LevelDB 源码阅读:DataBlock 的前缀压缩和重启点机制分析
在 LevelDB 中,SSTable(Sorted Strings Table)是存储键值对数据的文件格式。前面的文章LevelDB 源码阅读:一步步拆解 SSTable 文件的创建过程 介绍了 SSTable 文件的创建过程,我们知道了 SSTable 文件由多个数据块组成,这些块是文件的基本单位。
这些数据块起始可以分两类,一种是键值对数据块,一种是过滤块数据块。相应的,为了组装这两类数据块,LevelDB 实现了两类 BlockBuilder 类,分别是 BlockBuilder 和 FilterBlockBuilder。这篇文章,我们来看看 BlockBuilder 的实现。
先来看一个简单的示意图,展示了 LevelDB 中 DataBlock 的存储结构,图的源码在 leveldb_datablock.dot。
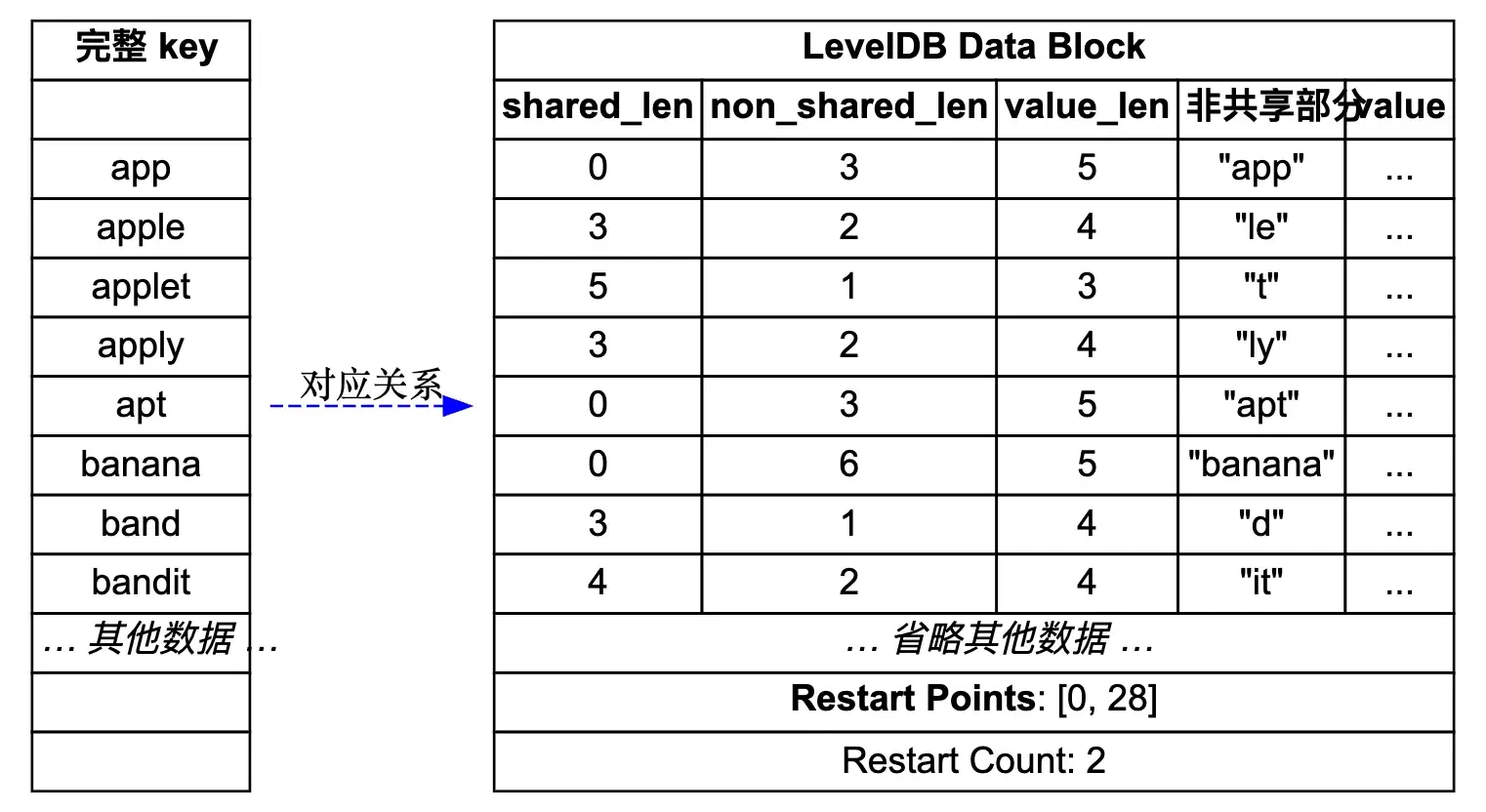
接下来配合这个图来理解前缀压缩和重启点机制。
如何高效存储键值对?
我们知道这里 DataBlock 用来存储有序的键值对,最简单的做法就是直接一个个存储。比如用 [keysize, key, valuesize, value] 这样的格式来存储。那么一个可能的键值对存储结果如下:
1 | [3, "app", 6, "value1"] |
仔细观察这些键,我们会发现一个明显的问题:存在大量的重复前缀。
- app, apple, applet, apply 都共享前缀 “app”
- apple, applet 还额外共享前缀 “appl”
这里的例子是我构造的,不过实际的业务场景中,我们的 key 经常都是有大量相同前缀的。这种共同前缀会浪费不少硬盘存储空间,另外读取的时候,也需要传输更多的冗余数据。如果缓存 DataBlock 到内存中,这种重复数据也会占用更多的内存。
前缀压缩
LevelDB 作为底层的存储组件,肯定要考虑存储效率。为了解决这个问题,LevelDB 采用了前缀压缩的存储格式。核心思想是:对于有序的键值对,后面的键只存储与前一个键不同的部分。
具体的存储格式变成了:
1 | [shared_len, non_shared_len, value_len, non_shared_key, value] |
其中 shared_len 表示与前一个键共享的前缀长度,non_shared_len 表示不共享部分的长度,value_len 表示值的长度,non_shared_key 表示键中不共享的部分,value 表示实际的值。
让我们用前面的例子来看看效果,这里看看前缀压缩后键长度的变化:
| 完整 key | shared_len | non_shared_len | non_shared_key | 存储开销分析 |
|---|---|---|---|---|
| app | 0 | 3 | “app” | 原始:1+3=4,压缩:1+1+3=5,省1字节 |
| apple | 3 | 2 | “le” | 原始:1+5=6,压缩:1+1+2=4,省2字节 |
| applet | 5 | 1 | “t” | 原始:1+6=7,压缩:1+1+1=3,省4字节 |
| apply | 4 | 1 | “y” | 原始:1+5=6,压缩:1+1+1=3,省3字节 |
当然这里为了简化,假设长度值存储用 1 字节,实际上LevelDB使用变长编码,不过小长度下,长度也是 1 字节的。这里前缀压缩的效果并不是简单的节省重复前缀,而是需要权衡前缀长度与额外元数据的存储开销。
在这个例子中,总体上我们节省了 (1+2+4+3) = 10 个字节。其实对于大部分业务场景,这里肯定都能节省不少存储空间的。
重启点机制
看起来很完美是吧?别急,我们来看看读取的键值的时候,会遇到什么问题。如果我们想要查找 “apply” 这个键,在前缀压缩的存储中我们只能看到:
1 | [4, 1, 4, "y", ...] |
为了拿到完整的键,我们要从从第一个键开始顺序读取,然后重建每个键的完整内容,直到找到目标键。这样会有什么问题?效率低啊!我们之所以顺序存键值,就是为了能用二分法快速定位到目标键,现在前缀压缩后,我们只能顺序读取,这在大块数据中会变得非常低效!
那怎么办,放弃用前缀压缩,或者是用其他方法?哈哈,计算机科学中,我们经常遇到类似的问题,一般都是取个折中方案,在存储和查找效率之间找个平衡。
LevelDB 的实现中,引入了 Restart Points(重启点) 来平衡这里的存储和查找效率。具体做法也很简单,就是每隔一定数量 N 的键,就存储键的完整内容。这里存储完整内容的键,就叫重启点。
只有重启点还不够,我们还要有个索引,能快速找到一个块中所有的完整键。这里 LevelDB 做法也很简单,在 DataBlock 的尾部,记录每个重启点的偏移位置。
查询的时候,根据尾部存储的重启点偏移,就能读出这里重启点的完整键,接着就可以用二分法快速定位到键应该在的区间。之后就可以从重启点开始顺序读取,直到找到目标键。这时候,最多读取 N 个键,就能找到目标键。这部分逻辑,我们放到下篇文章来展开。
构建 DataBlock 代码详解
整体逻辑已经很清晰了,接下来看看代码实现吧。这里实现在 table/block_builder.cc 中,代码量不多,还是比较好理解。
这里我们先看几个内置成员变量,基本看到这些成员变量就能猜到具体的实现逻辑了。在 table/block_builder.h 中:
1 | class BlockBuilder { |
这里 buffer_ 就是存储 DataBlock 数据的地方,restarts_ 数组记录所有重启点的偏移位置。counter_ 用来计算从上次重启点开始存储的键值对数量,达到配置的阈值后,就设置新的重启点。
finished_ 记录是否已经完成构建,会在完成构建的时候,主动写尾部的数据。last_key_ 记录上一个键,用来做前缀压缩。
添加键值处理
BlockBuilder 中核心的方法 2 个,分别是 Add 和 Finish。 我们先来看看 BlockBuilder::Add,逻辑很清晰,这里去掉了一些 assert 校验逻辑。
1 | void BlockBuilder::Add(const Slice& key, const Slice& value) { |
这里代码很优雅,一看就懂。我多说一点这里 last_key_ 的一个小优化细节,我们看到 last_key_ 是一个 string,每次更新 last_key_ 的时候,首先复用共有部分,接着用 append 添加非共有部分。对于共同前缀长的键来说,这种更新方法可以节省不少内存分配。
在所有 key 添加完的时候,调用方主动调用 Finish 方法,然后把重启点数组和大小写到尾部,然后整体返回一个 Slice 对象。
1 | Slice BlockBuilder::Finish() { |
调用方会接着用这个 Slice 对象,写入到 SSTable 文件中。
重启点间隔大小选择
到此为止,我们了解了 LevelDB 中 DataBlock 构建过程中的优化细节,以及具体代码实现了。前面我们没提到重启点间隔大小,这里是通过配置项 options.h 中的 block_restart_interval 来控制的,默认值是 16。
1 | // Number of keys between restart points for delta encoding of keys. |
这个值为啥是 16?如果在自己的业务场景用的话,可以调整吗?
先来看第一个问题,LevelDB 中默认是 16,可能是作者经过测试选择的一个魔数。不过从开源出来的代码看,这里没有不同间隔的压测数据。table_test.cc 中,也只有不同间隔的功能测试代码。
再来看第二个问题,我们自己的业务中,如果选择这个间隔值?我们要明白这个间隔值主要用来平衡压缩和查询性能,如果设置太小,就会导致压缩率降低。如果设置太大的话,压缩率上去了,但是查找的时候,线性扫描的键就会增多。
LevelDB 默认块的大小是 4KB,假设我们一个键值对平均 100 字节,那么 4KB 的块可以存储 40 个键值对。如果重启点间隔是 16,那么每个块中,重启点就有 3 个。
1 | restart_point[0]: "user:12345:profile" (键 1-16) |
二分查找最多需要 2 次就能找到所在的区间,接着扫描的话,最坏情况要读取 15 个键,就能找到目标键。整体查找代价还是可以接受的。
总结
明白了这里前缀压缩和重启点机制后,其实整个 DataBlock 的构建过程还是挺简单的。接下来我会继续分析 DataBlock 的读取解析过程,以及 FilterBlock 的构建和解析。

