深入理解基于 eBPF 的 C/C++ 内存泄漏分析
对于 C/C++ 程序员来说,内存泄露问题是一个老生常谈的问题。排查内存泄露的方法有很多,比如使用 valgrind、gdb、asan、tsan 等工具,但是这些工具都有各自的局限性,比如 valgrind 会使程序运行速度变慢,gdb 需要了解代码并且手动打断点,asan 和 tsan 需要重新编译程序。对于比较复杂,并且在运行中的服务来说,这些方法都不是很方便。

好在有了 eBPF,我们可以使用它来分析内存泄露问题,不需要重新编译程序,对程序运行速度的影响也很小。eBPF 的强大有目共睹,不过 eBPF 也不是银弹,用来分析内存泄露也还是有很多问题需要解决,本文接下来就来探讨一下基于 eBPF 检测会遇到的常见问题。
内存泄露模拟
在 C/C++ 中,内存泄露是指程序在运行过程中,由于某些原因导致未能释放已经不再使用的内存,从而造成系统内存的浪费。内存泄露问题一旦发生,会导致程序运行速度减慢,甚至进程 OOM 被杀掉。内存泄露问题的发生,往往是由于在编写程序时,没有及时释放内存;或者是由于程序设计的缺陷,导致程序在运行过程中,无法释放已经不再使用的内存。
下面是一个简单的内存泄露模拟程序,程序会在循环中分配内存,但是没有释放,从而导致内存泄露。main 程序如下,发生泄露的函数调用链路是 main->caller->slowMemoryLeak:
1 |
|
其中内存泄露的代码在 slowMemoryLeak 函数中,具体如下:
1 | namespace LeakLib { |
注意这里编译的时候,带了帧指针选项(由 -fno-omit-frame-pointer 选项控制),这是因为 eBPF 工具需要用到帧指针来进行调用栈回溯。如果这里忽略掉帧指针的话(-fomit-frame-pointer),基于 eBPF 的工具就拿不到内存泄露的堆栈信息。完整编译命令如下(-g 可以不用加,不过这里也先加上,方便用 gdb 查看一些信息):
1 | g++ main.cpp leak_lib.cpp -o main -fno-omit-frame-pointer -g |
memleak 分析
接下来基于 eBPF 来进行内存分析泄露,BCC 自带了一个 memleak 内存分析工具,可以用来分析内存泄露的调用堆栈。拿前面的示例泄露代码来说,编译后执行程序,然后执行内存泄露检测 memleak -p $(pgrep main) --combined-only。
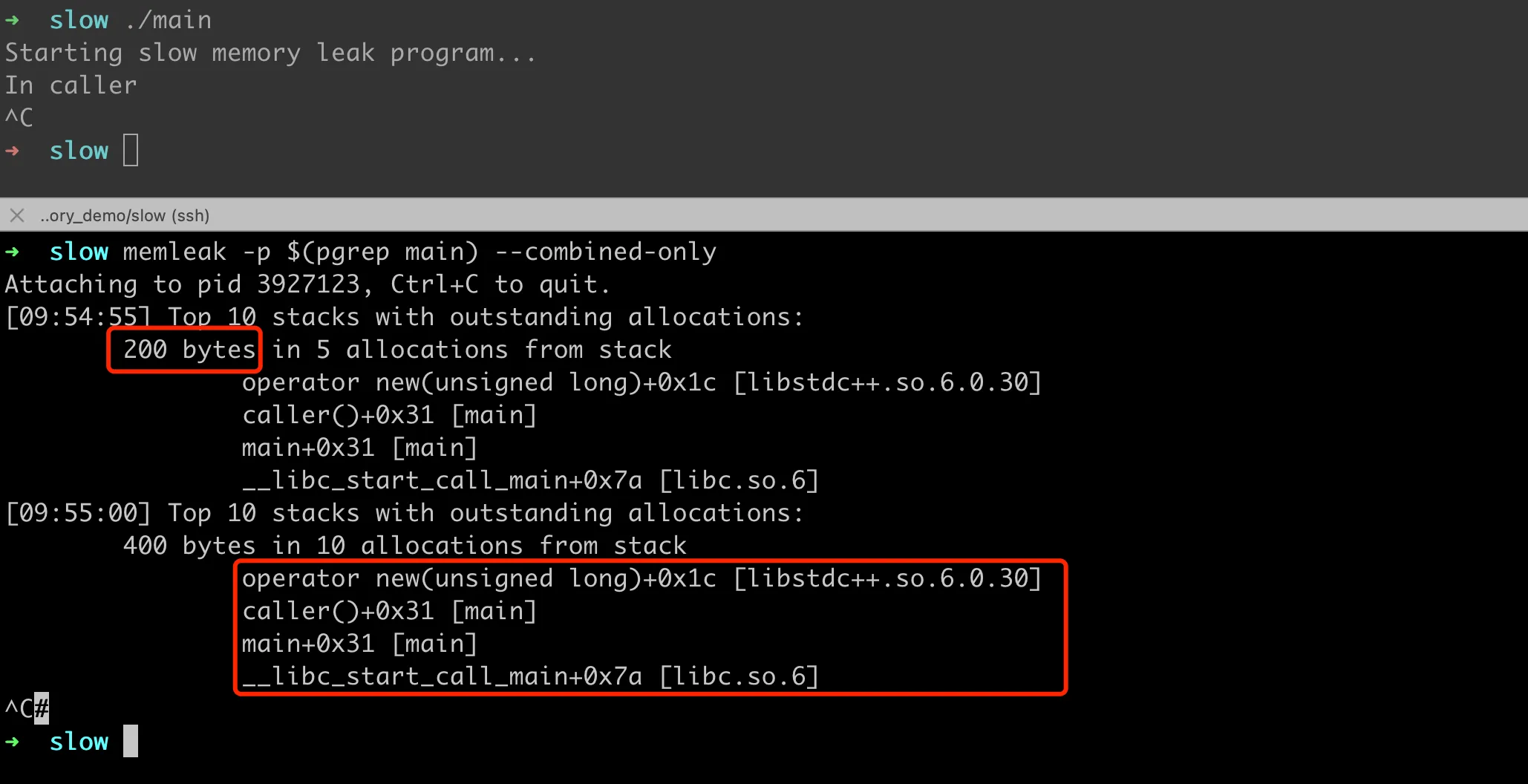
目前版本的 memleak 工具有 bug,在带 --combined-only 打印的时候,会报错。修改比较简单,我已经提了 PR #4769,已经被合并进 master。仔细看脚本的输出,发现这里调用堆栈其实不太完整,丢失了 slowMemoryLeak 这个函数调用。
1 | [11:19:44] Top 10 stacks with outstanding allocations: |
调用链不完整
这里为啥会丢失中间的函数调用呢?我们知道eBPF 相关的工具,是通过 frame pointer 指针来进行调用堆栈回溯的,具体原理可以参考朋友的文章 消失的调用栈帧-基于fp的栈回溯原理解析。如果遇到调用链不完整,基本都是因为帧指针丢失,下面来验证下。
首先用 objdump -d -S main > main_with_source.asm 来生成带源码的汇编指令,找到 slowMemoryLeak 函数的汇编代码,如下图所示:
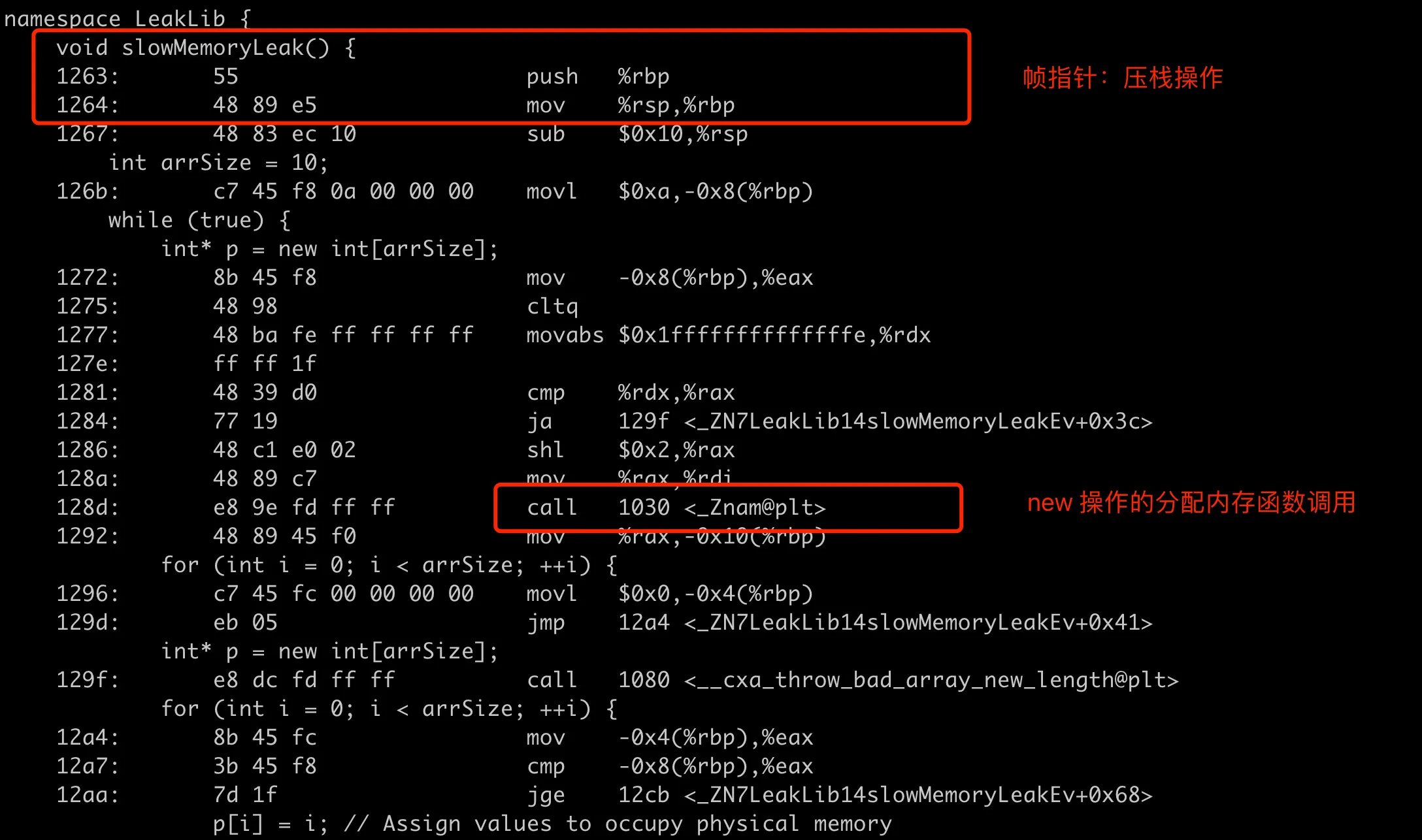
从这段汇编代码中,可以看到 new int[] 对应的是一次 _Znam@plt 的调用。这是 C++ 的 operator new[] 的名字修饰(name mangling)后的形式,如下:
1 | c++filt _Znam |
我们知道在 C++ 中,new 操作用来动态分配内存,通常会最终调用底层的内存分配函数如 malloc。这里 _Znam@plt 是通过 PLT(Procedure Linkage Table) 进行的,它是一个动态解析的符号,通常是 libstdc++(或其他 C++ 标准库的实现)中实现的 operator new[]。_Znam@plt 对应的汇编代码如下:
1 | 0000000000001030 <_Znam@plt>: |
这里并没有像 slowMemoryLeak 调用一样去做 push %rbp 的操作,所以会丢失堆栈信息。这里为什么会没有保留帧指针呢?前面编译的时候带了 -fno-omit-frame-pointer 能保证我们自己的代码带上帧指针,但是对于 libstdc++ 这些依赖到的标准库,我们是无法控制的。当前系统的 C++ 标准库在编译的时候,并没有带上帧指针,可能是因为这样可以减少函数调用的开销(减少执行的指令)。是否在编译的时候默认带上 -fno-omit-frame-pointer 还是比较有争议,文章最后专门放一节:默认开启帧指针来讨论。
tcmalloc 泄露分析
如果想拿到完整的内存泄露函数调用链路,可以带上帧指针重新编译 libstdc++,不过标准库重新编译比较麻烦。其实日常用的比较多的是 tcmalloc,内存分配管理更加高效些。这里为了验证上面的代码在 tcmalloc 下的表现,我用 -fno-omit-frame-pointer 帧指针编译了 tcmalloc 库。如下:
1 | git clone https://github.com/gperftools/gperftools.git |
接着运行上面的二进制,重新用 memleak 来检查内存泄露,**注意这里用 -O 把 libtcmalloc.so 动态库的路径也传递给了 memleak。**参数值存在 obj 中,在 attach_uprobe 中用到,指定了要附加 uprobes 或 uretprobes 的二进制对象,可以是要跟踪的函数的库路径或可执行文件。详细文档可以参考 bcc: 4. attach_uprobe。比如下面的调用方法:
1 | # 在 libc 的 getaddrinfo 函数入口打桩,当进入函数时,会调用自定义的 do_entry 函数 |
注意在前面的示例中,没有指定 -O,默认就是 “c”,也就是用 libc 分配内存。在用 tcmalloc 动态库的时候,这里 attach_uprobe 和 attach_uretprobe 必须要指定库路径:
1 | bpf.attach_uprobe(name=obj, sym=sym, fn_name=fn_prefix + "_enter", pid=pid) |
不过工具的输出有点出乎语料,这里竟然没有输出任何泄露的堆栈了:
1 | memleak -p $(pgrep main) --combined-only -O /usr/local/lib/libtcmalloc.so |
明明 new 分配的内存没有释放,为什么 eBPF 的工具检测不到呢?
深入工具实现
在猜测原因之前,先仔细看下 memleak 工具的代码,完整梳理下工具的实现原理。首先能明确的一点是,工具最后的输出部分,是每个调用栈以及其泄露的内存量。为了拿到这个结果,用 eBPF 分别在内存分配和释放的时候打桩,记录下当前调用栈的内存分配/释放量,然后进行统计。核心的逻辑如下:
gen_alloc_enter: 在各种分配内存的地方,比如 malloc, cmalloc, realloc 等函数入口(malloc_enter)打桩(attach_uprobe),获取当前调用堆栈 id 和分配的内存大小,记录在名为 sizes 的字典中;gen_alloc_exit2: 在分配内存的函数退出位置(malloc_exit)打桩(attach_uretprobe),拿到此次分配的内存起始地址,同时从 sizes 字段拿到分配内存大小,记录 (address, stack_info) 在 allocs 字典中;同时用update_statistics_add更新最后的结果字典 combined_allocs,存储栈信息和分配的内存大小,次数信息;gen_free_enter: 在释放内存的函数入口处打桩(gen_free_enter),从前面 allocs 字典中根据要释放的内存起始地址,拿到对应的栈信息,然后用update_statistics_del更新结果字典 combined_allocs,也就是在统计中,减去当前堆栈的内存分配总量和次数。
GDB 堆栈跟踪
接着回到前面的问题,tcmalloc 通过 new 分配的内存,为啥统计不到呢?很大可能是因为 tcmalloc 底层分配和释放内存的函数并不是 malloc/free,也不在 memleak 工具的 probe 打桩的函数内。那么怎么知道前面示例代码中,分配内存的调用链路呢?比较简单的方法就是用 GDB 调试来跟踪,注意编译 tcmalloc 库的时候,带上 debug 信息,如下:
1 | ./configure CXXFLAGS="-g -fno-omit-frame-pointer" CFLAGS="-g -fno-omit-frame-pointer" |
编译好后,可以用 objdump 查看 ELF 文件的头信息和各个段的列表,验证动态库中是否有 debug 信息,如下:
1 | objdump -h /usr/local/lib/libtcmalloc_debug.so.4 | grep debug |
接着重新用 debug 版本的动态库编译二进制,用 gdb 跟踪进 new 操作符的内部,得到结果如下图。可以看到确实没有调用 malloc 函数。
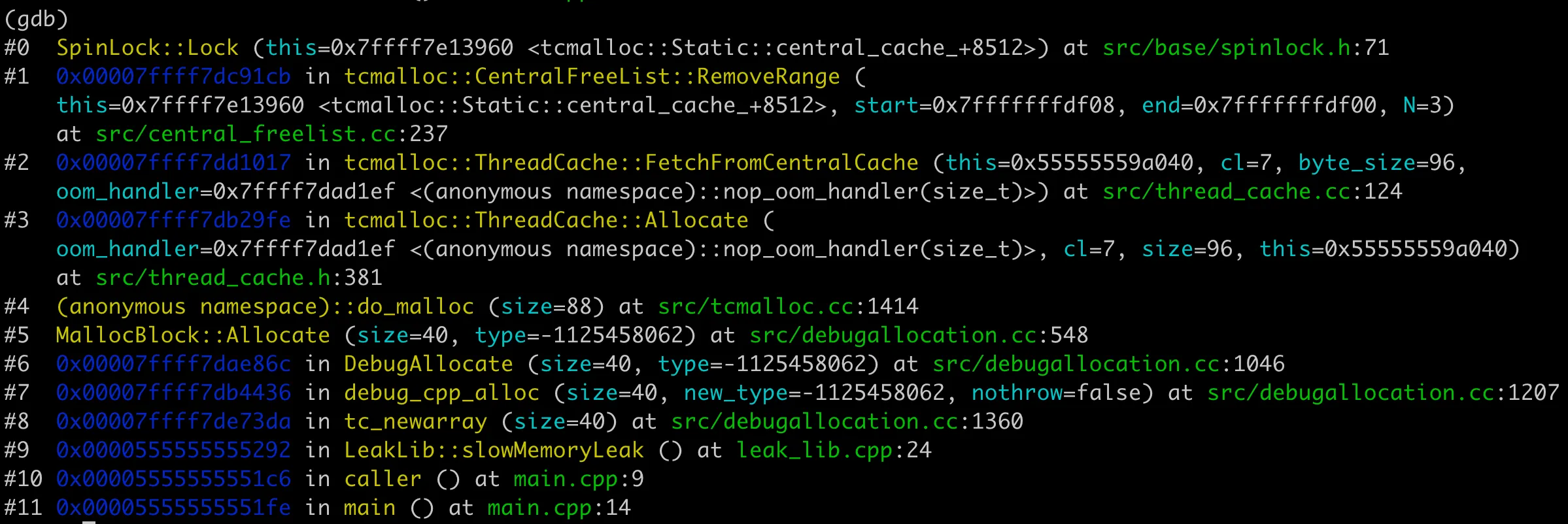
其实 tcmalloc 的内存分配策略还是很复杂的,里面有各种预先分配好的内存链表,申请不同大小的内存空间时,有不少的策略来选择合适的内存地址。
正常内存泄露分析
前面不管是 glibc 还是 tcmalloc,用 new 来分配内存的时候,memleak 拿到的分析结果都不是很完美。这是因为用 eBPF 分析内存泄露,必须满足两个前提:
- 编译二进制的时候带上帧指针(frame pointer),如果有依赖到标准库或者第三方库,也都必须带上帧指针;
- 实际分配内存的函数,必须在工具的 probe 打桩的函数内,比如 malloc, cmalloc, realloc 等函数;
那么下面就来看下满足这两个条件后,内存泄露的分析结果。修改上面的 leak_lib.cpp 中内存分配的代码:
1 | // int* p = new int[arrSize]; |
然后重新编译运行程序,这时候 memleak 就能拿到完整的调用栈信息了,如下:
1 | g++ main.cpp leak_lib.cpp -o main -fno-omit-frame-pointer -g |
如果分配内存的时候用 tcmalloc,也是可以拿到完整的泄露堆栈。
内存火焰图可视化
在我之前的 复杂 C++ 项目堆栈保留以及 ebpf 性能分析 这篇文章中,用 BCC 工具做 cpu profile 的时候,可以用 FlameGraph 把输出结果转成 CPU 火焰图,很清楚就能找到 cpu 的热点代码。对于内存泄露,我们同样也可以生成内存火焰图。
内存火焰图的生成步骤也类似 cpu 的,先用采集工具比如 BCC 脚本采集数据,然后将采集到的数据转换为 FlameGraph 可以理解的格式,之后就可以使用 FlameGraph 脚本将转换后的数据生成一个 SVG 图像。每个函数调用都对应图像中的一块,块的宽度表示该函数在采样中出现的频率,从而可以识别资源使用的热点。FlameGraph 识别的每行数据的格式通常如下:
1 | [堆栈跟踪] [采样值] |
这里的“堆栈跟踪”是指函数调用栈的一个快照,通常是一个由分号分隔的函数名列表,表示从调用栈底部(通常是 main 函数或者线程的起点)到顶部(当前执行的函数)的路径。而“采样值”可能是在该调用栈上花费的 CPU 时间、内存使用量或者是其他的资源指标。对于内存泄露分析,采样值可以是内存泄露量,或者内存泄露次数。
可惜的是,现在的 memleak 还不支持生成可以转换火焰图的数据格式。不过这里改起来并不难,PR 4766 有实现一个简单的版本,下面就用这个 PR 里的代码为例,来生成内存泄露火焰图。
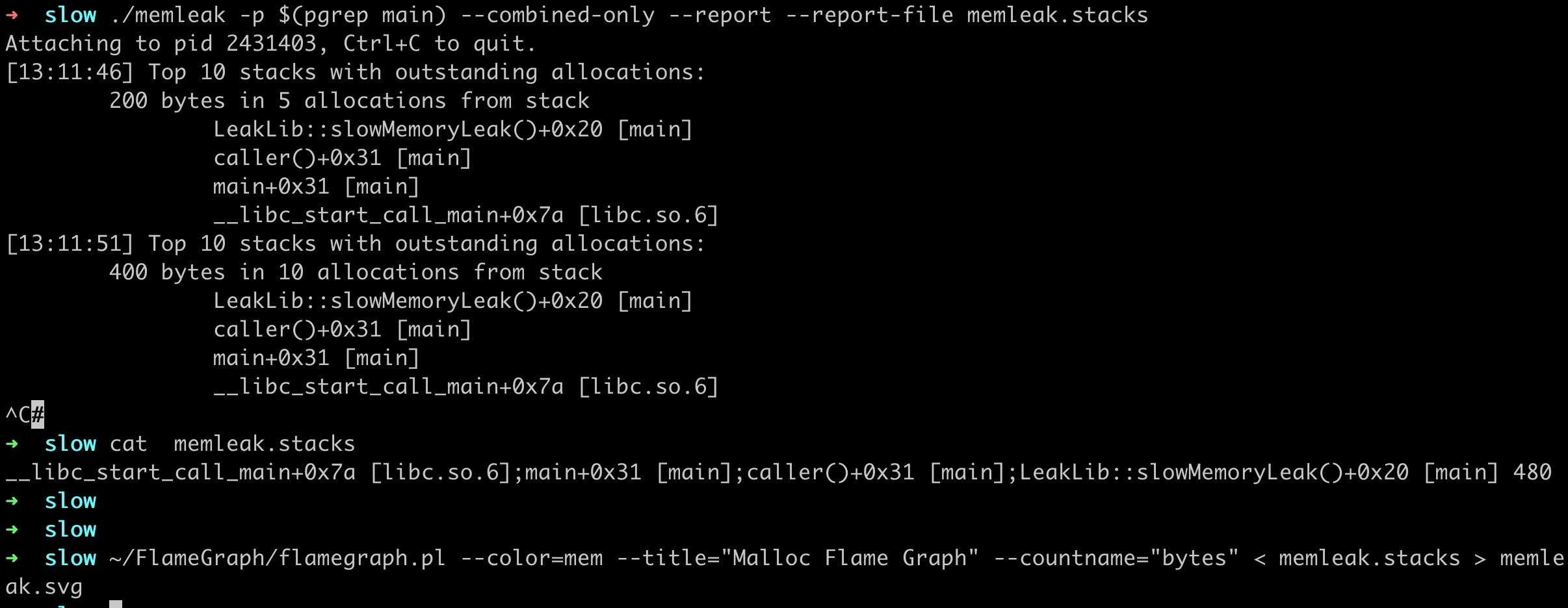
可以看到这里生成的采集文件很简单,如上面所说的格式:
1 | __libc_start_call_main+0x7a [libc.so.6];main+0x31 [main];caller()+0x31 [main];LeakLib::slowMemoryLeak()+0x20 [main] 480 |
最后用 FlameGraph 脚本来生成火焰图,如下:

默认开启帧指针
文章最后再来解决下前面留下的一个比较有争议的话题,是否在编译的时候默认开启帧指针。我们知道 eBPF 工具依赖帧指针才能进行调用栈回溯,其实栈回溯的方法有不少,比如:
- DWARF: 调试信息中增加堆栈信息,不需要帧指针也能进行回溯,但缺点是性能比较差,因为需要将堆栈信息复制到用户空间来进行回溯;
- ORC: 内核中为了展开堆栈创建的一种格式,其目的与 DWARF 相同,只是简单得多,不能在用户空间使用;
- CTF Frame:一种新的格式,比 eh_frame 更紧凑,展开堆栈速度更快,并且更容易实现。仍在开发中,不知道什么时候能用上。
所以如果想用比较低的开销,拿到完整的堆栈信息,帧指针是目前最好的方法。既然帧指针这么好,为什么有些地方不默认开启呢?在 Linux 的 Fedora 发行版社区中,是否默认打开该选项引起了激烈的讨论,最终达成一致,在 Fedora Linux 38 中,所有的库都会默认开启 -fno-omit-frame-pointer 编译,详细过程可以看 Fedora wiki: Changes/fno-omit-frame-pointer。
上面 Wiki 中对打开帧指针带来的影响有一个性能基准测试,从结果来看:
- 带帧指针使用 GCC 编译的内核,速度会慢 2.4%;
- 使用帧指针构建 openssl/botan/zstd 等库,没有受到显着影响;
- 对于 CPython 的基准测试性能影响在 1-10%;
- Redis 的基准测试基本没性能影响;
当然,不止是 Fedora 社区倾向默认开启,著名性能优化专家 Brendan Gregg 在一次分享中,建议在 gcc 中直接将 -fno-omit-frame-pointer 设为默认编译选项:
• Once upon a tme, x86 had fewer registers, and the frame pointer register was reused for general purpose to improve performance. This breaks system stack walking.
• gcc provides -fno-omit-frame-pointer to fix this – Please make this the default in gcc!
此外,在一篇关于 DWARF 展开的论文 提到有 Google 的开发者在分享中提到过,google 的核心代码编译的时候都带上了帧指针。
参考文章
基于 eBPF 的内存泄漏(增长)通用分析方法探索
Memory Leak (and Growth) Flame Graphs
DWARF-based Stack Walking Using eBPF
Trace all functions in program with bpftrace
Using BPF Tools: Chasing a Memory Leak
TCMalloc Overview

