ChatGPT Prompt 最佳指南六:系统基准评测
本文是 ChatGPT Prompt 最佳指南系列的第六篇,全部系列文章:
- ChatGPT Prompt 最佳指南一:写清晰的说明;
- ChatGPT Prompt 最佳指南二:提供参考文本;
- ChatGPT Prompt 最佳指南三:复杂任务拆分;
- ChatGPT Prompt 最佳指南四:给模型思考时间;
- ChatGPT Prompt 最佳指南五:借助外部工具;
- ChatGPT Prompt 最佳指南六:系统基准评测;
OpenAI 的 GPT 模型一直在不断进化,从 GPT-3 到 GPT-3.5,再到现在强大的 GPT-4,每一步都伴随着各种优化措施,使 AI 的回答变得越来越智能。然而,即使是同一版本的模型,使用不同的提示词也会产生质量各异的回答。这就引出了一个挑战:如何判断某个改变是否真正提升了AI的回答质量?换句话说,我们如何得出 GPT-4 比 GPT-3 更强大,或者哪个提示词效果更佳的结论?
这个问题并不容易解答。我们可能会看到一些例子,这些例子似乎暗示了新的改变带来了更好的效果。但是,由于我们只看到了少数几个例子,我们很难确定这是否是真正的改进,还是仅仅是随机运气的结果。更复杂的是,可能存在这样的情况:这个改变在某些输入下提升了效果,但在其他输入下却降低了效果。
近期,GPT-4 就因为这个问题受到了一些质疑。有人认为 OpenAI 为了节省算力,偷偷降低了模型的效果。例如,一篇公众号文章《大家都在吐槽GPT-4变‘笨’了,可能是架构重新设计惹的祸》就对此进行了讨论。在OpenAI的官方论坛上,也有很多类似的声音,如“Has There Been A Recent Decrease In GPT-4 Quality?”的讨论。甚至有人发表了论文,试图证明GPT-4的能力确实有所下降。
为了消除这些疑虑,同时也为了让开发者能更方便地评估模型的质量,OpenAI 决定开源他们的评测方法—— evals。这个工具的目标就是帮助我们更准确地评估我们的系统改进,让我们能够基于数据,而不是猜测,来决定我们的下一步行动。接下来,我将详细介绍这个工具的使用方法和评测标准,以便大家更好地理解和使用它。
评测原则和设计
什么是一个好的评测设计呢?OpenAI 在 Strategy: Test changes systematically 中给出了一个不错的答案:
- 代表现实世界的使用场景(或至少是多样化的):测试用例覆盖到许多使用场景,包括常见的和边缘的情况。
- 包含许多测试用例以获得更大的统计能力:评测结果需要有较高的置信度。
- 易于自动化或重复:为了确保评测结果的可靠性,我们需要能够轻松地重复评测过程。
评测工具 evals 的设计理念和实现方式,很好的体现了上述的评测设计原则。首先,它包含了各种类型的问题,如事实性问题、推理问题、创新性问题等,这些问题覆盖了 GPT 模型在实际使用中可能遇到的各种场景。事实性问题最好评测,这类问题的答案往往是一组已知事实,我们可以比对模型的输出包含多少事实。比如一些单选问题,判断问题,多选问题等。其他问题就比较难评测,比如翻译质量,总结摘要等。
其次,evals 包含了大量的测试用例,这使得我们可以从统计的角度对 GPT 模型的效果进行评估。最后,evals 的设计使得评测过程可以自动化运行。使用 evals,我们可以轻松地在不同的时间点,或者在 GPT 模型进行了修改之后,重新进行评测。
简单匹配评测
下面先来看看最简单的中文评测集 chinese_chu_ci。这里 是《楚辞》相关的匹配评测集,其中一条记录如下格式,给定了 Prompt 和期待的回答:
1 | { |
参考 README 和 How to run evals,我们在本地通过命令 pip install -e . 安装了 oaieval 工具,下面来执行下评测集看看。
GPT 3.5 评测
首先用 GPT3.5 来试试楚辞,结果如下:
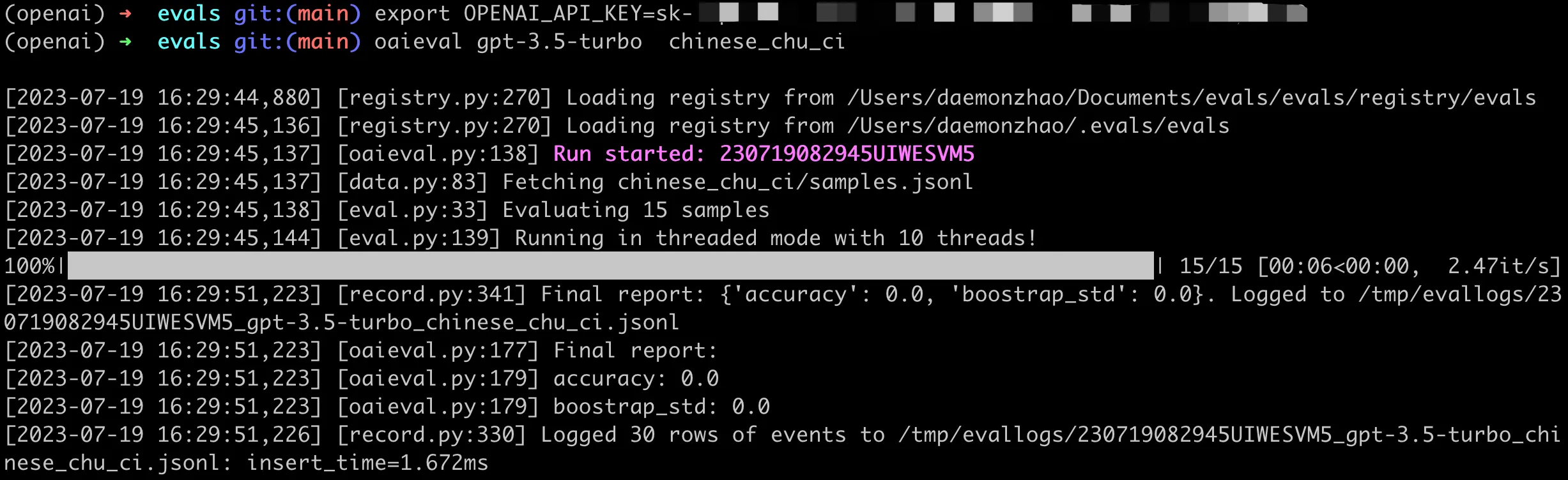
这里评测的结果里,除了总的评测汇总,还会给出一个详细日志,里面有每个问题样本的具体回答结果。随便找了一个问题的结果,可以看到这里的答案预期是《卜居》,但是模型回答成了《九歌》,完整结果如下:
1 | cat /tmp/evallogs/230719082945UIWESVM5_gpt-3.5-turbo_chinese_chu_ci.jsonl |
可以看到 3.5 在回答这种偏记忆的知识上确实不行,幻觉比较严重。
GPT4 评测
再来看看 GPT-4 的运行结果,如下图:
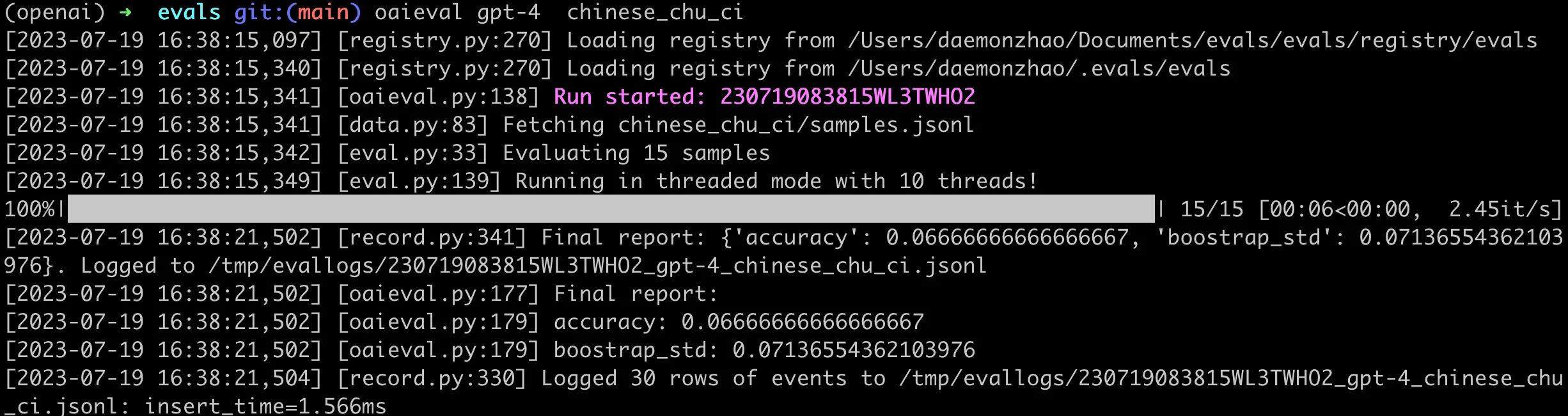
可以看到在这类问题上,即使是 GPT-4,回答的准确率也很低。唯一一个正确的样本结果如下:
1 | cat /tmp/evallogs/230719083815WL3TWHO2_gpt-4_chinese_chu_ci.jsonl |
这里需要说明的是,GPT-3.5 和 GPT-4 回答结果并不固定,因此每次尝试可能得到不同的结果。但是数据集足够大的话,整体样本的效果评测还是能有一个不错的置信度。
翻译质量评测
除了前面简单的匹配评测,OpenAI 还提供了翻译质量的评测。和前面匹配评测的区别在于,这里不能直接判断 GPT 模型生成的结果是否和数据集中期望的结果一致,而是通过一种算法,对模型翻译的文本和人工翻译的文本打分。
中文翻译的评测数据集在chinese_hard_translations,一共样本数量不多,如下图:
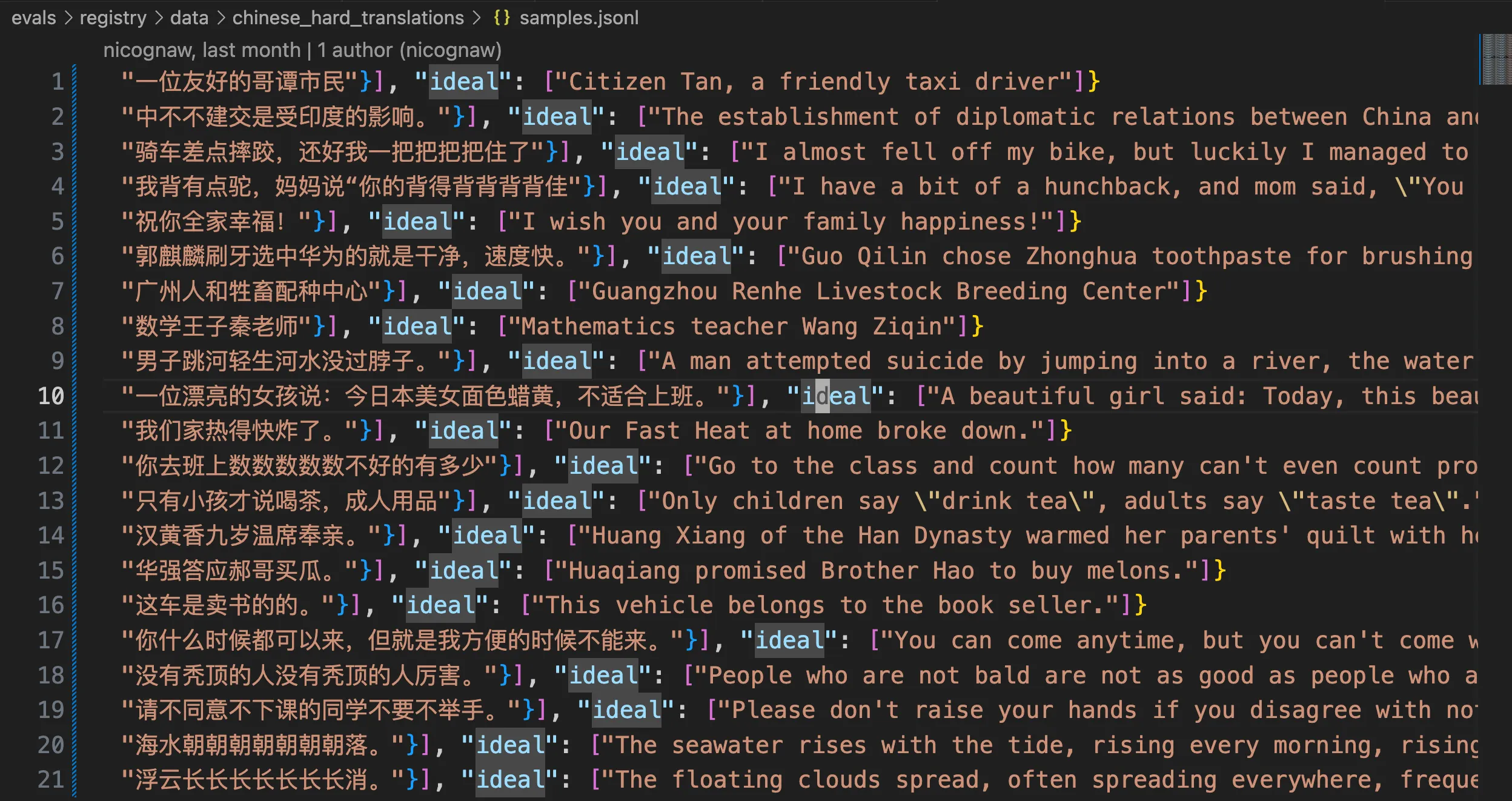
每条评测记录包括 Prompt,中文文本以及人工翻译的参考文本。如这个测试集名字 chinese_hard_translations 所言,这里的中文确实都是一些比较难翻译的中文语料,比如下面这种,一遍可能都读不通顺:
我背有点驼,妈妈说“你的背得背背背背佳“
你去班上数数数数数不好的有多少
这里评测记录的翻译 Prompt 值得学习:
Given a text representing, provide the English translation of the text. You MUST NOT provide any explanation in the output other than the translation itself. You MUST paraphrase rather than translate word for word, with ALL of the original meanings preserved.
这里我用不同 prompt 得到的翻译结果如下:

“I have a bit of a hunchback. My mom says, ‘You have to work on improving your posture.’”
“My back is slightly hunched, and my mother tells me, ‘You need to significantly better your posture.’”
其他的一些评测
截止 2023 年 7 月,OpenAI 的 evals 里提供了 423 个评测集,涵盖了日语,韩语,中文等语言,十分丰富。中文这里还有一些其他的评测,还比较有意思的,感兴趣的可以去看看。下面是一些示例:
回答小说作者。评测集在 chinese_famous_novel,比如 “小说《一地鸡毛》的作者是谁?只回答作者名称,不要额外附加其他内容”。
发音判断。提示词:下面这句话中是否存在发音一样的中文单词(两个汉字及以上),若存在返回是,若不存在返回否。你只需要输出是或者否。评测集在 chinese_homonym,里面还有歌词,比如“生活像一把无情的雕刻刀,改变了我们的样子。”。
猜字谜。提示词:
根据我给的描述猜出一个字(请从汉字的字形、发音、意义以及字的拆分组合等角度考虑)。首先提供你的推理,然后提供用英文方括号括[]起来的最终答案。
评测集在 Chinese_character_riddles,例子都还挺有意思,比如:
“一只黑狗,不叫不吼。” 。
小屋四四方,不见门和窗,有人犯了法,把他往里装。
田字露脚又露头,花果山上到处游,见人就把冤来报,戴上帽子问根由。
同音语义理解。这个是多选题,提示词:
The following are multiple choice questions (with answers) about Chinese homonym. Answer the question with english letter "A", "B" only, without explanation. Reply with only the option letter.
评测集在 chinese_homophonic,一些例子:
剩女产生的原因有个:一是谁都看不上,二是谁都看不上。这句话中的"看不上"是相同的意思吗?\nA. 相同\nB. 不同”
关于穿衣服,冬天能穿多少穿多少,夏天能穿多少穿多少。这句话中的"多少"是相同的意思吗?\nA. 相同\nB. 不同
孙悟空的金箍棒不见了,去询问土地公公,孙悟空:"我的金箍棒在哪里?" 土地公公:"大圣,你的金箍,棒就棒在特别配你的发型"。请问土地公公回答的对吗?\nA. 不对\nB. 对
实际上,中文数据集在整个评测集中只占据了一小部分。OpenAI 提供的评测用例非常丰富,可以帮助我们全面地评估模型的性能。在这篇文章中,我们只是简单地了解了 OpenAI 的 eval 评测示例。但是,这只是冰山一角。为了更深入地理解这个评测库,我们需要从代码的角度进行分析。在接下来的文章中,我们将深入探讨 eval 评测库的内部结构,以及如何使用这个库来进行更复杂、更精细的模型评估。

