LevelDB Explained - Implementation and Optimization Details of Key-Value Writing
LevelDB provides a Put interface for writing key-value pairs, which is one of the most important operations in a KV database. The usage is straightforward:
1 | leveldb::Status status = leveldb::DB::Open(options, "./db", &db); |
One of LevelDB’s greatest advantages is its extremely fast write speed, supporting high concurrent random writes. The official write performance benchmark shows:
1 | fillseq : 1.765 micros/op; 62.7 MB/s |
As we can see, without forced disk synchronization, random write speed reaches 45.0 MB/s, supporting about 400,000 writes per second. With forced disk synchronization, although the write speed decreases significantly, it still maintains around 0.4 MB/s, supporting about 3,700 writes per second.
What exactly happens behind the Put interface? How is data written? What optimizations does LevelDB implement? Let’s explore these questions together. Before we begin, let’s look at an overview flowchart:
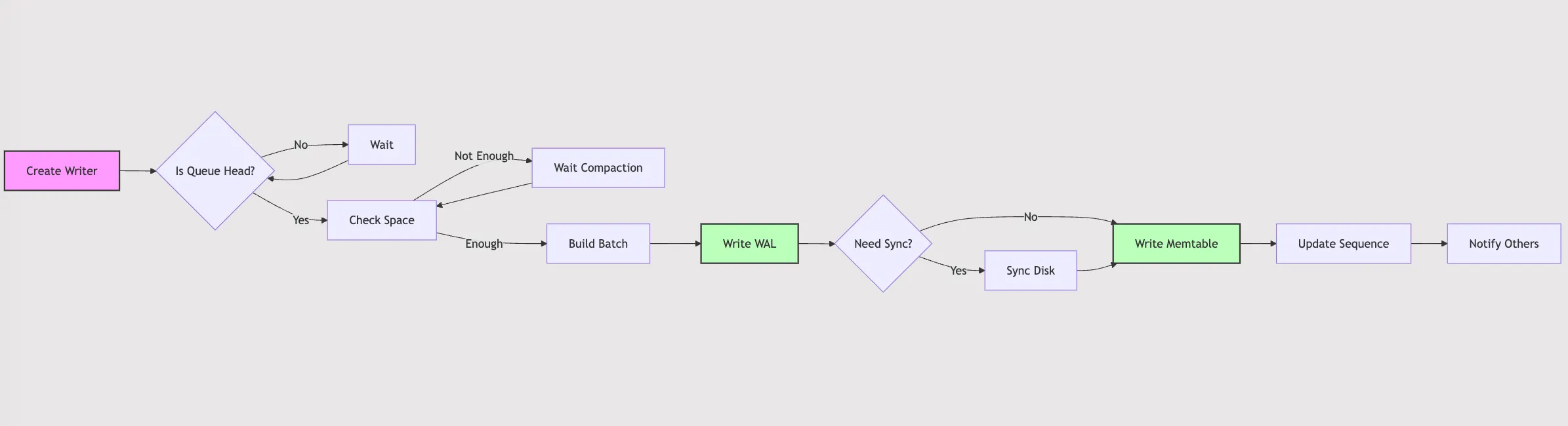
Two Ways to Write Keys in LevelDB
LevelDB supports both single key-value pair writes and batch writes. Internally, both are handled through WriteBatch, regardless of whether it’s a single or batch write.
1 | Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { |
We can choose to aggregate write operations at the application layer when calling LevelDB interfaces to achieve batch writes and improve write throughput. For example, we can design a buffer mechanism at the application layer to collect write requests over a period and then submit them together in a WriteBatch. This approach reduces disk write frequency and context switches, thereby improving performance.
Alternatively, we can write single key-value pairs each time, and LevelDB will handle them internally through WriteBatch. In high-concurrency situations, multiple write operations might be merged internally before being written to WAL and updated to the memtable.
The overall write process is quite complex. In this article, we’ll focus on the process of writing to WAL and memtable.
Detailed Write Steps in LevelDB
The complete write implementation is in the DBImpl::Write method in leveldb/db/db_impl.cc. Let’s break it down step by step.
1 | Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
The initial part assigns the WriteBatch and sync parameters to the Writer structure and manages multiple Writer structures through a writers_ queue. These two structures and the queue play crucial roles in the entire write process, so let’s examine them first.
Writer Structure and Processing Queue
Here, writers_ is a queue of type std::deque<Writer*>, used to manage multiple Writer structures.
1 | std::deque<Writer*> writers_ GUARDED_BY(mutex_); |
The queue is decorated with GUARDED_BY(mutex_), indicating that access to the queue needs to be protected by the mutex_ mutex lock. This uses Clang’s static thread safety analysis feature, which you can learn more about in my previous article LevelDB Explained - Static Thread Safety Analysis with Clang.
The Writer structure is defined as follows:
1 | struct DBImpl::Writer { |
The Writer structure encapsulates several parameters, with the most important being a WriteBatch pointer that records the data for each WriteBatch write request. A status field records any error states for each WriteBatch write request.
Additionally, a sync flag indicates whether each WriteBatch write request needs to be immediately flushed to disk. By default, it’s false, meaning no forced disk flush. In this case, if the system crashes, some data that hasn’t been written to disk might be lost. If the sync option is enabled, each write will be immediately flushed to disk. While this increases overall write latency, it ensures that once a write succeeds, the data won’t be lost. For more details about flushing files to disk, you can refer to my previous article LevelDB Explained - Posix File Operation Details.
The done flag marks whether each WriteBatch write request is completed. Since multiple WriteBatches might be merged internally, when a write request is merged into another batch, it’s marked as complete to avoid duplicate execution. This improves concurrent write efficiency.
To implement waiting and notification, there’s also a condition variable cv, which supports batch processing of multiple write requests and synchronization between them. During writes, multiple threads can submit write requests simultaneously, with each request being placed in the write queue. The actual write process is serialized, with only one batch of writes executing at a time. Each time, the front request from the queue is taken, and if there are other waiting tasks in the queue, they will be merged into one batch for processing. During the processing of the current batch, subsequent requests entering the queue need to wait. When the current batch is completed, waiting write requests in the queue are notified.
With this introduction, you should understand the meaning of the initial code in the Write method. For each write request, a Writer structure is created and placed in the writers_ queue. Then, in the while loop, it checks if the current write request is complete, returning the write status result if it is. If the current write request isn’t at the front of the queue, it needs to wait on the cv condition variable.
If the current write request is at the front of the queue, then the actual write operation needs to be executed. What does this specific write process look like?
Pre-allocating Space
Before the actual write, we need to ensure there’s enough space for the data. This is handled by the MakeRoomForWrite method, which ensures sufficient resources and space are available before processing new write requests. It manages memtable usage, controls Level 0 file count, and triggers background compaction when needed.
1 | // REQUIRES: this thread is currently at the front of the writer queue |
The initial part includes some validation: AssertHeld verifies that the current thread holds the mutex_ lock, and the writers_ queue must not be empty. Then it checks if bg_error_ is empty; if not, it returns the bg_error_ status. As we’ll see later, if writing to WAL fails during disk flush, bg_error_ will be set, causing subsequent writes to fail directly.
In the while loop, there are several if branches handling different situations:
1 | else if (allow_delay && versions_->NumLevelFiles(0) >= |
First, when the number of Level 0 files approaches the kL0_SlowdownWritesTrigger=8 threshold, it temporarily releases the lock and delays for 1 millisecond to slow down the write speed. However, this is only allowed once to avoid blocking a single write for too long. This small Level 0 file count threshold is set to prevent writes from being blocked for too long when the system reaches its bottleneck. Before reaching the bottleneck, it starts distributing the delay across each request to reduce pressure. The comments explain this clearly.
1 | else if (!force && |
Next, if the current memtable’s usage hasn’t exceeded its maximum capacity, it returns directly. Here, write_buffer_size is the maximum capacity of the memtable, defaulting to 4MB. This can be configured - a larger value will cache more data in memory, improving write performance, but will use more memory and take longer to recover when reopening the db.
The next two situations require waiting because there’s no place to write:
1 | else if (imm_ != nullptr) { |
The first case is when the immutable memtable is still being written, so we need to wait for it to complete. LevelDB maintains two memtables: one current writable memtable (mem_) and one immutable memtable (imm_). When mem_ is full, it becomes imm_ and flushes data to disk. If imm_ hasn’t finished flushing to disk, we must wait before converting the current mem_ to a new imm_.
The second case is when there are too many Level 0 files, requiring waiting for compaction to complete. LevelDB configures a threshold kL0_StopWritesTrigger for Level 0 file count, defaulting to 12. When exceeded, current write requests must wait. This is because Level 0 files don’t have global sorting guarantees, and multiple Level 0 files might contain overlapping key ranges. For reads, queries need to search all L0 files, and too many files increase read latency. For writes, more files mean more background compaction work, affecting overall system performance. Therefore, Level 0 file count is strictly controlled, blocking writes when the threshold is reached.
When both imm_ is empty and mem_ doesn’t have enough space, there are several tasks to be done:
- Create new log file: Generate a new log file number and try to create a new writable file as WAL (Write-Ahead Log). If it fails, reuse the file number and exit the loop, returning an error status.
- Close old log file: Close the current log file. If closing fails, record the background error to prevent subsequent write operations.
- Update log file pointer: Set the new log file pointer, update the log number, and create a new log::Writer for writing.
- Convert memtable: Convert the current memtable to an immutable memtable (imm_), and create a new memtable for writing. Mark the existence of an immutable memtable through has_imm_.store(true, std::memory_order_release).
- Trigger background compaction: Call MaybeScheduleCompaction() to trigger background compaction tasks to process the immutable memtable.
Here we can see that memtables and WAL files have a one-to-one correspondence, with each memtable corresponding to a WAL file. The WAL file records all operations written to the memtable, and when the memtable is full, the WAL file is switched simultaneously. At the same time, the foreground memtable and new WAL log file handle new requests, while the background imm_ and old WAL file handle compaction tasks. Once compaction is complete, the old WAL file can be deleted.
Merging Write Tasks
Next is the logic for merging writes. Here’s the core code:
1 | uint64_t last_sequence = versions_->LastSequence(); |
First, it gets the current global sequence value. Here, sequence is used to record the version number of written key-value pairs, which increases monotonically globally. Each write request is assigned a unique sequence value, implementing features like MVCC through the version number mechanism. When writing the current batch of key-value pairs, it first sets the sequence value, and after successful writing, it updates the last_sequence value.
To improve write concurrency performance, each write not only needs to write the front task but also attempts to merge subsequent write tasks in the queue. The merging logic is placed in BuildBatchGroup, which mainly traverses the entire write queue, continuously merging subsequent write tasks into the front write task while controlling the overall batch size and ensuring the disk flush level. The overall constructed write batch is placed in a temporary object tmp_batch_, which is cleared after the complete write operation is finished.
We mentioned that each write task is actually encapsulated as a WriteBatch object, whose implementation supports merging different write tasks and getting task sizes. For detailed implementation, you can refer to my previous article LevelDB Explained - Elegant Merging of Write and Delete Operations.
The code above actually omitted the core logic of writing to WAL and memtable, let’s look at this part’s implementation.
Writing to WAL and MemTable
In LevelDB, when writing key-value pairs, it first writes to the WAL log, then writes to the memtable. The WAL log is key to implementing data recovery in LevelDB, while the memtable is key to implementing memory caching and fast queries. Here’s the critical write code:
1 | // Add to log and apply to memtable. We can release the lock |
Here, when writing to WAL and memtable, the mutex_ lock is first released, and then reacquired after completion. The comments specifically explain that while the current front &w is responsible for writing to WAL and memtable, subsequent write calls can acquire the mutex_ lock to complete queue entry operations. However, since they’re not at the front, they need to wait on the condition variable, and only when the current task completes do they have a chance to execute. Therefore, although the lock is released during the process of writing to WAL and memtable, the overall write is still serialized. WAL and memtable themselves don’t need to ensure thread safety.
However, since writing to WAL and memtable is relatively time-consuming, after releasing the lock, other operations that need mutex_ can acquire it and continue executing, improving overall system concurrency.
WAL (Write-Ahead Logging) is a logging mechanism that allows recording logs before data is written to disk. WAL logs are written sequentially, and disk sequential IO performance is better than random IO performance, so sequential writes are generally more efficient. After successfully writing to WAL, data is placed in the memtable, which is a memory structure with high write efficiency. When enough data accumulates in memory, it’s written to disk. If the system crashes and restarts, data in the memtable may be lost, but through WAL logs, write operations can be replayed to restore the data state, ensuring data integrity.
The specific write here simply calls the AddRecord method of the log::Writer object log_ to write WriteBatch data. log::Writer will organize this data and write it to disk at appropriate times. For detailed implementation, you can refer to my previous article LevelDB Explained - How To Read and Write WAL Logs.
Of course, if the write comes with sync=true, after successfully writing to WAL, the logfile_->Sync() method will be called to force disk flush. To clarify, writing content to files is done through the system call write, but success of this system call doesn’t guarantee the data has been written to disk. File systems generally put data in a buffer first, then choose appropriate times to flush to disk based on circumstances. To ensure data is written to disk, additional system calls are needed, with different platforms having different interfaces. For details, refer to my previous article LevelDB Explained - Posix File Operation Details.
If an error occurs during forced disk flush, the RecordBackgroundError method is called to record the error status in bg_error_, causing all subsequent write operations to fail directly.
After successfully writing to WAL, we can write to the memtable. Here, the WriteBatchInternal::InsertInto method is called to insert WriteBatch data into the memtable. I’ll cover the implementation of memtable in detail in a future article.
Updating Batch Write Task Status
After completing the batch write, we need to update the status of batch write tasks, taking the Writer object from the front of the writers_ queue, then iterating until the last write task in the batch. Here we update the status of all completed tasks and wake up all waiting write tasks. The core implementation is as follows:
1 | while (true) { |
Finally, if there are still write tasks in the queue, we need to wake up the front write task to continue processing. At this point, the entire write process is complete, and we can return the write result to the caller.
Other Engineering Implementation Details
While we’ve analyzed the complete write process, there are some engineering implementation details worth examining.
Handling Mixed Sync and Non-sync Writes
How does LevelDB internally handle a batch of write requests that includes both sync and non-sync writes?
From our previous analysis, we can see that after taking the front write task from the queue, it attempts to merge subsequent write tasks in the queue. Since each write task can either force sync disk flush or not, how are write tasks with different sync configurations handled during merging?
Here, when sync=true is configured, writes will force disk flush. For merged batch writes, the sync setting of the front task is used. The core code is as follows:
1 | Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
Therefore, if the front task doesn’t require disk flush, then during merging, it cannot merge write tasks with sync=true. The core implementation code is as follows:
1 | for (; iter != writers_.end(); ++iter) { |
However, if the front task has sync=true, then during merging, we don’t need to consider the sync settings of the write tasks being merged. This is because the entire merged batch will be forced to flush to disk. This design ensures that the write durability guarantee level isn’t reduced while potentially improving it. Of course, improving the write durability guarantee level here doesn’t actually increase overall latency, because the front task must flush to disk anyway, and including additional write tasks that don’t require disk flush won’t increase the latency.
Optimizing Large Batch Small Key Write Latency
As we can see from the above implementation, during large-scale concurrent writes, write requests are first placed in a queue and then written serially. If the keys being written are relatively small, then after taking a write task from the front of the queue, it’s merged with other writes in the current queue into a batch. When merging, a max_size needs to be set to limit the number of merged keys. What’s a reasonable value for this max_size?
LevelDB provides an empirical value, defaulting to 1 << 20 bytes. However, consider a scenario where all keys being written are relatively small - during merging, many keys might be merged, leading to longer write latency. Since these are small key writes, long write latency doesn’t provide a good user experience.
Therefore, a small optimization was added: if the overall size of the current front write task is less than 128 << 10 bytes, then max_size will be much smaller. Of course, this value seems to be empirical as well; I haven’t found official documentation explaining it. The relevant code is in BuildBatchGroup:
1 | // Allow the group to grow up to a maximum size, but if the |
WAL Success but MemTable Failure
During the write process, WAL is written first, and only after successful WAL writing is the memtable written. These two writes aren’t atomic. If WAL writing fails, we don’t write to the memtable and block all subsequent writes, which is reasonable and won’t cause issues.
However, if WAL writing succeeds but writing to the memtable fails, the status returned to the caller indicates write failure, and the caller might consider the write failed. But since WAL was successfully written and other processes executed normally, including updating the global sequence, if a failure occurs at this point, during recovery from WAL, the failed memtable writes will also be recovered, resulting in data that the caller thought failed actually being successfully written.
I haven’t fully understood this issue yet - it might be a potential bug in LevelDB, or I might not have fully grasped the overall code. I tried analyzing this with GPT O1 and Deepseek’s R1 deep thinking, and both lean towards this being a bug. Deepseek’s thought process was quite interesting:
I need to confirm how likely this situation is in actual LevelDB operation. What typically causes MemTable write failures? Memory shortage or other unrecoverable errors? For temporary errors, does LevelDB have a retry mechanism?
Also, checking LevelDB’s official documentation or related discussions, is there any mention of how to handle this situation? For example, does LevelDB actively delete or invalidate corresponding WAL records when MemTable writes fail?
We might also need to consider the database recovery process. When LevelDB restarts, it reads WAL and rebuilds MemTable. If a WAL record corresponds to a failed MemTable write but WAL exists, recovery will attempt to write to MemTable again. If conditions allow (e.g., sufficient memory), the write might succeed, causing inconsistency. However, if the original failure was persistent (like data structure error), recovery might fail again, preventing the database from opening and thus avoiding inconsistency.
Additionally, does the user’s question assume certain specific scenarios? For example, MemTable write fails but the database doesn’t crash, then closes normally, and WAL isn’t cleared, so it’s reapplied during recovery. Is this scenario possible?
AI’s deep thinking and logical reasoning capabilities are quite strong now, considering issues quite comprehensively. Readers are welcome to discuss this issue in the comments.
Summary
The article is quite long, so let’s summarize. LevelDB’s write operation design fully considers high concurrency and performance optimization, implementing efficient key-value pair writing through a series of ingenious mechanisms. Here are some design aspects worth learning from:
Batch Write Merging: LevelDB merges multiple write requests through a Writer queue, avoiding frequent disk IO. Each write request is placed in the queue, with the queue head responsible for merging subsequent requests into a large WriteBatch. This design significantly improves throughput, especially suitable for high-concurrency small key-value pair write scenarios.
WAL Log Crash Recovery: Write-Ahead Logging (WAL): All write operations are first sequentially written to WAL logs, ensuring data durability. Only after writing to WAL is the MemTable in memory updated. This “log first, memory second” design is the cornerstone of LevelDB’s crash recovery.
Memory Double Buffering: When MemTable is full, it converts to Immutable MemTable and triggers background compaction while creating a new MemTable and WAL file. This double buffering mechanism avoids write blocking and achieves smooth memory-to-disk data transfer.
Write Throttling and Adaptive Delay: Through kL0_SlowdownWritesTrigger and kL0_StopWritesTrigger thresholds, actively introducing write delays or pausing writes when there are too many Level 0 files. This “soft throttling” strategy prevents system avalanche effects after overload.
Dynamic Batch Merging: Dynamically adjusting maximum batch size based on current queue head request size (e.g., 128KB for small requests, 1MB for large requests), balancing throughput and latency.
Condition Variable Wake-up: Implementing efficient thread wait-notify through CondVar, ensuring merged writes don’t block subsequent requests for too long.
Mixed Sync Handling: Supporting simultaneous handling of requests requiring forced disk flush (sync=true) and non-forced flush, prioritizing the persistence level of the queue head request without compromising data safety.
Error Isolation: WAL write failures mark global error state bg_error_, directly rejecting all subsequent write requests to prevent data inconsistency.
Finally, welcome to discuss in the comments and learn LevelDB’s implementation details together.

