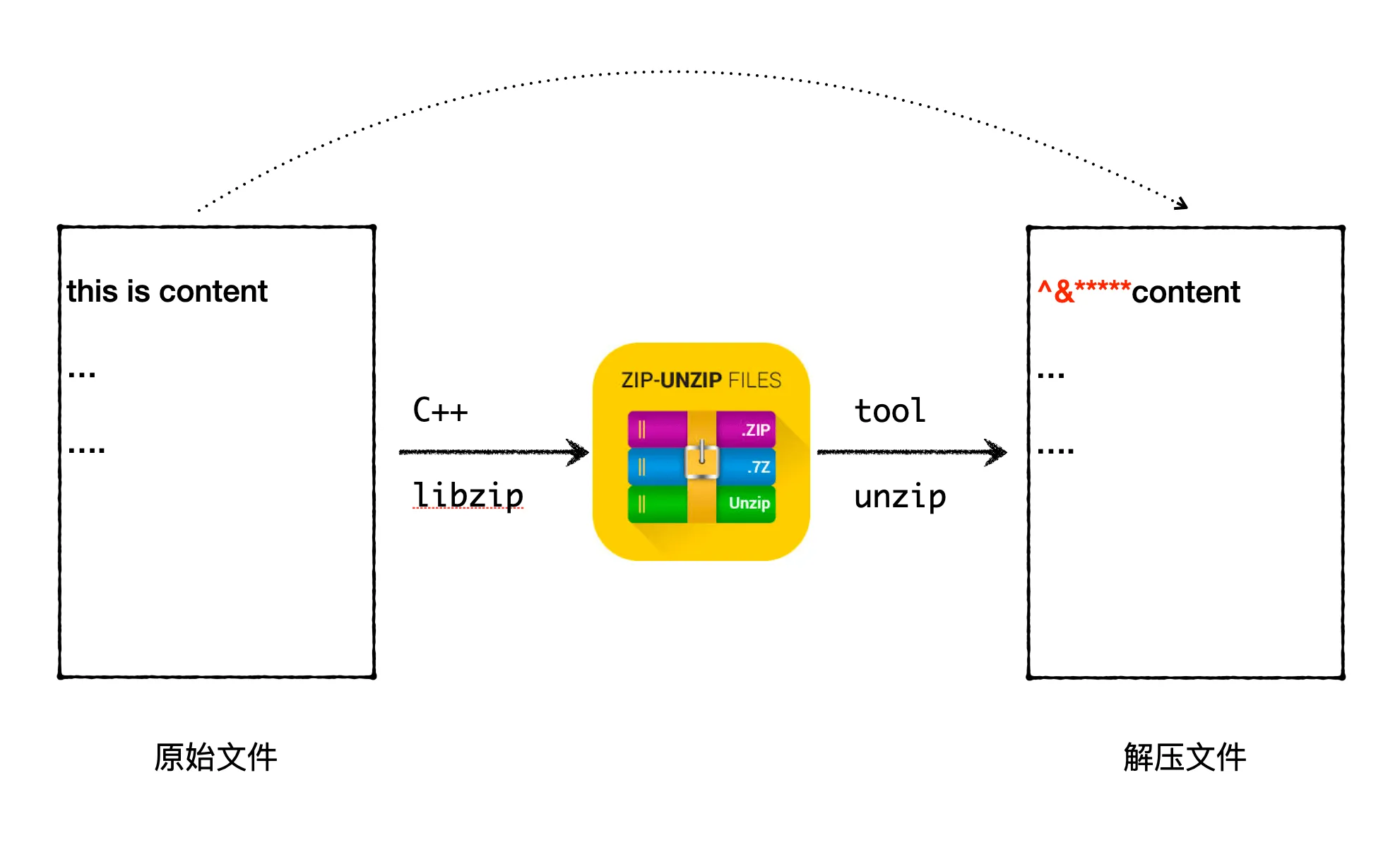
C++ Zip Archive Creation - Debugging Memory Corruption Issue
In daily C++ backend development work, dynamically generating Zip packages is rare, so I’m not familiar with C++’s libzip. Recently, I encountered a scenario where I needed to compress some backend-generated data into a Zip package for download. There was already existing code for generating Zip packages, but I needed to add a file to the Zip package. It seemed like a simple requirement, but during implementation, I encountered a strange problem: after unzipping the generated Zip package, the beginning of the files inside was corrupted.