Using Python Template Library docxtpl to Batch Create Word Documents
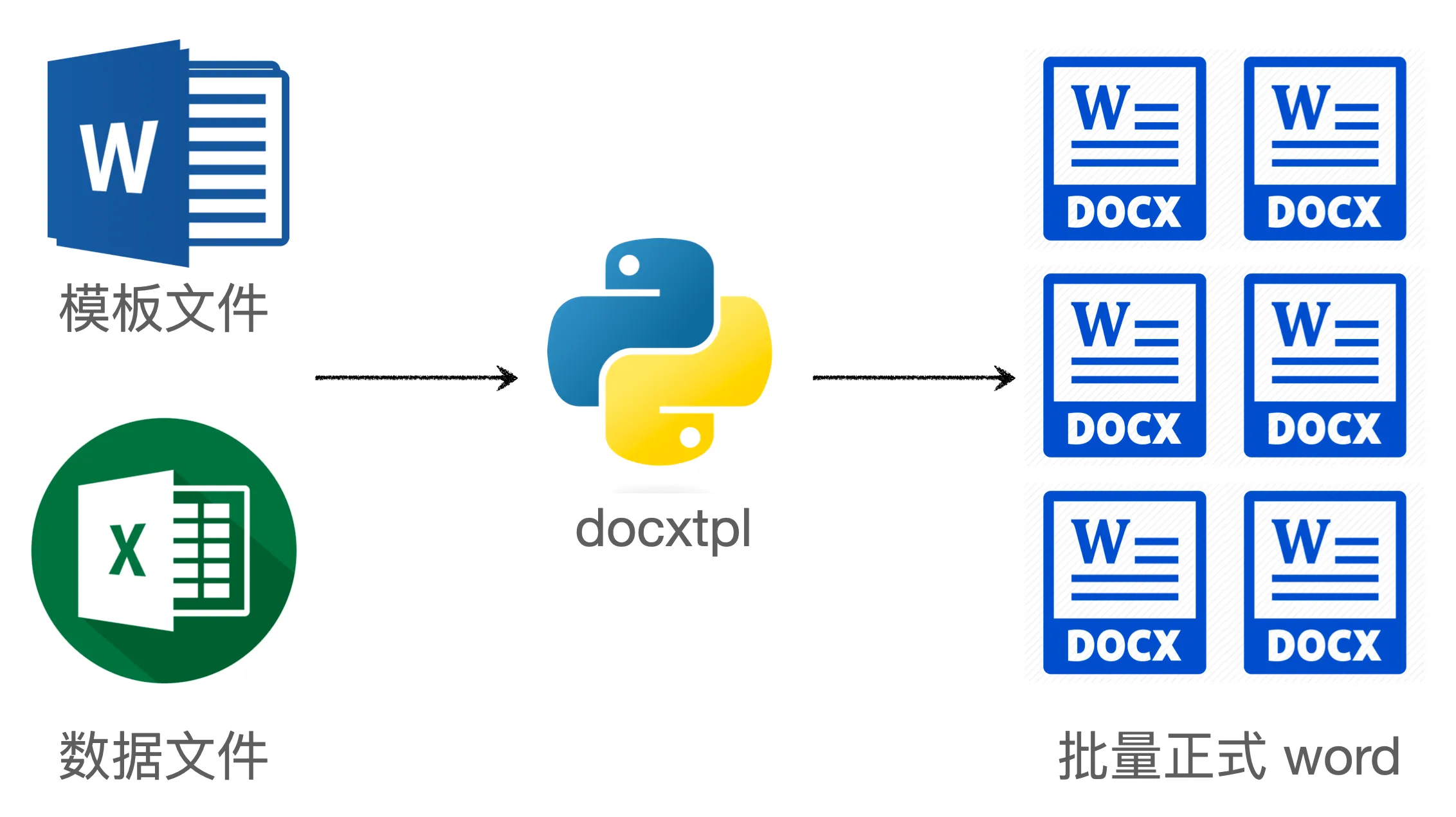
In work, repetitive labor is often tedious. Leveraging the power of Python to optimize workflows can greatly improve efficiency and achieve twice the result with half the effort. This article will detail how to use the Python template library docxtpl to automatically generate multiple Word documents in a very short time, saving a lot of manual operation time, thus freeing up your hands and easily completing tasks.
Update: It’s a bit difficult for beginners to do it with Python. So I wrote an online tool that supports batch generation of Word documents from templates and data. Online Batch Generate Word Tool Address
The story begins like this: Lawyer Xiao Sheng has a batch of cases where the case details for each client are similar, with only differences in the client’s name, ID number, address, and other information. Lawyer Xiao Sheng needs to prepare Word files for each client, where everything in the Word document is the same except for the client’s personal information.
Lawyer Xiao Sheng has an Excel file that records the client’s information. According to the previous method, she would need to open Excel, then copy and paste information one by one into each client’s Word file, and finally save it. This workload is huge; with dozens of clients, and multiple pieces of data for each client, she would need to copy and paste hundreds of times. Besides the large amount of physical labor, it’s also easy to make mistakes. A lawyer’s work is to avoid errors, so this method is not feasible.
Since it’s repetitive physical labor, programs can certainly come in handy, as machines are precise and fast at repetition. So, Lawyer Xiao Sheng found me, hoping I could help her write a program to automatically create appropriate Word files based on the data in the Excel file.
Simple Replacement
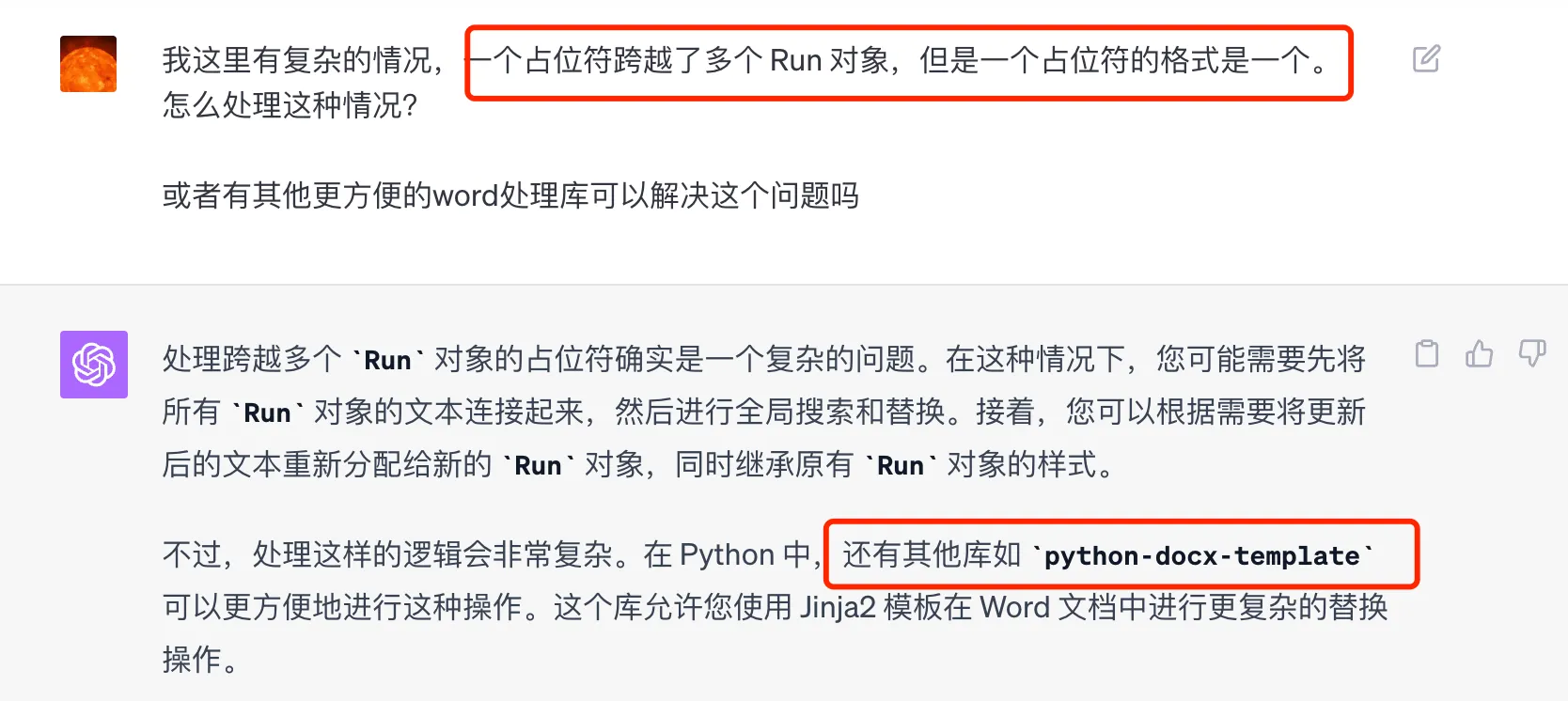
Xiao Sheng said her requirement was very simple: read data from Excel, replace it in Word, and then gave me 5 minutes to get it done (showing great potential as a product manager). So I habitually consulted ChatGPT teacher first, asking it to write the code. After communicating with it for half a day and continuously refining the requirements, I finally persuaded the AI to give up using the python-docx library.
Because while replacing the text, I needed to preserve the original file’s style. In Word’s .docx files, styles and text are stored separately. The text in a paragraph may consist of multiple Run objects, each of which may have different styles. Replacing text across multiple Run objects while preserving the format would be very complex. Moreover, this library’s API is also quite complex, requiring understanding of Run objects, which is not user-friendly. Fortunately, I was smart enough to remind ChatGPT to consider other libraries for text replacement, so ChatGPT teacher recommended the docxtpl library.
docxtpl is a template library based on python-docx. Its author found it too troublesome to modify Word using the python-docx library, so he developed the docxtpl library, drawing inspiration from the Jinja2 template library. It’s simple to use, mainly in three steps:
- Wrap the text to be replaced with
{{ }}in the Word document; - Use the
DocxTemplateclass ofdocxtplto load the Word template and provide the content before and after replacement; - Use the
rendermethod to render the template.
This is much simpler. After getting Lawyer Xiao Sheng’s sample Word file, I simply modified it into a template file that conforms to Jinja2 syntax. If a certain field needs to be obtained from column B of the table, just write it as {{ B }}. For example, the following content:
The case of
{{ A }}vs{{ B }}lease contract dispute accepted by your court
These template variables can be styled in Word, such as font, font size, color, etc. Then use pandas to read columns A and B from Excel, and use docxtpl to quickly perform text replacement while preserving the format. The core code is very simple, as follows:
1 | def generate_word_files(excel_filepath, word_template_filepath, output_dir): |
Special Handling of Dates
After writing the code and executing the replacement, I found that some fields were not correctly replaced. In Excel, there was a column that looked like a date ‘2023/04/12’, but after replacement in Word, it became 1970.1.1. What’s going on?
After printing the value read by pandas, I found it was an integer, not a string. This is because dates in Excel are based on January 1, 1900, so 2023/04/12 in Excel has a value of 44397. This value represents the number of days Excel uses to represent dates, not a string. Knowing this, we just need to add this number of days to the start date. Here’s the code ChatGPT provided:
1 | def excel_date_to_datetime(excel_date): |
Here, the start date has become 1899.12.30. This is because there’s an error in Excel’s date system: it treats 1900 as a leap year, which it actually isn’t. Therefore, February 1900 has 29 days in Excel’s date system. To solve this problem, a common practice is to start counting from December 30, 1899, which allows skipping this “extra” day (i.e., February 29, 1900) when calculating dates. ChatGPT teacher is indeed smart, automatically helping me avoid this pitfall.
For more information about Excel’s date format, you can refer to these two articles:
Complex Replacement
Simple replacement is of course not challenging, but we may encounter some more complex replacement scenarios in our work.
Calculated Data
As it happens, Lawyer Xiao Sheng’s file contains some calculation formulas that require filling in some calculated values, such as:
The defendant’s loss is:
{{ Y }}× 120% = ??? yuan
Here, column Y in Excel is the loss fee, but it needs to be multiplied by a coefficient and filled into Word. Excel doesn’t have this calculated data, so we can calculate the result in the code and then wrap it with {{ Y_calculated }} to replace it in Word. The calculation part of the code is also very simple, as follows:
1 | elif col_label == 'Y': |
Actually, it would be even better if calculations could be supported in the Jinja2 template, such as writing the template as {{ Y | calculate }}, which would allow direct calculation in the template. However, docxtpl doesn’t support such syntax, so we can only calculate the result in the code and then replace it in Word.
Conditional Statements
Xiao Sheng’s document also needs to dynamically display some content based on Excel data, such as showing relevant text only when the fee field is not empty. This can be achieved through the conditional statement jinja2 syntax supported by docxtpl.
1 | 1. {% if S != 0 %}Order the defendant to pay the plaintiff rent of {{ S }} yuan; |
Because there are lists in Word, to maintain the list format and numbering, the {% endif %} needs to be placed in the appropriate position.
In addition to the simple replacements and conditional statements mentioned above, docxtpl also supports loop statements, tables, setting rich text, etc. You can refer to its documentation.
Conclusion
With just over 100 lines of code, we can implement a program for batch creation of Word documents, which demonstrates the power of Python. Compared to manual copy and paste, the program is incredibly fast, capable of processing hundreds or thousands of documents in 1 minute, and is less prone to errors. For those without a programming background, with the help of ChatGPT teacher, such tasks can also be accomplished. This is a major use of current AI, allowing everyone to quickly get started with knowledge outside their professional field, especially in the programming domain.

