Hands-on with OpenAI's o1-preview - Not Better Enough?
OpenAI quietly released a new model in the middle of the night, introducing-openai-o1-preview. They released a series of videos showcasing the power of the new model, and the internet is flooded with articles discussing how impressive the new model’s evaluations are. However, having seen plenty of hype in the AI world, I approached it with a skeptical attitude and immediately tried it out firsthand.
Chinese Interpretations
Recently, Li Jigang had a very popular prompt that can generate interesting new interpretations of Chinese characters. I tried it with Claude3.5 and the results were particularly good. Below are some SVG images generated by Claude:

This prompt is particularly interesting as it uses the classic programming language Lisp to describe the task to be executed, and large language models can actually understand it and generate stable, aesthetically pleasing SVG images. This prompt really tests the model’s understanding and generation capabilities. I tried it with GLM and GPT-4o, but neither could generate SVG images that met the requirements. Currently, only Claude3.5 can consistently output good results. So how does OpenAI’s latest o1-preview model perform?
We directly output the prompt, then input the words, and the results are as follows:

Here, it didn’t output SVG, but provided output in Markdown format. Then, an interesting feature of the new model is that there’s a “thinking” process, which will show how long it thinks, and you can click to see the thinking process.
It seems the model can understand the prompt, but the output is a bit problematic. Claude3.5 can directly output SVG format images because of its Artifacts capability. Here, we can directly prompt o1-preview to generate SVG source code, so we make the prompt a bit more detailed and constrain the output format, like this:
Generate svg source code: Universe
This time it finally gave an SVG source code, generating a new Chinese interpretation image for “Universe”. Then I thought the model had understood my intention, so I directly input “mathematics”, but the model still gave the initial Markdown output. Each time, you must explicitly prompt “Generate svg source code” before the word to get the desired SVG format output. The image below shows the output for three words, which can be compared with the previous Claude3.5 results.
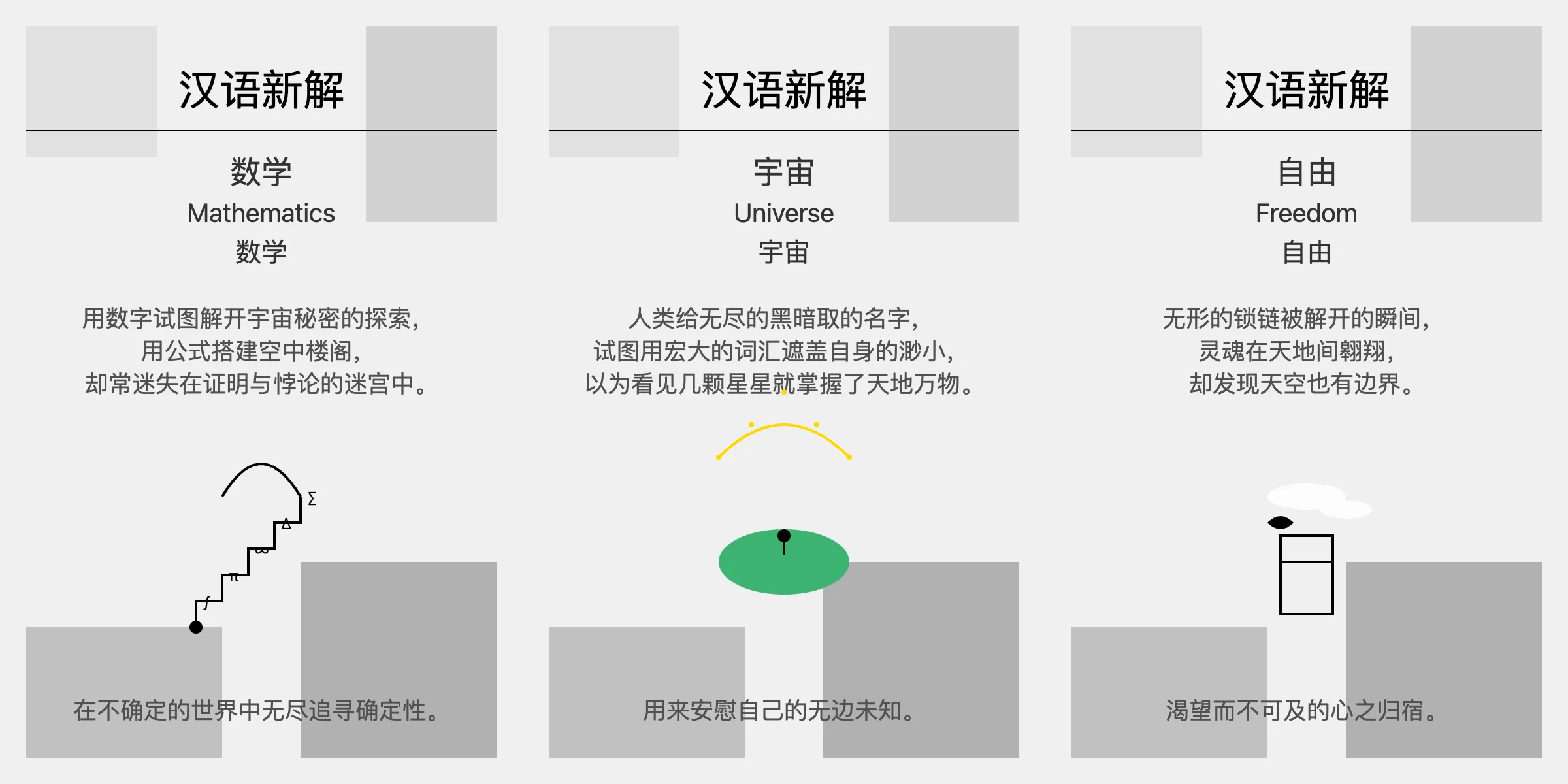
Personally, I feel that the images generated by Claude3.5 are more concise and aesthetically pleasing, while those generated by o1-preview are a bit rough. In terms of text content, Claude3.5’s interpretations are also more profound, while gpto1’s are a bit straightforward.
Code Understanding Capability
OpenAI’s new model emphasizes its strong ability to write and understand code, which is exactly what I need. I’ve recently been looking at the LevelDB source code implementation, and the test cases for the skip list are a bit complex. Although the code isn’t extensive, it’s a bit challenging to understand.
I’ve tried using GPT4 and Claude3.5 to interpret it before, and while they provided considerable help, some questions still didn’t get convincing answers. This is a good opportunity to have the o1-preview model interpret it. Before addressing my questions, I first had it read the concurrent testing code here to see how it understands it. The prompt was:
This is the concurrent testing code for LevelDB’s skip list. Please analyze this code and tell me the advantages of this test implementation.
// We want to make sure that with a single writer and multiple
// concurrent readers (with no synchronization other than when
…
When prompting, I provided the complete code, but I’ve omitted the latter part of the code here. The model’s result was fairly good, slightly better than Claude3.5’s previous attempt. It analyzed the code in several parts, including key data structures and concepts, core methods, the execution flow of concurrent testing, and finally summarized the advantages of the test code. Here’s an excerpt:
1 | 3. Execution flow of concurrent testing |
Then came my question:
The value of K here is now 4, why design such a small value? Which part of the test will this value affect?
At this point, gpto1 started to give inaccurate information.
1 | The value of K is set to 4, which is a very small value, aimed at increasing access conflicts to the same set of keys in the test, thereby more effectively detecting potential issues in a concurrent environment. |
Here, I continued to prompt:
That’s not right, is it? K here only affects the first 24 bits of the final key value, and the key values inserted into the linked list also have other gen and hash bits, which won’t be repeated, right?
This time the model thought for a longer time, and the thinking process was quite interesting, as shown below:

But the result given still couldn’t convince me, so I continued to ask:
Why introduce the K value at all? Couldn’t we just use gen and hash for testing?
Also, even if we introduce the K value, taking values from 0 to 4, why give it 24 bits?
The answer seemed to return to the previous pattern, still not providing valuable insights. Of course, Claude3.5 couldn’t give a very good answer to these questions either, and I haven’t come up with a good explanation myself yet. Maybe it’s just something the LevelDB author designed casually, without any particular reason behind it? Feel free to leave your thoughts in the comments section.
I didn’t get a chance to test the code generation ability as I ran out of quota. According to OpenAI’s documentation, currently o1-preview is limited to 30 messages per week, and o1-mini is 50 messages per week. When I have more quota later, I will continue to try this new model, update this article, and strive to provide a comprehensive evaluation.
Revisiting Model Performance
Over the past year, various new models have continually emerged, occasionally claiming to have set new highs in evaluation set scores. However, from practical experience, many models’ capabilities are still relatively average, with some even being unusable. Large model companies seem keen on chasing benchmarks and exaggerating their models’ capabilities, and even Google and OpenAI are not immune to this trend. Google’s previously released Gemini promotional video was exposed as being edited, and many of OpenAI’s official examples for GPT4o’s multimodal capabilities cannot be reproduced now.
To evaluate a model’s capabilities, you ultimately need to try it out yourself multiple times. Recently, I’ve rarely used GPT, instead using Claude3.5 for coding and daily tasks. Whether it’s code generation or text understanding, I feel it’s considerably better than other models. For coding, using cursor paired with Claude3.5 has significantly improved the experience. As a frontend novice with zero foundation, I’ve been able to quickly create many algorithm visualizations using Claude3.5, which are now available on AI Gallery for everyone to experience.

