ChatGPT Prompt 最佳指南三:复杂任务拆分
本文是 ChatGPT Prompt 最佳指南系列的第三篇,全部系列文章:
- ChatGPT Prompt 最佳指南一:写清晰的说明;
- ChatGPT Prompt 最佳指南二:提供参考文本;
- ChatGPT Prompt 最佳指南三:复杂任务拆分;
- ChatGPT Prompt 最佳指南四:给模型思考时间;
- ChatGPT Prompt 最佳指南五:借助外部工具;
- ChatGPT Prompt 最佳指南六:系统基准评测;
在我们日常生活中,无论是烹饪一道复杂的菜肴,还是组装一台复杂的机器,我们都会自然而然地将复杂的任务拆分成一系列更简单、更易于管理的子任务。这种策略也同样适用于计算机领域。想象一下,如果没有函数这种工具,我们如何能够有效地编写和管理复杂的代码呢?函数的发明,实际上就是为了将复杂的任务拆分成更小、更具体的子任务,使得代码更易于理解和维护。
同样,对于人工智能,特别是像 GPT 这样的模型来说,拆分子任务的策略也同样重要。将复杂任务拆分成更简单的子任务可以帮助 GPT 更好地回答问题,原因主要有以下几点:
- 理解上的优势:GPT 通过处理一系列简单的任务,可以更好地理解和处理复杂的问题。每个子任务都可以被看作是一个独立的问题,GPT 可以专注于解决这个问题,而不是同时处理多个问题。
- 上下文的限制:GPT 的上下文窗口有限,也就是说,它只能看到最近的一定数量的输入和输出。如果一个任务太复杂,可能会超出这个窗口,导致 GPT 无法看到所有的相关信息。通过将任务拆分,可以确保每个子任务都在 GPT 的上下文窗口内。
- 减少错误的可能性:如果一个任务非常复杂,GPT 可能会在尝试解决它的过程中犯错误。通过将任务拆分成更简单的子任务,可以减少这种错误的可能性。
- 更好的反馈:当你将一个复杂任务拆分成子任务时,你可以在每个子任务完成后给予 GPT 反馈,这可以帮助 GPT 更好地理解你的需求,从而提供更好的答案。
总的来说,将复杂任务拆分成更简单的子任务可以帮助 GPT 更有效地理解和处理问题,从而提供更好的答案。接下来我们会提供几个具体的例子,来具体看看如何拆分子任务。
示例一:客服助手
现在我们的目标是写一个微信 App 的智能客服,当用户提问关于 App 的问题时,我们的智能客服可以根据预先准备好的帮助文档,找到相关解决办法,并重新组织好语言给出答案。
因为微信的帮助文档内容太长,没办法作为引用文本一次性提供给 GPT4 作为提示词。所以可以考虑拆分下这里的问题,一个不错的拆分方法就是先让 GPT 分类问题,然后根据分类来提供这个分类下的帮助文档作为提示词。
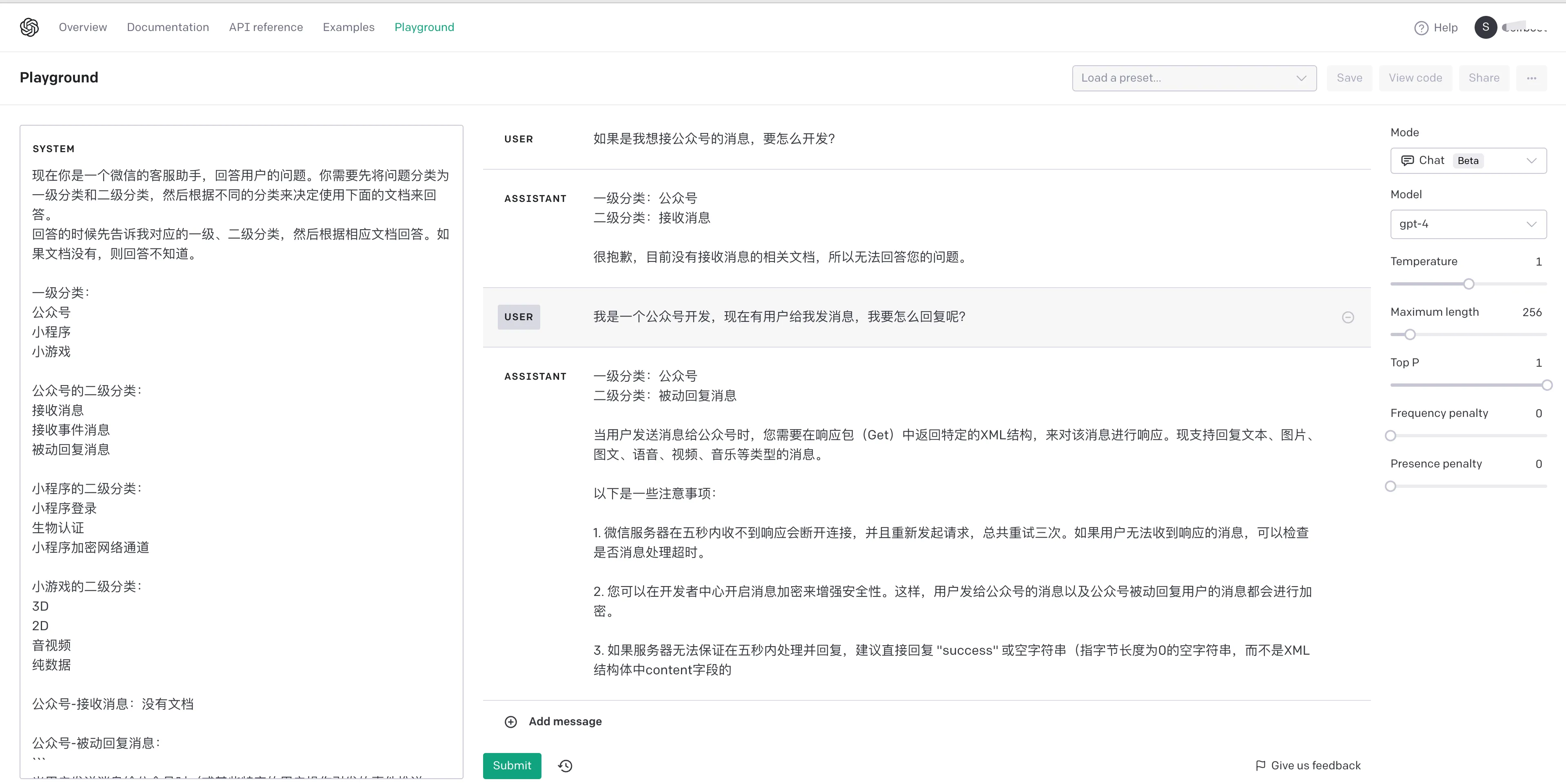
上面在 OpenAI playground 上创建了一个简单示例,通过让 GPT4 先对问题分类,然后再根据不同类型的子问题和引用文本,来生成答案。注意这里示例把整个内容放到 system msg,实际构建客服的时候,第一步只用让 GPT4 分类,然后根据分类信息,来选择文档作为引用文本,重新提问。
通过加入中间分类步骤,成功完成了一个复杂的查询任务。类似的场景还有许多,比如要总结很长的一段文本(超过 GPT 的上下文 token 限制),可以拆分成以下子任务:
- 将文本分段:可以将长文本分成几个段落或部分,可以根据文本的自然结构来完成,例如章节、标题或主题。
- 为每个部分生成摘要:让 GPT4 提取每个部分的主要观点或信息,因为已经拆分过,所以没有超过 token 限制。
- 组合摘要:用 GPT4 将所有的摘要组合成一个完整的总结。在这个步骤中,需要确保总结的连贯性和一致性。
当然这个过程中你需要确保每个部分的摘要都准确地反映了该部分的内容,而且所有的摘要在一起需要能够形成一个全面的总结。此外,你还需要处理可能出现的上下文问题,例如确保 GPT 在生成摘要时能够理解每个部分的上下文。
示例二:辅助编程
编写复杂程序一直以来是专业人员才能做到的,但现在人人都可以使用 GPT4 来写程序。比如我的目标是写一个程序,能够将我印象笔记导出的笔记批量导入到 notion 中。我可以拆分为下面的子问题(具体子问题的 prompt 可以根据当时的上下文写的更详细一些):
- 我想用 python3 把一个笔记导入到 notion 中去,有没有什么推荐的方法;
- 印象笔记导出的是 html 文件,我如何解析里面的笔记正文;
- 用 python3 如何并发导入文件到 notion;
- 要展示导入的进度条,在 Python3 中如何做呢?
- 如何在导入结束的时候,用红色把导入失败的原因打印到屏幕上
- 如何测试我的这段代码呢?
当然这里的子问题可能不是一开始就能规划好的,在和 GPT4 交流的过程中,可以不断根据上一个回答,来调整问题。在开发程序的过程中,遇到一些预期外的问题,也可以再来提问,比如 notion 返回了一个错误是请求频率太高,或者是网络超时,那么你可以继续提问:
- 有什么 python3 的库可以控制我请求接口的频率;
- 我的实现代码如下(这里省略),如何用 aiolimiter 来控制请求 notion api 的频次;
- 如果请求 notion api失败,我要怎么优雅的重试我的请求;
- 有哪些 python3 的重试库,哪些还是活跃的,要怎么在我的代码上添加上重试;
总之不要给 GPT4 太复杂的任务,毕竟还不是通用 AI,需要你帮忙拆分子问题,验证 AI 的回答,最终拼凑起来一个完整的解决方案。这个例子是真实的,在 GPT4 的帮助下,我比较快速的完成了一个 python 库 html2notion,能够将印象笔记导出来的 html 文件批量导入到 notion 笔记中,并尽量保留格式。
示例三:反转字符串
有些任务看起来很简单,似乎不用拆分子任务就能完成。比如反转一个英语单词,给你 apple,输出 elppa;给你 lollipop,输出popillol。如果让 gpt-4 直接来翻转单词,可能会得到错误的结果。
- apple->elppa
- popillol->pilpollol
这可能是因为GPT-4作为一个语言模型,是通过大量的文本数据进行训练的。在这些文本数据中,它学习到了单词的拼写、语法、句子结构等信息,但是并没有专门学习如何执行特定的算法或操作,比如反转单词。当你让 GPT-4 反转一个单词时,它可能会尝试根据它在训练数据中看到的模式来做,而不是按照一个明确的算法来执行。这可能导致它在执行这种简单任务时出错。
这里可以考虑拆分子任务,明确告诉 GPT 具体的反转步骤。一个参考提示词如下:
请按照下面的步骤反转给定的单词。
- 将单词拆分为一个个的字母;
- 将上面的字母倒序输出;
- 将字母拼接起来。
比如 apple,先拆分为 a,p,p,l,e ,然后反转 e,l,p,p,a,最后拼接起来为 elppa ;给定的单词如下,输出中间过程和结果。
可以看到已经能成功反转单词了,如下结果:
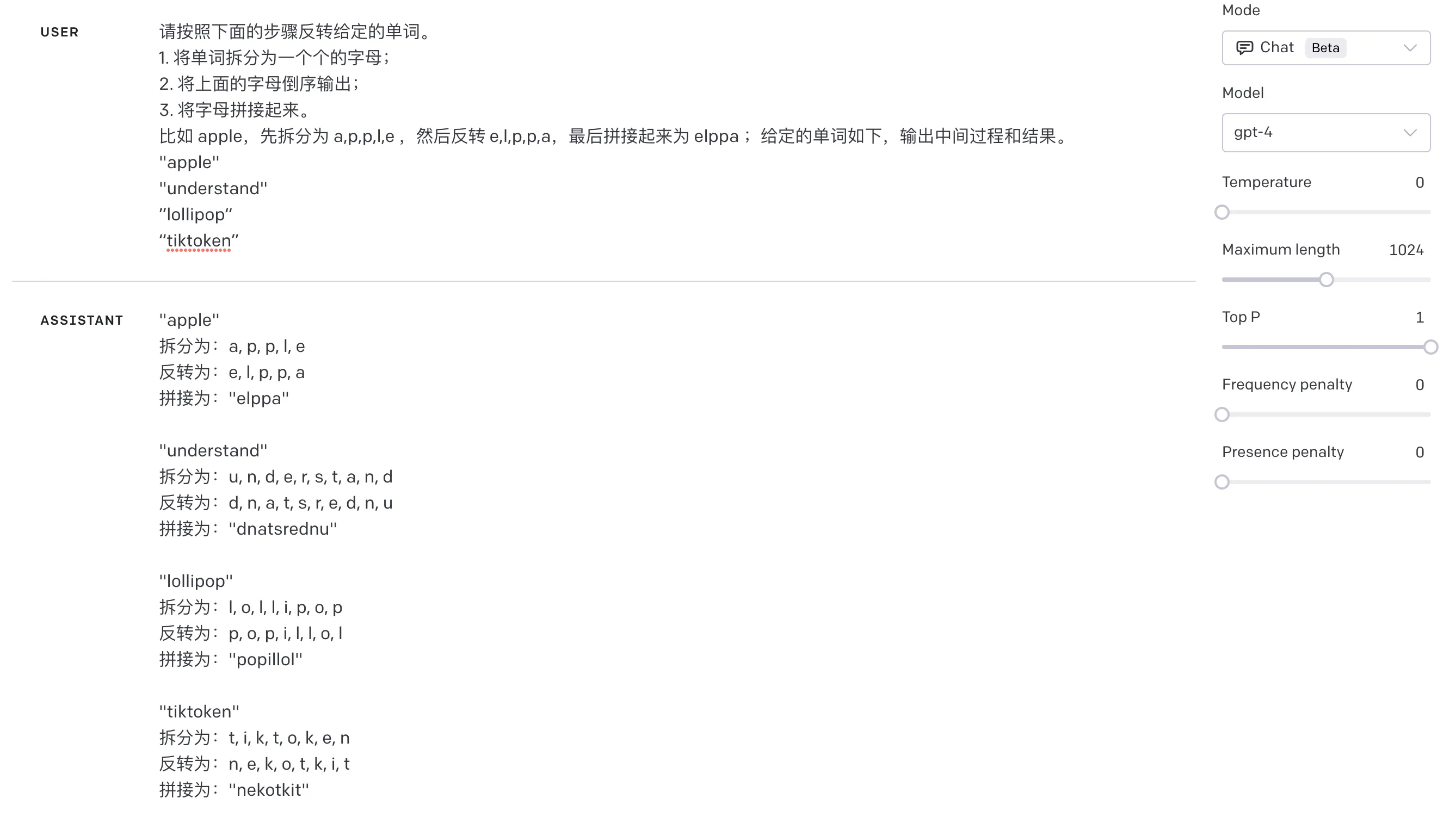
上面的提示词有时候也不稳定(如果不让模型输出中间过程,效果会更差),其实为了准确地执行这个任务,通常需要一个简单的算法,而不是一个复杂的语言模型。在编程中,反转一个字符串是一个基本操作,可以通过简单的代码来实现。我们可以让 GPT 来写一段反转单词的代码,这样不受任何语言模式的影响,可以准确地反转任何给定的单词。
面临的挑战
当然拆分子问题从来就不是一个简单的事情,其中一个挑战就是要理解 GPT 的能力和限制,在这些限制内有效地拆分问题。你需要通过实践和试错来了解 GPT 在处理不同粒度问题时的表现,以便找到最适合的问题粒度。比如是直接让 GPT4 来写一段代码,能够异步并发请求,并且限制请求频率,自动进行网络超时重试和异常处理。还是把这些拆分为不同的子任务,分别让它写出单独的代码,然后再组织起来。这需要在使用中慢慢摸索,才能找到一个好的平衡点。
另一个挑战是如何有效地组织和管理子问题。在拆分问题后,我们可能会得到大量的子问题和回答。如何有效地组织这些子问题,以便在需要时能够快速找到,是一个需要解决的问题。如果子问题之间没有关联,可能会丢失一些上下文,这会使得根据子问题的回答重新构建复杂问题的解决办法变得困难。因此,在每次提问时,我们应尽可能带上已经拿到的上下文,这可以帮助 GPT 更好地理解问题,从而给出更准确的回答。回到前面的例子,你可以带上目前已经有的相关代码,让 GPT4 在此基础上进行优化,增加新的功能点,这样 GPT4 会基于现有的代码直接更改,而不是重新写一段不一样的代码。

