Training and Deploying a Text Classification Model with BERT from Scratch
Previously, I created a tool for Lawyer Xiao Sheng to regularly screen posts online and determine if they are legal consultation-related. This requires text classification to judge whether the specified post content involves legal issues. As a backend developer with no experience in natural language processing, I only had a basic understanding of machine learning principles from my studies, but had never actually done a classification task. Fortunately, with ChatGPT now available, I decided to use its API for classification.
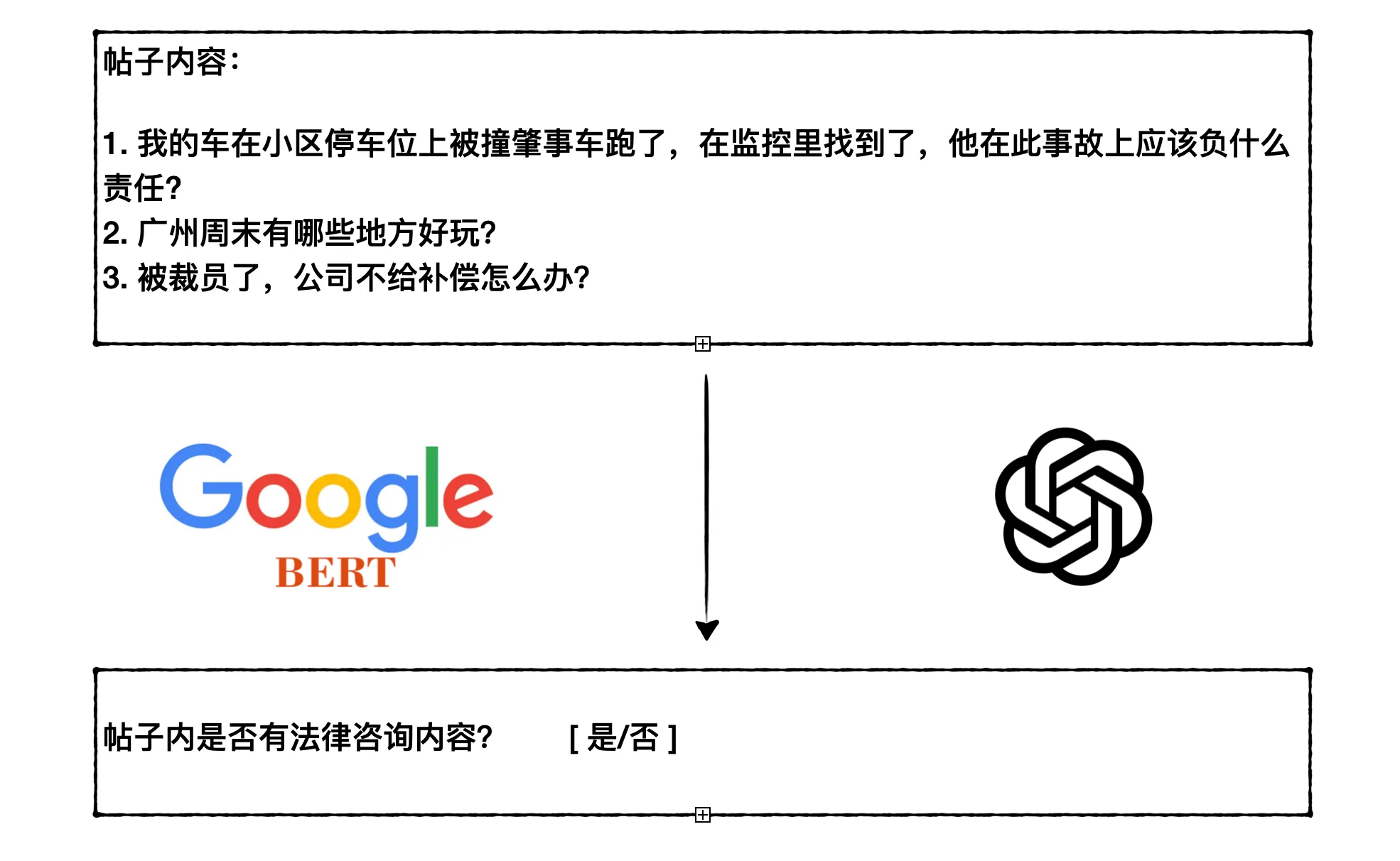
After running ChatGPT for a while, I found two problems with using it for classification:
- High cost. Currently using the GPT3.5 model, if there are many posts, it costs several dollars per day. So the current approach is to first filter with keywords, and then use the GPT3.5 model for classification, which misses some relevant posts without keywords.
- Misidentification. Some posts that are not legal consultation questions are also misjudged by GPT3.5. This hallucination problem persists even after improving the prompt. You can see examples in my article Real Examples Showing How ChatGPT Can Make Things Up!.
So I thought about training my own model for text classification. The most famous model in natural language processing is BERT, so I trained a classification model based on bert-base-chinese, which works quite well. This article mainly records the entire process of dataset preparation, model training, and model deployment. With the help of ChatGPT, the whole process was much simpler than I imagined.
Online Experience
Before we begin, let me give you an experience of this model (only available at the original blog post URL). Enter some text in the input box below, click the “Real-time Model Prediction” button, and you’ll see the prediction result. Due to my personal server’s poor configuration, each prediction takes about 2 seconds here, and only one request can be processed at a time. If it takes too long, you can try again later.
For example, the following are consultation-type texts:
My car was hit in the parking lot of the community and the hit-and-run vehicle was found on surveillance. What responsibility should they bear in this accident?
In November 2021, I worked with an individual contractor in Wuan City Smart City, and in the end, wages were owed and not given. How can I get them back?
The following are non-legal consultation texts, excerpted from article titles in my blog:
Analysis of C++ process coredump caused by missing dependencies in Bazel
ChatGPT Penetration Analysis: Search Trends, Demand Map, and Population Characteristics
Dataset Preparation
The prerequisite for training a model is to have a dataset. Specifically for my classification task, I needed to find many legal consultation texts and non-legal consultation texts.
Non-legal consultation texts are easy to find. I used post content from the programmer community V2EX. V2EX also provides a convenient API to directly get the titles and content of posts. I spent a day crawling about 200,000 post contents and saved them in a PostgreSQL database. Actually, there are a few legal consultation contents among these posts, but the overall proportion is very small and should not significantly affect the overall training effect of the model. Legal consultation texts are harder to find. After some attempts, I finally found some on a public site, totaling about 200,000.
I saved these two types of texts in separate files, with each line being a JSON file containing the text content. Here are some examples:
| Text Content | Is Consultation |
|---|---|
| Will filing for divorce investigate the bank card transactions or deposits of the other party or both parties? | Yes |
| The person being executed has the ability to repay, for example, work income, monthly income of 4,000, repaying 1,000 per month, but the person being executed evades and does not repay a penny. Can they be held accountable, and what are the legal provisions? | Yes |
| I lent money to someone, they always say they’ll repay but never do, I didn’t write an IOU at the time, I want to ask what to do! | Yes |
| I want to find the icon in this Android game apk file | No |
| I’ve never developed an official account, I want to ask, when the official account receives a push message, then clicking the message jumps to a third-party application, can this be achieved? The third-party application is not listed on the app store | No |
| Apart from competing with competitors for screen ratio and looking cooler, I really can’t think of any practical significance, it feels more solid with a border | No |
Model Training
With the dataset prepared, we can start training the model. I hadn’t had much exposure to BERT before, nor had I done neural network model training. Fortunately, with ChatGPT, I quickly wrote a complete training code. I used PyTorch for training here, and ChatGPT provided complete training code along with detailed code explanations. For any parts I didn’t understand, I first asked AI, then combined it with some materials to gradually understand.
The complete training script is on Gist, and the overall process can be summarized as follows:
- Data loading and preprocessing: Load the dataset from JSON files, convert the data into (text, label) format and shuffle randomly. Use
train_test_splitto divide the data into training and validation sets. - Encoding using
BERT Tokenizer: Use BertTokenizer for text tokenization and encoding, including adding special tokens, truncation, and padding. - Building datasets and data loaders: Convert the encoded data into TensorDataset. Create data loaders for training and validation sets using DataLoader.
- Defining model, loss function, and optimizer: Define a custom PyTorch model containing the BERT model and additional classification layers. Use Focal Loss as the loss function, suitable for handling class imbalance problems. Use the AdamW optimizer.
- Model training and validation: In the training loop, process data in batches, calculate loss, backpropagate, and update model parameters. Evaluate model performance using the validation set at the end of each training epoch. Apply learning rate scheduler and early stopping mechanism to optimize the training process.
- Performance evaluation: Calculate and print metrics such as accuracy, precision, recall, and F1 score.
- Model saving: Save the model’s state when performance improves.
Here, you don’t even need any neural network or machine learning basics. With just a dataset and ChatGPT, you can continuously adjust the code and train a model with good performance. However, as an ambitious developer, I still want to try my best to understand the principles behind each line of code, so that I can better understand the process of model training. In addition to constantly questioning ChatGPT and verifying its answers, I also found a good deep learning beginner tutorial, Dive into Deep Learning, which contains a lot of deep learning knowledge and code practices, very suitable for beginners.
Model training requires GPU machines. If you don’t have a good GPU personally, you can use the free T4 GPU quota on Google Colab for training. However, memory is limited, so when training, be sure to appropriately reduce the batch_size. I usually use batch_size=16 on Colab. If the dataset is too large, training one epoch here may take a long time, and the free quota may only be enough for a few epochs of training.
Model Deployment
After the model is trained, a torch model file model.pt will be saved. How to deploy an HTTP service using this model file? In simple terms, you can use ONNX Runtime + Flask + Gunicorn + Docker + Nginx for deployment.
- ONNX Runtime is a high-performance inference engine that can be used to load and run models.
- Flask is a Python Web framework used to write Web services. Gunicorn is a Python WSGI HTTP server used to start Flask services.
- Docker is a containerization tool used to package and run services.
The overall deployment structure can be referred to in the following diagram:
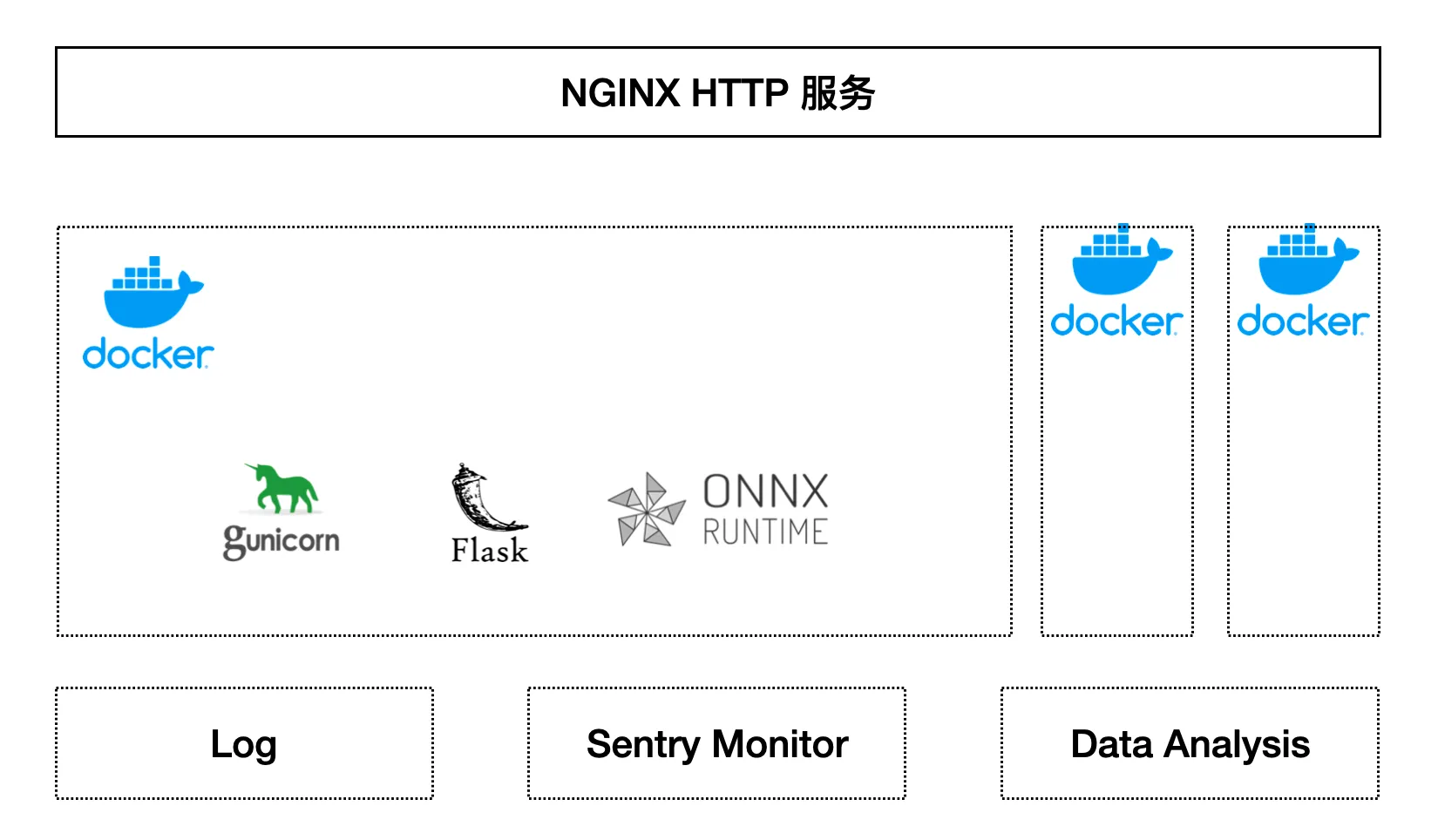
After Nginx receives an HTTP request, it will forward it to Gunicorn. Gunicorn will start the Flask service. The Flask service uses the loaded ONNX model file and inference environment to predict the requested text and finally return the prediction result. The core code of the Flask service is very simple, as follows:
1 | session = ort.InferenceSession('model.onnx') |
To facilitate the deployment of Gunicorn, Flask, and various dependencies, Docker is used to package them. The Dockerfile is as follows:
1 | FROM python:3.8-slim |
Then you can start the service with the following command:
1 | docker build -t lawer_model . |
The Nginx reverse proxy configuration is not mentioned here. At this point, the entire service has been deployed. However, to better monitor the service, you can use Sentry for performance monitoring and error tracking. The service can also add some logs appropriately to facilitate troubleshooting.
Additionally, my service domain is api.selfboot.cn. To access it from the blog page, we need to open CORS restrictions to allow cross-origin access. Here, flask-cors is used. You just need to add the following line of code in the Flask service:
1 | CORS(app, resources={r"/*": {"origins": ["https://selfboot.cn"]}}) |
Up to this point, the above is basically enough as a demonstration service. However, to serve as a formal online service, we need to consider disaster recovery and other issues, which may require the introduction of cluster deployment solutions such as k8s. We won’t expand on this here.
Some Shortcomings
After running this model for a while, I found that some text classifications are still not very accurate. For example, the following are also misjudged by the model as legal consultation questions:
My friend asked me to lend him money, should I lend it to him or not?
Borrowing money
I want to consult, how can I earn more money?
If I can’t get into university, what should I do?
This has a lot to do with the dataset. There is a lot of similar content in the legal consultation dataset, causing the model to learn incorrect features. Some keywords appear frequently in consultations, causing the model to tend to consider content with these keywords as legal consultations. For example, just entering “borrowing money“ or “I want to consult“ will be judged by the model as legal consultation. To see the distribution of some keywords in the legal consultation texts in the training set, I generated a word cloud with this part of the data, as shown in the following figure:

If you want to optimize this, you need to focus on the dataset, such as selectively adding some non-legal consultation texts, or doing some cleaning on the dataset to remove some noisy data. I didn’t continue to optimize here, as the current classification effect already meets the usage requirements.
Changes Brought by AI
The process of model training and deployment would have taken me a lot of time in the past. Because I would need to look up various materials and documents before I could write training code, write deployment services, and write Docker configurations. But now with ChatGPT, the whole process didn’t take much time. Most of the code in this article was completed with the help of ChatGPT, and some configurations and details were also completed by ChatGPT. For example, the ONNX model inference part in the following image:
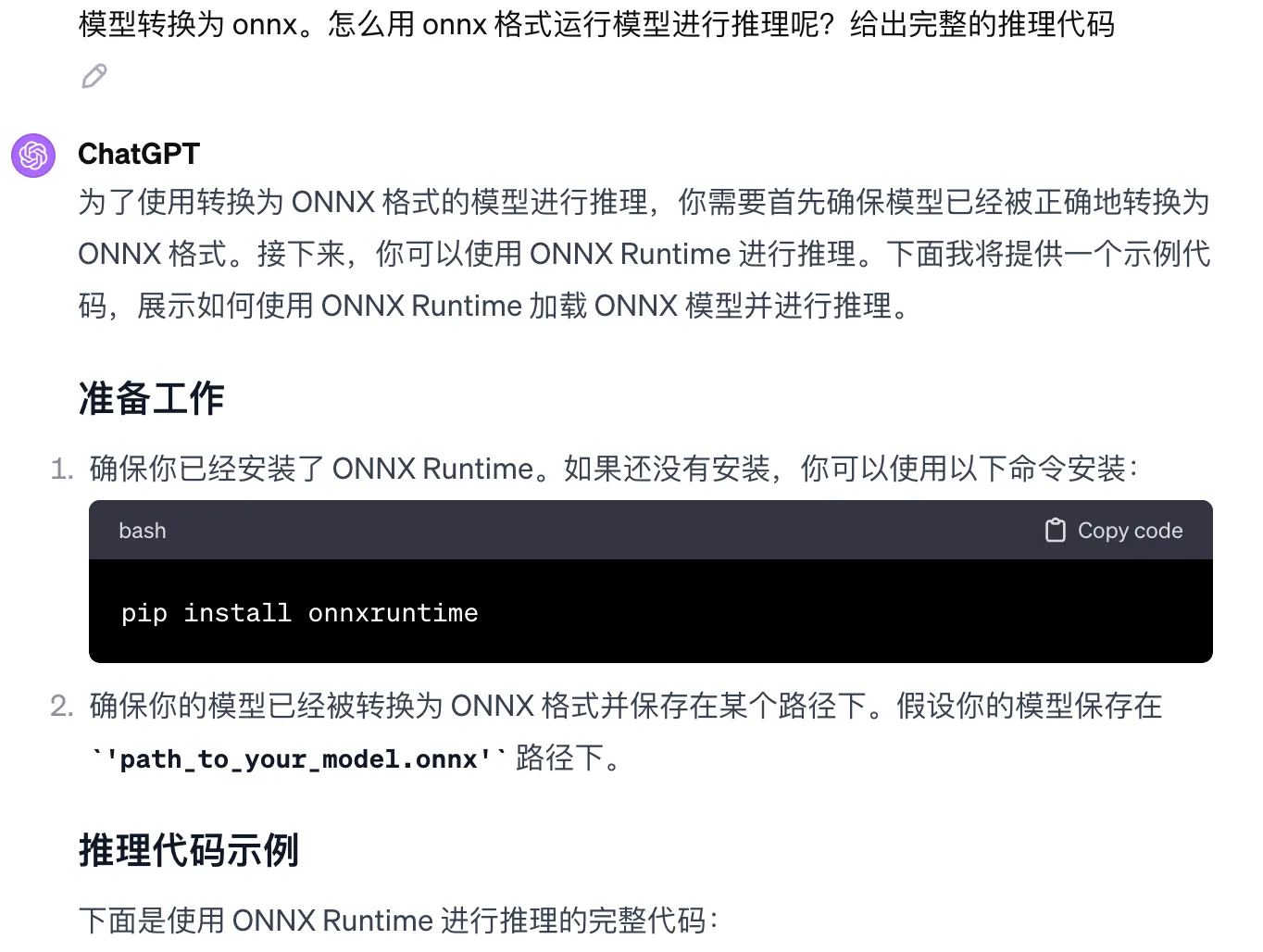
Even the code for crawling the dataset and the frontend code for the input box in this article were completed with the help of ChatGPT. What I needed to do was break down tasks, describe them clearly, and verify ChatGPT’s responses.
While greatly improving efficiency, ChatGPT can also help learn new fields. For example, my understanding of deep learning was previously vague, but now that I’ve actually used BERT, I’ve continuously deepened my understanding of deep learning throughout the process. When learning a new field, ChatGPT can fully act as a teacher, and it’s the kind of teacher that can tailor its teaching to the individual and provide help at any time.
Everyone deserves to have a ChatGPT and should get used to working with it as early as possible to maximize the effectiveness of AI.
Conclusion
This article has demonstrated how to train and deploy a text classification model using BERT, starting from scratch. We’ve covered the entire process from data collection to model deployment, including:
- Preparing a dataset of legal consultation texts and non-legal consultation texts.
- Training a BERT-based classification model using PyTorch.
- Deploying the trained model as a web service using Flask, Gunicorn, and Docker.
- Integrating the model into a real-world application with a simple web interface.
Throughout this process, we’ve seen how AI tools like ChatGPT can significantly accelerate development and learning in new fields. The ability to quickly implement complex machine learning projects with minimal prior experience in the field is a testament to the power of modern AI assistants.
However, we’ve also observed some limitations of the model, particularly in its tendency to misclassify certain types of non-legal texts. This highlights the importance of high-quality, diverse training data and the need for ongoing refinement of machine learning models.
As AI continues to evolve, it’s becoming an increasingly valuable tool for developers and researchers across various fields. By embracing these technologies and learning to work effectively with them, we can tackle complex problems more efficiently and push the boundaries of what’s possible in software development and data science.
Remember, while AI can greatly assist in the development process, it’s crucial to maintain a critical eye and validate the results. The combination of human expertise and AI capabilities can lead to powerful solutions, but it requires a thoughtful approach to harness its full potential.

