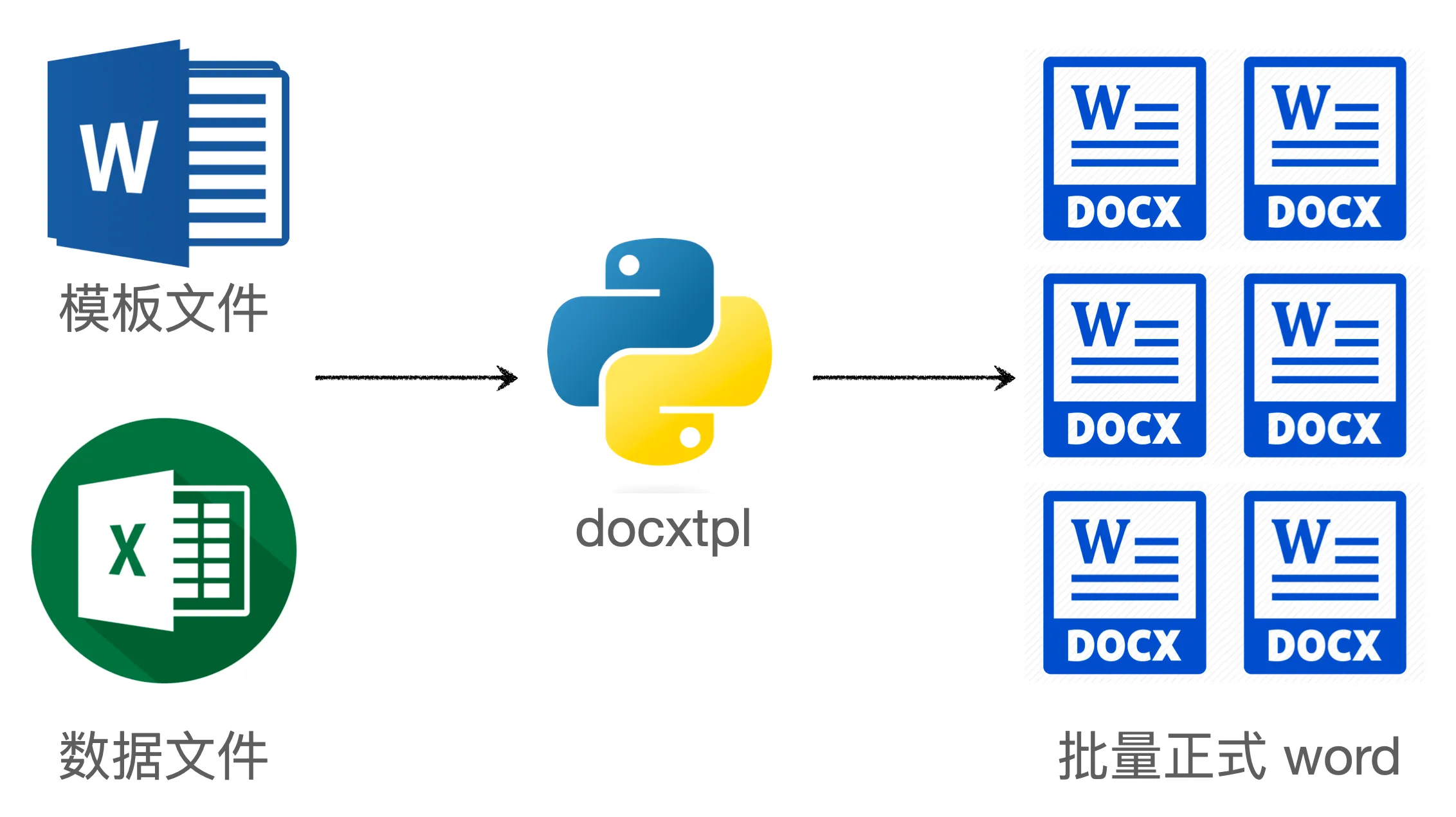
用 Python 模板库 docxtpl 批量制作 Word 文档
在工作中,重复性的劳动往往枯燥乏味。利用 Python 的力量来优化工作流程,可以极大地提高效率,事半功倍。本文将详细介绍如何使用 Python 模板库 docxtpl,在极短的时间内,自动批量生成多份 Word 文档,节省大量手工操作时间,从而解放双手,轻松完成任务。
Update: 用 python 来做对于小白有点难。于是写了个在线工具,支持批量从模板和数据生成 word 文件。在线批量生成 Word 工具地址
事情的起因是这样的,小盛律师 有一批案件,每个当事人的案情都是差不多的,只是当事人的姓名、身份证号、地址等信息不同。小盛律师需要为每个当事人准备 Word 文件,Word 里面除了当事人的个人信息外,其他都是一样的内容。
小盛律师有一份 Excel 文件,里面登记了当事人的信息。按照以前的做法,需要打开 Excel,然后一个个复制信息,贴到每个当事人的 Word 文件中去,最后保存。这样的工作量很大,几十个当事人,每个当事人有好多条数据,每个都要复制粘贴到 word 中指定位置,要复制粘贴几百次。除了体力劳动量大,还很容易出错,律师的工作就是要避免出错,所以这种方法不可取。
**既然是重复的体力劳动,程序肯定就能派上用场,机器重复起来精准又快速。**于是,小盛律师就找到了我,希望我能帮她写一个程序,自动根据 excel 文件里面的数据,批量制作合适的 Word 文件。
简单替换
小盛说自己的需求很简单,读 Excel 拿数据,替换到 Word 里,然后给我 5 分钟时间让我搞定(很有当产品经理的天赋)。于是就习惯性先请教 ChatGPT 老师,让它来写代码。在和它沟通半天,不断细化需求后,终于说服 AI 放弃用 python-docx 这个库了。
因为我在对文本进行替换的同时,需要保存原来文件中的样式。在 Word 的 .docx 文件中,样式和文本是分开存储的。一个段落中的文本可能由多个 Run 对象组成,每个 Run 对象可能有不同的样式,在多个 Run 对象中进行文本替换,并保留格式,会非常复杂。此外,这个库的 API 也比较复杂,还要了解 Run 对象,对使用者不友好。好在我足够机智,提醒 ChatGPT 可以考虑其他库来进行文本替换,于是 ChatGPT 老师就推荐了 docxtpl 这个库。
docxtpl 是一个基于 python-docx 的模板库,它的作者觉得使用 python-docx 这个库来修改 word 太麻烦了,于是借鉴 Jinja2 模板库的思路,开发了 docxtpl 这个库。它的使用方法很简单,主要分三步:
- 在 Word 文档中用
{{ }}包裹起来需要替换的文本; - 用
docxtpl的DocxTemplate类来加载 Word 模板,并且提供替换前、后的内容; - 用
render方法渲染模板。
这个就简单多了,把小盛律师的样本 Word 文件拿来后,简单改成一个符合 Jinja2 语法的模板文件,假设某一个字段需要从表格的第 B 列获取,就直接写成 {{ B }}。比如下面的内容:
贵院受理的
{{ A }}与{{ B }}租赁合同纠纷一案
这里的模板变量可以在 Word 里面指定样式,比如字体、字号、颜色等。然后用 pandas 读取 Excel 里面的 A 和 B 列,再用 docxtpl 能很快执行文本替换,同时保留格式,核心代码很简单,如下:
1 | def generate_word_files(excel_filepath, word_template_filepath, output_dir): |
日期特殊处理
写好代码后,执行替换后,发现有部分字段替换后的值不对。在 Excel 中有一列看着是一个日期 ‘2023/04/12’,但是替换到 Word 里面后成为了 1970.1.1,这是怎么回事呢?
打印了下 pandas 读取到的值,发现是一个整数,而不是字符串。这是因为 Excel 中的日期是以 1900 年 1 月 1 日为基准的,所以 2023/04/12 在 Excel 中的值是 44397,这个值是 Excel 用来表示日期的天数,而不是字符串。知道这点后,只需要把这个天数加上开始日期就行,这里 ChatGPT 给的代码是:
1 | def excel_date_to_datetime(excel_date): |
这里开始日期变成了 1899.12.30,这是因为 Excel 日期系统中存在一个错误:它把 1900 年当作闰年,实际上它不是。因此,1900 年 2 月有 29 天在 Excel 日期系统里。为了解决这个问题,一种通用的做法是从 1899 年 12 月 30 日开始计算,这样可以在计算日期时跳过这个“多出来”的一天(即 1900 年 2 月 29 日)。ChatGPT 老师还是高,自动帮我避雷了。
关于 Excel 的 date 日期格式,可以参考这两篇文章:
复杂替换
只是简单替换当然没啥难度,可是工作中也会遇到一些更复杂的替换场景。
计算后的数据
这不,小盛律师的文件中有一些计算公式,需要填一些计算后的值,比如内容:
被告的损失为:
{{ Y }}×120% = ??? 元
这里 Excel 的 Y 列是损失费用,但是需要乘以一个系数,填到 Word 里面。Excel 中并没有这个计算后的数据,于是可以在代码里计算好结果,然后用 {{ Y_calculated }} 包裹起来,替换到 Word 里面。计算的代码部分也很简单,如下:
1 | elif col_label == 'Y': |
其实这里要是支持在 Jinja2 模板中进行计算就更好了,比如模板可以写成 {{ Y | calculate }},这样就可以在模板中直接计算了。但是 docxtpl 并不支持这样的语法,所以只能在代码中计算好结果,然后替换到 Word 里面。
条件语句
小盛的文档中还需要根据 Excel 数据动态显示部分内容,比如费用字段非空时才显示相关文字。这可以通过 docxtpl 支持的条件语句 jinja2 语法来实现。
1 | 一、{% if S != 0 %}判令被告向原告支付租金{{ S }}元; |
因为在 Word 里面有列表,为了保持列表格式和数字序号,这里的 {% endif %} 都需要放在合适的位置才行。
除了前面的简单替换,条件语句等复杂替换,docxtpl 还支持循环语句、表格、设置富文本等,可以参考它的文档。
总结
用 100 多行代码,就能实现一个批量制作 Word 文档的程序,这是 Python 的强大之处。相比人工一个个复制粘贴,程序速度飞快,1 分钟就能处理成百上千的文档,而且还不容易出错。对于没有编程功底的人来说,借助 ChatGPT 老师的力量,也能完成这样的任务。这就是目前 AI 的一大用处,让每个人都能快速上手专业领域以外的知识,特别是编程领域。

