Bazel 依赖缺失导致的 C++ 进程 coredump 问题分析
最近在项目中遇到了一个奇怪的 coredump 问题,排查过程并不顺利。经过不断分析,找到了一个复现的步骤,经过合理猜测和谨慎验证,最终才定位到原因。
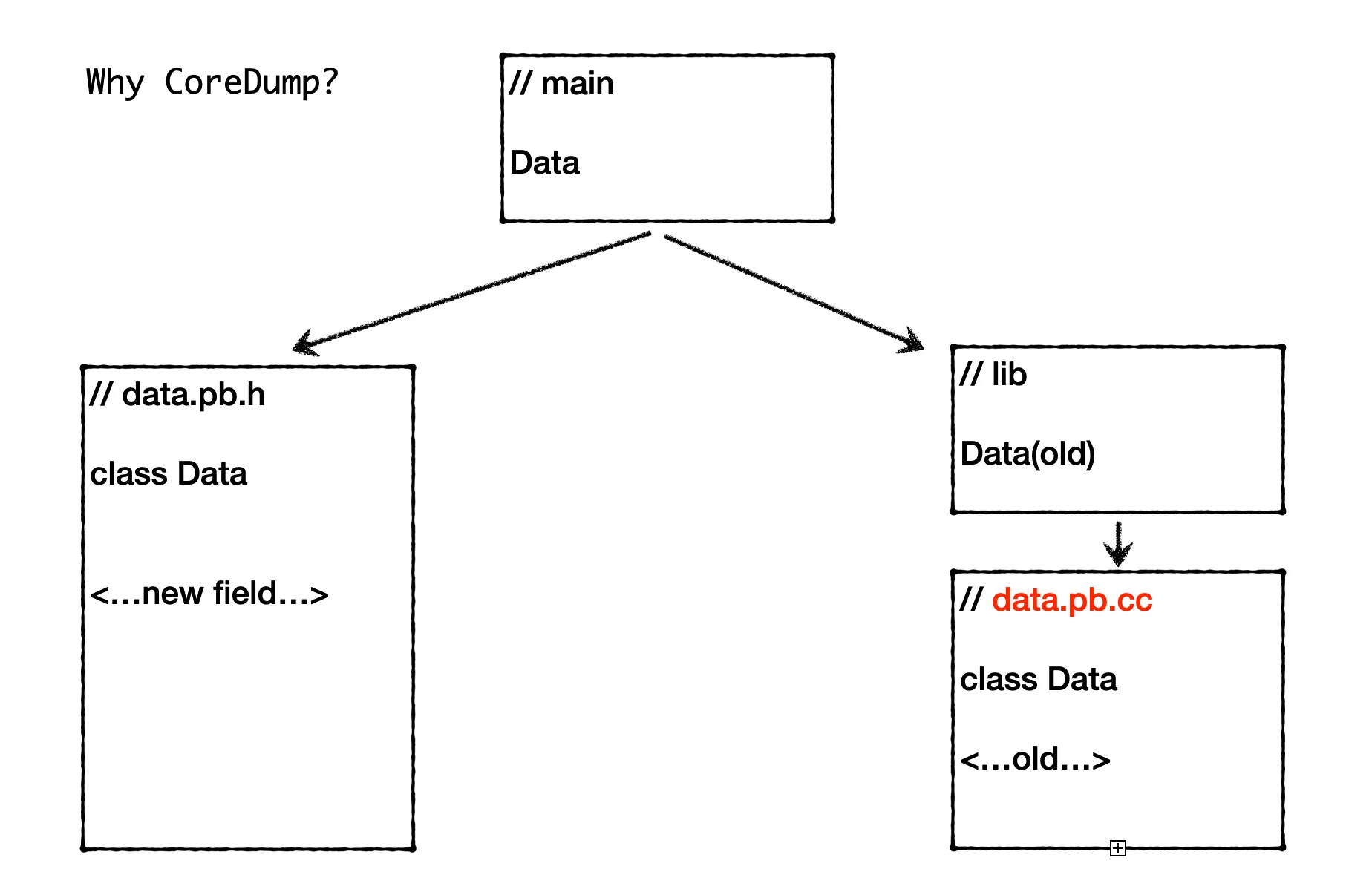
复盘下来,发现这类 coredump 问题确实比较罕见,排查起来也不是很容易。只有项目代码编译依赖管理不是很合理的时候,才可能出现。另外,在复盘过程中,对这里的 coredump 以及 C++ 对象内存分布也有了更多理解。于是整理一篇文章,如有错误,欢迎指正。
问题描述
先说下后台服务的基本架构,最外面是 cgi 层处理 nginx 转发的 http 请求,然后具体业务在中间的逻辑层处理。逻辑层是微服务框架,不同服务之间通过 RPC 调用,用的类似 grpc。
某次变更,在服务 A 的 service.proto 文件中,对某个 rpc 请求参数增加了一个字段(比如下面的 age):
1 | service Greeter { |
然后增加了这个字段的相关逻辑,随后编译上线了该模块。我们知道在微服务架构中,经常有多个服务共用同一个 proto 对象。如果要修改 proto 的话,一般都是增加字段,这样对调用方和被调用方都是兼容的。这里服务 A 上线后,用新的 proto,其他用到这个 proto 的服务在重新编译前都会用老的版本,这样不会有问题。其实严格来说这样也是可能有问题的,之前踩过坑,主要是 Merge 的兼容问题,可以参考我之前的文章 Protobuf 序列化消息引起的存储失败问题分析。
正常来说,如果其他服务想更新 proto,只需要重新编译就能用到新的 proto,肯定不会有问题。不过这次就出问题了,服务 A 的 proto 增加字段上线后,其他通过 client 调用 A 的服务,只要重新编译上线,就会 coredump。
复现步骤
这里看了现网的 core 文件,没有发现特别有用的信息(通过 core 文件定位问题的功力还是不太够)。就想着先看看能不能稳定复现一下,毕竟对于 core 的问题,如果能稳定复现,问题基本就解决一大半了。好在通过一番尝试,找到了一个可以稳定复现的步骤。
老版本 proto
创建一个最初版本的 proto 文件,这里就叫 data.proto,并用 protoc 编译为 data.pb.h 和 data.pb.cc,其中 proto 文件内容如下:
1 | syntax = "proto3"; |
编译命令也很简单,protoc --cpp_out=. data.proto 即可。此外,还有一个 libdata.cpp 文件,定义了一个 processData 函数,使用了上面的 proto 对象。这个cpp文件被编译进了一个公共库 libdata.so:
1 | // libdata.cpp |
编译为动态库的命令如下:
1 | g++ -fPIC -shared libdata.cpp data.pb.cc -o libdata.so -lprotobuf -g |
这样我们就有了 libdata.so 动态库文件了。
更新 proto
接下来我们修改下 data.proto 文件,增加一个 repeated 字段,如下:
1 | syntax = "proto3"; |
然后重新用 protoc 编译 proto 文件。接着写我们的主程序,就叫 main.cpp,只是简单调用前面 libdata.so 库中的函数,内容如下:
1 | // main.cpp |
然后编译链接我们的主程序,命令如下:
1 | g++ main.cpp -o main -L. -lprotobuf -Wl,-rpath,. -ldata -g |
这里需要注意的是,我们的 libdata.so 库文件在当前目录,所以需要用 -Wl,-rpath,. 指定下动态库的搜索路径。然后运行程序,就会必现 coredump,如下图:
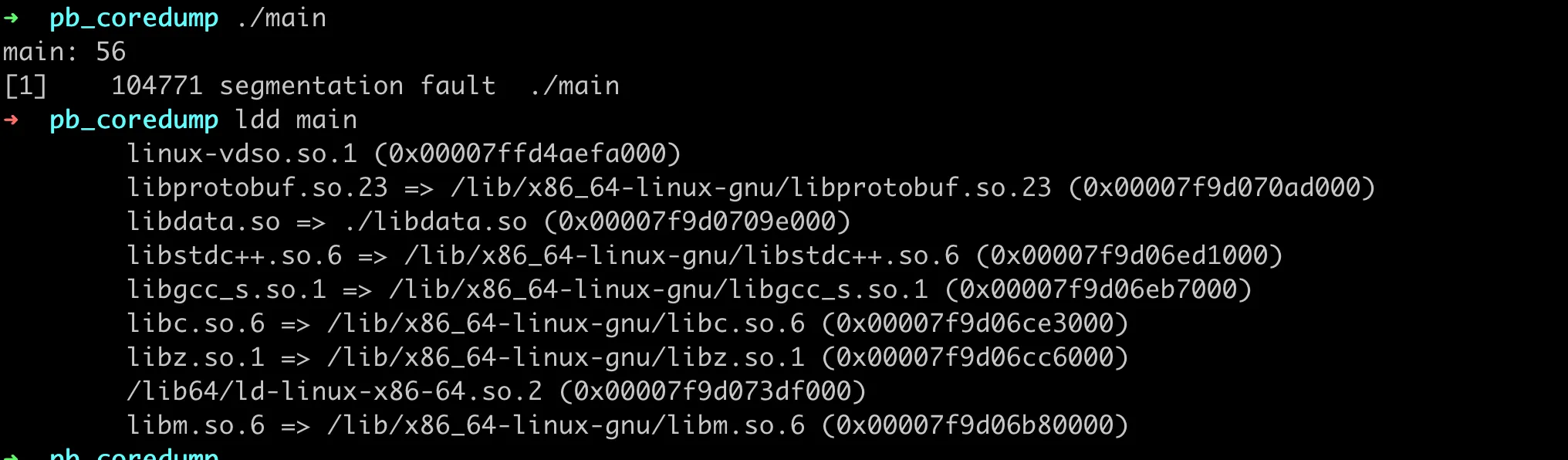
深入分析
大多时候,能稳定复现 coredump,基本就很容易找到 coredump 的原因了。用 -g 编译带上调试信息,然后就可以用 gdb 跟踪排查。因为在 set_message 这里会 core 掉,所以我们在这里打个断点,先查看下 req 对象的内存布局,然后执行到 core,查看堆栈即可。整体的结果如下图:
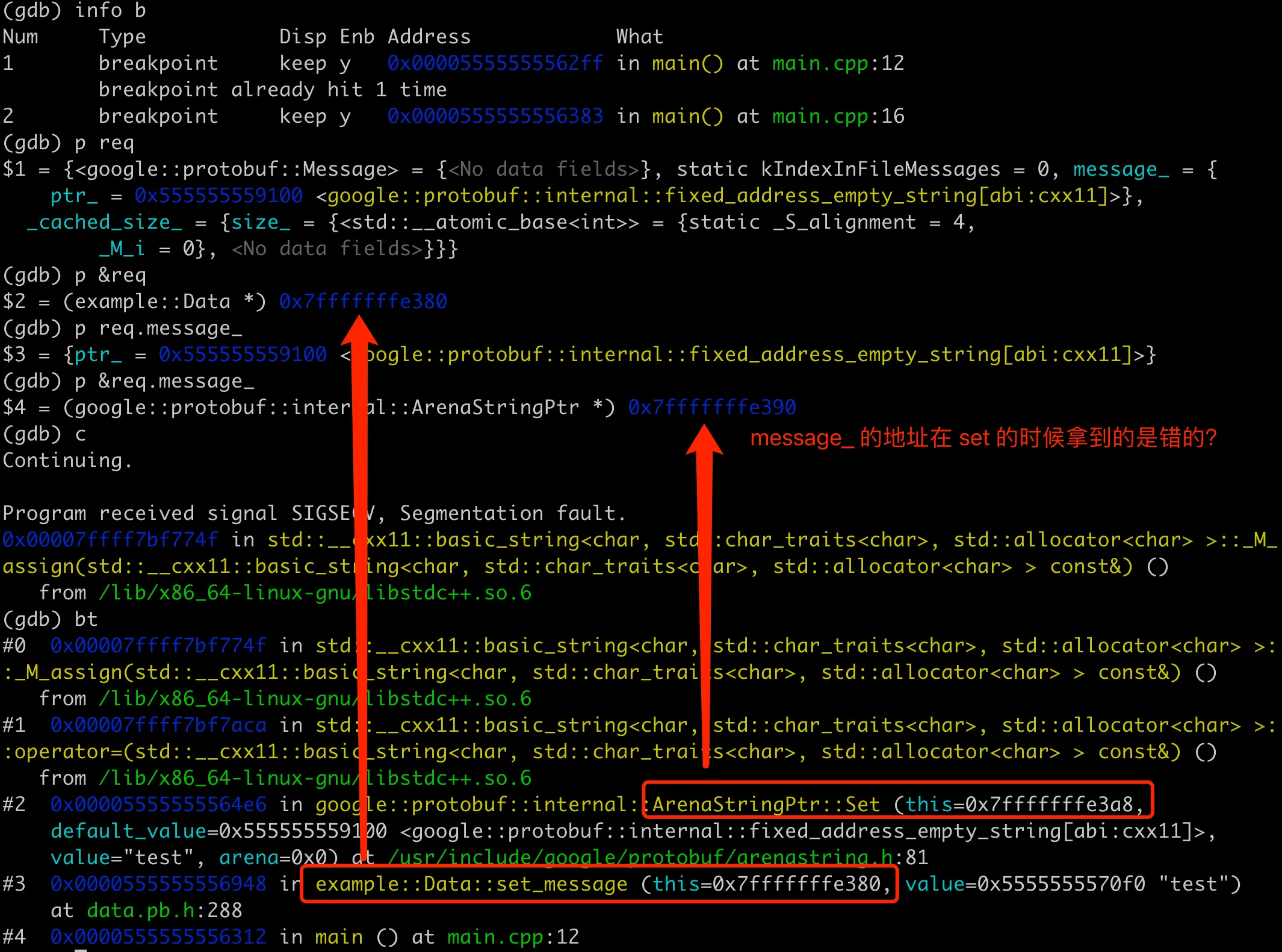
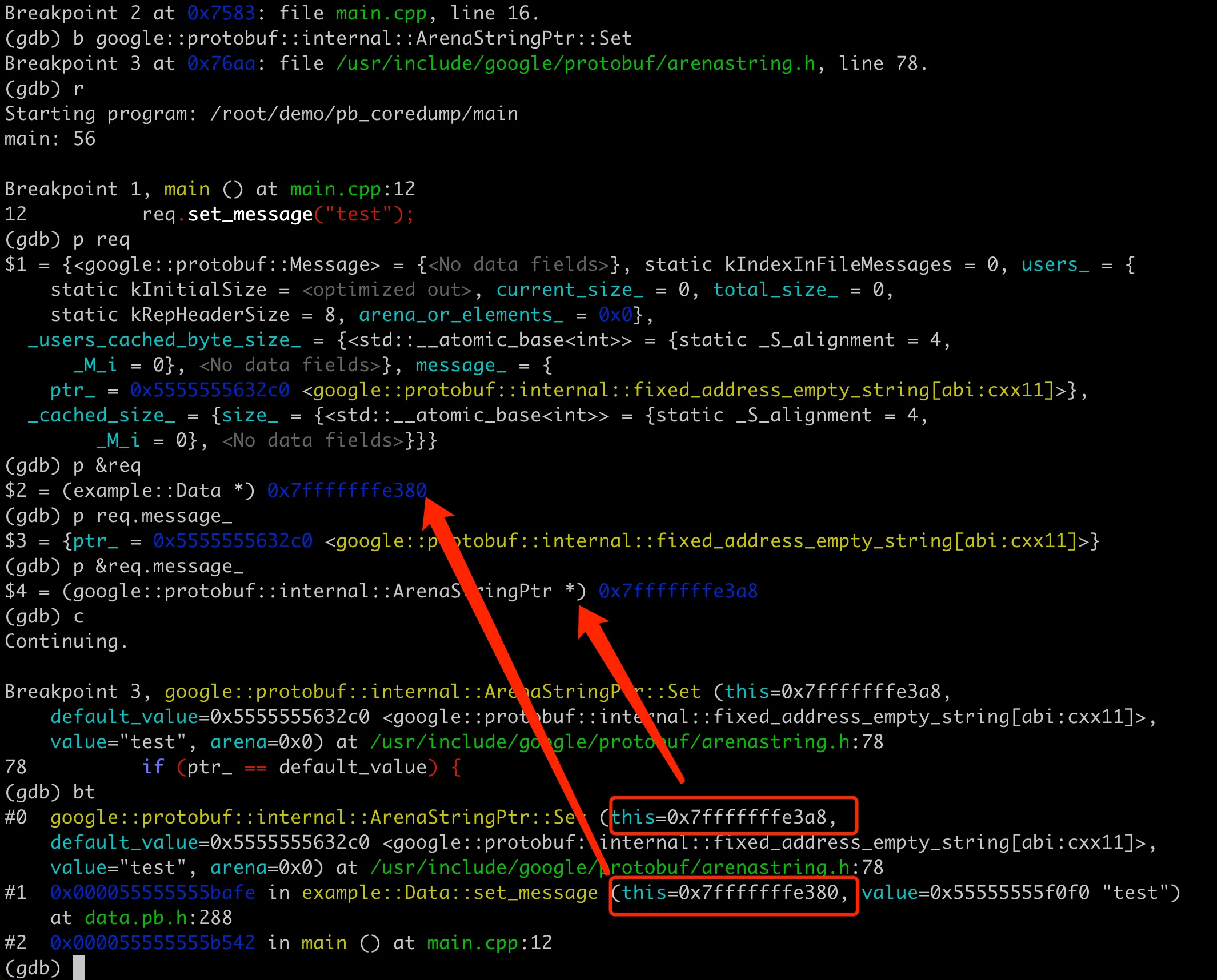
先用 GDB 打印 req 的内容,比较奇怪的是这里只有 message 字段,并没有看到 users 字段。然后执行到 req.set_message("test"); 这里,从 coredump 的堆栈来看,set_message 这里调用 this 和 value 地址都没问题。但是底层 ArenaStringPtr::Set 的时候,this 的地址是 0x7fffffffe3a8,这个感觉应该是 message 字段的地址。从前面输出来看,应该是 0x7fffffffe390 才对(这里不太确定,后面会验证这点)。
1 | (gdb) bt |
coredump 的直接原因就是 message 字段的内存地址错误。那么什么原因导致内存地址错了呢?这里就要回顾下我们的编译、运行过程了。我们知道在 C++ 中,对象的内存布局是由其类的定义决定的,这通常在头文件(.h)中给出。当编译一个 C++ 程序时,编译器根据类的定义(包括成员变量的类型、数量、顺序等)来确定每个对象的大小和内存布局。具体到我们这里 Protobuf 生成的 C++ 类,类的定义通常包含在 .pb.h 文件中,而 .pb.cc 文件则包含这些类的方法的实现,包含字段访问器(如 set_message 和 message)和其他成员函数的实现。这些实现负责实际的数据操作,如分配内存、修改字段值、生成对象的字符串表示等。
对象内存分布
我们上面的编译过程,主程序 main.cpp 使用了新版本的 data.pb.h,因此 main 中的 Data 对象按照新的内存布局进行编译。这里对象的内存布局包括成员变量的排列、对象的总大小以及可能的填充(为了满足对齐要求),所以 main 中的 Data 对象是包含了 users 字段的。怎么验证这一点呢?很简单,我们可以在 main 中打印下 Data 对象的大小,如下先注释掉会导致 coredump 的 set_message 以及读取 message 的代码:
1 | // main.cpp |
然后重新编译链接,运行程序,输出如下:
1 | main: 56 |
可以看到 main 中 data 的大小是 56,而 lib 中的 data 大小是 32。通过这个验证,我们可以确定 main 中的 Data 对象是包含了 users 字段的,所以会比 lib 中的 Data 对象大。
既然包含了 users 字段,为什么前面gdb 打印 main.cpp 中的 req 对象的时候,又不包含 users 字段呢?我们知道,GDB 之所以能输出对象成员、局部变量等信息,是用到了二进制文件中的符号表信息,gcc 编译的时候带上-g就会有这些调试信息。对于 pb 对象来说,这些调试信息是在 .pb.cc 文件中,包含了如何序列化和反序列化字段、如何进行内存管理(包括对于动态分配的字段如字符串和重复字段的处理)等逻辑。
我们再仔细回顾下前面 main 的编译链接命令,其实我们链接到的是动态库 libdata.so 中的老的 data.pb.cc 实现,这个版本的实现中并没有 users 字段。所以 gdb 打印的时候,无法显示出来。
1 | g++ main.cpp -o main -L. -lprotobuf -Wl,-rpath,. -ldata -g |
其实这里还有个问题需要解释下,为什么前面注释掉 set_message 以及读取 message 的代码,程序就没有 core 了呢?这是因为 main 程序不再尝试修改或访问 req 对象的内容,尽管 req 对象的内存布局与 libdata.so 中的不匹配,但由于没有实际操作这些不一致的内存区域,所以并不会触发非法内存访问。
链接新版本 pb
前面我们链接 main 的时候,用的是动态库里面的老的 data.pb.cc,如果改成链接新的 data.pb.cc,程序还会 core 吗?我们稍微改下前面的编译链接命令,注意 main.cpp 中仍然注释 set_message 部分:
1 | g++ main.cpp data.pb.cc -o main -L. -lprotobuf -Wl,-rpath,. -ldata -g |
新的链接命令只用把 data.pb.cc 放在 -ldata 前面,就会链接到新的pb实现。这里链接符号决议的过程,可以参考我之前的文章深入理解 C++ 链接符号决议:从符号重定义说起。
编译好后运行程序,发现果然又 core 了,不过这次 core 的位置在 libdata.cpp 中的 processData 函数中,具体在 data.set_message("Hello from lib"); 这里,如下图所示:
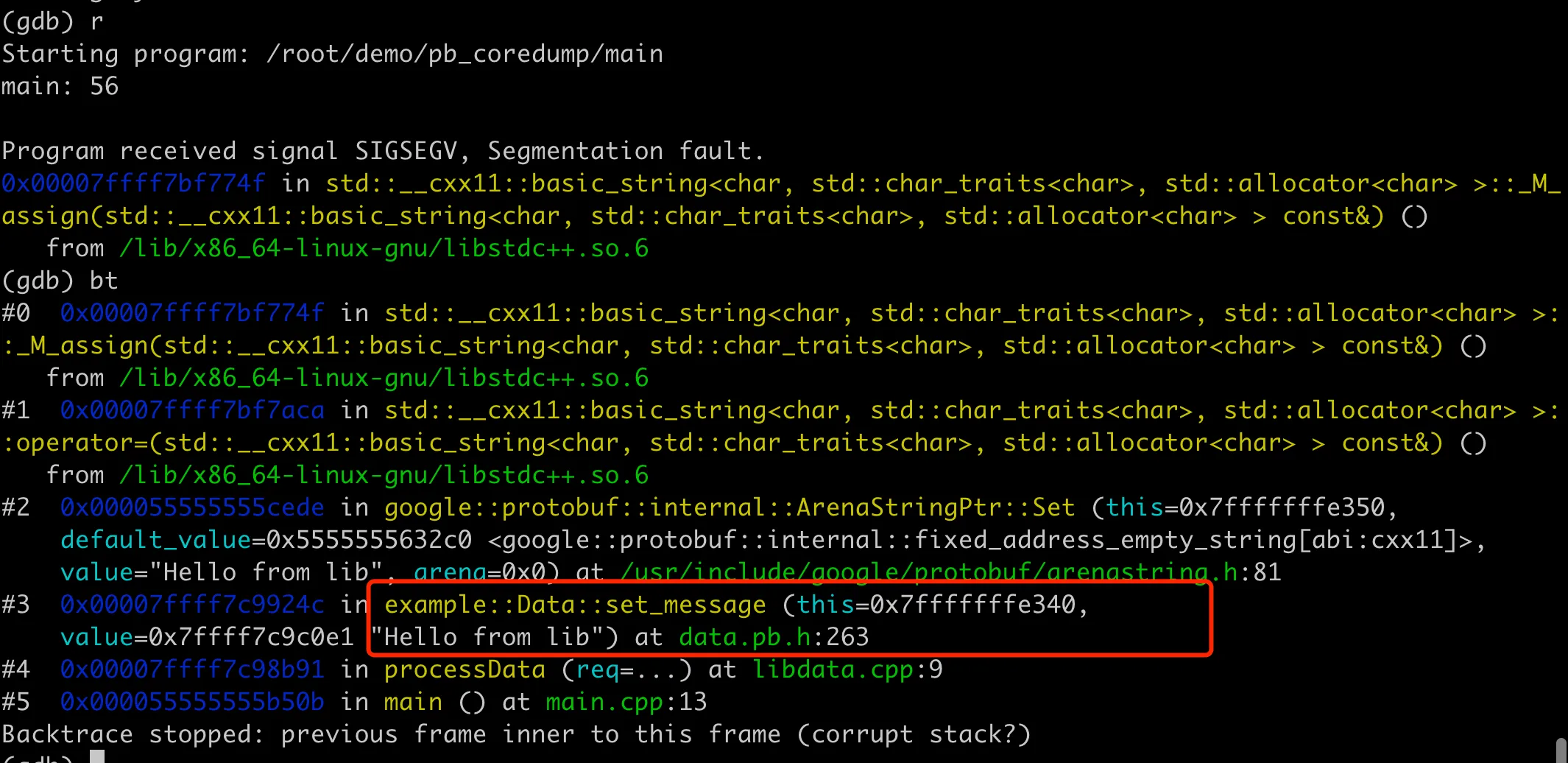
这是因为我们的 libdata.so 中的 Data 对象定义是用的老的 data.pb.h,而链接到的实现又是新的data.pb.cc,导致对象不一致,所以内存会错乱导致 core。
这里 core 的位置也挺有意思的,如果 main.cpp 不注释 set_message 部分,如下:
1 | int main() { |
程序并没有 core 在动态库 processData 中,反而是 core 在 main 中的 req.message() 了。大概是因为 processData 中访问对象凑巧没有错乱,直到 main 中访问 req.message() 的时候才触发内存错误。那么如果把 req.message() 这行也注释呢,如下代码还会 core 吗?
1 | int main() { |
执行后发现程序运行到了 return,打印了所有内容,但最后还是 core 掉。输出如下:
1 | g++ main.cpp data.pb.cc -o main -L. -lprotobuf -Wl,-rpath,. -ldata -g |
具体 core 的位置在 main 中 req 对象的析构过程,通过 GDB 可以发现,在 processData 处理之前,打印 req 也能看到 user 字段。但是 processData 后,req 的内存地址直接变成了一个非法地址,所以后续析构出错。整体 GDB 过程如下图:
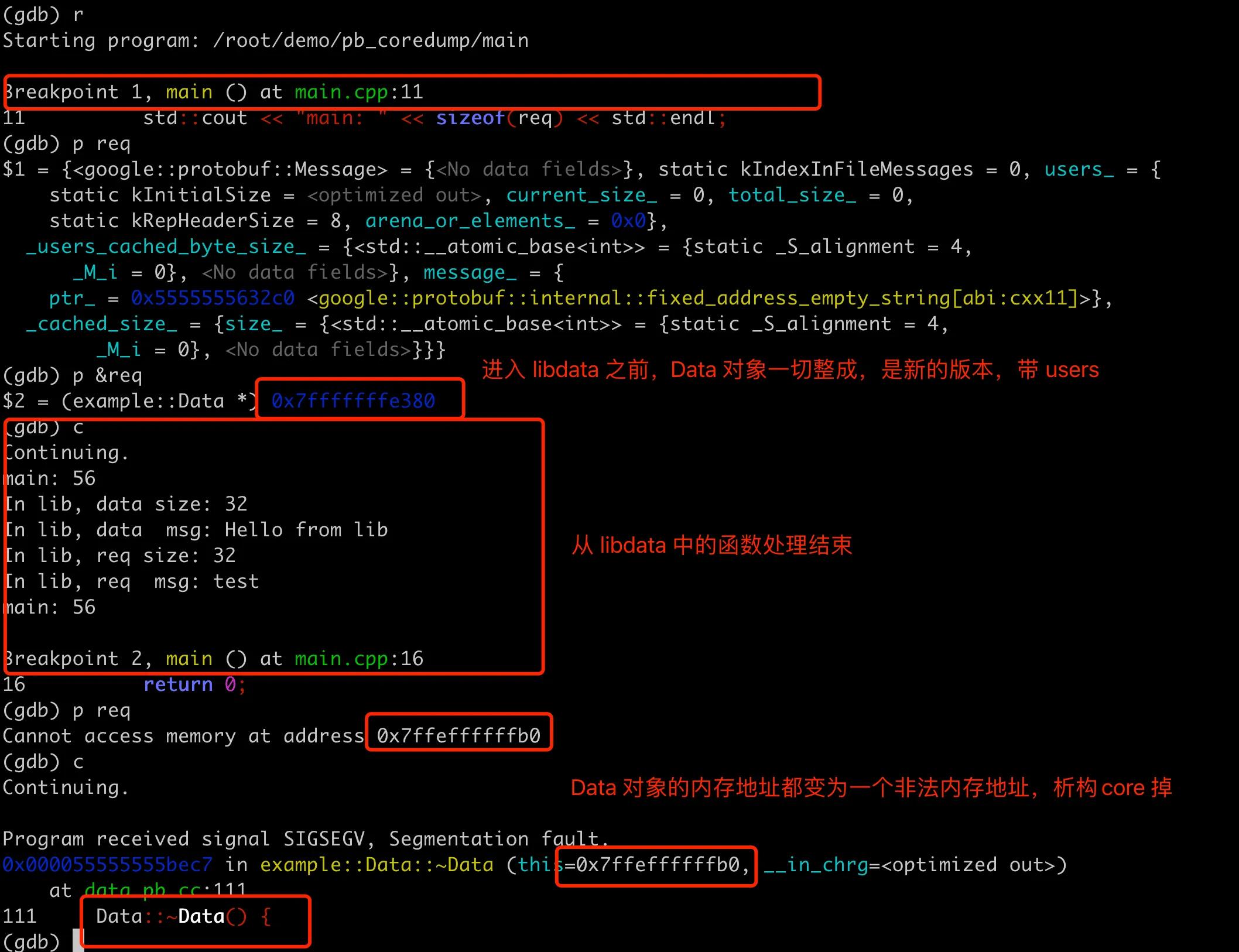
这里再补充说下,其实在 processData 中处理 req 的时候,因为 Data 对象的定义和实现有两个版本,导致 req 的内存地址错乱,只是凑巧这个函数里面的操作没有因为内存问题 core 掉,直到 main 中析构,才最终触发 core。
正常情况下内存分析
上面程序 core 的根源在于,在一个可执行文件中,用到了不同版本的 data.pb.h 和 data.pb.cc,从而导致内存读、写异常。接下来我们看看正常情况下,整个过程中 pb 对象的内存分布是怎样的。同时验证下前面遗留的一个猜测:底层 ArenaStringPtr::Set 的时候,this 的地址是 0x7fffffffe3a8,这个是 message 字段的地址。
首先用新版本 data.pb.cc 重新生成动态库,然后重新编译 main 程序,运行结果如下,一切正常。
1 | ./main |
接着用 GDB 来分析下,可以打印 req 对象,里面有 users 和 message 字段,拿到 message 的地址,可以看到和后面的 ArenaStringPtr::Set 中 this 的地址是一样的。并且在经过 processData 处理后,这里 req 对象的内存地址并没有变化,说明这里的内存操作是正常的。整体 GDB 过程如下图:
bazel 依赖缺失
让我们回到文章开始介绍的业务背景中去,业务中c++项目依赖比较多,用 bazel 来做依赖管理。有问题的 build 文件大致如下:
1 | proto_library( |
这里 libdata 的依赖其实是不完整的,正常是要依赖到 data_cc_proto 才对,但是这里并没有。在某次更新 data.proto 后,重新编译 main,bazel 分析依赖关系,发现声明的依赖里没有用到 data.proto(实际有依赖到),所以不会重新编译 libdata。导致 libdata 里面的 Data 对象定义还是老版本的,而 main 中的 Data 对象会用新版本,这样就会导致前面的内存错乱,最终 coredump。
其实上面 libdata 要能编译过,得找到 data.pb.h 头文件才行。这里使用了 includes = ["."] 这种写法,允许一个规则及其所有传递依赖包含工作区内任意位置的头文件。这种写法有很多问题,比如会使得库的封装性和可维护性降低,构建速度变慢。最新版本的 bazel 其实已经禁止了这种写法,老版本的 bazel 也是不推荐的。
我们项目中,因为要兼容比较老版本的 protobuf(2.6 左右的版本,也是很古老了),用的 bazel 版本比较老,大概是 2017 年的版本。在 BUILD 文件中,也大量使用 include=['.'],导致头文件的依赖路径很乱,所以 lib 库虽然依赖关系不全,但是仍然可以编译过,为后续的 coredump 埋下伏笔。如果升级到新版本 bazel,依赖的管理更加严格,这种依赖缺失的 BUILD 写法就会更容易发现了。
总结
最后简单总结下吧。问题的开始是简单给 proto 增加了一个字段,没想到竟然导致了 coredump。虽然知道和增加字段这个变更有关系,但是分析到具体的原因还是花了不少时间。
中间尝试过很多排查方向:
- protobuf 库有 bug?搜了一圈,没发现类似问题,并且用了这么久都很稳定,所以先排除这个可能。
- 分析 coredump 文件,没有发现有用的信息。一方面是因为对 protobuf 的实现并不是很了解,所以 core 在 pb 后就无从下手。另外 GDB 分析 core 的功底也不是很深。
- 不断地剥离无关的逻辑,争取能找到一个可以复现的小 demo。这里是同事最终找到了一个复现的步骤,成为突破口。在同事稳定复现后,就比较容易猜到、并验证这里和用了不同版本的 proto 有关。
然后想着写一篇文章来记录下这个不常见的坑,在准备文章开始的复盘代码时,又遇到了个问题。之前同事复现的时候,其实带了很多项目中的代码逻辑,bazel 的依赖关系也比较复杂。而在文章中,我想用最简单的代码复现并说明问题。最开始模拟改动 proto 的时候,只是增加一个 string 字段,结果发现并不会导致 coredump。虽然这里 Data 对象的内存布局不一样,但是凑巧读写内存都正常,没触发内存非法访问。后来想到增加这里的“扰动”,尝试换了 repeated,才能稳定复现 coredump。
复盘代码足够简单的一个好处就是,用 GDB 调试起来也比较方便,不会有太多无关的信息。通过对比 core 和正常代码中,对象内存地址的变化,再一次验证确实是因为用了不同版本的 pb 对象导致的 core。不过本文还是缺少一些深度,没有去深入分析不同版本的 pb 为什么会导致地址错乱,这部分估计得深入 protobuf 的实现了。
最后一个问题,后续怎么在项目中避免这类问题呢?首先避免用 include ['.'] 带来混乱的头文件查找路径,然后规范依赖管理,所有用到 protobuf 的库,都要加上对 pb 的依赖。当然,如果能升级 bazel 最好,不过这就需要花费更多人力了。

