Protobuf 序列化消息引起的存储失败问题分析
之前在实际业务中遇到过一个 Protobuf 序列化消息导致存储失败的问题,当时这个问题差点导致重大故障,但是也没写文章好好沉淀下来。刚好最近又遇到另一个 Protobuf 的问题,在写完 C++ 中使用 Protobuf 诡异的字段丢失问题排查 后,又想起前面的这个问题,这里再补一篇文章,好好介绍上次的踩坑过程。
故障回顾
业务中某个 HTTP 请求必现超时,通过日志,很快定位到是底层的某个服务读 KV 超时了,这里读 KV 在 5s 内都没有结束。因为这是个核心的 kv,监控粒度比较细,平均耗时和 P99 都是毫秒级别的,之前也没出现过耗时这么久的。
好在出现问题的这个 key 是必现超时,对于必现问题,查起来就容易多了。直接写了个工具,把超时设置久一点,这样就能读到完整的内容。因为这里存的是序列化后的 protobuf,读出来之后,直接解序列化,然后可以用 DebugString 打印内容。奇怪的是打印出来的是正常的业务 proto 字段,字段内容也很少,不应该超时才对。
于是又返回去重新查看超时的日志,发现日志中有打印从 kv 中读出来的 value 大小有几十兆,难怪耗时那么久。不过为啥 DebugString 打印出来的内容只有几个字段呢?为了进一步确认这里读出来的序列化后的内容有多大,进一步改了下工具,输出 value 的大小,确实是几十兆,和 KV 的日志对上了。
几十兆的内容,反序列化后输出只有几个字段,那可能就是 proto 没更新了。于是问了下小伙伴,发现这里 proto 在测试分支中,增加了一个字段,还没来得及提交。拿到新的 proto 后,重新反序列化,发现新增加的字段里有大量重复的内容。进一步梳理了整个流程,发现这里问题的触发过程还是比较隐蔽的:
- 一个新的测试模块,set 了新的 proto 字段,序列化之后存储到了 kv;
- 另一个老的模块中,创建了一个新的 message,然后 Merge 从 kv 中读出来的 pb,并写回去 kv;
- 每次 Merge 操作都会导致 message 膨胀,调用多次后,这里 pb 的体积就会特别大。
为了很好的展示这个问题,下面就准备一个简单的复现步骤。
复现问题
业务中的服务是用 C++ 实现的,不过这里为了更简单一些(刚好最近也在学着写Go),就用 Go 来复现。我们要模拟两个微服务来操作一个 protobuf 的 message:
- 服务 A(下面 serverA) 依赖新添加了字段的 proto 文件,里面会 set 新的字段,然后把序列化后的 pb 存到文件 message.pb 中。
- 服务 B(下面 serverB) 是老的服务,用的老的 proto 文件,里面会创建新的 message,然后 Merge 从上面文件读取并反序列化的 pb;
老的 Proto 如下:
1 | syntax = "proto3"; |
在服务 A 中,给这个 proto 增加了字段 string content = 4;,操作都是基于新的 proto 文件。
serverA
下面是 serverA 的实现,比较简单,需要注意的是这里用了新的字段:
1 | func main() { |
这里模拟的是业务中很常见的使用场景,从 kv 拿到某个 pb(这里为了简单,直接创建一个新的),然后新 set 一个字段重新保存。
serverB
接下来是 serverB 的实现了,这个服务中由于没有重新编译,所以 proto 还是用的老的。这种情况还是很常见的,毕竟实际业务中,经常会有多个服务依赖同一个 proto 文件,更新了 proto 后,不一定会立马更新所有服务。
这里复现代码也很简单,新建 proto meesage,然后 Merge 上面 serverA 保存到文件中的 message。注意这里在一个循环中重复 Merge,模拟于业务中不断触发的过程。整体代码如下,这里只是为了演示核心逻辑,所以去掉了每一步检查 err 的代码,实际项目中一定要注意检查 err。
1 | func main() { |
先执行 serverA,把 pb 序列号保存好文件。然后执行 serverB,读取文件反序列化,并执行后面的循环操作。可以看到下面的输出:
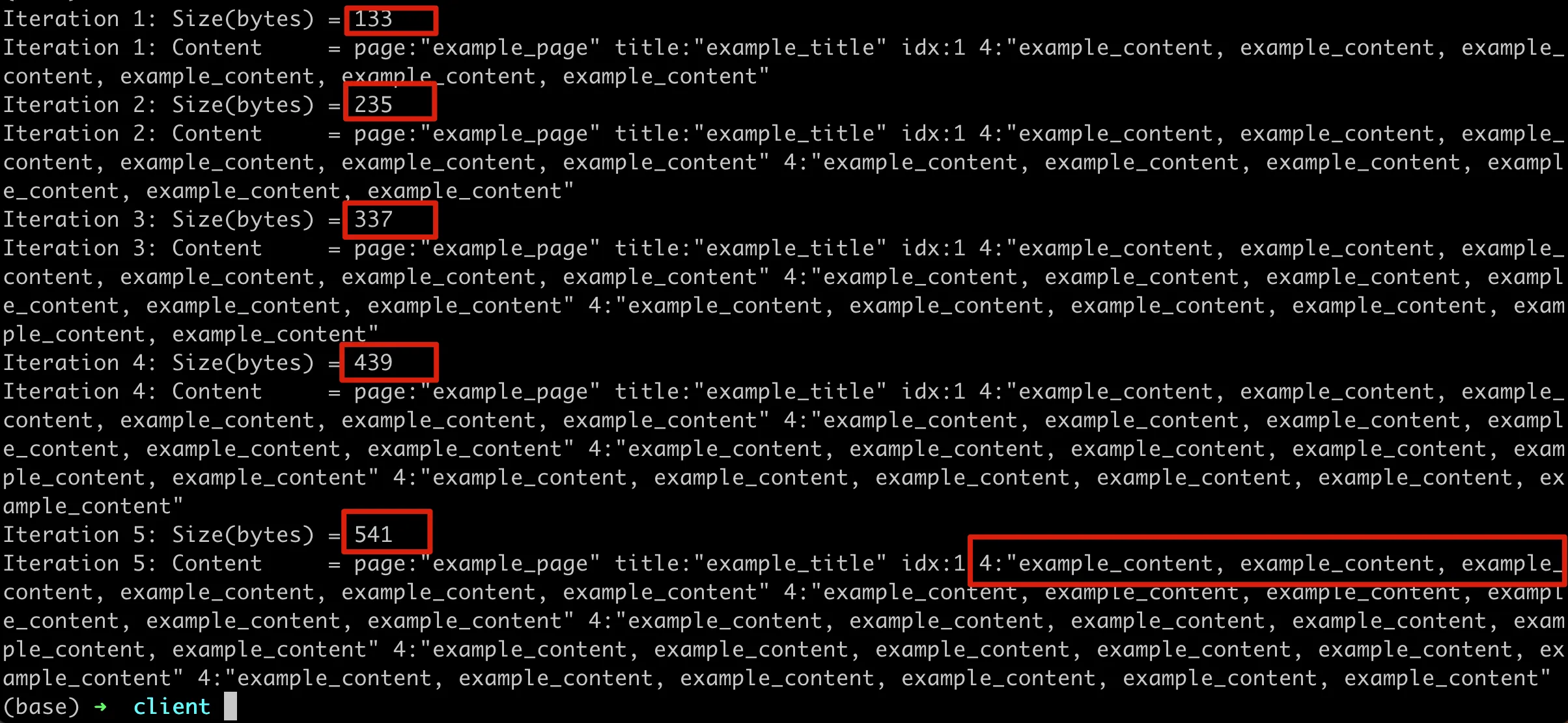
这里的 pb 内容不断膨胀,在实际业务中,如果不断触发这个 Merge 的过程,会慢慢导致很严重的后果。比如占满 KV 存储空间,或者因为内容过大导致网络传输超时。更糟糕的是,这个过程可能比较缓慢,可能是在服务 A 上线后的几个月后,才导致严重后果,排查起来就更加困难了。
源码分析
用 Go 语言就是舒服,vscode 里面可以一路跳转,看一些第三方库的代码实现简直不要太方便了。上面 proto.Merge(newInfo, initialInfo) 的实现如下(google.golang.org/protobuf v1.31.0):
1 | // Merge merges src into dst, which must be a message with the same descriptor. |
一些经典开源库的代码注释写的很不错,注意这里的注释:
The unknown fields of src are appended to the unknown fields of dst.
前面 ServerA 增加的 content 字段值,对于 ServerB 中的 newInfo 来说就是 unknown fields (因为这里没有更新proto),每次执行 Merge 操作,都会把 content 的内容 append 到 newInfo 的 unknown fields,所以导致大小不断膨胀。这个 append 的过程在上面 mergeMessage 函数中,具体如下(省略掉无关代码):
1 | func (o mergeOptions) mergeMessage(dst, src protoreflect.Message) { |
可以看到只要 src 有 unknown field,就会执行 append 操作。其实不止 Go 里面 Proto 的 Merge 是这样处理的,C++,Python也都是这样操作 unknow field 的。

