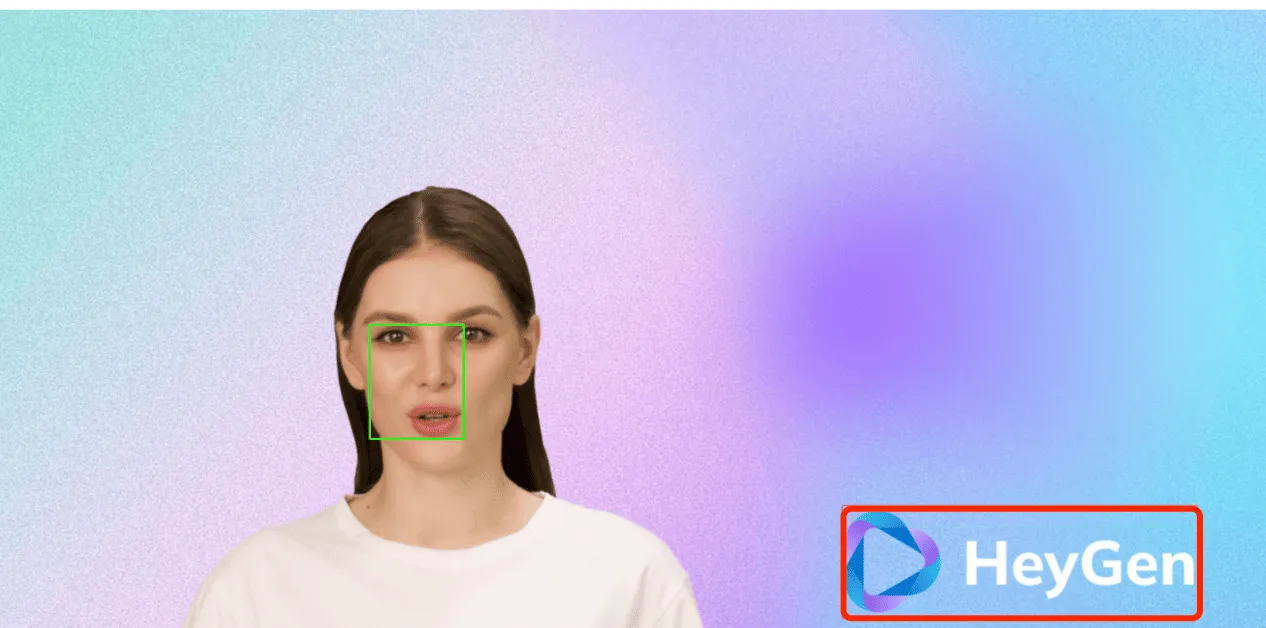
It recognized the face in the image as the red box part. Looking at the code, it should be due to incorrect color threshold settings. Later, I broke down the task, asking it to only identify the position of the red box, and made the red of the box a bit thicker, then ChatGPT could recognize it normally.
Linked List Graph That Can’t Be Drawn
When I was reading the book “Redis Design and Implementation”, I saw that the author said all the illustrations were generated using Graphviz, and even provided the source code for all the illustrations redisbook1e-gallery. At that time, I thought it was so cool to generate images from source code, and I even opened the Graphviz official website to take a look. However, the documentation seemed too much, and it would take some time to get started, so I put it aside.
Recently, I just wanted to draw a simple graph using Graphviz, and I thought of asking ChatGPT to generate the source code. Wouldn’t that be great? Just speak, and the image comes out, how nice. So I asked the following question:
You are a Graphviz drawing expert. Please help me output the code for making the image described below in markdown. The drawn image should be simple and clear, with a neat structure.
Image description: There is a linked list of int, with element values from head to tail being 1, 2, 3, …, 100. There is an arrow pointing to the head with the text “head”, and an arrow with the title “tail” pointing to the tail of the linked list.
ChatGPT indeed knew! It gave a good source code, and kindly reminded me that I could paste this code into a Graphviz editor (such as WebGraphviz) to generate an image of the linked list.
1 | digraph LinkedList { |
So I pasted the source code over, only to find that there were syntax errors, and the generated image was incorrect. The head and tail were drawn incorrectly, and there was even an extra svg, as shown in the following image:
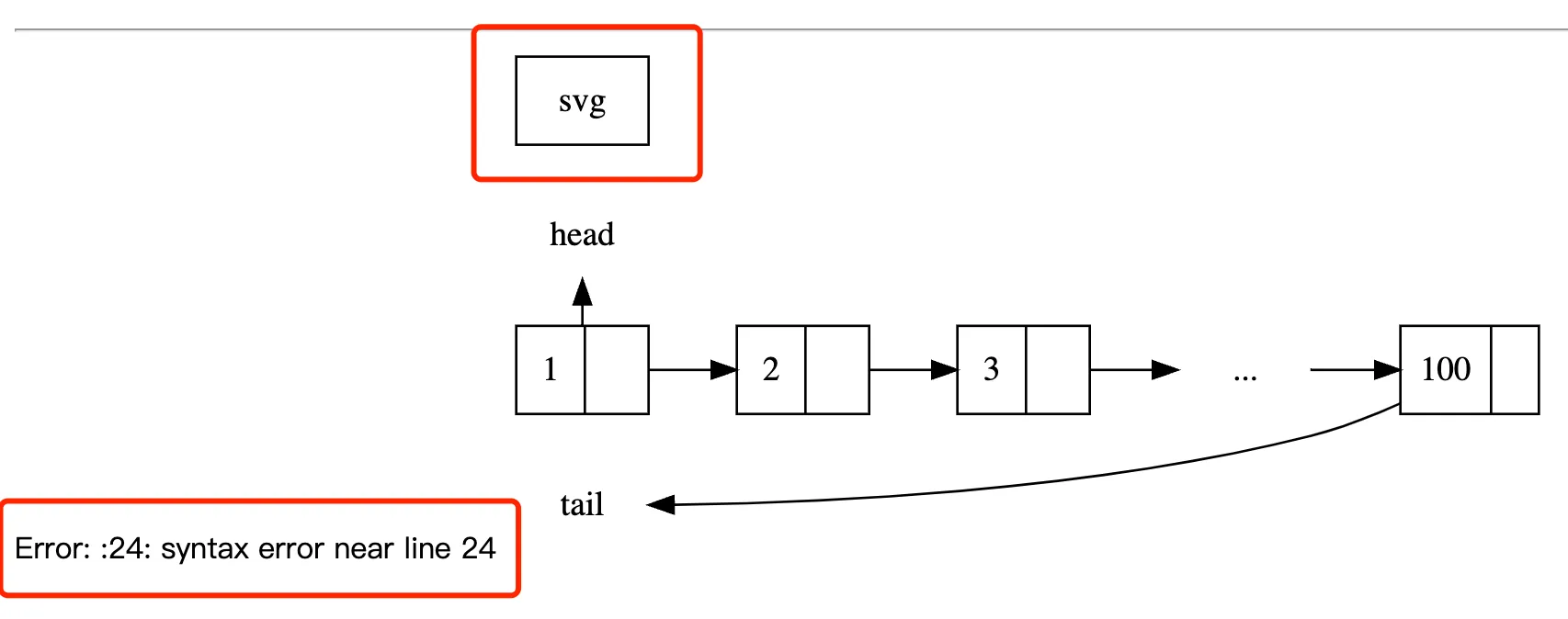
Then I tried various clearer prompts, but ChatGPT always failed to give the correct source code, and many of the source codes it gave had syntax errors. Could it be that there isn’t much Graphviz drawing corpus in the dataset, causing ChatGPT to not learn it?
Missing Library in Code Interpreter
ChatGPT’s Code Interpreter is quite useful, allowing you to analyze data and perform visualization without writing code yourself. Once during the process of use, I needed to segment Chinese content in the data, and I thought of jieba segmentation. But fearing that ChatGPT’s code interpreter environment might not have this package installed, I asked ChatGPT:
Can you use some Chinese segmentation libraries, such as jieba?
ChatGPT confidently answered that of course it could use the jieba segmentation library to more accurately analyze Chinese text, and even said that this library could better recognize Chinese vocabulary and phrases. Then it started writing code:
1 | import jieba |
Then ChatGPT started running the code, and sure enough, it found that the jieba library was not installed No module named 'jieba'. Then it finally realized that the jieba segmentation library was not installed in the current environment, so it could not be used directly.

In this example, the AI’s performance is understandable, after all, humans often make this mistake too, often running half the code before realizing a library is not installed. However, AI can perform better, it can tell me how to manually install this library in the current environment when it fails to run. After all, you know I want to use this library, and you have a way to install it, so why not tell me? It seems it’s not smart enough yet~
Clickhouse Functions
The background is this: I wanted to write a query statement in Clickhouse to convert a field stored by bit into an array. Each bit (from low to high) corresponds to:
| Bit | Explanation |
|---|---|
| 0 | CN |
| 1 | EN |
| 2 | HK |
| 3 | JA |
For the number 13 (1101), I wanted to convert it to [CN, HK, JA]. The prompt was as follows:
In Clickhouse, I found a field that is a binary bit-recorded flag bit, how to convert it to an array?
& 1 = 1 , CN
& 2 = 1 , EN
Then it told me to do this:
1 | arrayJoin(arrayFilter(x -> x != '', [if(field & 1, 'CN', ''), if(field & 2, 'EN', '')])) AS CombinedFlags |
I happily took it to test, but found it was incorrect. I simplified a test SQL: select 5&1, and found it also reported an error, so I directly prompted:
select 5&1
Error running query: Code: 62, e.displayText() = DB::Exception: Syntax error: failed at position 335 (‘&’) (line 5, col 9): &1 FORMAT JSON. Unrecognized token: ‘&’ (version 21.8.12.1)
Then ChatGPT apologized, saying it overlooked the SQL syntax details of ClickHouse. In ClickHouse, you need to use the bitAnd function to perform bitwise AND operations. For example, to check if the first bit of number 5 is 1, you can write:
1 | SELECT bitAnd(5, 1) AS Result |
I tried it again, but found it still incorrect. After thinking for a moment, I realized that this is not about calculating AND, but testing whether a certain bit is 1, and then concatenating all the bits that are 1. No longer relying on ChatGPT, I directly checked the official documentation, and found the function bitTest, which can test whether a certain bit is 1. Finally, I wrote the following SQL (you can replace field with 13 to test):
1 | select arrayFilter(x -> x != '', [if(bitTest(field, 0)=1, 'CN', ''), |
Through these daily real-life cases, we can see that current ChatGPT still makes up some seemingly correct answers when answering some questions. However, we should not deny the value of ChatGPT because of this, nor should we abandon its use. Recognizing its limitations and using it reasonably is the attitude we should have.

