C++ Zip Archive Creation - Debugging Memory Corruption Issue
In daily C++ backend development work, dynamically generating Zip packages is rare, so I’m not familiar with C++’s libzip. Recently, I encountered a scenario where I needed to compress some backend-generated data into a Zip package for download. There was already existing code for generating Zip packages, but I needed to add a file to the Zip package. It seemed like a simple requirement, but during implementation, I encountered a strange problem: after unzipping the generated Zip package, the beginning of the files inside was corrupted.
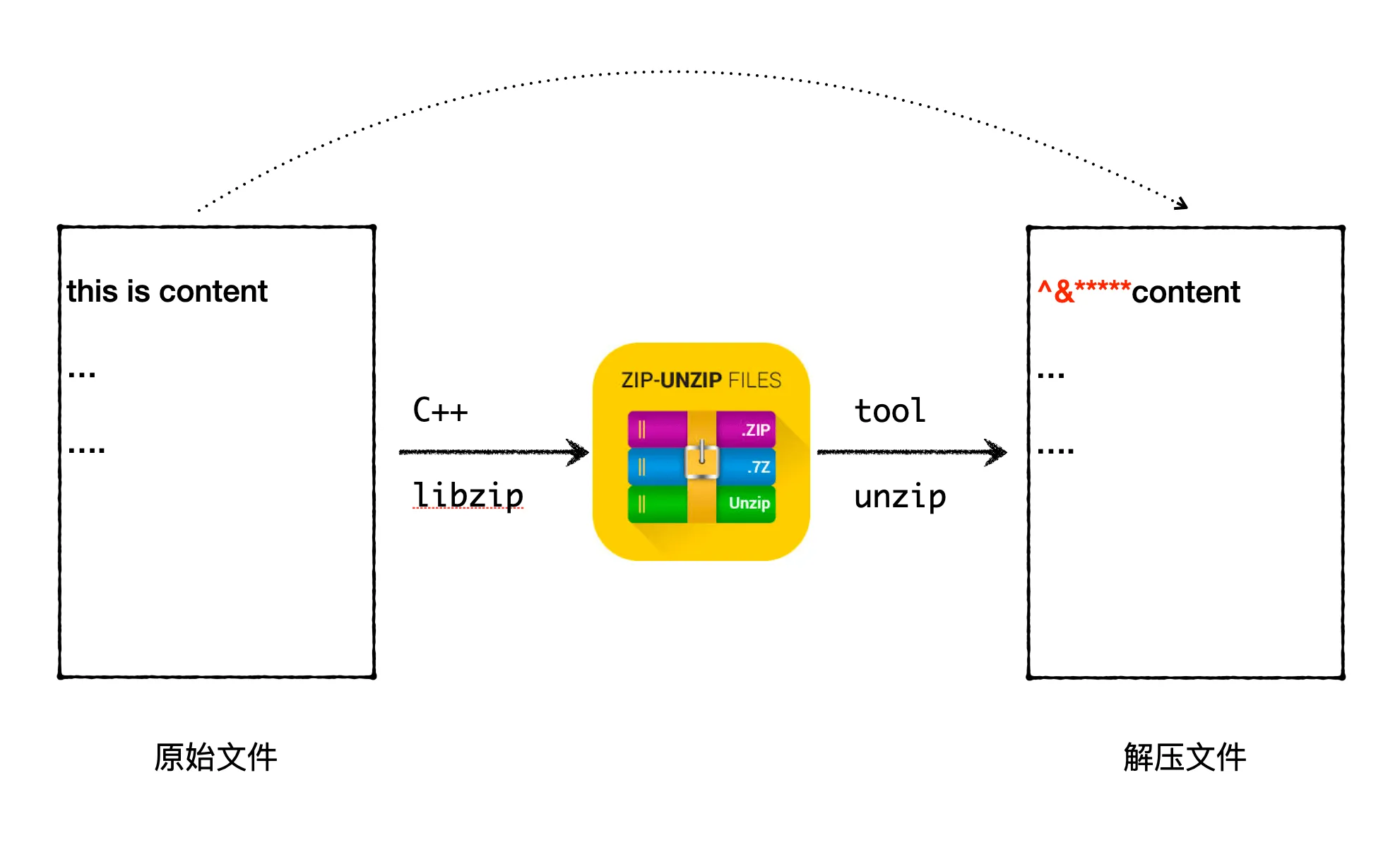
During the troubleshooting process, I took some detours before finally discovering that it was a C++ memory issue. Here, I’ll record the problem’s troubleshooting and fixing process, as well as the source code interpretation of the third-party Zip library. Readers unfamiliar with C++ can also read with confidence to experience how difficult C++ memory issues can be to debug.
Problem Reproduction
In the business logic, we obtained some data through an RPC request, processed this data, generated a Zip package, and finally returned it to the frontend. After decoding the zip package, the frontend found that some content was corrupted and didn’t conform to the pre-agreed protocol content. Since it was a consistently reproducible problem, it was relatively easy to locate. By directly adding debug logs, we found that the data retrieved from RPC was fine, but after generating the Zip package, the content inside had some corrupted content.
To easily reproduce the problem, I extracted the Zip package generation part and wrote a simple example. The core code is as follows:
1 | zip* archive = zip_open(tmpFile, ZIP_CREATE | ZIP_TRUNCATE, &error); |
The complete code is available on Gist. The logic is quite simple: it puts a string from the code into a file and then adds it to the tar package. After compression, it tries to unzip the tar package using the unzip tool and prints the file contents. Note that you need to install the libzip library on your system.

The original content of the file was (<?xml version="1.0" encoding="utf-8" standalone="no"?>demo, but as you can see from the above run result, the output content is directly corrupted. To see exactly what the content of the unzipped file is, we can use hexdump to view the file contents:
1 | $ hexdump -C file1_temp.xhtml |
We found that the entire content is completely different from the input string, and the corrupted content is also very strange, with no place generating such corrupted content. At this point, it’s best to debug with GDB or directly look at the documentation or source code of the zip library to see where the problem is.
Problem Troubleshooting
However, since ChatGPT came along, my first reaction when encountering a problem is to throw it to ChatGPT to see. I first threw this part of the code for writing the zip package directly to ChatGPT, then asked, “Is it reasonable to add files like this?” ChatGPT believed that this code is basically reasonable and there are no incorrect usage methods. No problem, I continued to ask, this time providing more details in the prompt, referring to ChatGPT Prompt Best Practices 2: Providing Reference Text, as follows:
Why is the content of file1_temp.xhtml not equal to htmltemlate after unzipping the zip file generated with the above code, with corrupted content at the beginning?
hexdump -C file1_temp.xhtml
00000000 00 dc 14 b3 f8 55 00 00 50 a2 2a a1 07 7f 00 00 |.....U..P.*.....|
00000010 00 a2 2a a1 07 7f 00 00 c4 02 00 00 00 04 00 00 |..*.............|
ChatGPT truly is a jack of all trades, immediately giving what seemed to be a correct answer:

According to ChatGPT’s answer, after the loop over FileInfos is completed and before zip_close is called, the content in item.htmltemlate‘s memory may have already been released, so the added content is incorrect. This conclusion is easy to verify if it’s reliable. We can directly modify this line of code:
1 | for (const auto &item : FileInfos) { |
Change this to a reference (actually, it should have been a reference to begin with, which can reduce copy operations), run it again, and indeed, the problem is solved.
GDB Verification
After locating the problem, let’s go back and use GDB to verify the execution process of the program with corrupted output. The implementation of libzip is quite complex, but the most crucial parts are the zip_source_buffer and zip_close functions. According to the previous code, we can reasonably guess that when zip_source_buffer adds htmltemlate, it doesn’t copy the content in memory, but only references the address. Then, when zip_close is called, it goes to read the content in this htmltemlate. However, by this time, the htmltemlate memory has already been released, and the content inside is undefined, which could be corrupted or might still be the old value.
Since we don’t have much time to spend reading the libzip source code, to quickly verify this guess, we can debug step by step using GDB. To see the debug symbols of the libzip library with GDB, download the libzip source code and recompile it with -g.
Adding Debug Symbols
1 | $ git clone https://github.com/nih-at/libzip.git |
Then recompile the previous code, specifying the paths for the libzip header files and library files.
1 | $ g++ zip_test.cpp -o zip_test -L/root/libzip/build/install/lib -lzip -Wl,-rpath=/root/libzip/build/install/lib -g -fno-omit-frame-pointer |
As we can see, the binary is now using the recompiled libzip with debug information.
Locating Memory Read Position
Here, we want to verify that the content is read from htmltemlate to create the compressed package only when zip_close is called. Initially, I thought of simply looking at the zip_close code to confirm where it reads and then set a breakpoint at the appropriate place. But I found that the function calls go down layer by layer, and it’s difficult to find a suitable place to set a breakpoint in a short time.
I took some detours here, thinking of using some tools to find the function call stack of zip_close, so that I could quickly find the core functions.
- Tried to use ebpf’s stackcount to trace the function call stack,
stackcount -p $(pgrep zip_test) 'zip_*', but it kept reporting errors: Failed to attach BPF program b’trace_count’ to kprobe , it’s not traceable (either non-existing, inlined, or marked as “notrace”); In the end, I couldn’t find a solution (if anyone knows the reason, please leave a comment). - Used Valgrind’s callgrind tool,
valgrind --tool=callgrind ./zip_testto generate call relationships, and then usedgprof2dotanddotfor visualization. This did show some execution flow, but there was no zip_source_buffer function.
Since it’s difficult to clarify the code here, let’s start directly from the memory address. We know that GDB can use rwatch to monitor read operations of a certain memory address, so we can rwatch the memory address of htmltemlate before zip_close ends to see exactly when the content here is read.
The overall GDB debugging approach is as follows: First, set breakpoints at the lines where zip_source_buffer and zip_close are located, as well as just before the final exit. Then execute to the zip_source_buffer breakpoint, print the memory address of htmltemlate, set rwatch, and then continue to see where this memory address is read.
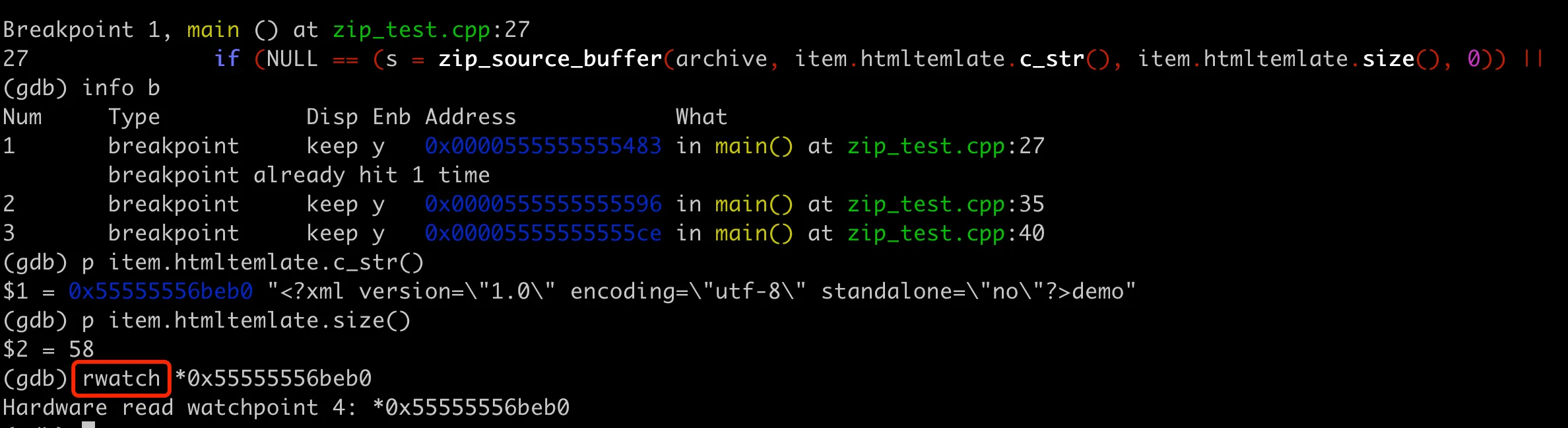
The above image shows execution to the zip_source_buffer breakpoint, printing the memory address of htmltemlate, then setting rwatch, and continuing to see where this memory address is read.
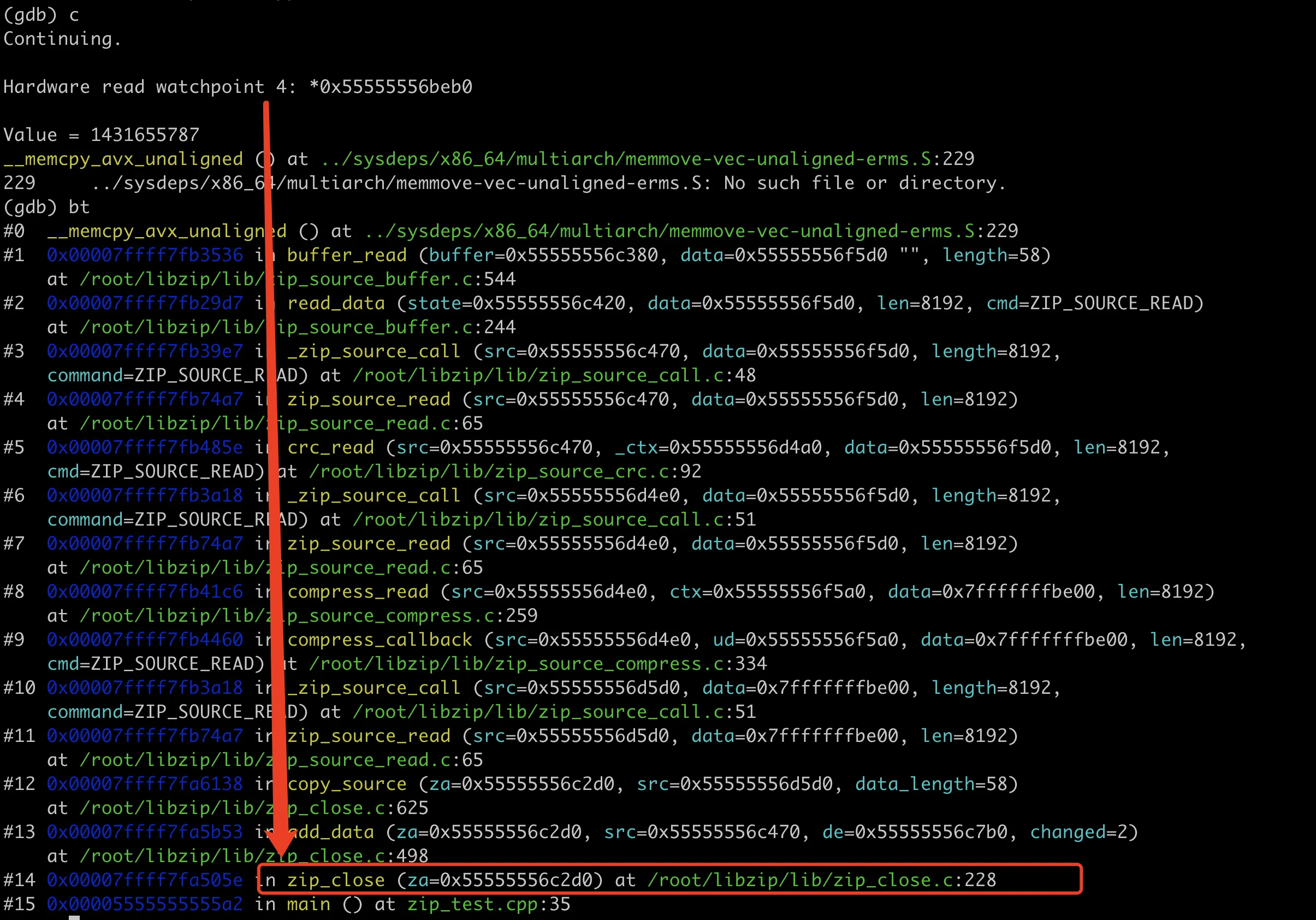
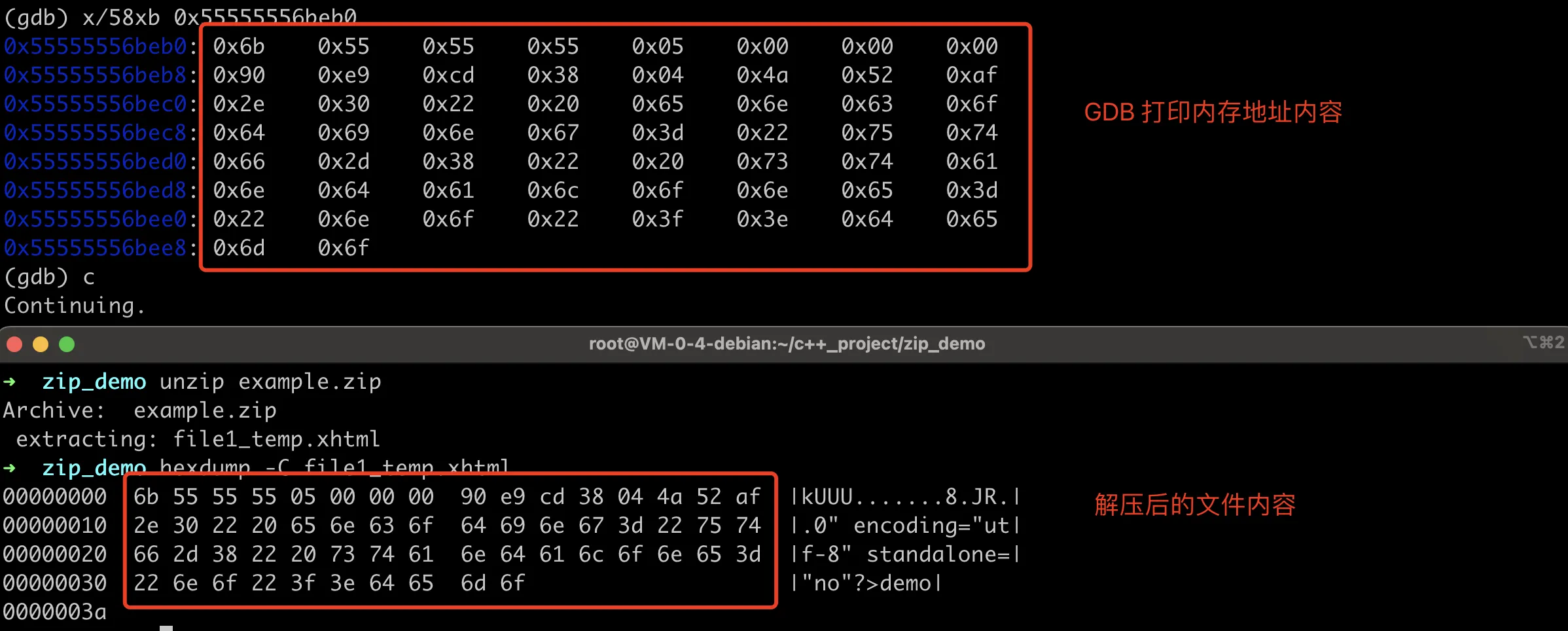
At this point, we’ve verified our earlier guess. The content of htmltemlate is not read in zip_source_buffer, it’s only read when creating the compressed package during zip_close. The memory address here is 0x55555556beb0. If we print the content at this point, it should match the final generated corrupted content, as shown in the following image:
Summary
Quite a few people have encountered this problem, such as these two questions on Stack Overflow:
- libzip with zip_source_buffer causes data corruption and/or segfaults
- Add multiple files from buffers to ZIP archive using libzip
In fact, even the official documentation of libzip has issues. The official documentation for zip_source_buffer states:
The functions zip_source_buffer() and zip_source_buffer_create() create a zip source from the buffer data of size len. If freep is non-zero, the buffer will be freed when it is no longer needed. data must remain valid for the lifetime of the created source.
The documentation says that data must remain consistent with the lifetime of the source, which is not accurate. Here, it must be ensured that the data is not destroyed before zip_close is called. In other languages, there wouldn’t be such a bizarre interface design, but in C, this kind of design is not uncommon. Many classic C libraries have this kind of design.

