C++ string 意外修改之深入理解 COW 写时复制
最近工作中有小伙伴遇到了一个奇怪的问题,C++中复制一个 string 后,更改复制后的内容,结果原值也被改了。对于不是很熟悉 C++ 的小伙伴来说,这就有点“见鬼”了。本文接下来从问题的简单复现,到背后的原理,以及 C++ 标准的变更,来一起深入讨论这个问题。
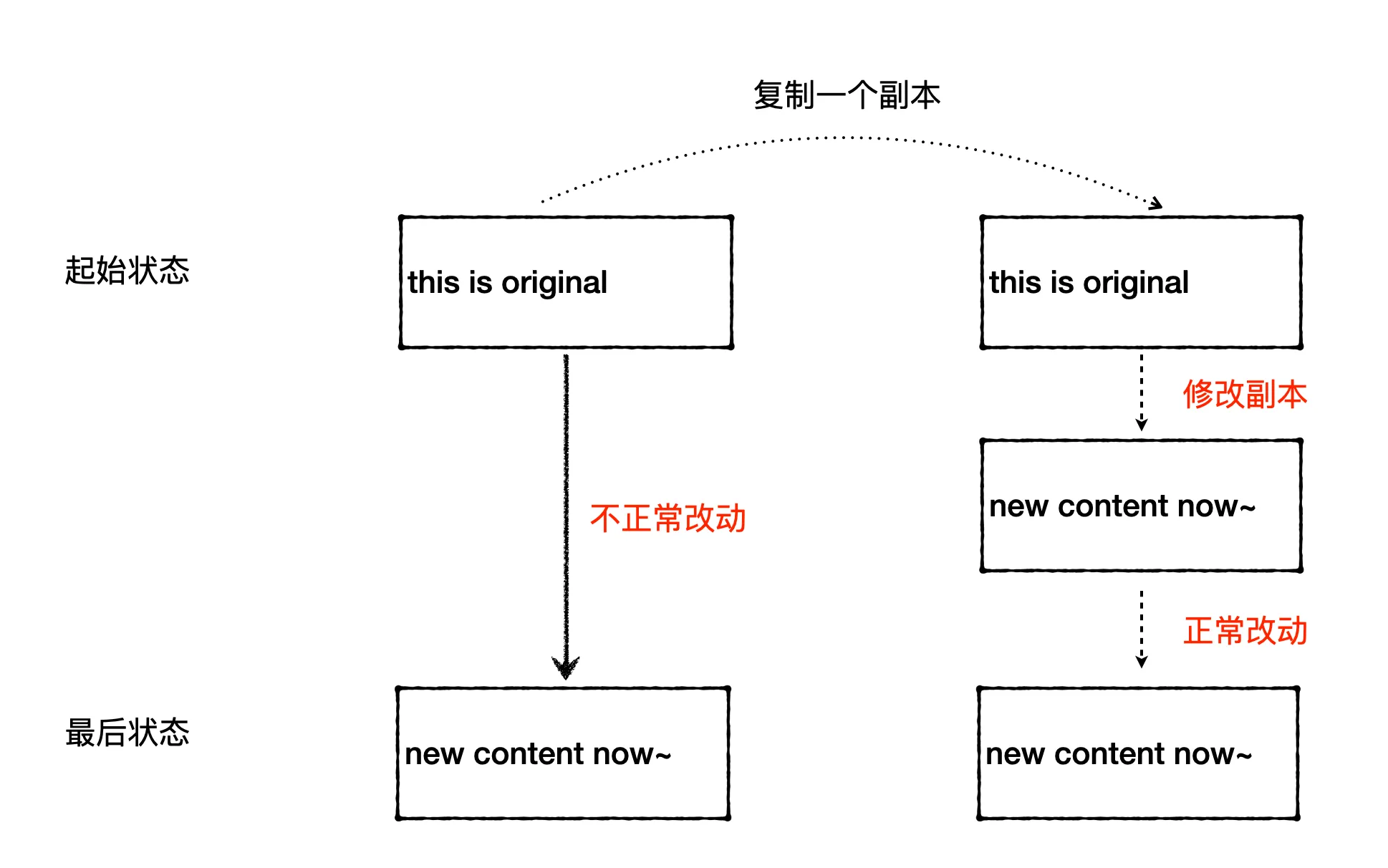
问题复现
这里直接给出可以稳定复现的代码,定义一个字符串 original,然后复制一份,接着调用一个函数来修改副本字符串的内容。业务中的函数比较复杂,这里复现用了一个简单的函数,只是修改 copy 的第一个字符。在修改副本 copy 前后,打印两个字符串的内容和内存地址。往下看之前,你可以先猜猜下面代码的输出。
1 |
|
在业务生产环境上,用 G++ 4.9.3 编译上面的代码,运行结果如下:
1 | Original: Hello, World!, address: 0x186c028 |
可以看到在修改副本后,原始字符串的内容也发生了变化。还有一点奇怪的是,原始字符串和副本的内存地址始终是一样的。这究竟是怎么回事呢?要解决这个疑问,我们需要先了解下 C++ string 的实现机制。
字符串写时复制
在低版本的 GCC/G++(5 版本以下) 中,string 类的实现采用了写时复制(Copy-On-Write,简称 COW)机制。当一个字符串对象被复制时,它并不立即复制整个字符串数据,而是与原始字符串共享相同的数据。只有在字符串的一部分被修改时(即“写入”时),才会创建数据的真实副本。COW 的优点在于它可以大幅度减少不必要的数据复制,特别是在字符串对象频繁被复制但很少被修改的场景下。
COW 的一般实现方式:
- 引用计数:string 对象内部通常包含一个指向字符串数据的指针和一个引用计数。这个引用计数表示有多少个 string 对象共享相同的数据。
- 复制时共享:当一个 string 对象被复制时,它会简单地复制指向数据的指针和引用计数,而不是数据本身。复制后的字符串对象和原始对象共享相同的数据,并且引用计数增加。
- 写入时复制:如果任何一个 string 对象试图修改共享的数据,它会首先检查引用计数。如果引用计数大于 1,表示数据被多个对象共享。在这种情况下,修改操作会先创建数据的一个新副本(即“复制”),然后对这个新副本进行修改。引用计数随后更新以反映共享情况的变化。
COW 实现需要仔细管理内存分配和释放,以及引用计数的增加和减少,确保数据的正确性和避免内存泄漏。现在回到上面的复现代码,我们更改了复制后的字符串,但是从输出结果来看,并没有触发 COW 中的写复制,因为前后地址还是一样的。这是为什么呢?先来看 ModifyStringInplace 的实现,string 的 c_str() 方法返回一个指向常量字符数组的指针,设计上这里是只读的,不应该通过这个指针来修改字符串的内容。
但是上面的实现中,用 const_cast 移除了对象的 const(常量)属性,然后对内存上的数据进行了修改。通过指针直接修改底层数据的操作不会被 string 的内部机制(包括 COW)所识别到,因为它跳过了string 对外暴露接口的状态检查。如果把上面代码稍微改动下,用[]来修改字符串的内容,str[0] = 'X',那么就会触发 COW 的写复制,从而导致原始字符串的内容不会被修改。输出如下:
1 | Original: Hello, World!, address: 0x607028 |
其实用 [] 只读取字符串中某位的内容,也会触发写时复制。比如下面的代码:
1 | { |
在低版本 G++ 上编译运行,可以看到用 operator[] 读取字符串后,复制内容的地址也发生了变化(从 0x21f2028 到 0x21f2058),如下:
1 | Original: Hello, World!, address: 0x21f2028 |
这是因为 operator[] 返回的是对字符的引用,可以通过这个引用来修改字符串的内容,这个接口有”修改”字符串的语义,所以会触发写时复制。虽然上面代码实际并没有修改,但是 COW 机制本身很难感知到这里没修改,这里改成用迭代器 begin()/end() 也会有同样的问题。
写时复制的缺点
用 COW 实现 string 的好处是可以减少不必要的数据复制,但是它也有一些缺点。先看一个简单示例,参考 Legality of COW std::string implementation in C++11 下的一个回答。
1 | int main() { |
在 COW 机制下,当创建 copy 作为 s 的副本时,s 和 copy 实际上共享相同的底层数据,此时,p 指向的是这个共享数据的地址。然后 operator[] 导致 s 会触发重新分配内存,这时 p 对应内存部分的引用只有 copy 了。当 copy 的生命周期结束并被销毁,p 就成为悬空指针(dangling pointer)。后面访问悬空指针所指向的内存,这是未定义行为(undefined behavior),可能导致程序崩溃或者输出不可预测的结果。如果不使用 COW 机制,这里就不会有这个问题。
不过,就算是 C++11 及以后的标准中,标准库中的 std::string 不再使用 COW 机制了,保留指向字符串内部数据的指针仍然是一种不安全的做法,因为任何修改字符串的操作都可能导致重新分配内部缓冲区,从而使得之前的指针或引用变得无效。
多线程问题
COW 写时复制除了带来上面这些潜在 bug 外,还有一个比较重要的缺陷,就是不适合多线程环境,详细可以阅读 Concurrency Modifications to Basic String 这篇文章,COW 写时复制带来的问题就是:
The current definition of basic_string allows only very limited concurrent access to strings. Such limited concurrency will inhibit performance in multi-threaded applications.
举个简单的例子,如下对于原始字符串,这里先复制了几个副本,然后分别在不同的线程中运行。在 COW 的实现中,必须保证这里各个线程操作独立副本字符串是线程安全的,也就要求COW 的实现中,字符串中共享内存的引用计数必须是原子操作。原子操作本身需要开销,而且在多线程环境下,多个 CPU 对同一个地址的原子操作开销更大。如果不用 COW 实现,本来是可以避免这部分开销的。
1 | // StringOperations 这里修改字符串 |
当然如果是不同线程之间共享同一个 string 对象,那么不管是不是写时复制,这里都要进行线程同步,才能保证线程安全,这里不做讨论了。
C++11 标准改进
鉴于上面提到的写时复制的缺点,GCC 编译器,从 5.1 开始不再用 COW 实现 string,可以参考 Dual ABI:
In the GCC 5.1 release libstdc++ introduced a new library ABI that includes new implementations of string and std::list. These changes were necessary to conform to the 2011 C++ standard which forbids Copy-On-Write strings and requires lists to keep track of their size.
这里主要是因为 C++11 标准做了更改,21.4.1 basic_string general requirements 中有这样的描述:
References, pointers, and iterators referring to the elements of a basic_string sequence may be invalidated by the following uses of that basic_string object:
- as an argument to any standard library function taking a reference to non-const basic_string as an argument.
- Calling non-const member functions, except operator[], at, front, back, begin, rbegin, end, and rend.
如果是 COW 实现的字符串,如前面的例子,只是调用 non-const operator[] 也会导致写时复制,从而导致原始字符串的引用失效。
高版本字符串优化
高版本的 GCC,特别是遵循 C++11 标准和之后版本的实现,对 std::string 的实现进行了显著的修改,主要是为了提高性能和保证线程安全。高版本的 GCC 放弃了 COW,同时对小字符串做了优化(SSO)。当字符串足够短以至于可以直接存储在 std::string 对象的内部缓冲区中时,它就会使用这个内部缓冲区(在栈中),而不是分配单独的堆内存。这可以减少内存分配的开销,并提高访问小字符串时的性能。
可以用下面代码来验证下:
1 |
|
用高版本编译运行,可以看到输出类似下面结果:
1 | 0x7ffcb9ff22d0:0x7ffcb9ff22e0 |
对于比较短的字符串,地址和变量本身地址十分接近,说明就在栈上。而对于比较长的字符串,地址和变量本身地址相差很大,说明是在堆上分配的。对于较长的字符串,高版本的 GCC 实现了更有效的动态内存分配和管理策略,包括避免不必要的内存重新分配,以及在增长字符串时采用增量或倍增的容量策略,以减少内存分配次数和提高内存利用率。

