Redis Issue 分析:流数据读写导致的“死锁”问题(2)
在 Redis Issue 分析:流数据读写导致的“死锁”问题(1) 中,我们成功复现了 Issue 中提到的 bug,观察到 Redis Server CPU 飙慢,无法建立新的连接,现有的连接也不能执行任何读写操作。借助强大的 ebpf profile 工具,我们观察到了 CPU 时间主要消耗在哪里,接下来我们一起来看下这个 BUG 的调试过程和修复方法。
调试 bug
考虑到 Redis server 进程还在,我们可以用 GDB attach 到进程上,打断点看下具体的执行过程。在火焰图上看到的比较耗时的 handleClientsBlockedOnKey 函数里面有 while 循环语句。而 CPU 飙满的话一般都是死循环,为了验证是不是有死循环在这个 while 里,可以在 whil 前面的 565 行和里面的 569 行打上断点,然后 continue 多次进行观察。
1 | while((ln = listNext(&li))) { |
我们看到每次都是在循环里面的 569 行暂停住,基本认定确实是这里发生了死循环。查看当前栈帧上的局部变量,可以看到 receiver指针。具体如下: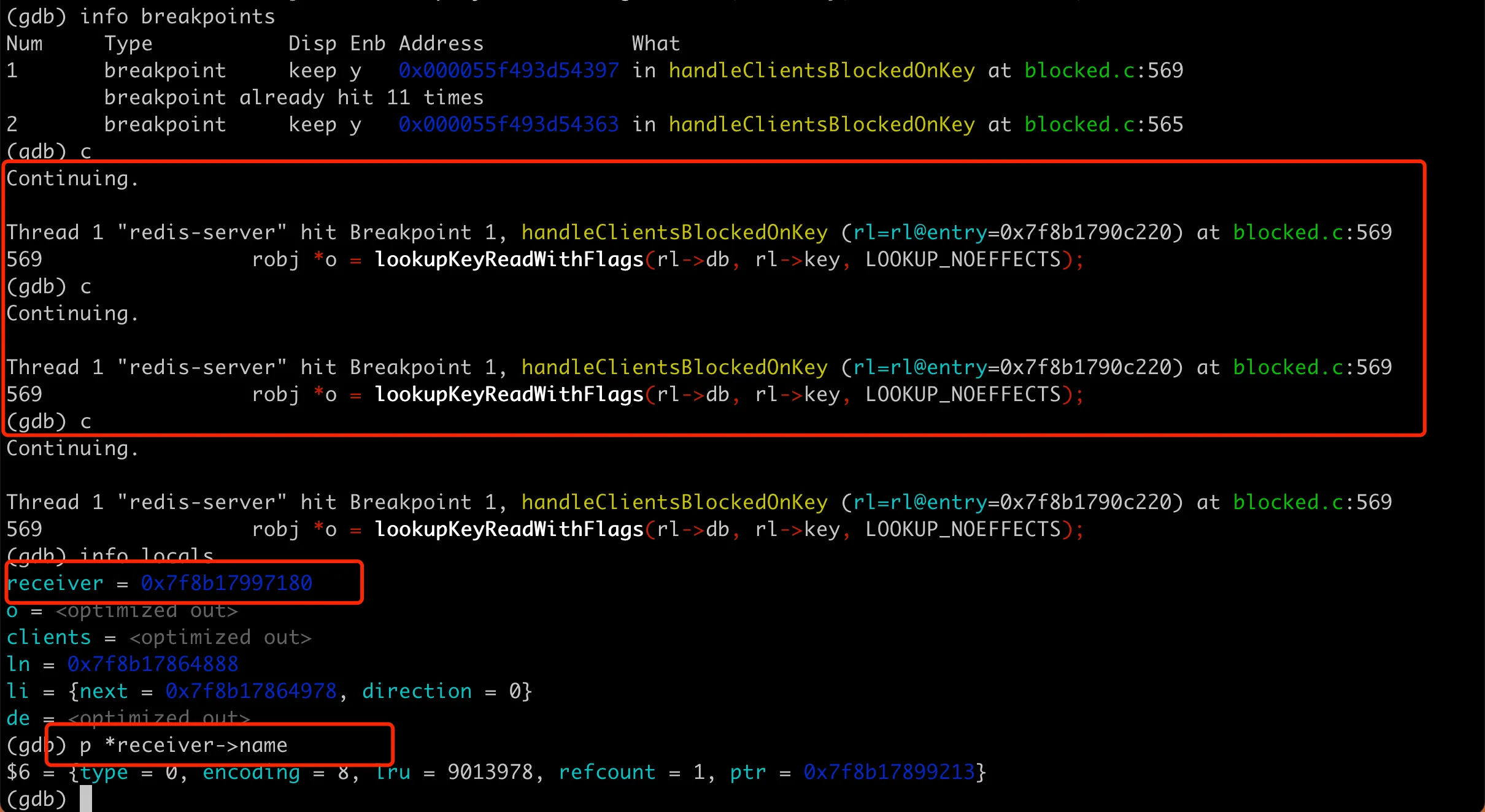
这里 receiver 是 server.h 里面声明的 struct client,是 redis 里面为每一个 client 连接维护的数据结构。现在的问题很清晰,server 进程在 while 循环中不断拿出来 client 连接,一直停不下来。为了弄清楚这些 client 从哪里来的,我们可以打印 client 里面的 name 字段。
1 | typedef struct client { |
不过这个是需要在 client 连接的时候设定的,于是重新改下我们在 Redis Issue 分析:流数据读写导致的“死锁”问题(1) 中的测试脚本,重新启动 server,跑一下复现流程,然后用 GDB 重新分析。
1 | def subscriber(user_id): |
GDB 打印出来 receiver 的 name 如下:
1 | (gdb) p *receiver->name |
其中 name 是一个 redisObject 对象,根据 type=0 和 encoding=8,知道这个 name 其实是一个 string,内存存储在 ptr 指针中。
1 | // object.c |
然后就可以用 p (char *)receiver->name->ptr 来打印 client 的具体名字了。这里还要连续打印多次 client name,看看每次取出来的 client 是什么。为了自动打印多次,可以用 GDB 里面的 commands指令,如下图:
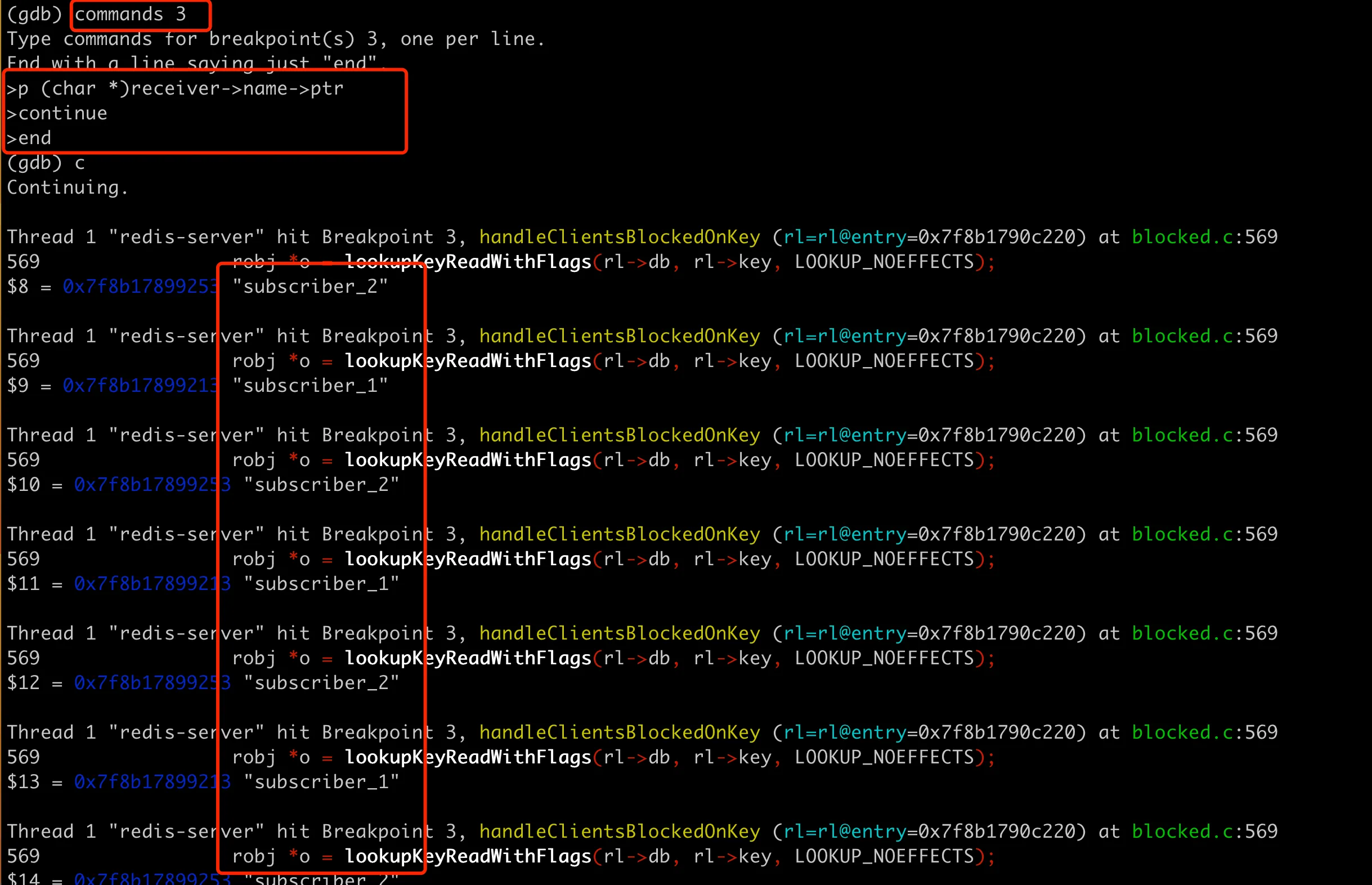
其实从队列里取出来的一直是 subscriber_1 和 subscriber_2,他们两个交替被取出来,无穷尽了,所以这里没法跳出循环。
修复代码
这里的修复用的是一个比较 trick 的方法,保证这里一次只处理完队列里当前时刻有的 client,新加入的 client 并不处理。具体提交是 commit e7129e43e0c7c85921666018b68f5b729218d31e ,提交信息描述了这个问题
Author: Binbin [email protected]
Date: Tue Jun 13 18:27:05 2023 +0800
Fix XREADGROUP BLOCK stuck in endless loop (#12301)For the XREADGROUP BLOCK > scenario, there is an endless loop.
Due to #11012, it keep going, reprocess command -> blockForKeys -> reprocess commandThe right fix is to avoid an endless loop in handleClientsBlockedOnKey and handleClientsBlockedOnKeys,
looks like there was some attempt in handleClientsBlockedOnKeys but maybe not sufficiently good,
and it looks like using a similar trick in handleClientsBlockedOnKey is complicated.
i.e. stashing the list on the stack and iterating on it after creating a fresh one for future use,
is problematic since the code keeps accessing the global list.Co-authored-by: Oran Agra [email protected]
提交修改部分比较少,如下:
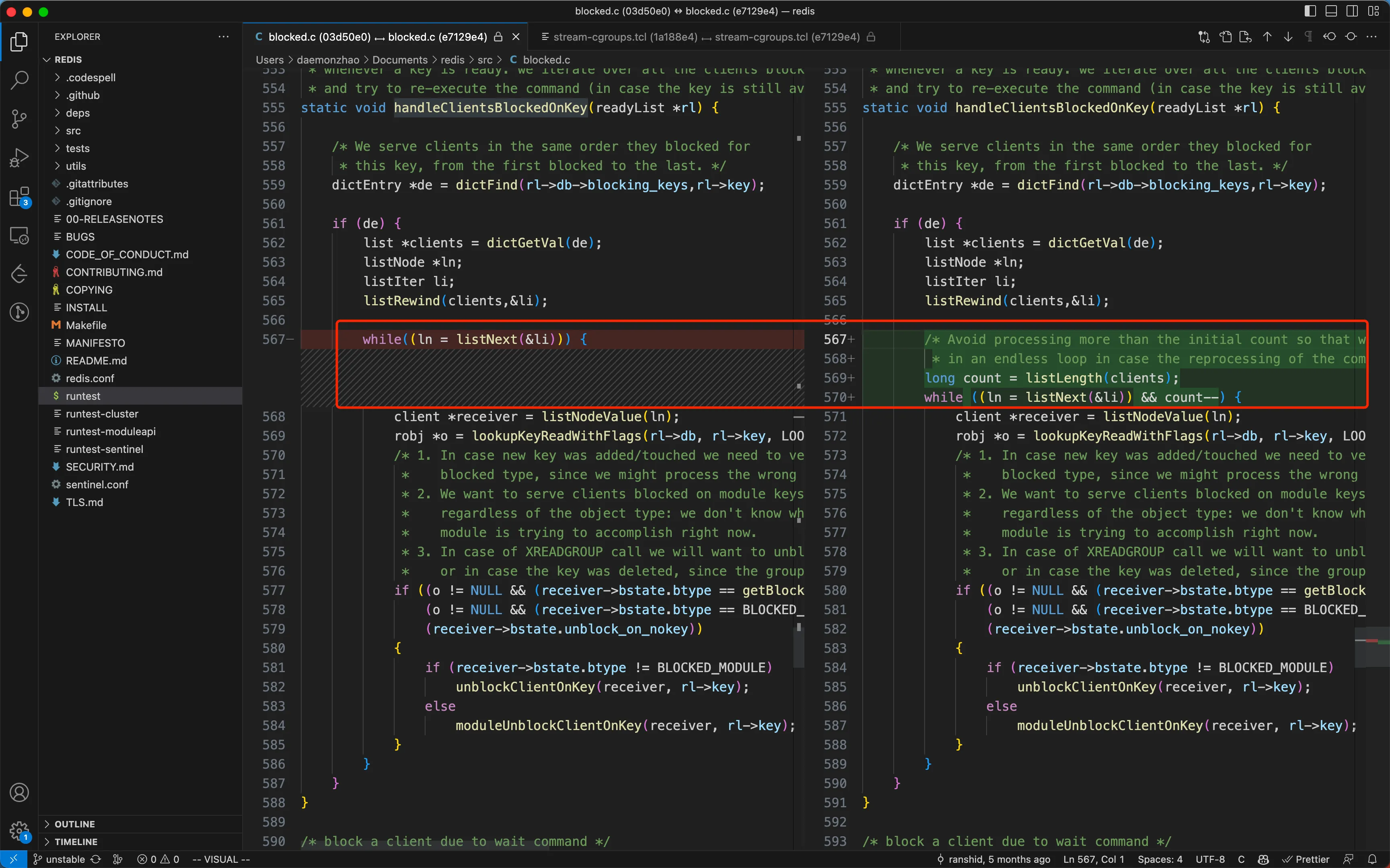
list 何时添加元素?
这里还有个问题需要明确,已经取出队列的 client,具体在什么时间又被放到队列中去了呢?因为对 redis 源码不是很熟悉,开始的时候看了半天没找到相应代码。在 Issue 上问了下,oranagra 出来解释说是在 blockForKeys 中(其实提交信息里也有说到这个函数)。
后来再思考这里的时候,才发现自己完全也能找到。因为这里 list 在循环中肯定不断添加 client,而 redis 里面 list 尾部添加元素的函数很容易找到就是 listAddNodeTail:
1 | // adlist.c |
我们只用在这个函数打断点就行了,执行到这里的时候,就能拿到函数的堆栈,就可以知道调用关系链了,如下图:
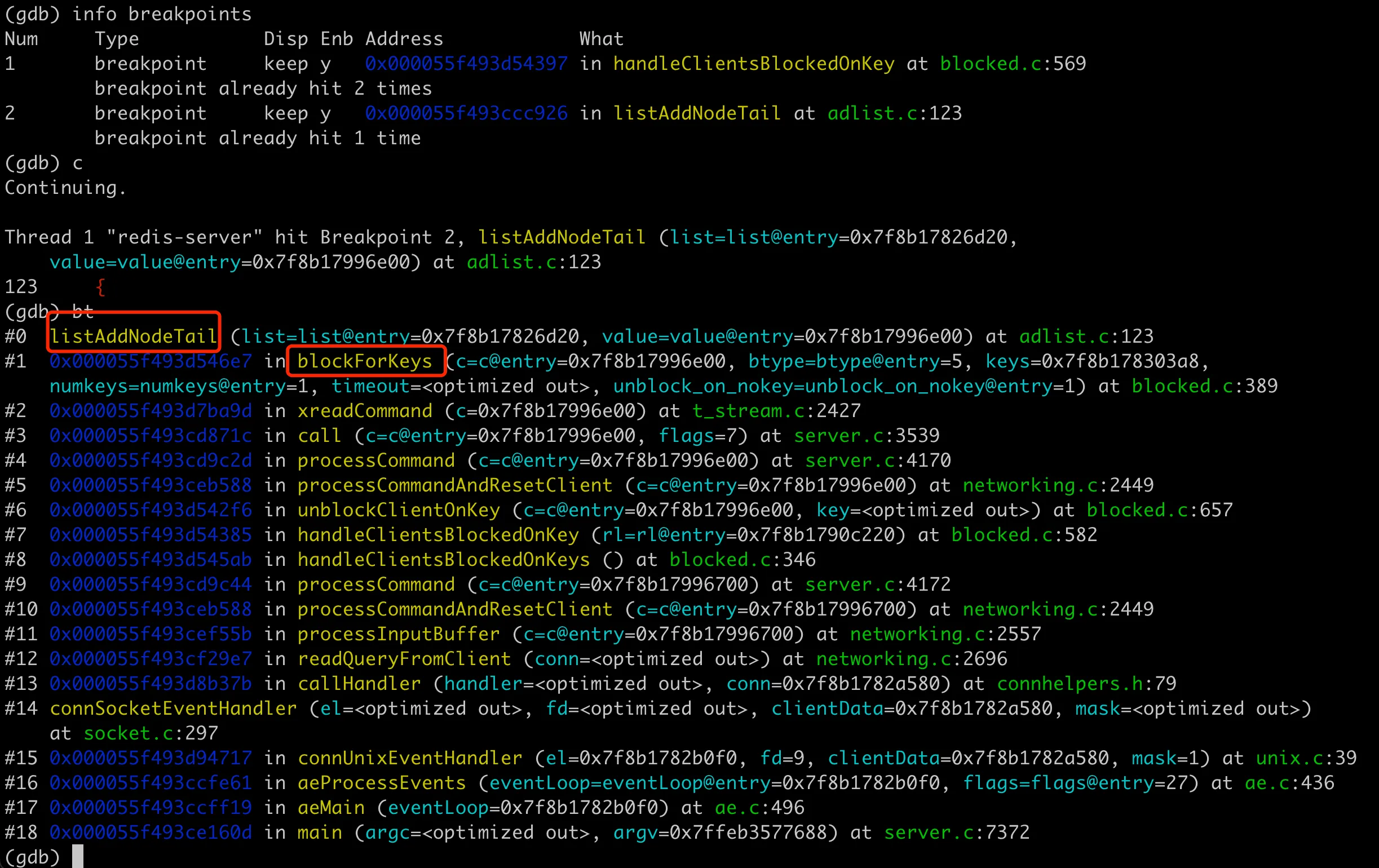
跳出循环就可以了?
还有个问题就是这里的修复方案里,在单次的 handleClientsBlockedOnKey 函数处理中,client 依旧会被追加到队列尾(这里其实没啥变更)。那么修改后的代码,后续为什么不会再取出来这两个 client 呢?
TODO…(待续)
测试用例
这里官方也补充了一个 tcl 测试用例脚本,在 tests/unit/type/stream-cgroups.tcl 中添加了如下 case:
1 | test {Blocking XREADGROUP for stream key that has clients blocked on list - avoid endless loop} { |
这里的测试逻辑基本和复现脚本一样,创建 3 个 client 阻塞在 xreadgroup 中,然后用另一个 client 往里面添加了 3 组数据。后面关闭了消费 client,尝试用添加数据的 client 发送 ping 信息,看是否有回复 pong。如果这个 bug 还在的话,发送 ping 也不会有任何回复。
可以在 redis-7.2-rc2 的目录中运行 ./runtest --single unit/type/stream-cgroups 来测试这个新增加 case 的用例组,执行结果如下:
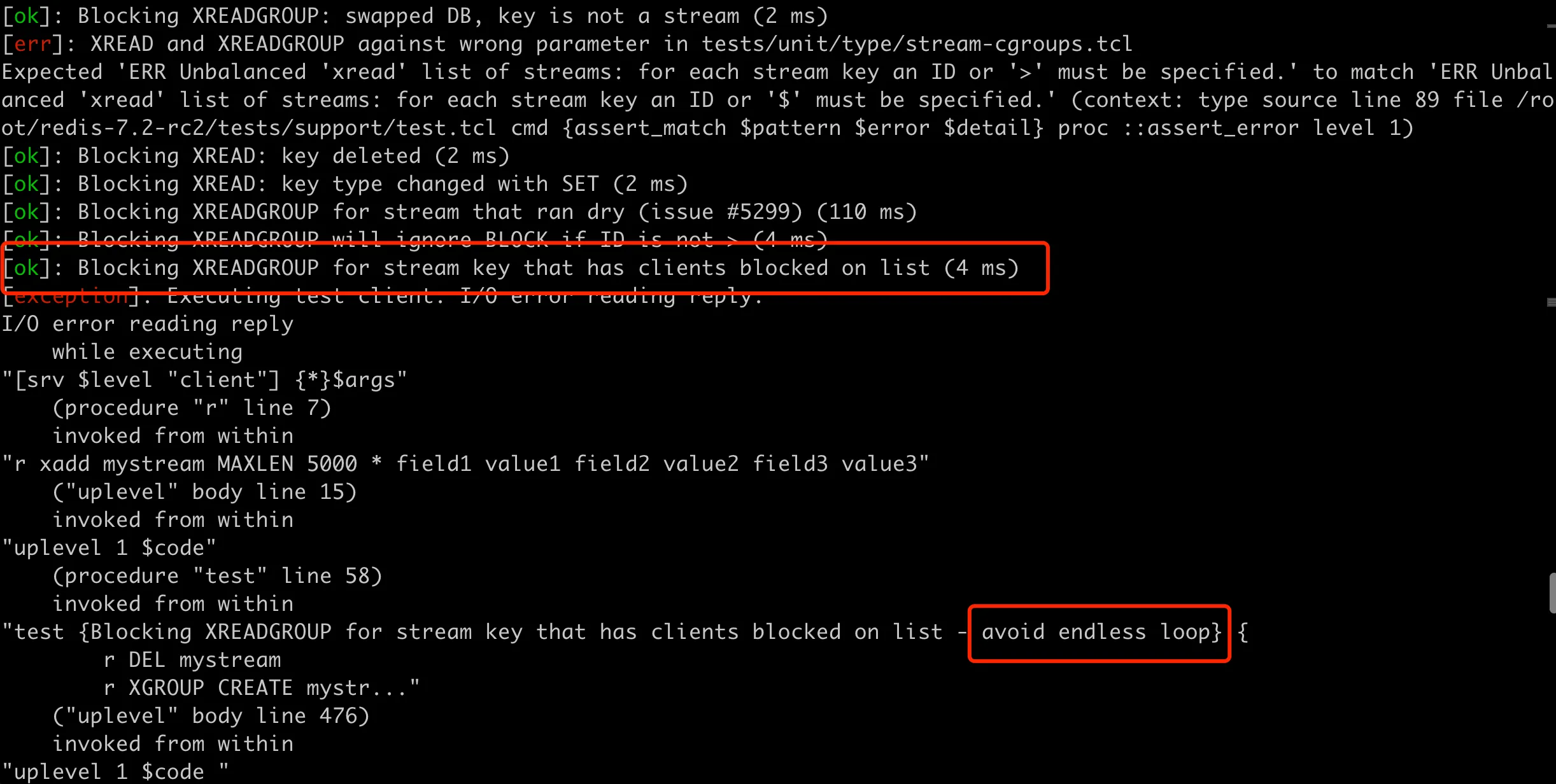
在执行完新加用例的前一组用例后,测试用例就卡住了,然后看到 redis 进程的 cpu 占用也是 100%,说明这个测试用例完全能复现这个问题。这里再补充说一点,在 TCL 测试中,使用的 Redis 二进制文件位于 Redis 源代码目录的 src 子目录下。具体来说,它是通过以下 TCL 脚本中的命令找到的:
1 | set ::redis [file normalize [file join [pwd] ../src/redis-server]] |
它将当前目录(即 tests 目录)的父目录(即 Redis 源代码的根目录)与 src/redis-server 连接起来,形成完整的 Redis 二进制文件的路径。这意味着它使用的是你自己编译的 Redis 版本,而不是系统中可能已经安装的任何版本。

