被忽视的 partition 算法
如果你学习过算法,那么肯定听说过快速排序的大名,但是对于快速排序中用到的 partition 算法,你了解的够多吗?或许是快速排序太过于光芒四射,使得我们往往会忽视掉同样重要的 partition 算法。
Partition 可不只用在快速排序中,还可以用于 Selection algorithm(在无序数组中寻找第K大的值)中。甚至有可能正是这种通过一趟扫描来进行分类的思想激发 Edsger Dijkstra 想出了 Three-way Partitioning,高效地解决了 Dutch national flag problem 问题。接下来我们一起来探索 partition 算法。
Partition 实现
快速排序中用到的 partition 算法思想很简单,首先从无序数组中选出枢轴点 pivot,然后通过一趟扫描,以 pivot 为分界线将数组中其他元素分为两部分,使得左边部分的数小于等于枢轴,右边部分的数大于等于枢轴(左部分或者右部分都可能为空),最后返回枢轴在新的数组中的位置。
Partition 的一个直观简单实现如下(这里取数组的第一个元素为pivot):
1 | // Do partition in arr[begin, end), with the first element as the pivot. |
如果原始数组为[5,9,2,1,4,7,5,8,3,6],那么整个处理的过程如下图所示:
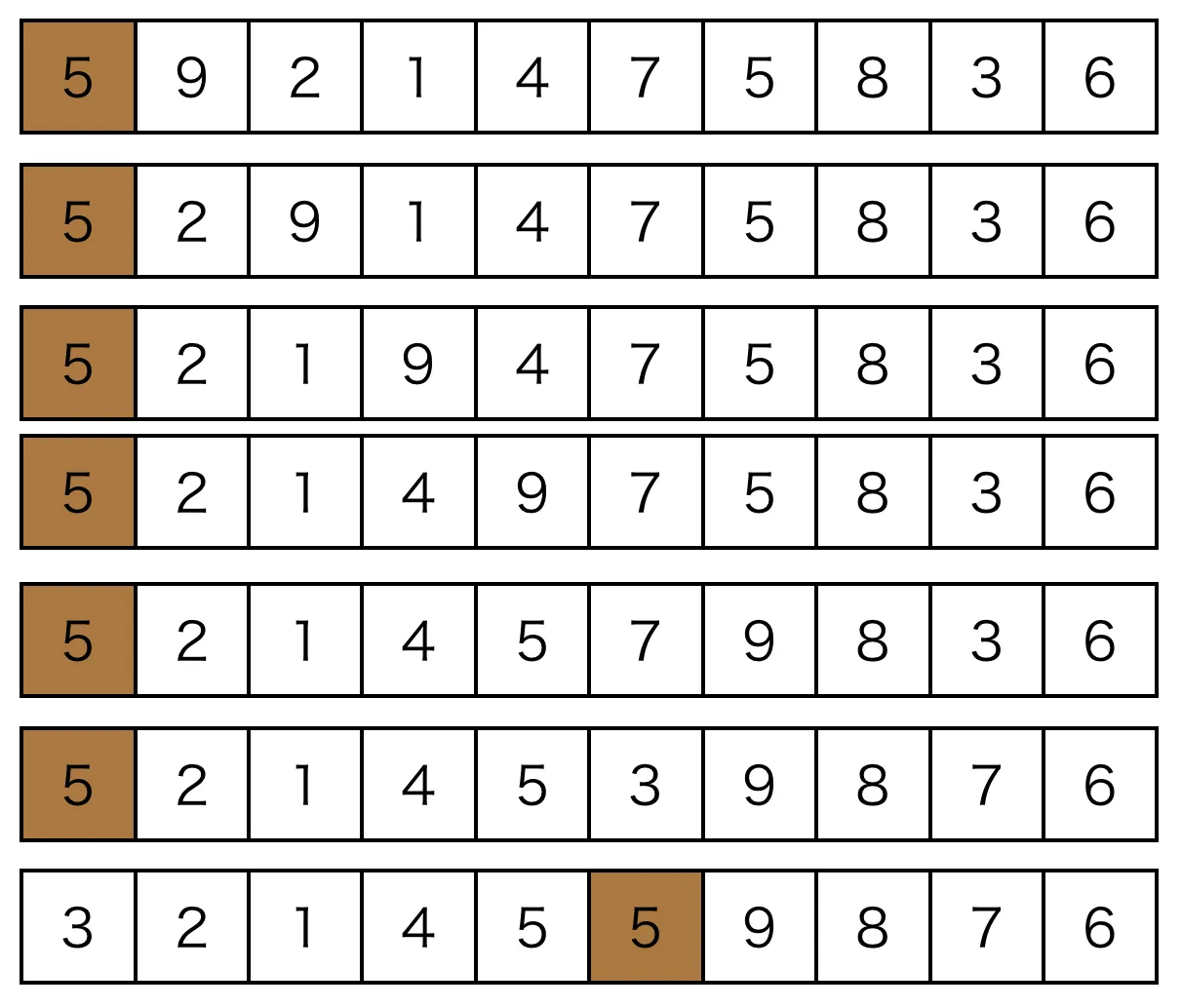
这种实现思路比较直观,但是其实并不高效。从直观上来分析一下,每个小于pivot的值基本上(除非到现在为止还没有遇见大于pivot的值)都需要一次交换,大于pivot的值(例如上图中的数字9)有可能需要被交换多次才能到达最终的位置。
如果我们考虑用 Two Pointers 的思想,保持头尾两个指针向中间扫描,每次在头部找到大于pivot的值,同时在尾部找到小于pivot的值,然后将它们做一个交换,就可以一次把这两个数字放到最终的位置。一种比较明智的写法如下:
1 | int partition(vector<int>&arr, int begin, int end) |
如果是第一次看到上面的代码,那么停下来,好好品味一下。这里没有用到 swap 函数,但其实也相当于做了 swap 操作。以前面的数组为例,看看以这种方法来做的话,整个处理的流程。
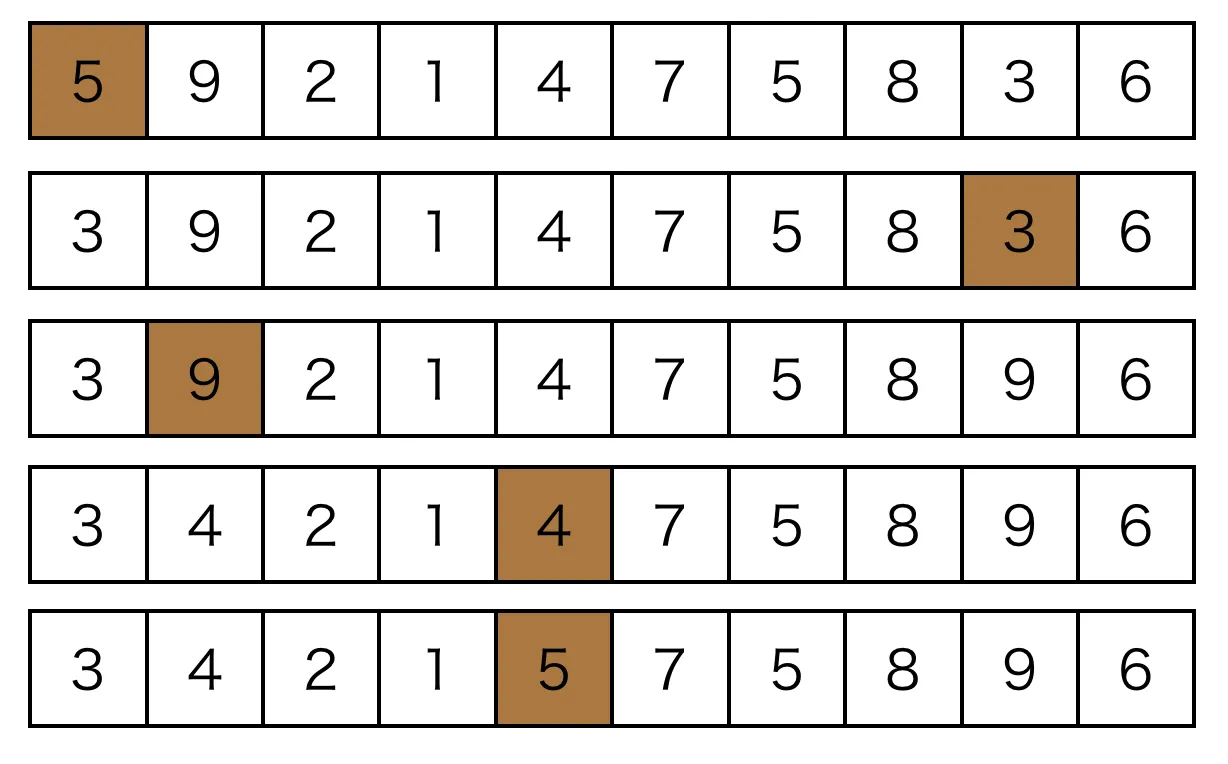
直观上来看,赋值操作的次数不多,比前面单向扫描的swap次数都少,效率应该会更高。这里从理论上对这两种方法进行了分析,有兴趣可以看看。
Partition 应用
我们都知道经典的快速排序就是首先用 partition 将数组分为两部分,然后分别对左右两部分递归进行快速排序,过程如下:
1 | void quick_sort(vector<int> &arr, int begin, int end){ |
虽然快排用到了经典的分而治之的思想,但是快排实现的前提还是在于 partition 函数。正是有了 partition 的存在,才使得可以将整个大问题进行划分,进而分别进行处理。
除了用来进行快速排序,partition 还可以用 O(N) 的平均时间复杂度从无序数组中寻找第K大的值。和快排一样,这里也用到了分而治之的思想。首先用 partition 将数组分为两部分,得到分界点下标 pos,然后分三种情况:
- pos == k-1,则找到第 K 大的值,arr[pos];
- pos > k-1,则第 K 大的值在左边部分的数组。
- pos < k-1,则第 K 大的值在右边部分的数组。
下面给出基于迭代的实现(这里寻找第 k 小的数字):
1 | int find_kth_number(vector<int> &arr, int k){ |
该算法的时间复杂度是多少呢?考虑最坏情况下,每次 partition 将数组分为长度为 N-1 和 1 的两部分,然后在长的一边继续寻找第 K 大,此时时间复杂度为 O(N^2 )。不过如果在开始之前将数组进行随机打乱,那么可以尽量避免最坏情况的出现。而在最好情况下,每次将数组均分为长度相同的两半,运行时间 T(N) = N + T(N/2),时间复杂度是 O(N)。
Partition 进阶
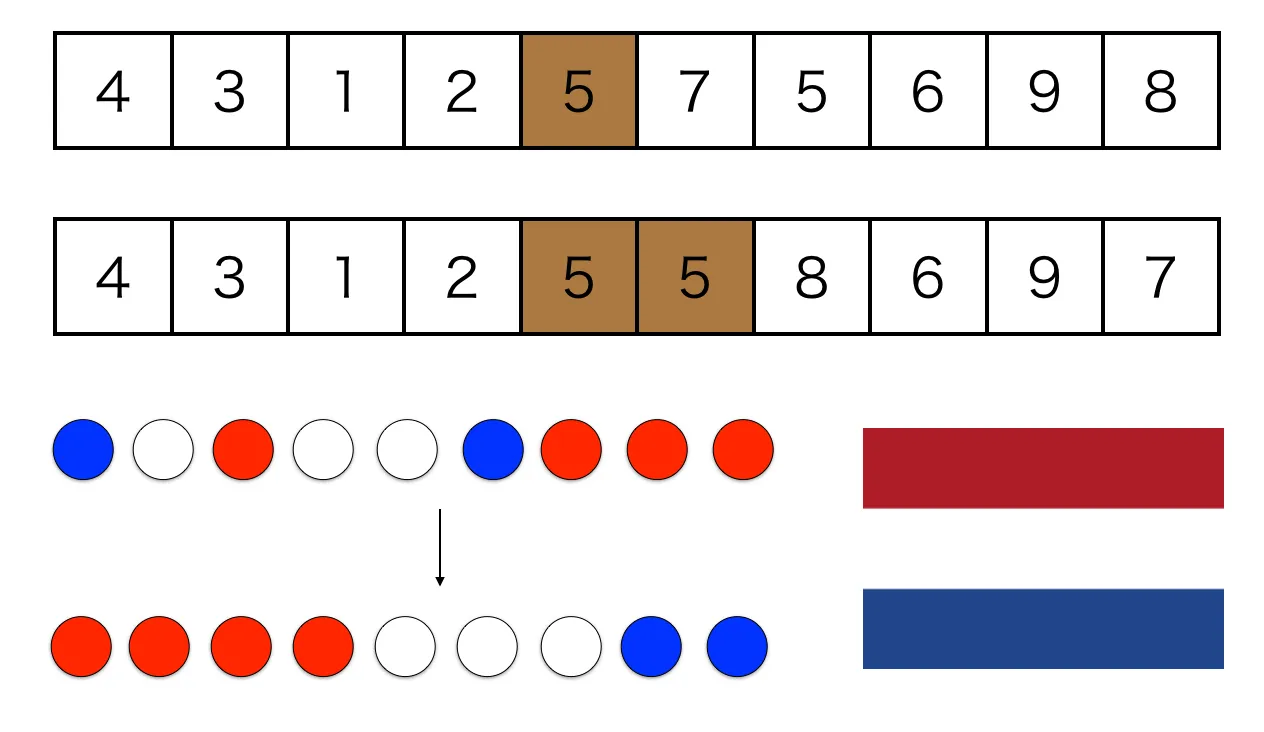
接下来先考虑这样一个问题,给定红、白、蓝三种颜色的小球若干个,将其排成一列,使相同颜色的小球相邻,三种颜色先后顺序为红,白,蓝。这就是经典的 Dutch national flag problem。
我们可以针对红,蓝,白三种颜色的球分别计数,然后根据计数结果来重新放球。不过如果我们将问题进一步抽象,也就是说将一个数组按照某个target值分为三部分,使得左边部分的值小于 target,中间部分等于 target,右边部分大于 target,这样就不能再用简单的计数来确定排序后的结果。这时候,就可以用到另一种 partition 算法:three-way-partition。它的思路稍微复杂一点,用三个指针将数组分为四个部分,通过一次扫描最终将数组分为 <,=,> 的三部分,如下图所示:
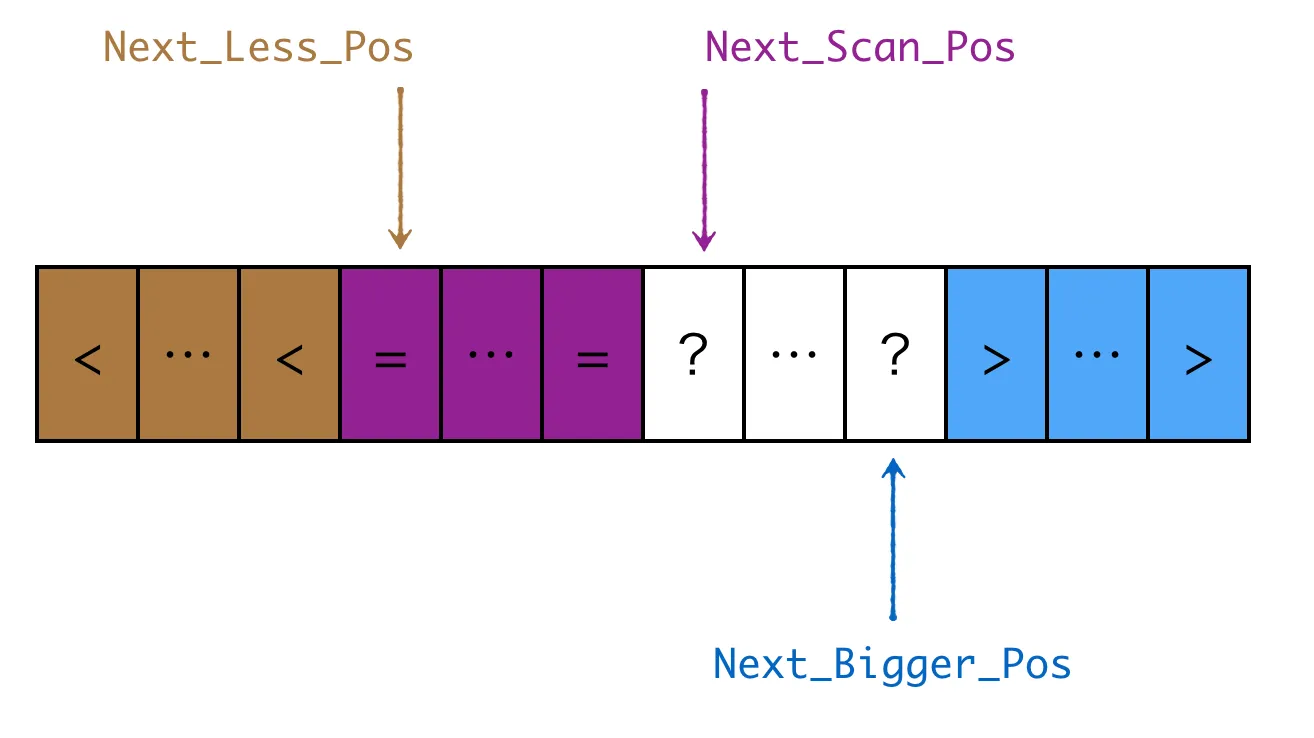
可以结合下面代码来理解具体的逻辑:
1 | // Assume target is in the arr. |
这里的主要思想就是在一遍扫描中,通过交换不同位置的数字,使得数组最终可以维持一定的顺序,和前面快排中用到的 partition 思想一致。区别在于快排按照 pivot 将数组分为两部分,左右部分中的值都可能等于 pivot,而 three-way-partition 将数组分为 <, =, >的三部分。
更多阅读
Algorithms 4.0: DemoPartitioning
Dutch national flag problem
Time complexity of quick-sort in detail
Quicksort Partitioning: Hoare vs. Lomuto
数学之美番外篇:快排为什么那样快

