LevelDB Explained - The Implementation Details of MemTable
In LevelDB, all write operations are first recorded in a Write-Ahead Log (WAL) to ensure durability. The data is then stored in a MemTable. The primary role of the MemTable is to store recently written data in an ordered fashion in memory. Once certain conditions are met, the data is flushed to disk in batches.
LevelDB maintains two types of MemTables in memory. One is writable and accepts new write requests. When it reaches a certain size threshold, it is converted into an immutable MemTable. A background process is then triggered to write it to disk, forming an SSTable. During this process, a new MemTable is created to accept new write operations, ensuring that write operations can continue without interruption.
When reading data, LevelDB first queries the MemTable. If the data is not found, it then queries the immutable MemTable, and finally the SSTable files on disk. In LevelDB’s implementation, both the writable MemTable and the immutable MemTable are implemented using the MemTable class. In this article, we will examine the implementation details of the memtable.
How to Use MemTable
First, let’s see where the MemTable class is used in LevelDB. In the core DB implementation class DBImpl, we can see two member pointers:
1 | class DBImpl : public DB { |
mem_ is the writable memtable, and imm_ is the immutable memtable. These are the only two memtable objects in the database instance, used to store recently written data. Both are used when reading and writing key-values.
Let’s first look at the write process. I previously wrote about the entire process of writing key-values in LevelDB Explained - Implementation and Optimization Details of Key-Value Writing. During the write process, after the WAL is successfully written, the MemTableInserter class in db/write_batch.cc is called to write to the memtable. The specific code is as follows:
1 | // db/write_batch.cc |
Here, the Add interface is called to write a key-value pair to the memtable. sequence_ is the write sequence number, kTypeValue is the write type, and key and value are the user-provided key-value pair.
Besides the write process, the MemTable class is also needed when reading key-value pairs. Specifically, in the Get method of the DBImpl class in db/db_impl.cc, the memtable’s Get method is called to query for a key-value pair.
1 | Status DBImpl::Get(const ReadOptions& options, const Slice& key, |
Here, local pointers mem and imm are created to reference the member variables mem_ and imm_, and these local pointers are then used for reading. A question arises here: Why not use the member variables mem_ and imm_ directly for reading? We’ll answer this question later in the Answering Questions section.
So far, we have seen the main usage of MemTable. Now let’s look at how it’s implemented internally.
MemTable Implementation
Before discussing the implementation of MemTable’s external methods, it’s important to know that the data in a MemTable is actually stored in a skiplist. A skiplist provides most of the advantages of a balanced tree (such as ordering and logarithmic time complexity for insertion and search), but is simpler to implement. For a detailed implementation of the skiplist, you can refer to LevelDB Explained - How to implement SkipList.
The MemTable class declares a skiplist object table_ as a member variable. The skiplist is a template class that requires a key type and a Comparator for initialization. Here, the key in the memtable’s skiplist is of type const char*, and the comparator is of type KeyComparator. KeyComparator is a custom comparator used to sort the key-values in the skiplist.
KeyComparator contains a member variable comparator of type InternalKeyComparator, which is used to compare the sizes of internal keys. The operator() of the KeyComparator comparator overloads the function call operator. It first decodes the internal key from the const char*, and then calls the Compare method of InternalKeyComparator to compare the sizes of the internal keys. The specific implementation is in db/memtable.cc.
1 | int MemTable::KeyComparator::operator()(const char* aptr, |
To add, LevelDB’s internal key is actually a concatenation of the user-provided key and an internal sequence number, plus a type identifier. This ensures that different versions of the same key are ordered, thus enabling MVCC for concurrent reads and writes. When storing to the MemTable, length information is encoded before the internal key, called a memtable key. This allows us to decode the internal key from the const char* memtable key using the length information during reads. I have analyzed this part in detail in another article: LevelDB Explained - Understanding Multi-Version Concurrency Control (MVCC). Feel free to check it out.
MemTable uses a skiplist for storage and primarily supports Add and Get methods externally. Let’s look at the implementation details of these two functions.
Add a Key-Value Pair
The Add method is used to add a key-value pair to the MemTable, where key and value are the user-provided key-value pair, SequenceNumber is the sequence number at the time of writing, and ValueType is the write type. There are two types: kTypeValue and kTypeDeletion. kTypeValue represents an insertion operation, and kTypeDeletion represents a deletion operation. In LevelDB, a deletion operation is actually an insertion of a key-value pair marked for deletion.
The implementation of Add is in db/memtable.cc, and the function definition is as follows:
1 | void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, |
The comments here are very clear. The MemTable stores a formatted key-value pair, starting with the length of the internal key, followed by the internal key byte string (which is the tag part below, including User Key + Sequence Number + Value Type), then the length of the value, and finally the value byte string. The whole thing consists of 5 parts, with the following format:
1 | +-----------+-----------+----------------------+----------+--------+ |
Here, the first part, keysize, is the Varint-encoded length of the user key plus an 8-byte tag. The tag is a combination of the sequence number and the value type, with the high 56 bits storing the sequence number and the low 8 bits storing the value type. The other parts are simpler and will not be detailed here.
The insertion process first calculates the required memory size, allocates the memory, then writes the values of each part, and finally inserts it into the skiplist. The specific write process code is as follows:
1 | // db/memtable.cc |
EncodeVarint32 and EncodeFixed64 here are encoding functions used to encode integers into a byte stream. For details, you can refer to LevelDB Explained - Arena, Random, CRC32, and More.. Next, let’s look at the implementation of key querying.
Get a Key-Value
The definition of the query method is also quite simple, as follows:
1 | // If memtable contains a value for key, store it in *value and return true. |
The key passed to this interface is not the user input key, but a LookupKey object, defined in db/dbformat.h. This is because in LevelDB, the same user key can have different versions. When querying, a snapshot (i.e., sequence number) must be specified to get the corresponding version. Therefore, a LookupKey class is abstracted here, which can be initialized with the user-input key and sequence number to get the required key-value format.
For the lookup process, we first get the previously mentioned memtable key using the memtable_key method of the LookupKey object, and then call the skiplist’s Seek method to perform the search. The complete implementation of the Get method in db/memtable.cc is as follows:
1 | bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) { |
We know that the skiplist’s Seek method positions the iterator at the first position in the list that is greater than or equal to the target internal key. Therefore, we need to additionally verify that the key of this entry is consistent with the user’s query key. This is because there may be multiple keys with the same prefix, and Seek may return a different key that has the same prefix as the query key. For example, querying for “app” might return a record for “apple”.
The comments also specifically mention that we do not check the sequence number in the internal key. Why is that? As mentioned earlier, the keys in the skiplist are sorted based on the internal key comparator (InternalKeyComparator), which considers both the key value and the sequence number. First, it uses the user-defined comparison function (defaulting to lexicographical order) to compare the user keys, with smaller key values coming first. If the user keys are the same, it then compares the sequence numbers, with records having larger sequence numbers appearing earlier in the skiplist. This is because we usually want newer changes (i.e., records with larger sequence numbers) for the same user key to be accessed first.
For example, if there are two internal keys, Key1 = “user_key1”, Seq = 1002 and Key2 = “user_key1”, Seq = 1001. In the skiplist, the first record (Seq = 1002) will be placed before the second record (Seq = 1001), because 1002 > 1001. When Seek is used to find <Key = user_key1, Seq = 1001>, it will naturally skip the record with Seq = 1002.
So, after getting the internal key, there is no need to check the sequence number again. We only need to confirm that the user keys are equal, then get the 64-bit tag and extract the low 8-bit operation type using 0xff. For a delete operation, it will return a “not found” status, indicating that the key-value has been deleted. For a value operation, it will then decode the value byte string from the end of the memtable key and assign it to the value pointer.
Friend Class Declaration
In addition to the Add and Get methods, the MemTable class also declares a friend class friend class MemTableBackwardIterator;. As the name suggests, it is a reverse iterator. However, this class definition is not found anywhere in the entire code repository. It’s possible that this was a feature reserved during development that was never implemented, and the invalid code was forgotten to be removed. The compiler doesn’t report an error here because the C++ compiler does not require a friend class to be defined when processing a friend declaration. The compiler only checks the syntax correctness of the declaration. The lack of a definition only becomes an issue when the class is actually used (e.g., creating an instance or accessing its members).
There is also another friend, friend class MemTableIterator;, which implements the Iterator interface for traversing the key-value pairs in the memTable. The methods of MemTableIterator, such as key() and value(), rely on operations on the internal iterator iter_, which works directly on the memTable’s SkipList. These are all private members of memTable, so it needs to be declared as a friend class.
In db_impl.cc, when the immemtable needs to be flushed to an SST file at Level0, MemTableIterator is used to traverse the key-value pairs in the memTable. The usage part of the code is as follows, where BuildTable traverses the memTable and writes the key-value pairs to the SST file.
1 | // db/db_impl.cc |
When traversing the memtable, a friend class is used. Why not just provide some public interfaces for traversal? One advantage of using a friend class is that the responsibilities of the classes are clearly divided. MemTableIterator is responsible for traversing the data in the memTable, while memTable is responsible for managing the storage of the data. This separation helps to clearly define the responsibilities of the classes, following the single responsibility principle, where each class handles only a specific set of tasks, making the system design more modular.
Memory Management
Finally, let’s look at the memory management of MemTable. The MemTable class has a member variable arena_ of type Arena, which is used to manage the memory allocation for the skiplist. When a key-value pair is inserted, the encoded information is stored in the memory allocated by arena_. For information on the Arena class for memory management, you can refer to LevelDB Explained - Arena, Random, CRC32, and More..
To release memory promptly when the MemTable is no longer in use, a reference counting mechanism is introduced to manage memory. Reference counting allows shared access to the MemTable without worrying about resource release issues. It also provides Ref and Unref methods to increase and decrease the reference count:
1 | // Increase reference count. |
When the reference count drops to zero, the MemTable automatically deletes itself, at which point the destructor ~MemTable() is called to release the memory. When an object is destructed, for custom member variables, their respective destructors are called to release resources. In MemTable, a skiplist is used to store keys, and the memory for the skiplist is managed by Arena arena_. During the destruction of MemTable, the destructor of arena_ is called to release the previously allocated memory.
1 | Arena::~Arena() { |
It is worth noting here that MemTable sets its destructor ~MemTable(); to private, forcing external code to manage the lifecycle of MemTable through the Unref() method. This ensures that the reference counting logic is executed correctly, preventing memory errors caused by improper deletion operations.
Answering Questions
Now, there is one last question, the one we left earlier. In the LevelDB Get method, why are two local pointers created to reference the member variables mem_ and imm_ instead of using them directly?
What would be the problem if mem_ and imm_ were used directly? First, consider the case without locking. If a read thread is reading mem_, and another write thread happens to fill mem_, triggering the logic to switch mem_ to imm_, a new empty mem_ will be created. At this point, the memory address the read thread is reading from becomes invalid. Of course, you could add a lock to protect both reads and writes to mem_ and imm_, but this would result in poor concurrency performance, as only one read or write operation would be allowed at a time.
To support concurrency, LevelDB’s approach here is more complex. When reading, it first acquires a thread lock, copies mem_ and imm_, and increases their reference counts using Ref(). After that, the thread lock can be released, and the find operation can be performed on the copied mem and imm. This find operation does not require a thread lock, allowing multiple read threads to operate concurrently. After the read is complete, Unref() is called to decrease the reference count. If the reference count becomes zero, the object is destroyed.
Consider multiple read threads reading mem_ while one write thread is writing to mem_. Each read thread will first get its own reference to mem_, then release the lock and start the find operation. The write thread can continue to write content to it, or create a new mem_ after it is full. As long as any read thread is still searching, the reference count of the original mem_ will not be zero, and the memory address will remain valid. Only after all read threads have finished, and the write thread has filled mem_, converted it to imm_, and written it to an SST file, will the reference count of the original mem_ become zero. At this point, the destruction operation is triggered, and the address can be reclaimed.
The text might be a bit confusing, so I had an AI generate a mermaid flowchart to help understand:
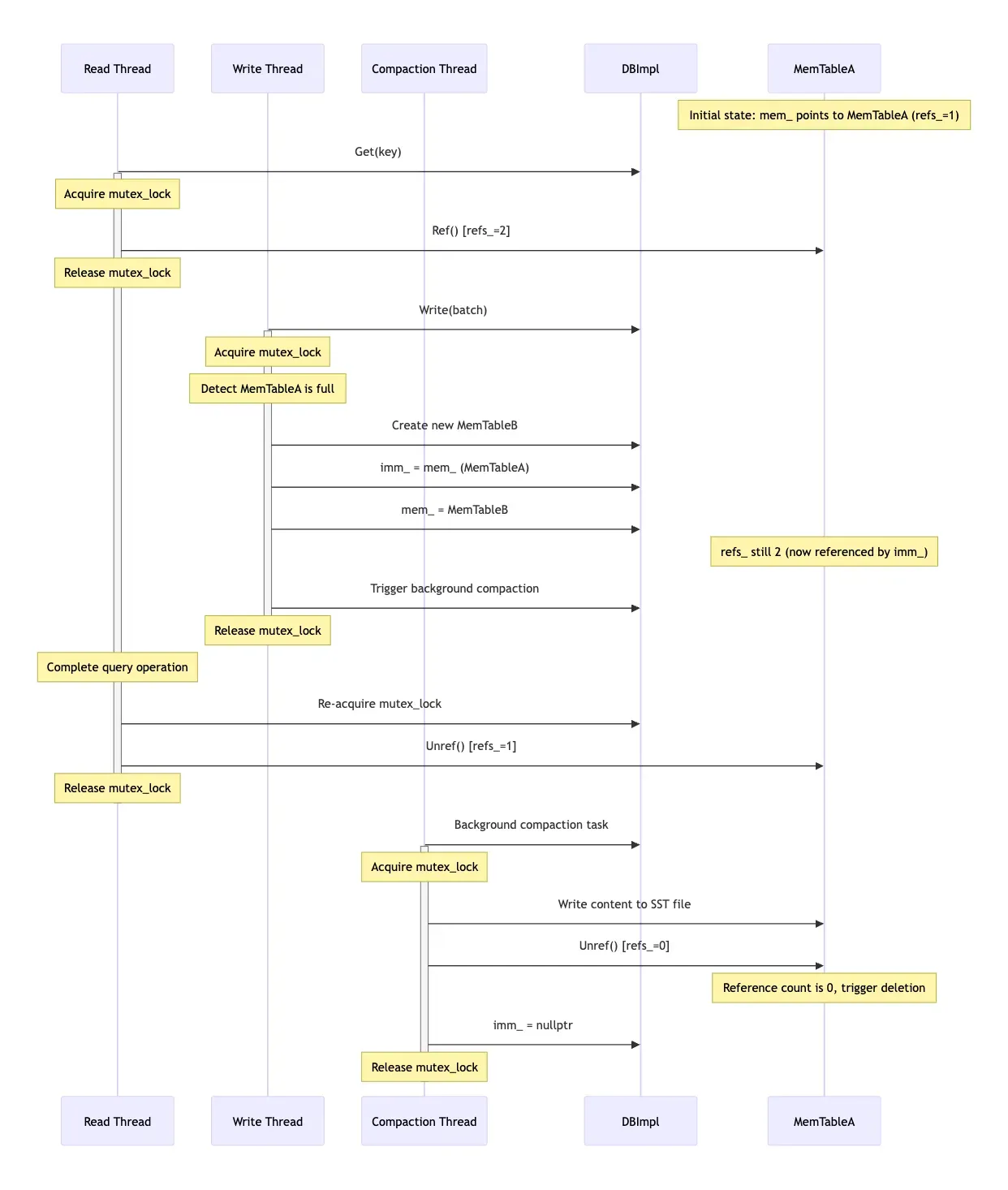
The mermaid source code can be found here.
Summary
In the entire LevelDB architecture, MemTable plays a pivotal role, connecting the upper and lower layers. It receives write requests from the upper layer, accumulates them in memory to a certain amount, then transforms into an immutable Immutable MemTable, which is eventually written to disk as an SST file by a background thread. At the same time, it is the highest priority component in the read path, ensuring that the most recently written data can be read immediately.
In this article, we have analyzed the implementation principles and working mechanism of MemTable in LevelDB in detail. Finally, let’s briefly summarize the core design of MemTable:
- Skiplist-based implementation: MemTable uses a skiplist internally to store data. This data structure provides most of the advantages of a balanced tree, while being simpler to implement and efficiently supporting find and insert operations.
- Memory management mechanism: MemTable uses the Arena memory allocator to manage memory, allocating and deallocating uniformly to avoid memory fragmentation and improve memory utilization.
- Reference counting mechanism: The
Ref()andUnref()methods implement reference counting to support concurrent access while ensuring that resources are released promptly when no longer in use. - Specific key-value encoding format: The key-value pairs stored in MemTable use a specific encoding format, including key length, user key, sequence number and type identifier, value length, and the value itself, which supports LevelDB’s multi-version concurrency control (MVCC).
- Friend class collaboration: The friend class
MemTableIteratoris used to traverse the data in MemTable, implementing the principle of separation of concerns.
Through meticulous memory management and a reference counting mechanism, MemTable solves the problem of concurrent access. With its skiplist data structure, it achieves efficient queries and insertions. Through a specific key-value encoding format, it supports multi-version concurrency control. These design choices together form the foundation of LevelDB’s high performance and reliability.

