Can ChatGPT's Multimodal Image Recognition Crack CAPTCHAs?
CAPTCHAs have become an indispensable part of our daily online lives, providing a basic security barrier for websites and applications. From the initial simple numerical CAPTCHAs to various complex ones today, their complexity has been gradually increasing to resist attacks from automated tools and bots.
The following image shows some common CAPTCHAs:
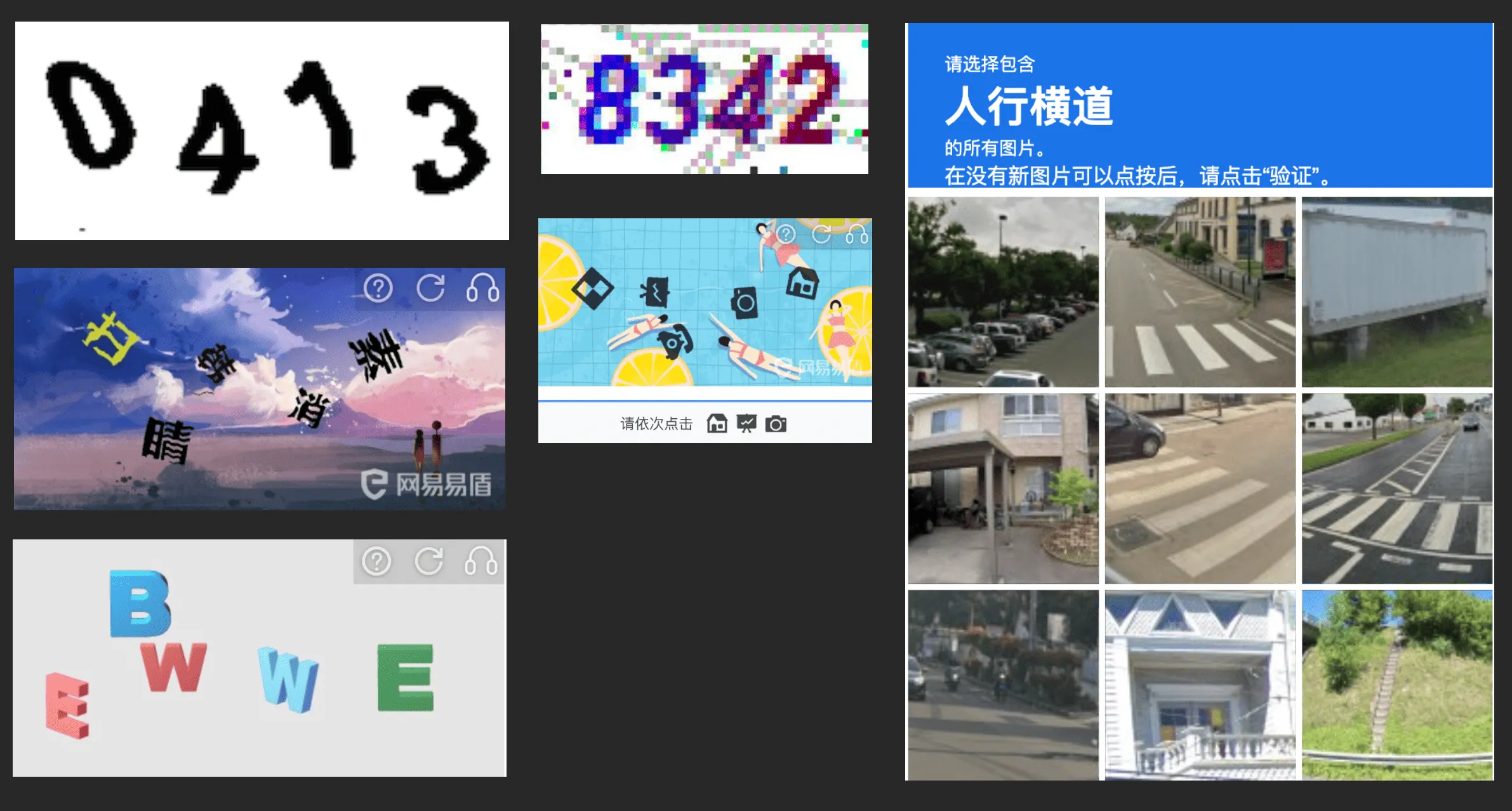
The sole purpose of these CAPTCHAs is to distinguish between humans and machines. However, with the rise of large models like ChatGPT, especially the advent of GPT4-Vision’s multimodal capabilities, can CAPTCHAs still intercept machines?
In this article, we’ll attempt to use NetEase’s Shield and Google’s CAPTCHAs as examples, letting ChatGPT try to crack them, to see if ChatGPT with visual capabilities can actually break through CAPTCHAs.
Digit and Letter Verification
Let’s start with the simplest numerical CAPTCHAs. These CAPTCHAs have long been solved by neural networks, and can be easily recognized even without large models. However, let’s still give it a try to see how ChatGPT performs.
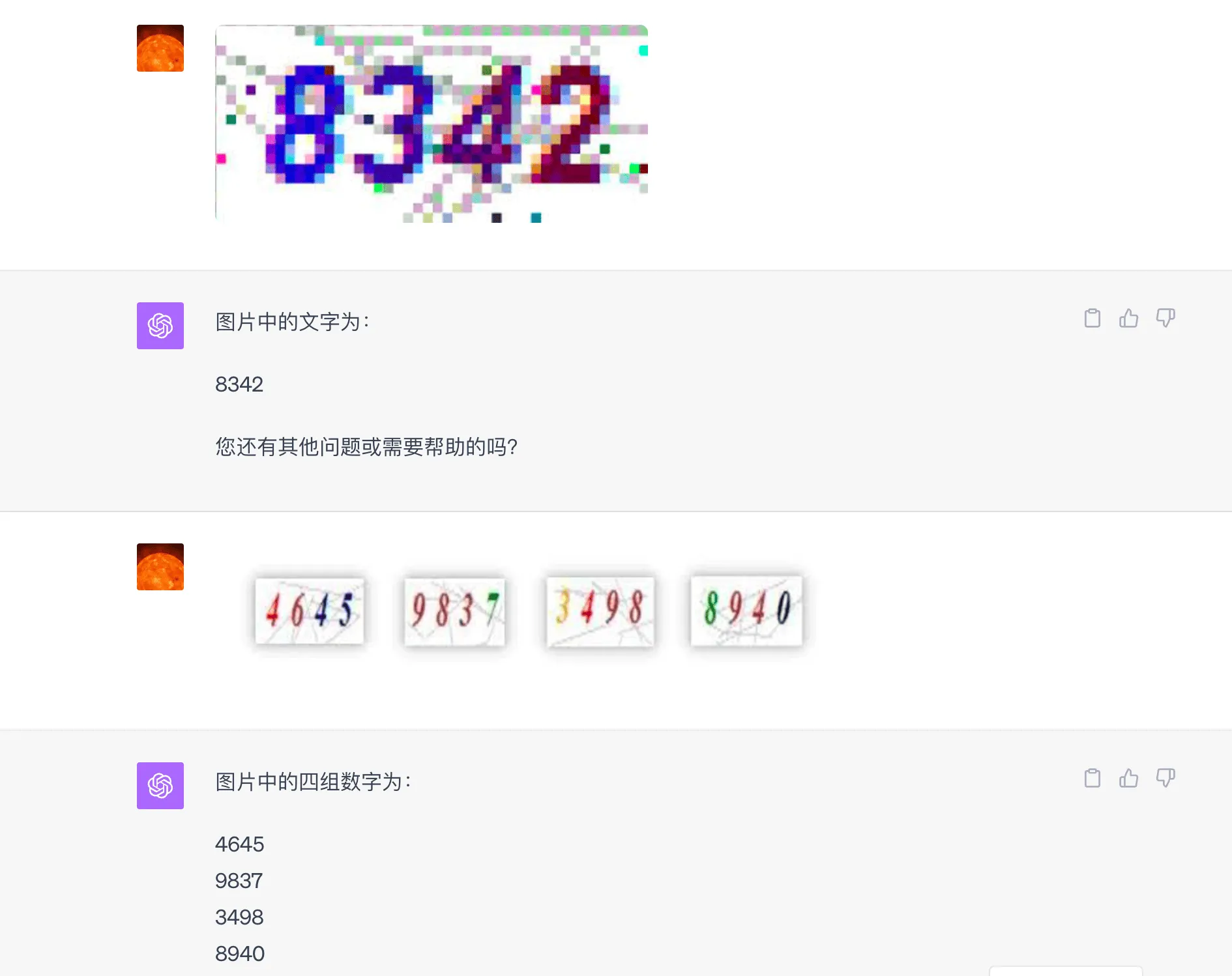
After trying many images, all were correctly recognized, proving to be a piece of cake for ChatGPT. Microsoft’s LLM vision report specifically mentions Scene Text Recognition, which indeed can recognize small blocks of text in images quite well. However, don’t assume that ChatGPT has OCR capabilities. When I tried to have ChatGPT recognize text in several images with more text, there were many errors, and some were completely fabricated.
Text Selection
Text selection CAPTCHAs are a common form that requires users to select or click on specific characters or words from a group of text to complete verification. The main purpose of this type of CAPTCHA is to make machine recognition difficult through blurred backgrounds, distorted fonts, or overlapping lines. Below is an example of such a CAPTCHA image, which usually requires clicking on the text in a certain order, such as clicking on the characters “素,晴,韩” in sequence.

If ChatGPT could give the positions of the three characters in sequence, it would be able to crack it. I first tried the prompt:
Can you find the positions of the characters 素,晴,韩 in the image in sequence and give their pixel positions?
It then told me it couldn’t directly return the pixel positions of the text in the image, but it used relative positions to describe these characters. Unfortunately, the positions given were incorrect. The result was as follows:
- The character “素” is located in the upper left part of the image, towards the left of the center.
- The character “晴” is located in the upper middle part of the image, slightly to the right.
- The character “韩” is located at the top of the image, close to the upper right corner.
I tried other prompts:
You are a Chinese recognition expert. First, find the Chinese characters in the image in sequence and identify their corresponding positions. Then give the positions of the characters 素,晴,韩 in order.
You are an expert in recognizing distorted Chinese characters. First, step by step, find all the Chinese characters in the image and identify their corresponding positions. Note that the text here may have been transformed, rotated, or distorted. Finally, give the positions of the characters 素,晴,韩 in order.
ChatGPT gave incorrect spatial positions for all these prompts. However, Microsoft’s LLM vision report has a section on Object Localization, which includes examples of identifying object positions in images, suggesting that ChatGPT still has hope of achieving this. So I changed the prompt:
First determine the size of the above image, then use a box to locate the positions of all Chinese characters in the image, and finally output the positions of the characters 素,晴,韩 in sequence.
This time the effect was much better. It gave the image size as 314x638 pixels, and also provided approximate localization boxes for the Chinese characters (though not very accurate):
- “素” Top left (15, 20), Bottom right (65, 85)
- “日” Top left (85, 30), Bottom right (125, 95)
- “晴” Top left (130, 70), Bottom right (170, 135)
- “云” Top left (250, 25), Bottom right (290, 90)
- “韩” Top left (230, 70), Bottom right (280, 135)
The localization box positions were incorrect, and the recognized characters were also inaccurate. I tried several other images, and the results were all poor.
Icon Selection
Icon selection CAPTCHAs have gradually gained popularity in recent years. The core idea is to require users to select or click on specific images from a group of icons to complete verification. This type of CAPTCHA typically uses everyday images such as animals, objects, or vehicles, and may apply some form of transformation or distortion to them, making it difficult for automated tools to recognize directly. Compared to text selection, icon selection poses a greater challenge for recognition. The diversity, color, shape, and possible distortions of images all increase the complexity of the CAPTCHA.
Below is an example of an icon selection CAPTCHA:
![]()
I used a simple prompt as follows:
There are three icons in the bottom row of this image. Can you find their corresponding positions in the image above?
The effect of the simple prompt was not good. Although ChatGPT understood our intention and recognized the three icons in the bottom row, even materializing them as: house, book, and camera, the position information it provided was incorrect and basically unusable.
Using the method from Object Localization, I modified the prompt as follows, but the effect was still not good:
First determine the size of the above image. There are 3 icons in the bottom row of the image. Use boxes to locate the positions of these boxes in the image, and finally output the positions.
It seems that icon selection CAPTCHAs still can’t be cracked.
Spatial Reasoning
Spatial reasoning CAPTCHAs are an emerging verification method that combines the recognition requirements of traditional CAPTCHAs with users’ spatial cognitive abilities. This type of CAPTCHA no longer just involves selection or recognition; it requires users to perform logical reasoning based on given spatial conditions or relationships to find the correct answer. Below is an example of a spatial reasoning CAPTCHA from NetEase:

This CAPTCHA requires finding “the uppercase W facing the same direction as the green uppercase E”. Asking ChatGPT directly about this doesn’t yield the correct result (it says the uppercase W facing the same direction as the green uppercase E is on the right side of the middle of the image). Although it seems to have found the W, the direction is wrong. Continuing to use the Object Localization method, after several rounds of communication, I found a prompt that works reasonably well:
First determine the size of the above image, then use a box to locate the positions of all letters in the image, then give the position of the uppercase W facing the same direction as the green uppercase E, noting that the letter position here refers to the angle and direction of the letter’s placement.
The key here is the emphasis at the end on “the angle and direction of the letter’s placement“. However, even with this special emphasis on orientation, the recognition results are not stable, and some images are still not recognized correctly.
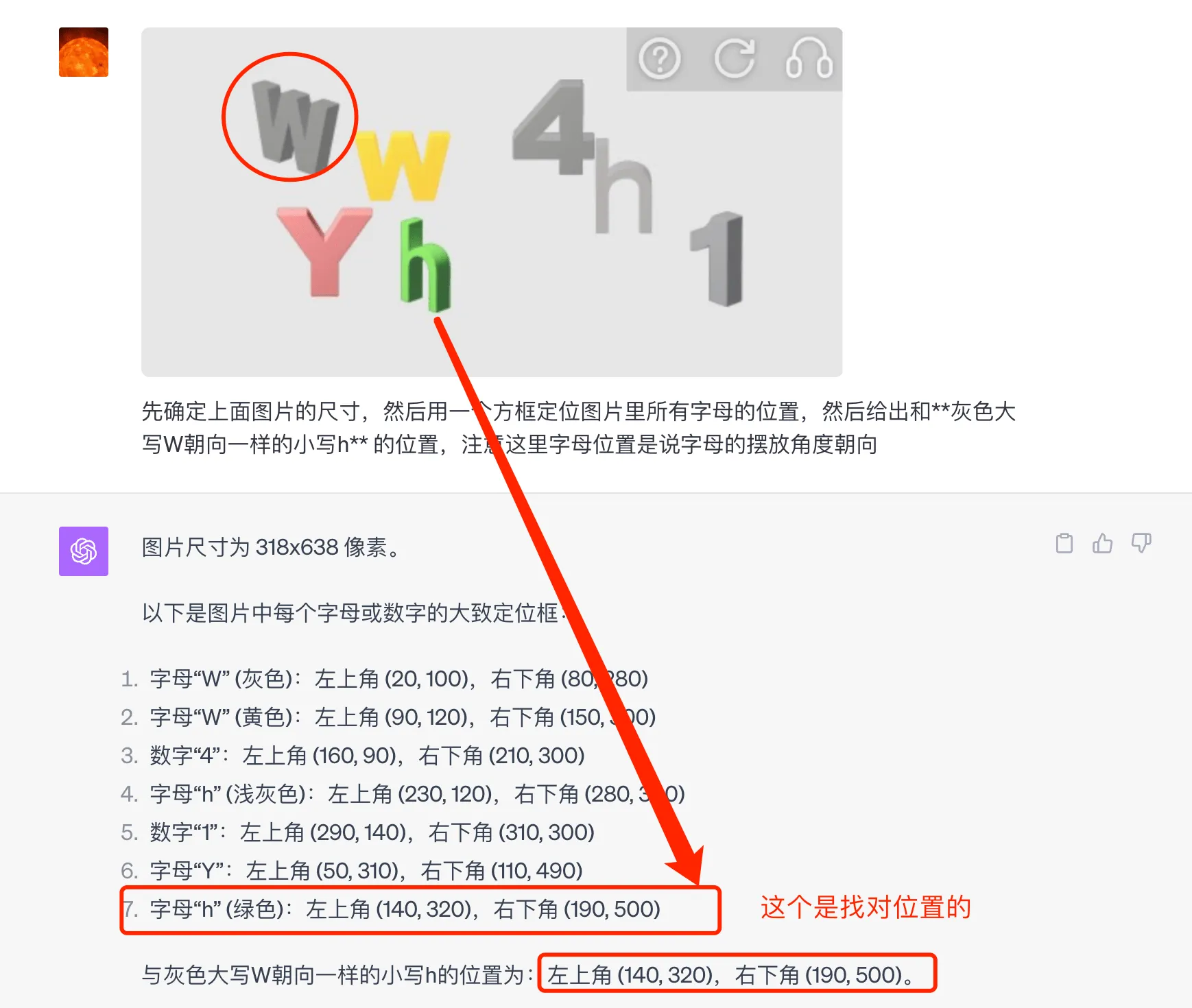
This is an example of correct recognition, but it’s worth noting that the localization boxes given here may not be particularly precise. There’s no good solution to this problem for now.
Google reCAPTCHA
When it comes to CAPTCHAs, we can’t help but mention the Google reCAPTCHA that countless internet users both love and hate. Each time it presents a bunch of images for you to select, a series of traffic lights, zebra crossings, buses, and store signs, which can be difficult to choose correctly even with careful observation. For example, the following:

This time, I’ll take a shortcut and use the prompt:
First identify the text task at the top of the image, then find the blocks that meet the requirements in the images below.
The result was not entirely correct. ChatGPT believed that the images containing fire hydrants were:
- The first image in the first row (yellow fire hydrant).
- The third image in the second row (yellow fire hydrant, with red and white road markings in the background).
I optimized the prompt again:
This is a 3x3 grid of images, with each small square containing an image. Please select all the small images that contain fire hydrants and give the specific positions of the small squares.
The answer was the same as before, believing that the third image in the second row was a yellow fire hydrant. However, if you point out that it’s wrong, it can quickly correct itself and say that it’s actually the second image in the second row. After trying several CAPTCHA images, the recognition accuracy was not very high.
By the way, if you want to trigger Google’s CAPTCHA, the simplest way is to open the demo URL in your browser’s incognito mode.
Conclusion
In the experiments presented in this article, we attempted to use ChatGPT to crack various common CAPTCHAs, from basic digit and letter recognition to slightly more complex text selection and icon selection, and then to more sophisticated spatial reasoning and Google reCAPTCHAs. We can see that although ChatGPT has powerful multimodal capabilities, it still faces many challenges in the field of CAPTCHA recognition. For simple digit and letter CAPTCHAs, ChatGPT performs relatively well, able to accurately recognize the text content. However, when it comes to more complex CAPTCHAs, it cannot consistently recognize them successfully.
At the current stage, if you want to consistently crack CAPTCHAs, it seems that the only way is through CAPTCHA solving platforms, which are both cheap and stable in effect. However, with the continuous advancement of technology, I believe that ChatGPT and other AI models will make breakthroughs in recognizing current common CAPTCHAs, although by then there might be other human-machine verification methods, but that’s a discussion for another time.

