LevelDB 源码阅读:如何正确测试跳表的并行读写?
在上篇 LevelDB 源码阅读:跳表的原理、实现以及可视化中,从当前二叉搜索树和平衡树的一些缺点出发,引出了跳表这种数据结构。然后结合论文,解释了跳表的实现原理。接着详细分析了 LevelDB 的代码实现,包括迭代器实现,以及并行读的极致性能优化。最后还提供了一个可视化页面,可以直观看到跳表的构建过程。
但是还有两个问题:
- 怎么测试 LevelDB 跳表的代码,保证功能的正确性?特别是怎么保证读写并行情况下跳表实现的正确性。
- 怎么定量分析跳表的时间复杂度?
接下来通过分析 LevelDB 的测试代码,先来回答第一个问题。跳表的性能定量分析,放到另外单独一篇文章。
跳表测试分析
上篇文章分析了 LevelDB 跳表的实现,那么这里的实现是否正确呢?如果要写测试用例,应该怎么写?需要从哪些方面来测试跳表的正确性?我们看看 LevelDB 的测试代码 skiplist_test.cc。
首先是空跳表的测试,验证空跳表不包含任何元素,检查空跳表的迭代器操作 SeekToFirst, Seek, SeekToLast 等。接着是插入、查找、迭代器的测试用例,通过不断插入大量随机生成的键值对,验证跳表是否正确包含这些键,以及测试迭代器的前向和后向遍历。
1 | TEST(SkipTest, InsertAndLookup) { |
这些都是比较常规的测试用例,这里不展开了。我们重点来看看 LevelDB 的并行测试。
测试 Key 设计
LevelDB 的跳表支持单线程写,多线程并行读,在上篇详细分析过这里的并行读实现细节,那么要如何测试呢?先定义测试目标,多个线程并行读的时候,每个读线程初始化迭代器后,应该要能读到当前跳表的所有元素。因为有写线程在同时运行,所以读线程可能也会读到后续新插入的元素。读线程在任何时刻,读到的元素都应该满足跳表的性质,即前一个元素小于等于后一个元素。
LevelDB 的测试方法设计的还是比较巧妙的。首先是一个精心设计的元素值 Key(这里 K 大写来区分),注释部分写的很清晰:
1 | // We generate multi-part keys: |
跳表元素值由三部分组成,key 是随机生成,gen 是插入的递增序号,hash 是 key 和 gen 的 hash 值。三部分一起放在一个 uint64_t 的整数中,高 24 位是 key,中间 32 位是 gen,低 8 位是 hash。下面是根据 Key 提取三个部分,以及从 key 和 gen 生成 Key 的代码:
1 | typedef uint64_t Key; |
那为什么要设计 key 呢?key 的取值在 0 到 K-1 之间,K 这里是 4。key 虽然占了高 24 位,但是取值范围是 0-3。其实这里键值设计不用高 24 位的 key也是完全可以的,后面的测试逻辑没有大的影响。这里问了下 gpto1 和 claude3.5,给的解释也说不通。结合后续的并行读、写测试代码,个人理解可能是想模拟在链表中执行跨度比较大的 seek 操作。欢迎各位在评论区指正,给出其他可以说的通的解释~
至于 gen 和 hash 的好处就比较明显了,插入的时候保证 gen 递增,那么读线程就可以用 gen 来验证跳表中元素插入的顺序。每个键低 8 位是 hash,可以用来验证从跳表中读出来的元素和插入的元素是否一致,如下 IsValidKey 方法:
1 | static uint64_t HashNumbers(uint64_t k, uint64_t g) { |
这里取出键值的低 8 位,和从 key 和 gen 生成的 hash 值对比,如果相等,则说明元素是有效的。上面实现都放在 ConcurrentTest 类,这个类作为辅助类,定义了系列 Key 相关的方法,以及读写跳表部分。
写线程操作
接下来看写线程的操作方法 WriteStep,它是 ConcurrentTest 类的 public 成员方法,核心代码如下:
1 | // REQUIRES: External synchronization |
这里随机生成一个 key,然后拿到该 key 对应的上个 gen 值,递增生成新的 gen 值,调用 Insert 方法往跳表插入新的键。新的键是用前面的 MakeKey 方法,根据 key 和 gen 生成。插入调表后还要更新 key 对应的 gen 值,这样就保证了每个 key 下插入的元素 gen 是递增的。这里 key 的取值在 0 到 K-1 之间,K 这里取 4。
这里的 current_ 是一个 State 结构体,保存了每个 key 对应的 gen 值,代码如下:
1 | struct State { |
State 结构体中有一个 atomic 数组 generation,保存了每个 key 对应的 gen 值。这里用 atomic 原子类型和 memory_order_release, memory_order_acquire 语义来保证,写线程一旦更新了 key 的 gen 值,读线程立马就能读到新的值。关于 atomic 内存屏障语义的理解,可以参考上篇跳表实现中 Node 类的设计。
读线程操作
上面写线程比较简单,一个线程不断往跳表插入新的元素即可。读线程相对复杂了很多,除了从跳表中读取元素,还需要验证数据是符合预期的。这里是注释中给出的测试读线程的整体思路:
1 | // At the beginning of a read, we snapshot the last inserted |
主要确保跳表在读写并行环境下的正确性,可以从下面 3 个角度来验证:
- 一致性验证:确保读线程在迭代过程中不会遗漏在迭代器创建时已经存在的键。
- 顺序遍历:验证迭代器遍历的顺序始终是递增的,避免回退。
- 并行安全:通过随机的迭代器移动策略,模拟并行读操作场景,检测潜在的竞争条件或数据不一致问题。
这里 ReadStep 方法有一个 while(true) 循环,在开始循环之前,先记录下跳表的初始状态到 initial_state 中,然后用 RandomTarget 方法随机生成一个目标键 pos,用 Seek 方法查找。
1 | void ReadStep(Random* rnd) { |
之后就是整个验证过程,这里省略了跳表中找不到 pos 的情况,只看核心测试路径。
1 | while (true) { |
这里找到位置 current 后,会验证 current 位置的键值 hash 是否正确,接着验证 pos <= current。之后用一个 while 循环遍历跳表,验证 [pos, current) 区间内的所有键都没有在初始状态 initial_state 中。这里可以用反证法思考,如果某个键 tmp 在 [pos, current) 区间内,并且也在 initial_state 中,那么根据跳表的性质,Seek 的时候就会找到 tmp,而不是 current 了。所以只要链表实现正确,那么 [pos, current) 区间内的所有键都没有在 initial_state 中。
当然这里没有记录下跳表中的键值,只用验证 [pos, current) 区间内所有键的 gen 值大于初始状态下的 gen 值,就能说明开始迭代的时候这个范围内的所有键都不在链表中。
在上面每轮验证后都会重新找到一个新的测试目标键 pos,并更新迭代器,如下代码:
1 | if (rnd->Next() % 2) { |
这里随机决定是 iter.Next() 移动到下一个键,还是创建一个新的目标键并重新定位到该目标键。整个读测试模拟了真实环境下的不确定性,确保跳表在各种访问模式下的稳定性和正确性。
单线程读写
上面介绍完了测试读写的方法,下面看看具体怎么结合线程来测试。单线程下读、写比较简单,写和读交换执行就好。
1 | // Simple test that does single-threaded testing of the ConcurrentTest |
并行读写测试
实际场景中,有一个写线程,但是可以有多个读线程,还要测试读和写并行场景下跳表的正确性。核心测试代码如下:
1 | static void RunConcurrent(int run) { |
这里每个用例中迭代 N 次,每次迭代中使用 Env::Default()->Schedule 方法,创建了一个新的线程执行 ConcurrentReader 函数,并传入 state 作为参数。ConcurrentReader 会在独立线程中执行读操作,模拟并行读环境。接着调用 state.Wait(TestState::RUNNING) 等读线程进入运行状态后,主线程开始写操作。
这里写操作通过循环调用 state.t_.WriteStep(&rnd),在跳表中执行 kSize 次写操作。每次写操作会插入新的键值对到跳表中,模拟写线程的行为。等执行完写操作后,设置 state.quit_flag_ 为 true,通知读线程停止读取操作并退出。等待读线程完成所有操作并退出,确保当前循环的读写操作全部结束后再进行下一次测试。
这里的测试用到了 TestState 来同步线程状态,还封装了一个 ConcurrentReader 作为读线程方法。此外还调用了 Env 封装的 Schedule 方法,在独立线程中执行读操作。涉及到条件变量、互斥锁以及线程相关内容,这里不展开了。
值得一说的是,这里也只是测试了一写一读并行的场景,并没有测试一写多读。可以在每轮迭代中启动多个读线程,所有读线程同时与写操作并发执行。或者维护一个固定数量的读线程池,多个读线程持续运行,与写线程并发操作。不过当前的测试,通过多次重复一写一读的方式,依然能够有效地验证跳表在读写并发下的正确性和稳定性。
下面是执行测试用例的输出截图:
并行测试正确性
上面并行测试比较详细,但是这里值得再多说一点。对于这种并行下的代码,特别是涉及内存屏障相关的代码,有时候测试通过可能只是因为没触发问题而已(出现问题的概率很低,可能和编译器,cpu 型号也有关)。比如这里我把 Insert 操作稍微改下:
1 | for (int i = 0; i < height; i++) { |
这里两个指针都用 NoBarrier_SetNext 方法来设置,然后重新编译 LevelDB 库和测试程序,运行多次,都是能通过测试用例的。
当然这种情况下,可以在不同的硬件配置和负载下进行长时间的测试,可能也可以发现问题。不过缺点就是耗时较长,可能无法重现发现的问题。
ThreadSanitizer 检测数据竞争
此外也可以使用 clang 的动态分析工具 ThreadSanitizer 来检测数据竞争。使用也比较简单,编译的时候带上 -fsanitize=thread 选项即可。完整的编译指令如下:
1 | CC=/usr/bin/clang CXX=/usr/bin/clang++ cmake -DCMAKE_BUILD_TYPE=Debug -DCMAKE_EXPORT_COMPILE_COMMANDS=1 -DCMAKE_CXX_FLAGS="-fsanitize=thread" -DCMAKE_C_FLAGS="-fsanitize=thread" -DCMAKE_EXE_LINKER_FLAGS="-fsanitize=thread" -DCMAKE_INSTALL_PREFIX=$(pwd) .. && cmake --build . --target install |
把上面改动后的代码重新编译链接,运行测试用例,结果如下:
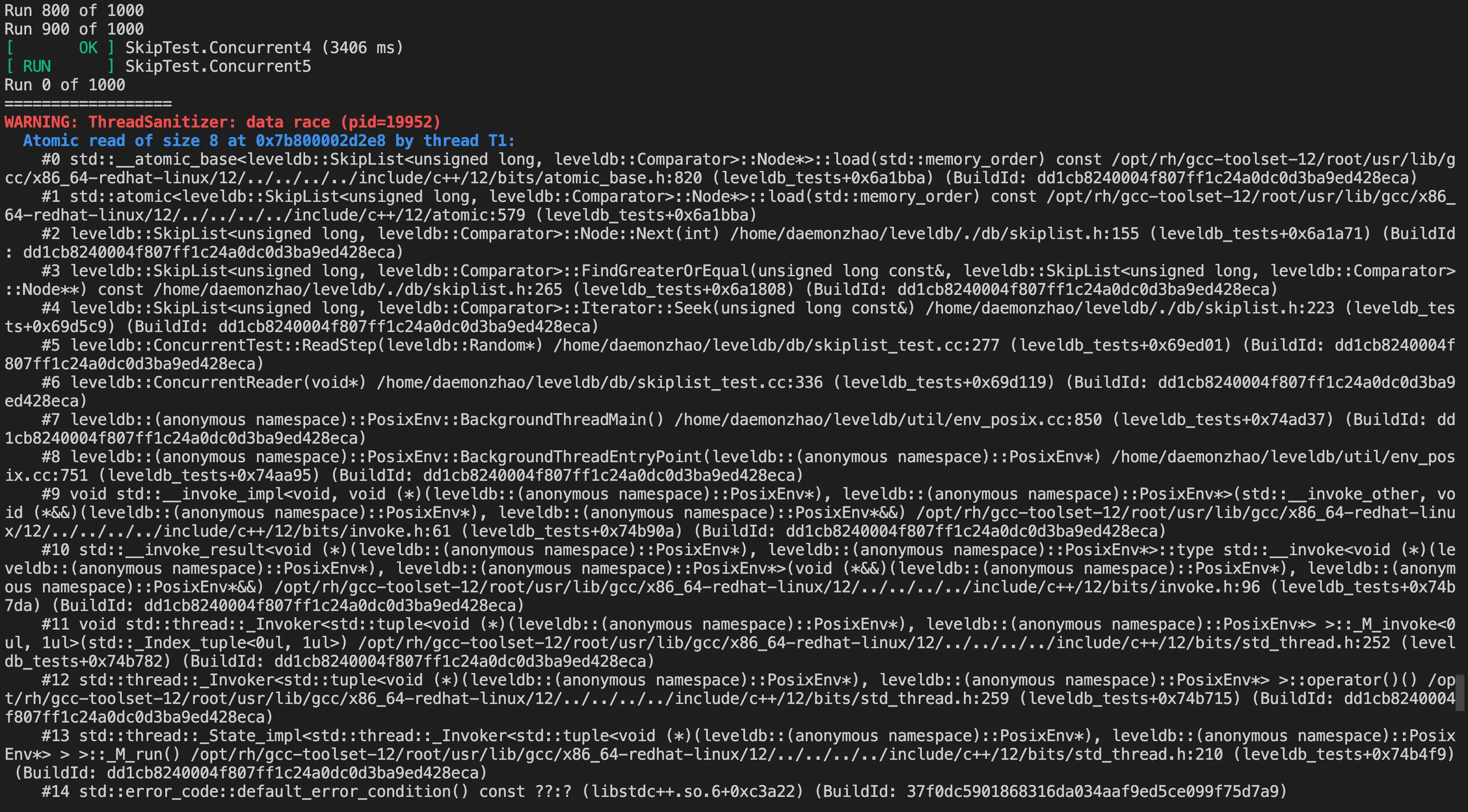
这里定位到了问题代码,还是很精准的。如果取消这里的错误改动重新编译运行,是不会有问题的。ThreadSanitizer 的实现原理比较复杂,程序被编译时,TSan 在每个内存访问操作前后插入检查代码。运行过程中,当程序执行到一个内存访问操作时,插入的代码会被触发,这段代码检查并更新相应的影子内存。它比较当前访问与该内存位置的历史访问记录。如果检测到潜在的数据竞争,TSan 会记录详细信息,包括堆栈跟踪。
它的优点是能够检测到难以通过其他方法发现的微妙数据竞争,同时还提供详细的诊断信息,有助于快速定位和修复问题。不过会显著增加程序的运行时间和内存使用。可能无法检测到所有类型的并发错误,特别是那些依赖于特定时序的错误。
总结
跳表的测试部分也分析完了,我们重点分析了下并行读写场景下的正确性验证。这里插入键值 Key 的设计,读线程的验证方法都很巧妙,值得我们借鉴。同时我们也要认识到,多线程下数据竞争的检测,有时候靠测试用例是很难发现的。借助 ThreadSanitizer 这种工具,可以辅助发现一些问题。
最后欢迎大家留言交流~

