LevelDB Explained - Prefix Compression and Restart Points in BlockBuilder
In LevelDB, SSTable (Sorted Strings Table) is the file format for storing key-value pairs. A previous article, LevelDB Explained - A Step by Step Guide to SSTable Build, introduced the creation process of SSTable files, where we learned that an SSTable file is composed of multiple data blocks, which are the fundamental units of the file.
These data blocks can be categorized into two types: key-value data blocks and filter data blocks. Accordingly, LevelDB implements two types of BlockBuilder classes to assemble them: BlockBuilder and FilterBlockBuilder. In this article, we’ll dive into the implementation of BlockBuilder.
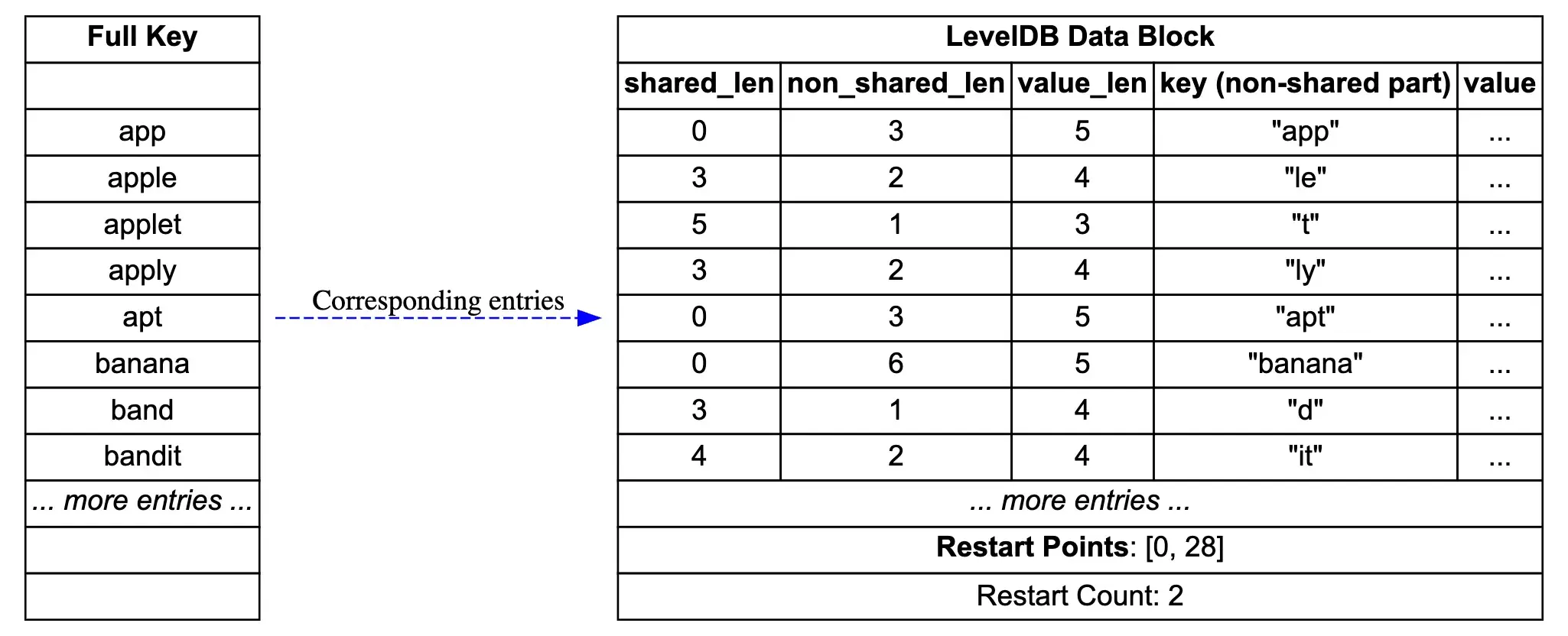
First, let’s look at a simple diagram showing the storage structure of a DataBlock in LevelDB. The source for the diagram can be found at leveldb_datablock_en.dot.