ChatGPT plugin 来做数据分析
GPT4 的部分插件还是能提高工作效率的,其中 noteable 可以写脚本绘制图,在数据分析领域还是很不错的。我们可以 AI 总结中国过去十年的出生人口趋势,可以分析用户留存率,或者找出某些日子都活跃的用户。
人口趋势
Human:
统计下中国官方给的最近 10 年总出生人口,用 python 画一个曲线走势图。
ChatGPT:
好的,首先我们需要找到这些数据。这些数据可能来自中国的官方统计局或其他可靠的数据源。让我帮你找一下。
我在中国统计局的官方网站上没有直接找到过去十年的出生人口数据。可能需要在网站的不同部分或者在年度统计报告中进行深入搜索。另一种可能是这些数据可能需要在其他可靠的数据源中查找。你是否有推荐的数据源,或者我可以继续在中国统计局网站上进行深入搜索?
这里用了插件 WebPilot,可以去网上搜索,目前用过的最好用的插件了。作者是一个产品经理,可以在这里找他。不过这里没有找到相关数据,就自己去网上搜索了下,给他链接。
Human:
这里有,https://www.163.com/dy/article/HSAQ6SQ2055611U3.html ,帮我用 python 画一个曲线走势图吧
ChatGPT:
这篇文章中包含了从1949年到2022年中国每年的出生人口数据。以下是最近十年的数据:
- 2013年:1640万
- 2014年:1687万
- 2015年:1655万
- 2016年:1786万
- 2017年:1723万
- 2018年:1523万
- 2019年:1465万
- 2020年:1202万
- 2021年:1062万
- 2022年:956万
接下来,我将使用这些数据创建一个Python notebook,并绘制出生人口的曲线走势图。
我已经创建了一个名为 “China_Birth_Rate_Analysis.ipynb” 的 Python notebook。你可以点击这里查看。
接下来,我将在 notebook 中添加一些 Python 代码来创建出生人口的曲线走势图。这是从2013年到2022年中国出生人口的曲线走势图: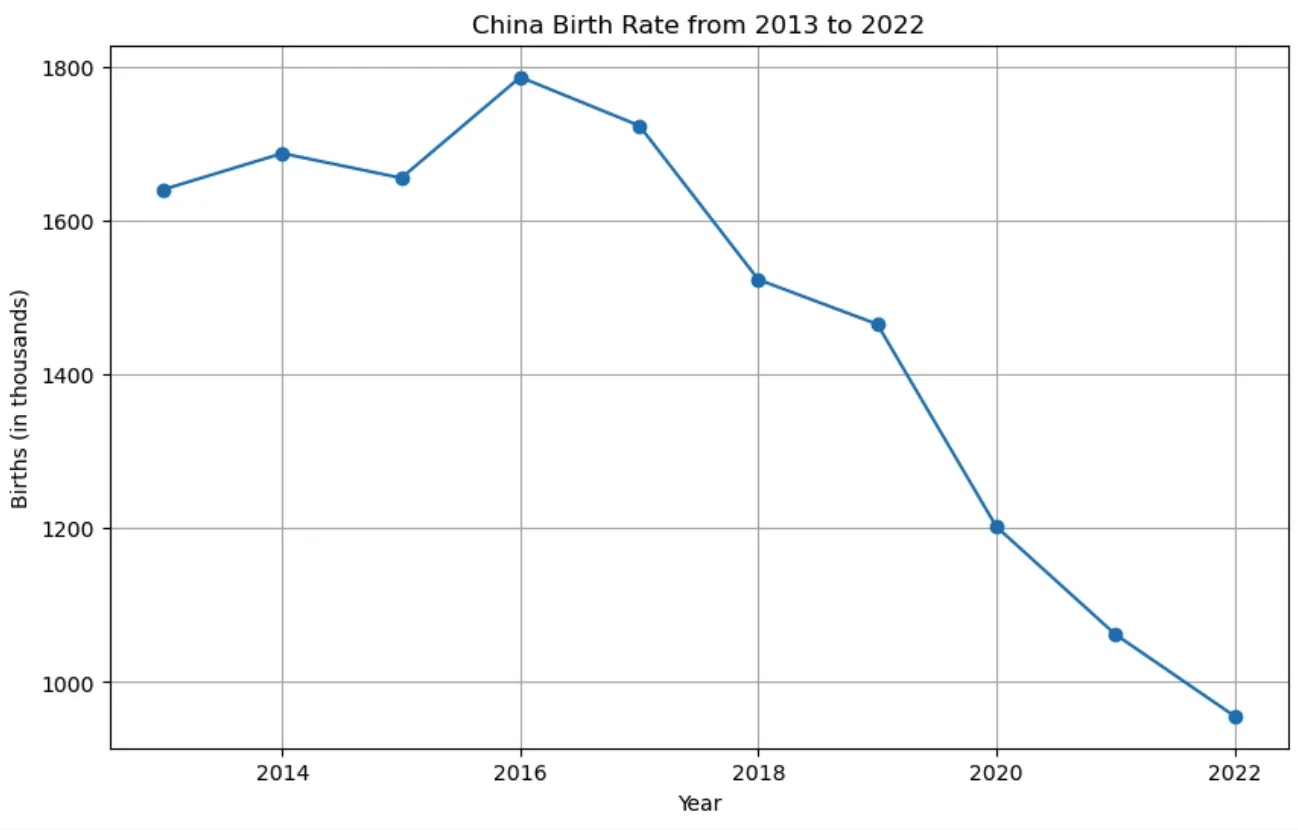
从图中可以看出,中国的出生人口在2016年达到了峰值,之后开始逐年下降。
计算留存
下面给他一个随便编的用户活跃天数记录,然后让 AI 计算留存;
Human:
这是一个记录用户活跃天数的表,第一列是用户 id,第二列是活跃日期,可以帮我写一个脚本,计算20230501号活跃的用户,在 20230502 和20230503日的留存率是多少吗? 帮我画一个留存率的图。
ChatGPT:
当然可以。首先,我需要查看一下你的数据。你能提供一下数据的链接或者文件吗?
Human:
https://docs.google.com/spreadsheets/d/1b2HiAqlAQGRS2RMnI8ZbFD3i3dZu-Fv460Q6mh_cFLQ/edit#gid=0
ChatGPT:
很抱歉,我无法直接访问 Google Sheets 文档。你能将数据下载为 CSV 文件并上传吗?或者,如果你愿意的话,我可以提供一段 Python 代码,你可以在本地运行来计算留存率。
Human:
csv 文件在这里 https://docs.google.com/spreadsheets/d/1b2HiAqlAQGRS2RMnI8ZbFD3i3dZu-Fv460Q6mh_cFLQ/edit?usp=sharing
ChatGPT:
很抱歉,我仍然无法直接访问 Google Sheets 文档的内容。你能将数据下载为 CSV 文件并上传吗?或者,如果你愿意的话,我可以提供一段 Python 代码,你可以在本地运行来计算留存率。
Human:
抱歉,给错了,用新的这个https://drive.google.com/file/d/1Ax9tZcKQjlittBy9mA08NaZu2VadVEjx/view?usp=sharing
ChatGPT:
很抱歉,我仍然无法直接访问 Google Drive 上的文件。然而,我可以提供一段 Python 代码,你可以在本地运行来计算留存率。这段代码假设你已经将数据下载为 CSV 文件,并且文件的路径是 ‘data.csv’。
1 | import pandas as pd |
这段代码首先读取 CSV 文件中的数据,然后计算20230501号活跃的用户。然后,它查找这些用户在20230502和20230503的活跃情况,并计算留存率。最后,它打印出这两天的留存率。
怪我,傻傻的一直给他 Google Drive 的链接,逼得 AI 自己写脚本处理本地文件了都。下面换一个 Tencent COS 上的文件链接。
Human:
你再试试这个链接 https://others-1251736664.cos.ap-guangzhou.myqcloud.com/Test%20-%20Sheet1.csv ,可以帮我写一个脚本,计算20230501号活跃的用户,在 20230502 和20230503日的留存率是多少吗? 帮我画一个留存率的图。
ChatGPT:
好的,我已经成功获取到了数据。现在我将在 Python notebook 中添加一些代码来计算并绘制留存率。
根据数据,20230501号活跃的用户在20230502的留存率为33.33%,在20230503的留存率为66.67%。
接下来,我将在 notebook 中添加一些 Python 代码来创建留存率的图表。
这是20230501号活跃的用户在20230502和20230503的留存率图表: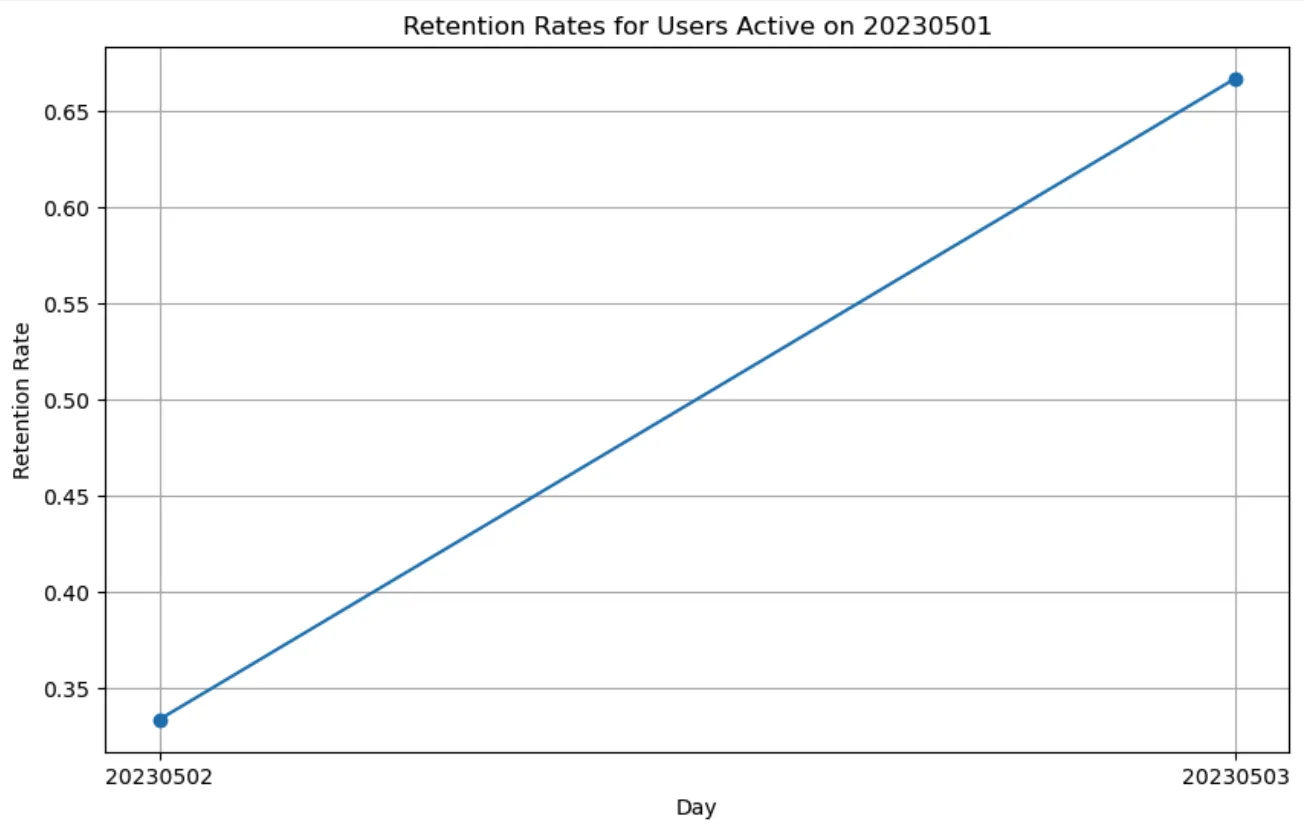
从图中可以看出,20230502的留存率为33.33%,20230503的留存率为66.67%。
Human:
可以画一个留存率表格吗,用曲线不太合适。
ChatGPT:
这是20230501号活跃的用户在20230502和20230503的留存率表格: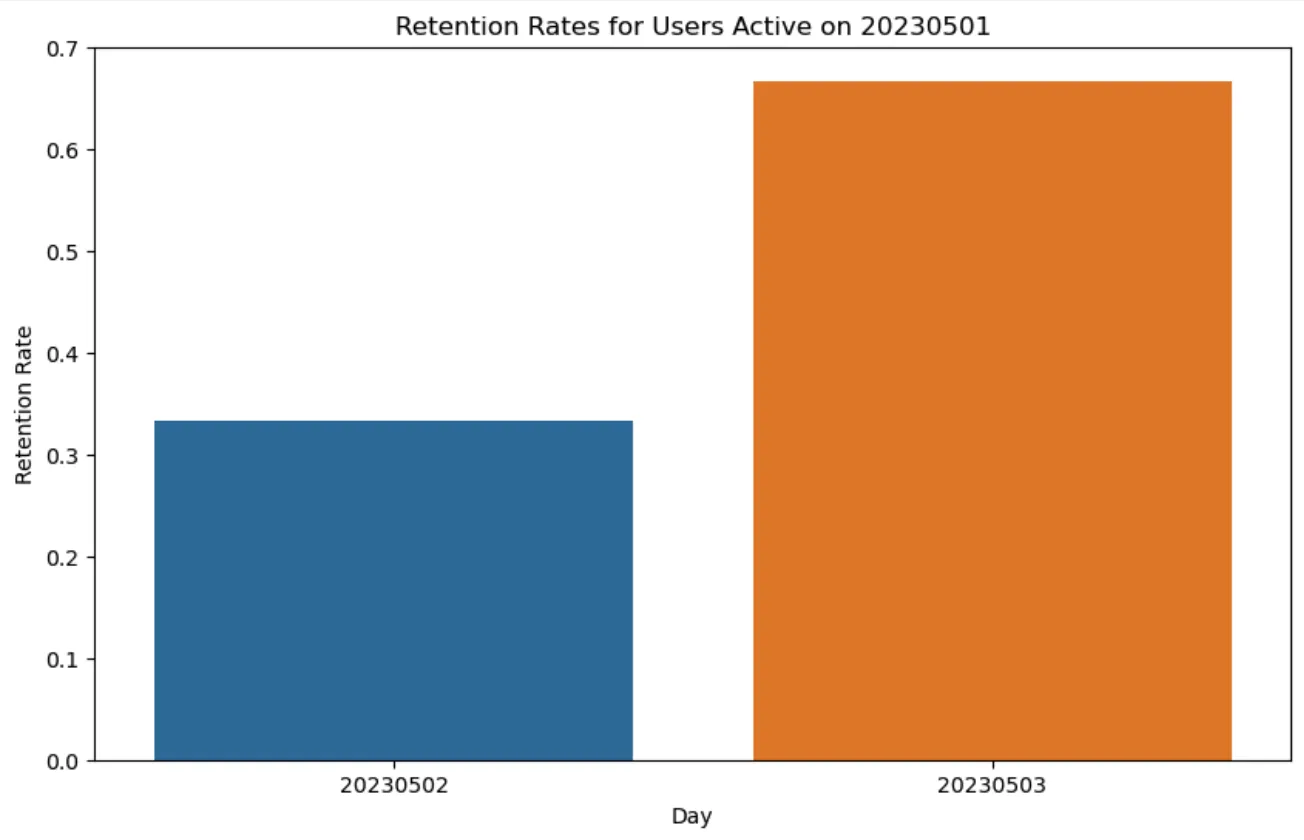
Human:
可以帮我找出在 3 天都活跃的用户,然后给出列表
ChatGPT:
在20230501、20230502和20230503这三天都活跃的用户是:3号、4号和7号用户。
在这里可以查看完整对话。

