C++ 内存问题排查:创建 Zip 压缩包,解压后内容错乱
在日常的 C++ 后台开发工作中,很少会动态生成 Zip 包,所以对 C++ 的 libzip 并不熟悉。最近刚好有个场景,需要将后台生成的一份数据压缩为一个 Zip 包以便下载。这里其实之前已经有生成 Zip 包的代码,只是需要在 Zip 包里面增加一个文件。本来是一个简单的需求,但是实现中遇到了一个诡异的问题,解压生成的 Zip 包里,里面文件开头部分有错乱。
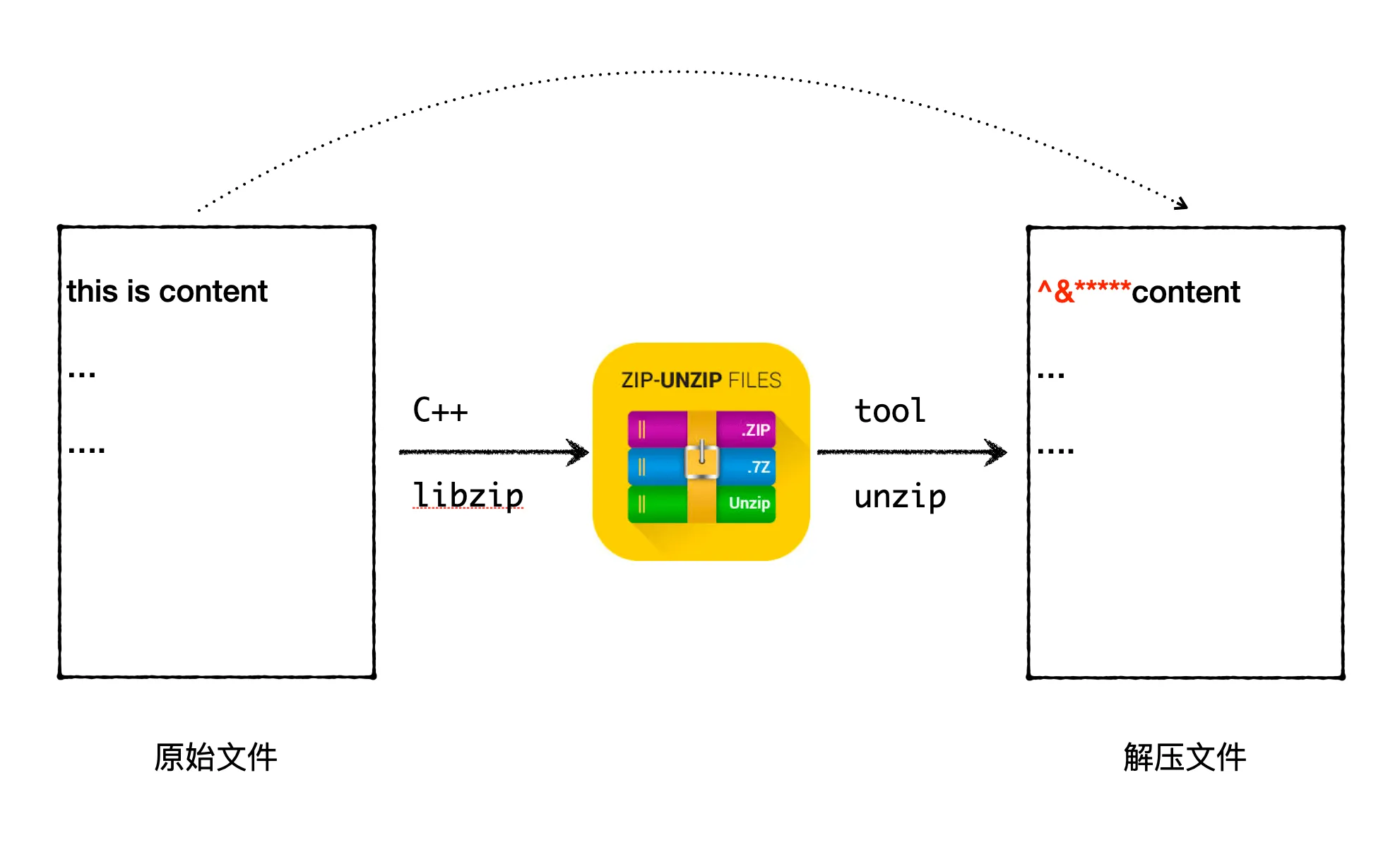
问题的排查过程中,绕了一些弯路,最后发现是 C++ 的内存问题导致的,这里记录下问题的排查和修复,以及对第三方库 Zip 的源码解读。对 C++ 不熟悉的读者也可以放心阅读,来感受下 C++ 的内存问题有多难调试。
问题复现
业务中是通过一个 RPC 请求拿到了部分数据,然后把这些数据进行处理后,生成一个 Zip 包,最后返回给前端。前端解码 zip 包后发现部分内容乱码,不符合事先约定的协议内容。由于是个必现的问题,比较好定位,直接加日志调试,发现 RPC 拿回来的数据并没有问题,但是生成 Zip 包之后,里面的内容就会多了些乱码内容。
这里为了能够方便地复现问题,直接把生成 Zip 包部分抽离出来,写了一个简单的示例,核心代码如下:
1 | zip* archive = zip_open(tmpFile, ZIP_CREATE | ZIP_TRUNCATE, &error); |
完整代码在 Gist 上。逻辑比较简单,将代码里一段 string 放进去一个文件,然后添加到 tar 包中去。压缩后再用 unzip 工具来尝试解压 tar 包,打印文件内容。注意需要在系统中安装 libzip 库。

文件原来的内容是(<?xml version="1.0" encoding="utf-8" standalone="no"?>demo,但是上面的运行结果可以看到,输出的内容直接乱码了。为了能够看到这里解压后的文件到底是什么内容,这里直接用 hexdump 来查看文件的内容:
1 | $ hexdump -C file1_temp.xhtml |
发现整个内容和输入字符串完全不一样,并且错乱的内容也很奇怪,没有任何地方会生成这些错乱内容。这时候最好是用 GDB 调试,或者直接去看 zip 库的文档或者源码,看看这里是哪里出了问题。
问题排查
不过自从有了 ChatGPT,遇见问题的第一反应就是丢给 ChatGPT 来看看。先把这部分写 zip 包的代码直接丢给 ChatGPT,然后提问“这样往里面添加文件是合理的吗?”。ChatGPT 认为这段代码基本是合理的,没有什么错误使用方法。没关系,继续追问,这次提示词提供了更多细节,参考ChatGPT Prompt 最佳指南二:提供参考文本,如下:
我用上面的代码,生成的 zip 文件,用 unzip 解压缩后,file1_temp.xhtml 文件的内容为啥不等于 htmltemlate,在前面部分有乱码的内容。
hexdump -C file1_temp.xhtml
00000000 00 dc 14 b3 f8 55 00 00 50 a2 2a a1 07 7f 00 00 |.....U..P.*.....|
00000010 00 a2 2a a1 07 7f 00 00 c4 02 00 00 00 04 00 00 |..*.............|
ChatGPT 果真是江湖百晓通,一下子就给出了一个看起来正确的答案:

按照 ChatGPT 的回答,这里循环 FileInfos 执行完后,zip_close 被调用之前,item.htmltemlate 内存里的内容可能已经被释放了,所以这里添加的内容不对。这个结论很容易验证是不是靠谱,直接改下这行代码:
1 | for (const auto &item : FileInfos) { |
把这里改成引用(其实本来也应该用引用,这样可以减少拷贝操作),重新跑下,发现问题果然解决了。
GDB 验证
定位到了问题后,再回过头来,用 GDB 验证下输出乱码的程序执行过程。这里 libzip 的实现还是比较复杂的,不过最关键在于 zip_source_buffer 和 zip_close 两个函数。按照前面的代码,可以合理猜测 zip_source_buffer 添加 htmltemlate 的时候,没有复制内存里的内容,只是引用了地址。然后在 zip_close 的时候,才去读取这个 htmltemlate 里的内容。可是这时候 htmltemlate 内存已经被释放了,里面的内容是未定义的,可能是乱码,也可能还是旧的值。
由于没有那么多精力花在读 libzip 源码上,为了快速验证这里的猜想,可以用 GDB 一步步调试。为了用 GDB 能看到 libzip 库的调试符号,下载 libzip 的源码,用 -g 重新编译。
添加调试符号
1 | $ git clone https://github.com/nih-at/libzip.git |
然后重新编译前面的代码,这里需要指定 libzip 的头文件和库文件的路径。
1 | $ g++ zip_test.cpp -o zip_test -L/root/libzip/build/install/lib -lzip -Wl,-rpath=/root/libzip/build/install/lib -g -fno-omit-frame-pointer |
可以看到这里二进制已经用了重新编译的带 debug 信息的 libzip 了。
定位读内存位置
这里我们想验证的就是,zip_close 的时候,才从 htmltemlate 里面读内容创建压缩包。刚开始,想着简单看下 zip_close 的代码,确认下在哪个地方读,然后在相应地方打断点。但是发现这里函数调用一层层下去,段时间很难找到一个合适的地方打断点。
这里走了一些弯路,想着用一些工具能找到 zip_close 的函数调用栈,从而能快速找到核心的函数。
- 尝试用 ebpf 的 stackcount 来跟踪下函数调用栈,
stackcount -p $(pgrep zip_test) 'zip_*',结果一直报错:Failed to attach BPF program b’trace_count’ to kprobe , it’s not traceable (either non-existing, inlined, or marked as “notrace”);最后也没有找到解决办法(谁知道原因的可以留言给我)。 - 用
Valgrind的callgrind工具,valgrind --tool=callgrind ./zip_test来生成调用关系,然后再用gprof2dot和dot进行可视化,这里也确实看到了一些执行流程,但是并没有 zip_source_buffer 函数的。
既然很难理清楚这里的代码,就直接从内存地址入手。我们知道 GDB 可以用 rwatch 监控某个内存地址的读操作,所以可以在 zip_close 结束前,rwatch htmltemlate 的内存地址,看看到底是什么时候会读这里的内容。
整体 GDB 调试思路如下:首先在 zip_source_buffer 和 zip_close 所在行以及最后退出前设置断点,然后执行到 zip_source_buffer 断点,然后打印 htmltemlate 的内存地址,并设置 rwatch,接着 continue 看看这里的内存地址在哪里被读。
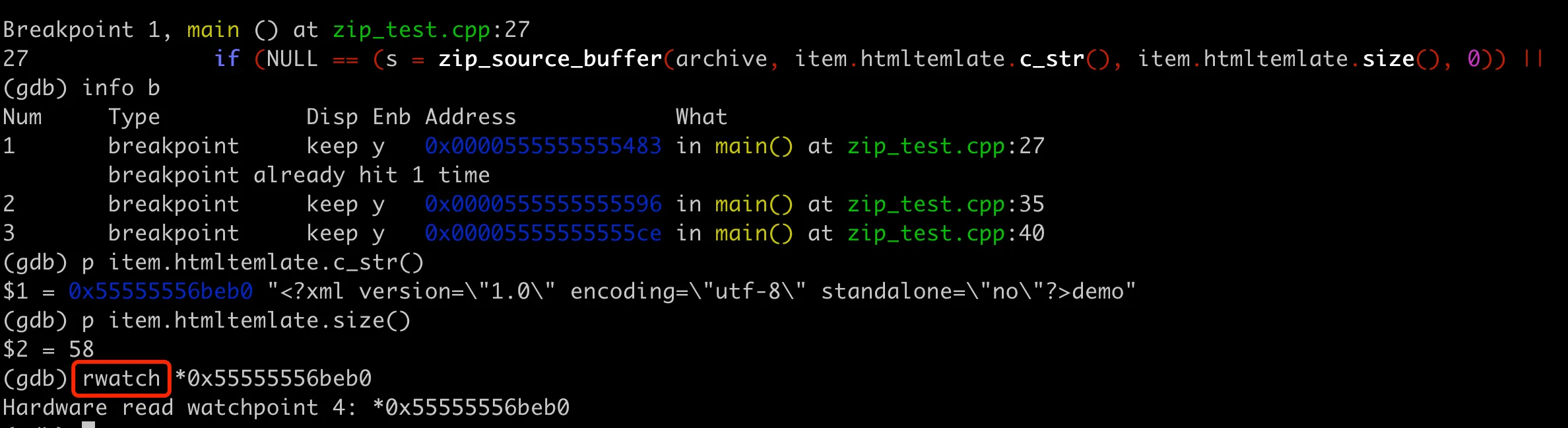
上面图片执行到 zip_source_buffer 断点,打印 htmltemlate 的内存地址,然后设置 rwatch,接着 continue 看看这里的内存地址在哪里被读。
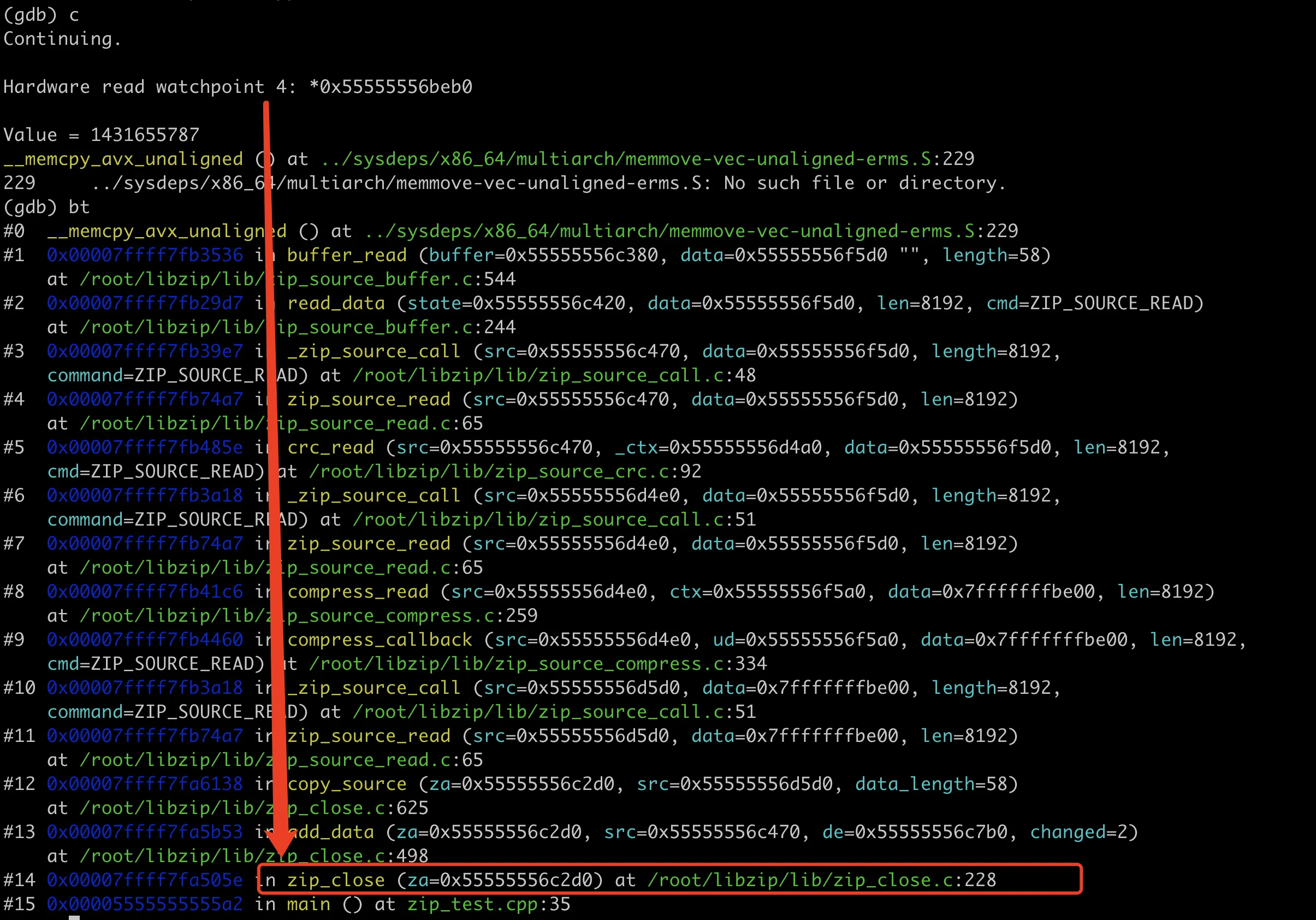
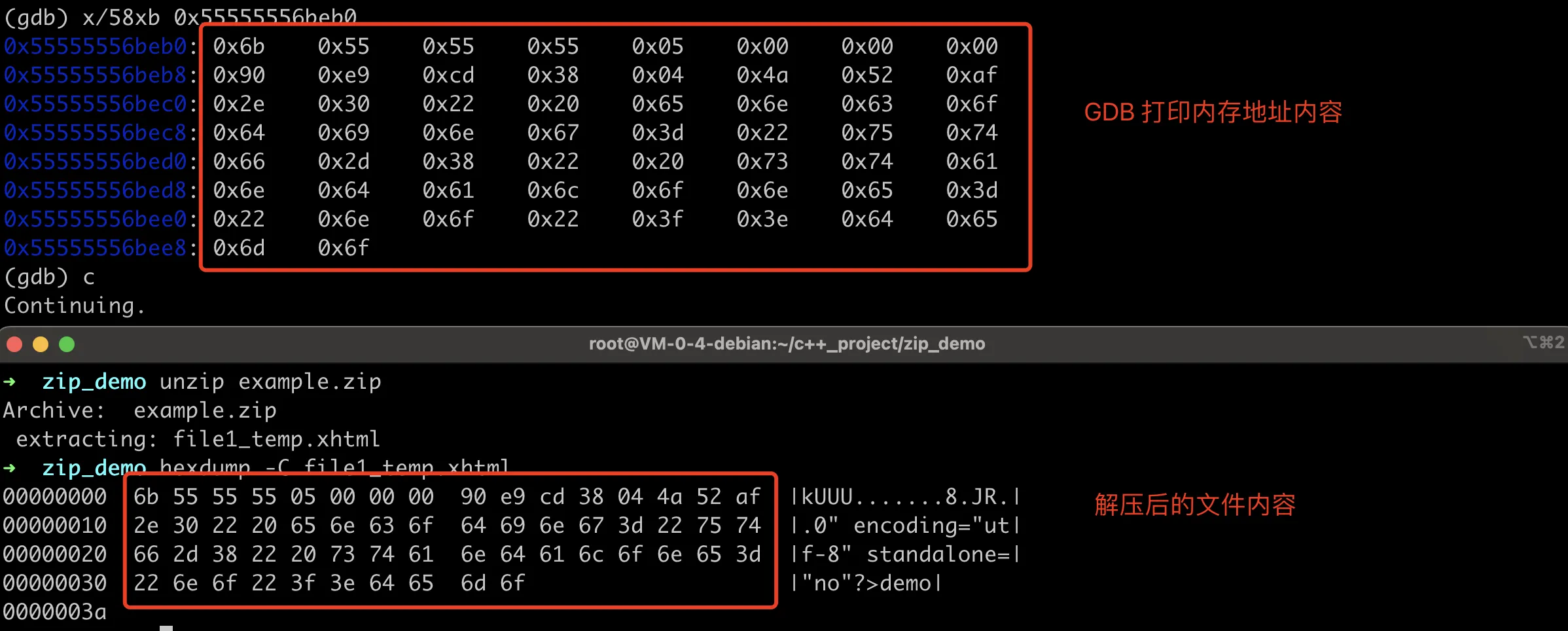
到这里就验证了前面的猜想,zip_source_buffer 里面并没有读 htmltemlate 里面的内容,在 zip_close 的时候才从这里读内容创建压缩包。这里的内存地址是 0x55555556beb0,这时候打印里面的内容,应该和最后生成的乱码内容一致,如下图所示:
总结
这个问题遇到的人还有不少,比如 Stack Overflow 上的这两个问题:
- libzip with zip_source_buffer causes data corruption and/or segfaults
- Add multiple files from buffers to ZIP archive using libzip
其实 libzip 的官方文档都写的有问题,zip_source_buffer 官方文档 如下:
The functions zip_source_buffer() and zip_source_buffer_create() create a zip source from the buffer data of size len. If freep is non-zero, the buffer will be freed when it is no longer needed. data must remain valid for the lifetime of the created source.
文档说 data 必须和 source 的生命周期保持一致,其实并不准确,这里必须要保证数据在 zip_close 调用前不会被销毁。在其他语言,基本不会有这么奇葩的接口设计,但是在 C 里面,这种设计还是不少。各种比较经典的 C 库里面,都会有这种设计。

