LevelDB Explained - How to Test Parallel Read and Write of SkipLists?
In the previous article LevelDB Source Code Reading: Principles, Implementation, and Visualization of Skip Lists, we started by discussing the drawbacks of current binary search trees and balanced trees, which led to the introduction of skip lists as a data structure. Then, combining with the original paper, we explained the implementation principles of skip lists. Next, we analyzed in detail the code implementation in LevelDB, including the iterator implementation and extreme performance optimization for parallel reading. Finally, we provided a visualization page that intuitively shows the skip list construction process.
However, two questions remain:
- How to test the LevelDB skip list code to ensure functional correctness? Especially, how to ensure the correctness of skip list implementation in parallel read and write scenarios.
- How to quantitatively analyze the time complexity of skip lists?
Next, by analyzing LevelDB’s test code, we’ll first answer the first question. The quantitative analysis of skip list performance will be covered in a separate article.
Skip List Test Analysis
In the previous article, we analyzed the implementation of LevelDB’s skip list. So, is this implementation correct? If we were to write test cases, how should we write them? From which aspects should we test the correctness of the skip list? Let’s look at LevelDB’s test code skiplist_test.cc.
First is the empty skip list test, which verifies that an empty skip list contains no elements and checks the iterator operations of an empty skip list such as SeekToFirst, Seek, SeekToLast, etc. Then there are test cases for insertion, lookup, and iterator, which verify whether the skip list correctly contains these keys and test the forward and backward traversal of the iterator by continuously inserting a large number of randomly generated key-value pairs.
1 | TEST(SkipTest, InsertAndLookup) { |
These are fairly standard test cases, so we won’t expand on them here. Let’s focus on LevelDB’s parallel testing.
Test Key Design
LevelDB’s skip list supports single-threaded write and multi-threaded parallel read. We analyzed the details of parallel read implementation in the previous article, so how should we test it? Let’s first define the test objective: when multiple threads are reading in parallel, after each read thread initializes its iterator, it should be able to read all the elements currently in the skip list. Since there’s a write thread running simultaneously, read threads may also read newly inserted elements. At any time, the elements read by read threads should satisfy the properties of a skip list, i.e., each element should be less than or equal to the next element.
LevelDB’s test method is designed quite cleverly. First is a carefully designed element value Key (capitalized here to distinguish from key), with clear comments:
1 | // We generate multi-part keys: |
The skip list element value consists of three parts: key is randomly generated, gen is the incremental insertion sequence number, and hash is the hash value of key and gen. All three parts are placed in a uint64_t integer, with the high 24 bits being key, the middle 32 bits being gen, and the low 8 bits being hash. Below is the code for extracting the three parts from Key and generating Key from key and gen:
1 | typedef uint64_t Key; |
Why design key this way? The value of key ranges from 0 to K-1, where K is 4 here. Although key occupies the high 24 bits, its value range is 0-3. In fact, the key value design could work perfectly fine without using the high 24 bits, and it wouldn’t significantly affect the subsequent test logic. I asked gpto1 and claude3.5 about this, but their explanations weren’t convincing. Considering the subsequent parallel read and write test code, my personal understanding is that it might be intended to simulate seek operations with large spans in the linked list. Feel free to correct me in the comments section if you have a more plausible explanation!
The benefits of gen and hash are more obvious. By ensuring gen increments during insertion, read threads can use gen to verify the order of elements inserted into the skip list. The low 8 bits of each key is a hash, which can be used to verify whether the elements read from the skip list are consistent with the inserted elements, as shown in the IsValidKey method:
1 | static uint64_t HashNumbers(uint64_t k, uint64_t g) { |
Here, the low 8 bits of the key value are extracted and compared with the hash value generated from key and gen. If they are equal, it indicates that the element is valid. All the above implementations are placed in the ConcurrentTest class, which serves as an auxiliary class, defining a series of Key-related methods and read/write skip list parts.
Write Thread Operation
Next, let’s look at the write thread operation method WriteStep. It’s a public member method of the ConcurrentTest class, with the core code as follows:
1 | // REQUIRES: External synchronization |
Here, a key is randomly generated, then the previous gen value corresponding to that key is obtained, incremented to generate a new gen value, and the Insert method is called to insert a new key into the skip list. The new key is generated using the previously mentioned MakeKey method, based on key and gen. After inserting into the skip list, the gen value corresponding to the key is updated, ensuring that the elements inserted under each key have incremental gen values. The value of key here ranges from 0 to K-1, where K is 4.
The current_ here is a State structure that stores the gen value corresponding to each key, with the code as follows:
1 | struct State { |
The State structure has an atomic array generation that stores the gen value corresponding to each key. The use of atomic types and memory_order_release, memory_order_acquire semantics here ensures that once the write thread updates the gen value of a key, the read thread can immediately read the new value. For understanding the memory barrier semantics of atomic, you can refer to the Node class design in the skip list implementation from the previous article.
Read Thread Operation
The write thread above is relatively simple, with one thread continuously inserting new elements into the skip list. The read thread is more complex, not only reading elements from the skip list but also verifying that the data conforms to expectations. Here’s the overall approach for testing read threads as given in the comments:
1 | // At the beginning of a read, we snapshot the last inserted |
To ensure the correctness of the skip list in a parallel read-write environment, we can verify from the following 3 aspects:
- Consistency verification: Ensure that read threads do not miss keys that already existed when the iterator was created during the iteration process.
- Sequential traversal: Verify that the order of iterator traversal is always increasing, avoiding backtracking.
- Parallel safety: Simulate parallel read operation scenarios through random iterator movement strategies to detect potential race conditions or data inconsistency issues.
The ReadStep method here has a while(true) loop. Before starting the loop, it first records the initial state of the skip list in initial_state, then uses the RandomTarget method to randomly generate a target key pos, and uses the Seek method to search.
1 | void ReadStep(Random* rnd) { |
Then comes the entire verification process. Here, we’ve omitted the case where pos is not found in the skip list and only look at the core test path.
1 | while (true) { |
After finding the position current, it verifies if the hash of the key value at current is correct, then verifies if pos <= current. Afterwards, it uses a while loop to traverse the skip list, verifying that all keys in the [pos, current) interval were not in the initial state initial_state. Here, we can use proof by contradiction: if there’s a key tmp in the [pos, current) interval that’s also in initial_state, then according to the properties of skip lists, Seek would have found tmp instead of current. So as long as the linked list is implemented correctly, all keys in the [pos, current) interval should not be in initial_state.
Of course, we haven’t recorded the key values in the skip list here. We only need to verify that the gen values of all keys in the [pos, current) interval are greater than the gen values in the initial state, which can prove that all keys in this range were not in the linked list when iteration began.
After each round of verification above, a new test target key pos is found and the iterator is updated, as shown in the following code:
1 | if (rnd->Next() % 2) { |
Here, it randomly decides whether to move to the next key with iter.Next() or create a new target key and relocate to that target key. The entire read test simulates the uncertainty in a real environment, ensuring the stability and correctness of the skip list under various access patterns.
Single-threaded Read and Write
After introducing the methods for testing read and write, let’s see how to combine them with threads for testing. Single-threaded read and write is relatively simple, just alternating between write and read execution.
1 | // Simple test that does single-threaded testing of the ConcurrentTest |
Parallel Read and Write Testing
In real scenarios, there’s one write thread but can be multiple read threads, and we need to test the correctness of the skip list in parallel read and write scenarios. The core test code is as follows:
1 | static void RunConcurrent(int run) { |
Here, each test case iterates N times. In each iteration, the Env::Default()->Schedule method is used to create a new thread to execute the ConcurrentReader function, passing state as a parameter. ConcurrentReader will perform read operations in an independent thread, simulating a parallel read environment. Then, it calls state.Wait(TestState::RUNNING) to wait for the read thread to enter the running state before the main thread starts write operations.
Here, write operations are performed by calling state.t_.WriteStep(&rnd) in a loop, executing kSize write operations on the skip list. Each write operation will insert a new key-value pair into the skip list, simulating the behavior of the write thread. After completing the write operations, state.quit_flag_ is set to true, notifying the read thread to stop reading operations and exit. It then waits for the read thread to complete all operations and exit, ensuring that all read and write operations in the current loop have ended before proceeding to the next test.
This test uses TestState to synchronize thread states and encapsulates a ConcurrentReader as the read thread method. It also calls the Schedule method encapsulated by Env to execute read operations in an independent thread. This involves condition variables, mutexes, and thread-related content, which we won’t expand on here.
It’s worth noting that this only tests the scenario of one write and one read in parallel, and doesn’t test one write with multiple reads. Multiple read threads could be started in each iteration, with all read threads executing concurrently with the write operation. Alternatively, a fixed pool of read threads could be maintained, with multiple read threads running continuously, operating concurrently with the write thread. However, the current test, through repeated one-write-one-read iterations, can still effectively verify the correctness and stability of the skip list under read-write concurrency.
Below is a screenshot of the test case execution output:
Correctness of Parallel Testing
The above parallel testing is quite detailed, but it’s worth elaborating a bit more. For this kind of parallel code, especially code involving memory barriers, sometimes passing tests might just be because issues weren’t triggered (the probability of problems occurring is very low, and it might also be related to the compiler and CPU model). For example, if I slightly modify the Insert operation here:
1 | for (int i = 0; i < height; i++) { |
Here, both pointers use the NoBarrier_SetNext method to set, then recompile the LevelDB library and test program, run multiple times, and all test cases can pass.
Of course, in this case, long-term testing can be conducted under different hardware configurations and loads, which might reveal issues. However, the drawback is that it’s time-consuming and may not be able to reproduce the issues found.
Detecting Data Races with ThreadSanitizer
In addition, we can use clang’s dynamic analysis tool ThreadSanitizer to detect data races. It’s relatively simple to use, just add the -fsanitize=thread option when compiling. The complete compilation command is as follows:
1 | CC=/usr/bin/clang CXX=/usr/bin/clang++ cmake -DCMAKE_BUILD_TYPE=Debug -DCMAKE_EXPORT_COMPILE_COMMANDS=1 -DCMAKE_CXX_FLAGS="-fsanitize=thread" -DCMAKE_C_FLAGS="-fsanitize=thread" -DCMAKE_EXE_LINKER_FLAGS="-fsanitize=thread" -DCMAKE_INSTALL_PREFIX=$(pwd) .. && cmake --build . --target install |
Recompile and link the code with the above modification, run the test case, and the result is as follows:
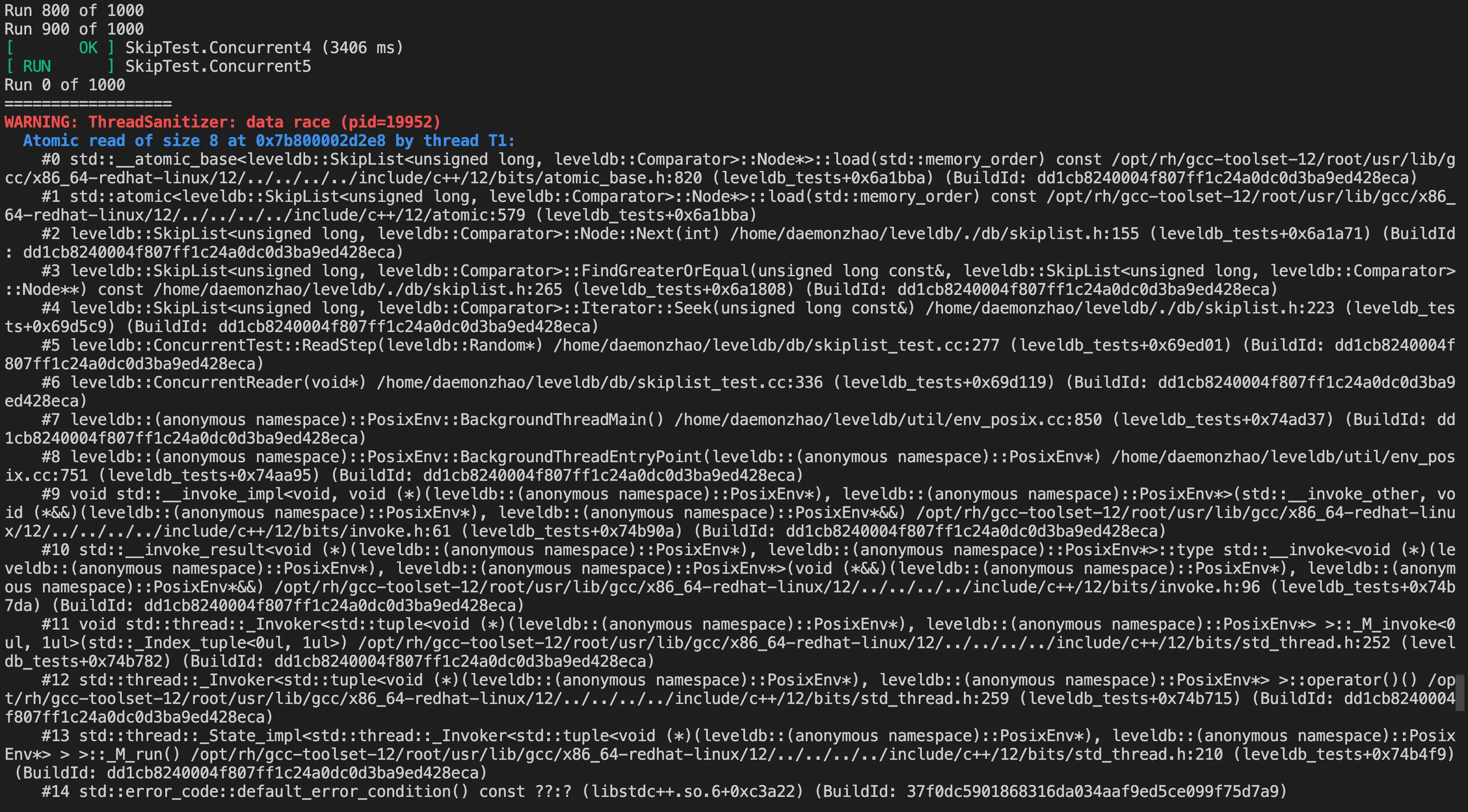
It has precisely located the problematic code. If we undo this erroneous modification and recompile and run, there won’t be any issues. The implementation principle of ThreadSanitizer is quite complex. When the program is compiled, TSan inserts check code before and after each memory access operation. During runtime, when the program executes a memory access operation, the inserted code is triggered. This code checks and updates the corresponding shadow memory. It compares the current access with the historical access records of that memory location. If a potential data race is detected, TSan records detailed information, including stack traces.
Its advantage is that it can detect subtle data races that are difficult to discover through other methods, while providing detailed diagnostic information, which helps to quickly locate and fix problems. However, it significantly increases the program’s runtime and memory usage. It may not be able to detect all types of concurrent errors, especially those that depend on specific timing.
Summary
We have completed the analysis of the skip list testing part, focusing on the correctness verification in parallel read and write scenarios. The design of the inserted key value Key and the verification method of read threads are both very clever, worthy of our reference. At the same time, we should recognize that in multi-threaded scenarios, data race detection is sometimes difficult to discover through test cases alone. Tools like ThreadSanitizer can assist in discovering some issues.
Finally, welcome everyone to leave comments and exchange ideas!

