LevelDB Explained - Implementation and Optimization Details of Key-Value Writing
LevelDB provides a Put interface for writing key-value pairs, which is one of the most important operations in a KV database. The usage is straightforward:
1 | leveldb::Status status = leveldb::DB::Open(options, "./db", &db); |
One of LevelDB’s greatest advantages is its extremely fast write speed, supporting high concurrent random writes. The official write performance benchmark shows:
1 | fillseq : 1.765 micros/op; 62.7 MB/s |
As we can see, without forced disk synchronization, random write speed reaches 45.0 MB/s, supporting about 400,000 writes per second. With forced disk synchronization, although the write speed decreases significantly, it still maintains around 0.4 MB/s, supporting about 3,700 writes per second.
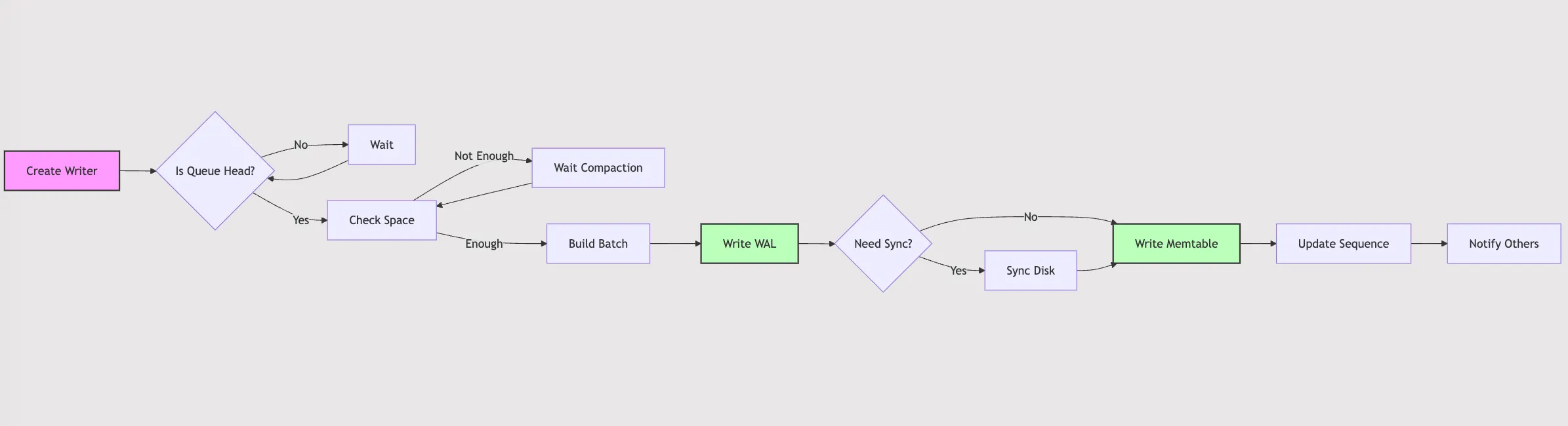
What exactly happens behind the Put interface? How is data written? What optimizations does LevelDB implement? Let’s explore these questions together. Before we begin, let’s look at an overview flowchart: