LevelDB Explained - Prefix Compression and Restart Points in BlockBuilder
In LevelDB, SSTable (Sorted Strings Table) is the file format for storing key-value pairs. A previous article, LevelDB Explained - A Step by Step Guide to SSTable Build, introduced the creation process of SSTable files, where we learned that an SSTable file is composed of multiple data blocks, which are the fundamental units of the file.
These data blocks can be categorized into two types: key-value data blocks and filter data blocks. Accordingly, LevelDB implements two types of BlockBuilder classes to assemble them: BlockBuilder and FilterBlockBuilder. In this article, we’ll dive into the implementation of BlockBuilder.
First, let’s look at a simple diagram showing the storage structure of a DataBlock in LevelDB. The source for the diagram can be found at leveldb_datablock_en.dot.
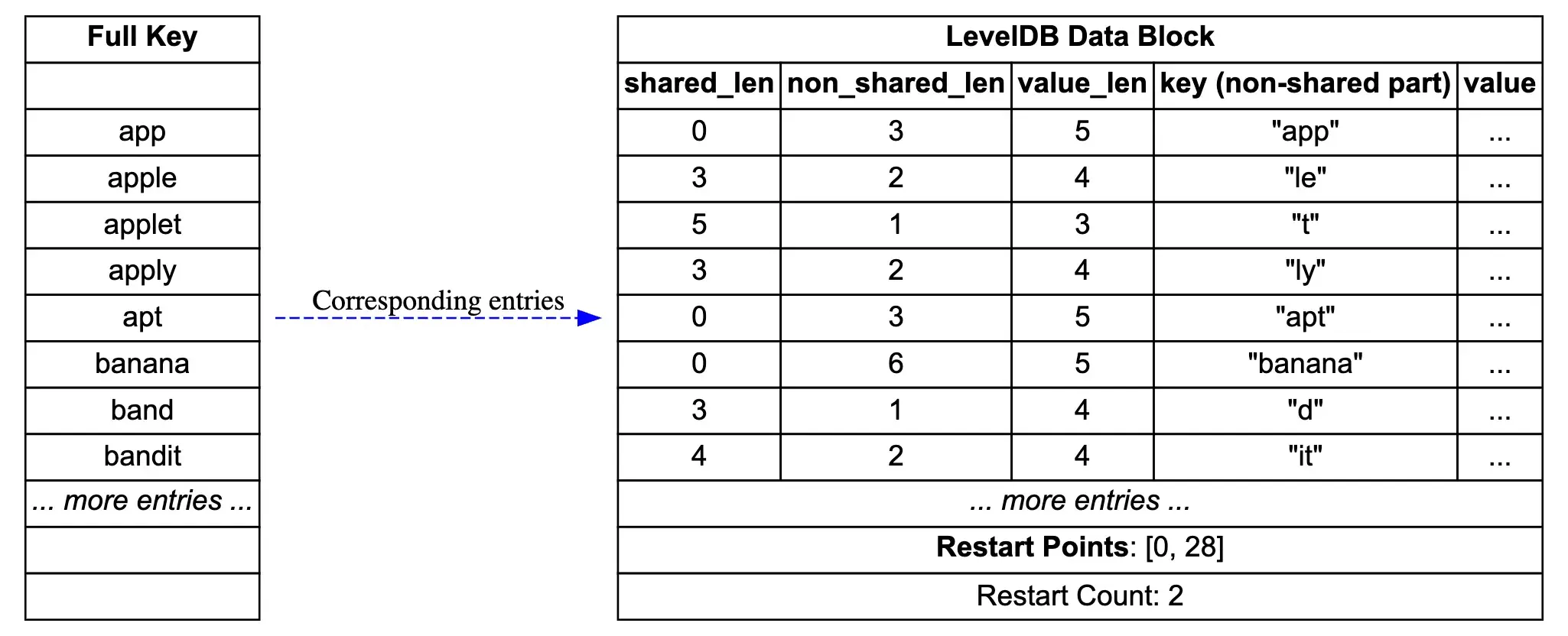
Next, we’ll use this diagram to understand the prefix compression and restart point mechanisms.
How to Store Key-Value Pairs Efficiently?
As we know, a DataBlock is used to store sorted key-value pairs. The simplest approach would be to store them one by one, perhaps in a format like [keysize, key, valuesize, value]. A possible storage result would look like this:
1 | [3, "app", 6, "value1"] |
Observing these keys, we notice a significant issue: a large number of shared prefixes.
- app, apple, applet, and apply all share the prefix “app”.
- apple and applet also share the additional prefix “appl”.
While this example is constructed, real-world scenarios often involve keys with many common prefixes. These shared prefixes waste a considerable amount of disk space and require transferring more redundant data during reads. If a DataBlock is cached in memory, this redundant data also consumes more memory.
Prefix Compression
As a low-level storage component, LevelDB must consider storage efficiency. To address this, LevelDB uses a prefix compression storage format. The core idea is: for sorted key-value pairs, subsequent keys only store the part that differs from the previous key.
The specific storage format becomes:
1 | [shared_len, non_shared_len, value_len, non_shared_key, value] |
Where shared_len is the length of the shared prefix with the previous key, non_shared_len is the length of the non-shared part, value_len is the length of the value, non_shared_key is the non-shared part of the key, and value is the actual value.
Let’s see the effect with our previous example, focusing on the change in key length after prefix compression:
| Full Key | shared_len | non_shared_len | non_shared_key | Storage Cost Analysis |
|---|---|---|---|---|
| app | 0 | 3 | “app” | Original: 1+3=4, Compressed: 1+1+1+3=6, uses 2 more bytes |
| apple | 3 | 2 | “le” | Original: 1+5=6, Compressed: 1+1+1+2=5, saves 1 byte |
| applet | 5 | 1 | “t” | Original: 1+6=7, Compressed: 1+1+1+1=4, saves 3 bytes |
| apply | 4 | 1 | “y” | Original: 1+5=6, Compressed: 1+1+1+1=4, saves 2 bytes |
Of course, for simplicity, we assume the length fields are 1 byte. In reality, LevelDB uses variable-length encoding (Varint), but for small lengths, it is indeed 1 byte. A careful calculation reveals that prefix compression isn’t just about saving on repeated prefixes; it requires a trade-off between the prefix length and the storage overhead of additional metadata.
In this example, we save a total of (1+3+2-2) = 4 bytes. For most business scenarios, this can definitely save a significant amount of storage space.
Restart Points Mechanism
Looks perfect, right? Not so fast. Let’s see what problems we encounter when reading key-value pairs. If we want to find the key “apply”, all we see in the prefix-compressed storage is:
1 | [4, 1, 4, "y", ...] |
To reconstruct the full key, we have to start from the first key, sequentially read and rebuild each key’s full content until we find our target. What’s the problem with this? It’s inefficient! The reason we store keys in sorted order is to use binary search for fast lookups. Now, with prefix compression, we’re forced into a linear scan, which can be very slow in large data blocks.
So, what’s the solution? Abandon prefix compression? Or find another way? In computer science, we often face similar problems, and the solution is usually a compromise, finding a balance between storage and lookup efficiency.
In its implementation, LevelDB introduces Restart Points to balance storage and lookup efficiency. The method is quite simple: every N keys, the full key content is stored. A key stored with its full content is called a restart point.
But restart points alone are not enough. We also need an index to quickly find all the full keys within a block. LevelDB’s approach here is also straightforward: it records the offset of each restart point at the end of the DataBlock.
During a query, by using the restart point offsets stored at the end, we can read all the complete keys at these restart points. Then, we can use binary search to quickly locate the interval where the key should be. After that, we can start a sequential read from that restart point until we find the target key. In this case, we’d need to read at most N keys to find the target. We’ll explore the logic for this in a future article.
Building a DataBlock: Code Walkthrough
With the overall logic clear, let’s look at the code implementation. It’s located in table/block_builder.cc, and the code is relatively short and easy to understand.
First, let’s look at a few internal member variables. Seeing them gives us a good idea of the implementation logic. In table/block_builder.h:
1 | class BlockBuilder { |
Here, buffer_ is where the DataBlock data is stored, and the restarts_ vector records the offsets of all restart points. counter_ is used to count the number of key-value pairs stored since the last restart point; when it reaches a configured threshold, a new restart point is set.
finished_ records whether the build process is complete and is used to write the trailer data. last_key_ stores the previous key for prefix compression.
Adding a Key-Value Pair
The BlockBuilder has two core methods: Add and Finish. Let’s first look at BlockBuilder::Add. The logic is clear (some assert checks are removed for brevity).
1 | void BlockBuilder::Add(const Slice& key, const Slice& value) { |
The code is elegant and easy to understand. I’ll add a small detail about the optimization of last_key_. We see that last_key_ is a std::string. Each time last_key_ is updated, it first reuses the shared part (resize) and then appends the non-shared part. For keys with long common prefixes, this update method can save a lot of memory allocations.
When all keys have been added, the caller invokes the Finish method, which writes the restart point array and its size to the end of the buffer and returns the entire buffer as a Slice object.
1 | Slice BlockBuilder::Finish() { |
The caller then uses this Slice object to write to the SSTable file.
Choosing the Restart Interval
So far, we’ve covered the optimization details and code implementation of the DataBlock build process in LevelDB. We haven’t mentioned the restart interval size, which is controlled by the block_restart_interval option in options.h, with a default value of 16.
1 | // Number of keys between restart points for delta encoding of keys. |
Why is this value 16? Can it be adjusted for our own use cases?
First, the default of 16 in LevelDB is likely a magic number chosen by the authors after testing. However, looking at the open-source code, there’s no benchmark data for different intervals. The table_test.cc file only contains functional tests for different intervals.
Second, how should we choose this interval for our own services? We need to understand that this interval is primarily a trade-off between compression and query performance. If it’s set too small, the compression ratio will decrease. If it’s set too large, the compression ratio improves, but the number of keys to scan linearly during a lookup increases.
The default block size in LevelDB is 4KB. Assuming an average key-value pair is 100 bytes, a 4KB block can store about 40 key-value pairs. If the restart interval is 16, then there would be about 3 restart points per block.
1 | restart_point[0]: "user:12345:profile" (keys 1-16) |
A binary search would take at most 2 comparisons to find the interval. Then, the subsequent scan would require reading at most 15 keys to find the target. The overall lookup cost is quite acceptable.
Conclusion
Once you understand prefix compression and the restart point mechanism, the process of building a DataBlock is actually quite simple. Next, I will continue to analyze the process of reading and parsing a DataBlock, as well as the construction and parsing of the FilterBlock.

