C++ 函数可变参实现方法的演进
可变参数函数是接受可变数量参数的函数,在不少场景下,可变参数函数是非常有用的。比如想打印日志时,可以接受任意数量的参数,然后将这些参数拼接输出到控制台,如下:
1 | { |
在C++中,可变参数函数的实现方法也是不断演进的,从最初C风格的可变参数列表,到 C++11 的变参模板,再到 C++17 引入的折叠表达式,见证了 C++ 语言的逐步发展和完善。接下来本文会介绍这三种方式的实现细节以及优缺点。
C 风格变长参数列表
最早是 C 风格的变长参数列表,它通过 <cstdarg> 中定义的宏实现,主要包括:va_list, va_start, va_arg, va_end。下面是一个使用 C 风格变长参数的例子,实现了一个函数来计算任意数量整数的和:
1 |
|
变长参数函数在汇编层面的实现依赖于特定的平台和调用约定。基本的思想是通过栈(或在某些情况下是寄存器)来传递参数,并使用指针运算在内部遍历这些参数。优点是提供与C语言良好的兼容性,适用于需要与C代码接口的场合。
但是这种实现中,需要在调用函数时显式提供参数的个数。这是因为编译器在编译时不检查省略号后面参数的类型或数量,因此必须有一种方式来确定传递了多少个参数以及如何正确处理它们。最常见的方法是通过一个固定的参数指定后续参数的数量,不过也有其他方法,比如 printf 使用格式字符串中的格式说明符来确定后续参数的数量和类型。对于 printf("i = %d, pi = %.2f, s = %s\n", i, pi, s);,通过格式字符串中的%d, %.2f, 和%s自动推断出它需要从可变参数中读取一个整数(int), 一个双精度浮点数(double), 和一个字符串(char*)。
要注意这种方式不检查数据类型,错误地传递参数类型可能导致运行时错误。比如下面的调用中,第 1 个参数传成了字符串,编译器不会报错,但是运行时计算出来的结果是不对的。
1 | std::cout << sum(5, "1", 2, 3, 4, 5) << std::endl; |
C++11 的变参模板
随着 C++ 模板技术的发展,为了更好支持变参函数,C++11 引入了变参模板,不需要在调用时指定参数的个数,而是通过模板和递归函数展开来处理任意数量和类型的参数。上面的 sum 函数用变参模板实现如下:
1 |
|
在底层,变参模板的实现依赖于编译器对模板的实例化过程。编译器会递归地将变参模板实例化为多个重载函数,每个函数处理一个参数,直到参数包被完全展开。这个过程完全在编译时进行,不涉及运行时性能开销。这个过程主要分两步:
- 递归展开:编译器会生成一系列函数实例,每次调用中使用一个参数,直到参数列表为空。在上述例子中,sum(1, 2, 3, 4, 5) 会被展开为 1 + sum(2, 3, 4, 5),接着 sum(2, 3, 4, 5) 被展开为 2 + sum(3, 4, 5),以此类推。
- 终止条件:递归展开的过程需要一个终止条件来结束递归调用。在上述例子中,当参数包中只剩下一个参数时,会调用基础案例的sum(T t),作为递归的终止条件。
我们可以在上面模板函数中添加打印语句,然后在运行时观察到模板展开的结果。虽然这种方法不能直接展示编译时的情况,但它可以帮助理解模板是如何逐步被实例化和展开的。
1 | template<typename T> |
运行结果如下:
1 | Processing 1 |
模板递归实例化
为了能够直观看到编译时模板的递归展开,我们可以用 Clang 提供的-Xclang -ast-print选项,显示模板展开后的抽象语法树(AST)。完整命令如下:
1 | clang++ -fsyntax-only -Xclang -ast-print -std=c++11 test.cpp |
可以看到下面结果:
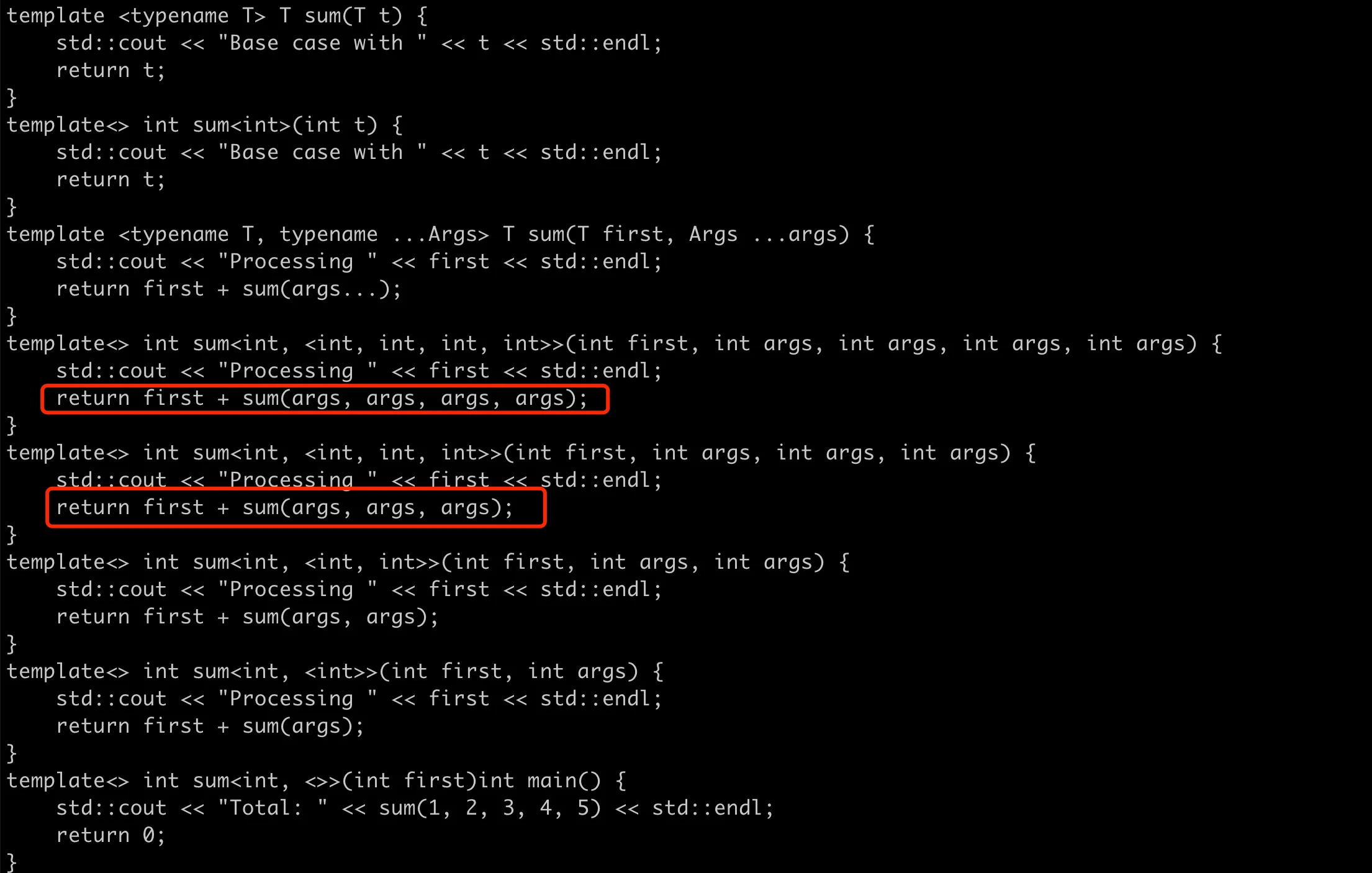 模板递归展开变参函数
模板递归展开变参函数
可以看到当函数 sum(1, 2, 3, 4, 5) 被调用时,编译器生成如下展开:
1 | sum<int, int, int, int, int>(int first, int args, int args, int args, int args) |
这些展开显示了如何逐步减少参数的数量,每次调用处理一个参数并将剩余的参数传递到下一个递归调用。
类型安全
变参模板有一个优点就是类型安全,这是因为变参模板的实现依赖于编译器的模板展开机制,可以在编译时进行类型检查。前面 C 风格的变长参数 sum 实现中,函数调用时候,如果传入参数是一个 string,是可以通过编译的,在运行时结果才会出错。
1 | std::cout << sum(1, "2", 3, 4, 5) << std::endl; // 输出: 15 |
而在变参模板中,函数调用每个参数都是在编译时明确指定的类型,编译器将检查加法操作是否对每种类型有效,这就确保了类型安全。上面代码尝试把int和string类型相加,将在编译时就直接报错,而不是等到运行时。如下图:
 变参模板是类型安全的
变参模板是类型安全的
通过使用变参模板而不是传统的C风格变长参数,所有类型错误都在编译时被捕捉,不会在运行时突然崩溃。对于不支持的操作,比如尝试打印一个没有重载输出运算符的复杂对象,编译器会报错。这样的代码更加安全、清晰且易于维护。
变参模板的局限
当然变参模板也有一些局限,熟悉递归的人可能会想到,递归展开的深度往往是有限的。这个问题在变参模板中也是存在的,编译器对递归展开的深度有限制,当参数过多时,可能会导致编译失败。Clang 编译器的默认模板递归实例化深度在 Mac 上是 1024 层,可以使用下面的 C++ 程序来测试 Clang 的模板递归深度限制。
1 |
|
上面代码尝试实例化模板 Depth<5000>,如果超过了编译器默认的递归实例化深度限制,则会出现编译错误。
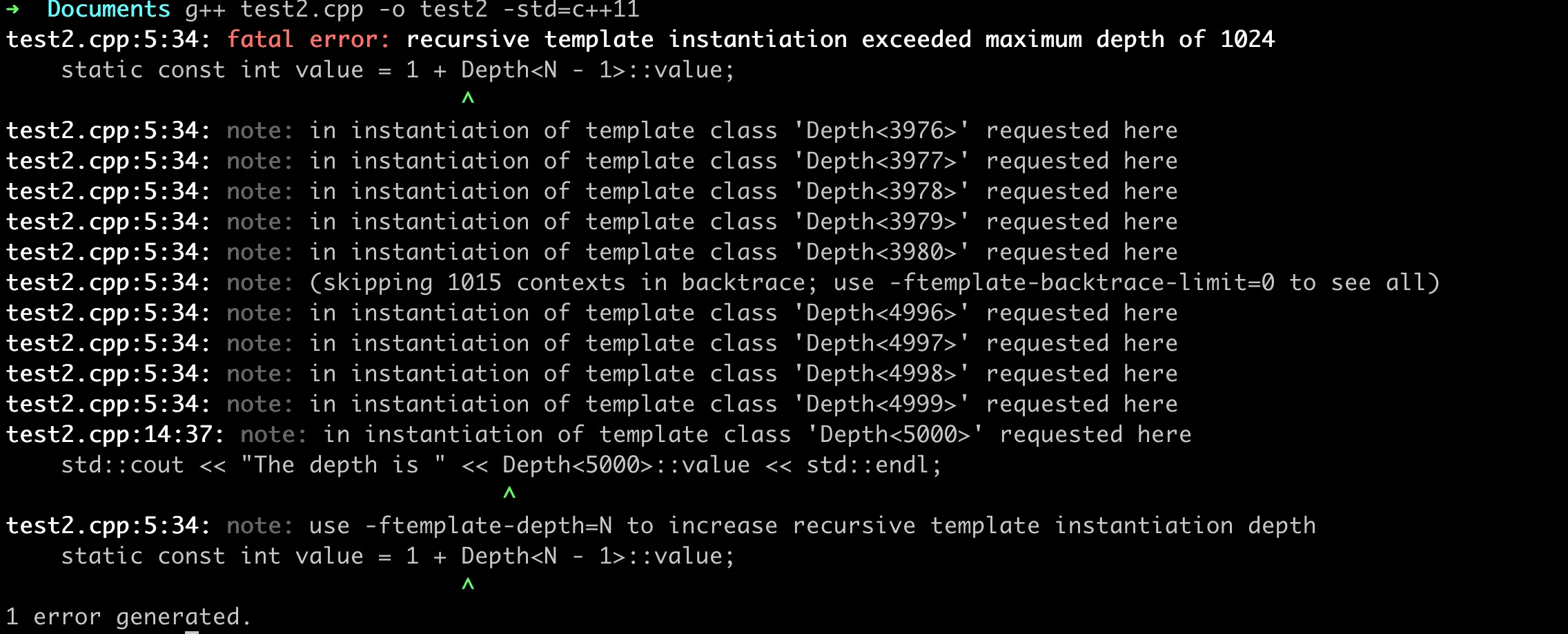 Clang 编译器默认的递归实例化深度限制
Clang 编译器默认的递归实例化深度限制
除了递归深度问题,还有一些其他缺点也值得关注:
- 在一些性能敏感的环境,递归模板函数的编译结果可能不如手写的迭代代码高效。
- **编译速度变慢。**变参模板的处理需要编译器在编译时展开和实例化模板,特别是当涉及复杂的递归展开和多层模板嵌套时,编译器的工作量显著增加。
- 代码膨胀(二进制大小增加)。每次使用变参模板函数时,如果涉及到不同的参数类型组合,编译器需要生成该特定组合的新实例。每个实例都是一个单独的函数,这会增加最终可执行文件的大小。
C++17 的折叠表达式
在 C++11 引入变参模板后,社区和委员会也一直在评估其使用情况和局限性。随着技术和理解的进步,以及编译器技术的发展,折叠表达式在C++17中被认为是成熟且有用的,因此被加入标准。折叠表达式提供了一种非递归的方式来处理变参模板,有效解决了深度递归和编译效率问题。折叠表达式是一种新的语法,可以在编译时展开参数包,将参数包中的所有参数组合成一个表达式。
先来看简单示例代码,一个变参的 sum 和 show 打印函数,从代码行数来说比之前方案就简单了很多:
1 |
|
上面实现了一个 sum 和一个打印变量的方法,sum函数利用了C++17的折叠表达式语法 (args + ...)。这种语法告诉编译器将加法运算符应用于所有给定的参数。如果函数被调用如 sum(1, 2, 3, 4, 5),折叠表达式将展开为 1 + 2 + 3 + 4 + 5。同理,折叠表达式(std::cout << ... << args)将会对每个args进行展开,并应用<<运算符,这样做避免了递归调用,直接在一行中处理所有参数。
和模板变参一样,折叠表达式也是在编译时展开的,不会引入运行时开销。折叠表达式的优点在于简洁、高效,并且不会引入递归深度限制。同时,也是类型安全的,编译器会在编译时检查参数的类型,确保所有参数都可以正确地应用到表达式中。
实现细节
折叠表达式允许编译器通过一种简洁的语法规则来展开参数包,这种展开是在编译时完成的,具体的实现依赖于编译器的内部机制。从结果来看,当编译器遇到折叠表达式时,它会将表达式中的操作符应用于参数包中的每个元素。对于二元操作符如 +,<< 等,编译器生成一系列操作,这些操作按照指定的折叠模式(左折叠或右折叠)连接起来。
- 左折叠
((... op args)):如果参数包为 {1, 2, 3},结果为 ((1 + 2) + 3)。左折叠的应用场景如逻辑运算 AND 或 OR 操作,可以确保从左到右的短路评估。 - 右折叠
((args op ...)):如果参数包为 {1, 2, 3},结果为 (1 + (2 + 3))。右折叠的应用场景如函数组合,从右至左组合函数更自然,因为这符合数学中的复合函数(g(f(x)))顺序。
用 clang 可以看到编译器展开折叠表达式的结果,结果如下:
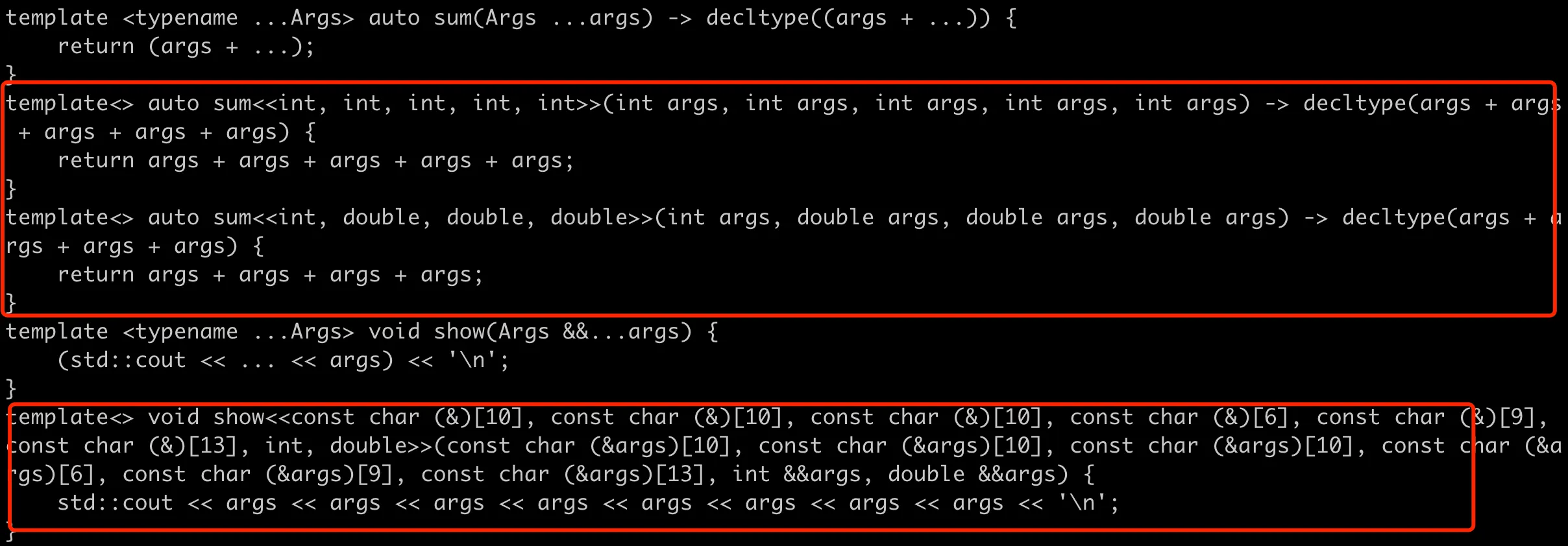 折叠表达式展开
折叠表达式展开
可以看到这里对于每个模板调用,只生成了一个展开的迭代的函数,而不是模板变参的递归实现。
在开源库中的应用
许多现代 C++ 库利用了变参模板和折叠表达式来实现其功能,使得这些库更加灵活、强大和类型安全。比如 fmt 是一个现代化的 C++ 格式化库,提供了一种类型安全的方法来替换 C 风格的printf。在C++20标准中,fmt的核心功能被采纳为标准库的一部分,即std::format。它的用法很现代化,和 python 的 print 用法有点类似,如下:
1 | std::string s = fmt::format("The answer is {}.", 42); |
在它的实现中,有个比较重要的make_format_args函数,它用于创建一个存储参数引用的对象,该对象可以隐式转换为fmt::format_args。这个函数展示了变参模板的复杂用法,包括默认模板参数、模板非类型参数、参数包和SFINAE(Substitution Failure Is Not An Error)技术。具体实现代码如下:
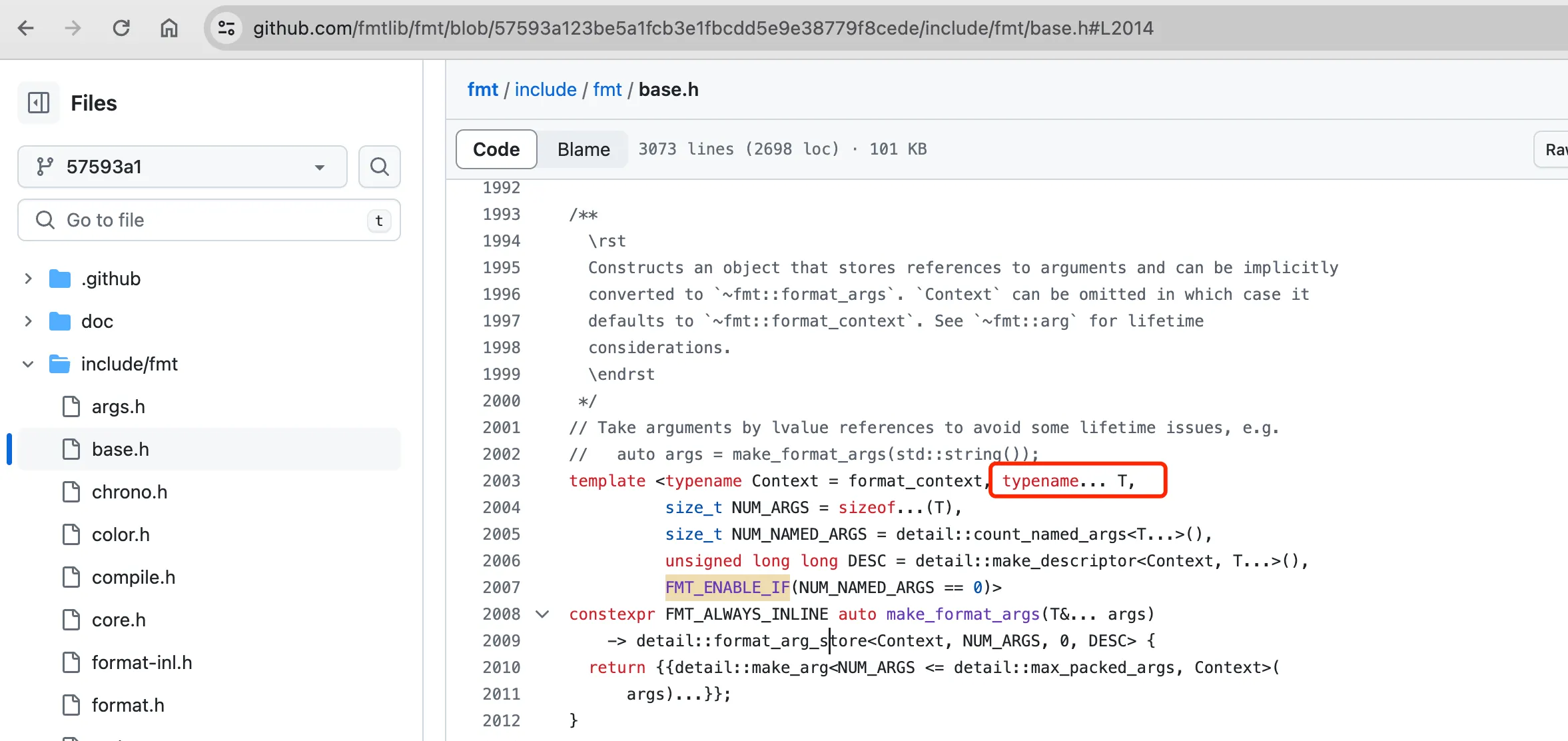 make_format_args 利用变参模板的实现
make_format_args 利用变参模板的实现
其中 typename... T是一个类型参数包,允许函数接受任意数量和类型的参数。NUM_ARGS 通过sizeof...(T)计算,这是一个编译时常数,表示传递给函数的参数数量。NUM_NAMED_ARGS通过detail::count_named_args<T...>()计算,这个值代表命名参数的数量。fmt库支持基于名称的参数引用,这个计算帮助库识别有多少个命名参数被传递。
函数返回一个模板结构体,用于存储和管理传递给函数的参数。该结构体将参数包装成fmt::basic_format_arg类型,这些参数可以在后续的格式化操作中使用。
总结
本文介绍了 C++ 中实现可变参数函数的三种方法:C 风格的变长参数列表、C++11 的变参模板和 C++17 的折叠表达式。这三种方法各有优缺点,适用于不同的场景。C 风格的变长参数列表适用于需要与 C 代码接口的场合,但是不支持类型安全。C++11 的变参模板通过递归展开实现了类型安全,但是可能存在递归深度限制和编译速度问题。C++17 的折叠表达式提供了一种简洁、高效的方式来处理变参模板,避免了递归调用和深度限制,同时保持了类型安全。
另外再补充说明下,本文部分内容是和 ChatGPT 结对,通过提问并验证的方式来学习和总结的,整体对话可以查看ChatGPT - Variadic Templates in C++。另外也参考了一些其他文档,如下:

