零基础用 Bert 训练并部署文本分类模型
之前帮小盛律师 做过一个工具,定期从网上筛选一些帖子,看看是不是法律咨询类的。这里就需要对文本进行分类,判断指定帖子正文是不是涉及到法律问题。作为一个后台开发,没接触过自然语言处理,也就之前读书的时候,了解过一些机器学习的基本原理,但是也没有实际做过分类任务。好在现在有 ChatGPT,于是就用它的 API 来做分类。
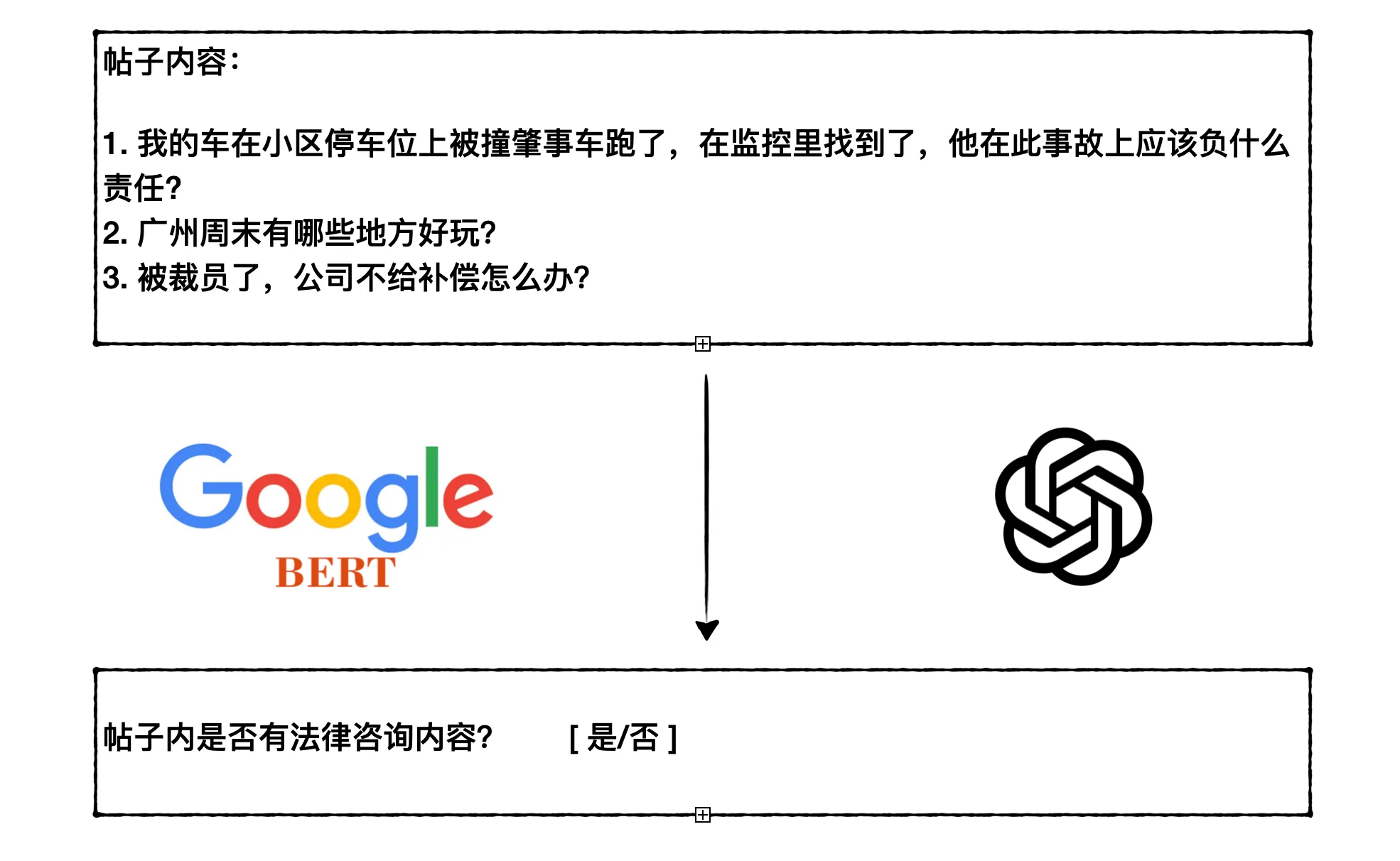
用 ChatGPT 跑了一段时间,发现用 ChatGPT 用来做分类有两个问题:
- 成本贵。目前用的是 GPT3.5 模型,如果帖子数量多的话,每天也需要几美元。所以现在做法是先用关键词过滤,然后再拿来用 GPT3.5 模型进行分类,这样会漏掉一些没有带关键词的相关帖子。
- 误识别。有些帖子不是法律咨询问题,但是也会被 GPT3.5 误判。这种幻觉问题,试过改进 Prompt,还是不能完全解决。可以看我在 真实例子告诉你 ChatGPT 是多会胡编乱造! 里面的例子。
于是想着自己训练一个模型,用来做文本分类。自然语言处理中最著名的就是 bert 了,这里我基于 bert-base-chinese 训练了一个分类模型,效果还不错。本文主要记录数据集准备、模型训练、模型部署的整个过程,在 ChatGPT 的帮助下,整个过程比想象中简单很多。
在线体验
开始之前,先给大家体验下这里的模型(只有博客原文地址才可以体验到)。在下面输入框写一段文本,点击模型实时预测按钮,就可以看到预测结果。由于个人服务器配置太差,这里单个预测大概耗时在 2s 左右,同一时间只能处理 1 个请求。如果耗时太久,可以等会再试。
比如下面这些就是咨询类文本:
我的车在小区停车位上被撞肇事车跑了,在监控里找到了,他在此事故上应该负什么责任
2021年11月份在武安市智慧城跟个人包工头做工,最后拖欠工资不给,请问怎么可以要回?
下面这些为非法律咨询类文本,摘自我博客里的文章标题:
Bazel 缺失依赖导致的 C++ 进程 coredump 问题分析
ChatGPT 渗透力分析:搜索热度、需求图谱与人群特征
数据集准备
训练模型的前提是得有数据集,具体到我这个分类任务,就需要找到很多法律咨询类文本和非法律咨询类文本。
非法律咨询类的文本很好找,我这里用的是程序员社区 V2EX 上面的帖子内容。V2EX 也提供了方便的 API,可以直接获取到帖子的标题和正文。用了一天时间,大概爬到了 20 万条帖子正文,保存在 postgres 数据库中。其实这的帖子中,也有少量的法律咨询内容,不过整体比例很小,对模型整体训练效果影响应该不大。法律咨询类的文本比较难找,经过一番尝试,最后在一个公开站点上找到了一些,一共是大概 20 万条。
这里对上面两类文本,分开保存了两个文件,里面每行都是一个 json 文件,包含文本内容。下面是一些样例:
| 文本内容 | 是否咨询 |
|---|---|
| 起诉离婚会不会查对方或者双方银行卡流水账或者存款。 | 是 |
| 被执行人有能力还款,比如说工作收入,月收入4千,每月还一千,但被执行人躲避分文不还,能否对其追责,法律有什么规定吗? | 是 |
| 本人借钱给别人,别人总说还可就是不还,当时没写借条,我想问问怎么办! | 是 |
| 我想找这个安卓游戏 apk 文件里面的图标 | 否 |
| 没有开发过服务号,我想问下,服务号收到推送消息,然后点击消息跳转到第三方应用,这个能实现吗?第三方应用没有在应用市场上架 | 否 |
| 除了跟竞争对手拼屏占比,看起来酷弦点,实在想不出来有啥实际意义,还是有边框的比较踏实 | 否 |
模型训练
数据集准备好了,就可以开始训练模型了。之前没有怎么接触过 bert,也没做过神经网络模型训练,好在有了 ChatGPT,很快就能写一个完整的训练代码。我这里使用 pytorch 进行训练,ChatGPT 给出了完整的训练代码,以及详细的代码解释。中间有任何不懂的地方,都是先问 AI,然后再结合一些资料,来慢慢理解。
完整的训练脚本在 Gist 上,整体流程总结起来如下:
- 数据加载与预处理:从 Json 文件中加载数据集,将数据转换为 (文本, 标签) 格式并随机打乱。使用
train_test_split将数据划分为训练集和验证集。 - 使用
BERT Tokenizer进行编码:使用 BertTokenizer 对文本进行分词和编码,包括添加特殊标记、截断和填充。 - 构建数据集和数据加载器:将编码后的数据转换为 TensorDataset。使用 DataLoader 创建训练集和验证集的数据加载器。
- 定义模型、损失函数和优化器:定义一个包含 BERT 模型和额外分类层的自定义 PyTorch 模型。使用 Focal Loss 作为损失函数,适合处理类别不平衡的问题。使用 AdamW 优化器。
- 模型训练和验证:在训练循环中,按批处理数据、计算损失、反向传播并更新模型参数。在每个训练周期结束时,使用验证集评估模型性能。应用学习率调度器和早停机制以优化训练过程。
- 性能评估:计算并打印准确度、精确度、召回率和 F1 分数等指标。
- 模型保存:在性能提升时保存模型的状态。
这里甚至都不需要什么神经网络和机器学习的基础,只需要有数据集和 ChatGPT,就能不断调整代码,训练一个效果可以的模型。不过作为有追求的开发,还是想尽力搞明白每行代码背后到底有着什么样的原理,这样才能更好地理解模型训练的过程。除了不断追问 ChatGPT,并对它的回答进行各种验证,这里也发现了一个不错的深度学习入门教程,《动手学深度学习》,里面有很多深度学习的知识,还有代码实践,非常适合入门。
模型的训练离不开 GPU 机器,个人没有好的 GPU 的话,可以用 Google Colab 上面的 T4 GPU 免费额度来训练。不过内存有限制,训练的时候,注意适当调小 batch_size,我一般在 colab 上用 batch_size=16。如果数据集太大,这里训练一轮耗时可能比较就,可能免费额度只够训练几个轮次。
模型部署
模型训练完之后,会保存一个 torch 的模型文件 model.pt,怎么用这个模型文件部署一个 http 服务呢?简单来说,可以用 ONNX Runtime + Flask + Gunicorn + Docker + Nginx 来部署。
- ONNX Runtime 是一个高性能的推理引擎,可以用来加载和运行模型。
- Flask 是一个 Python 的 Web 框架,用来写 Web 服务。Gunicorn 是一个 Python WSGI HTTP 服务器,用来启动 Flask 服务。
- Docker 是一个容器化工具,用来打包和运行服务。
整体部署结构可以参考下图:
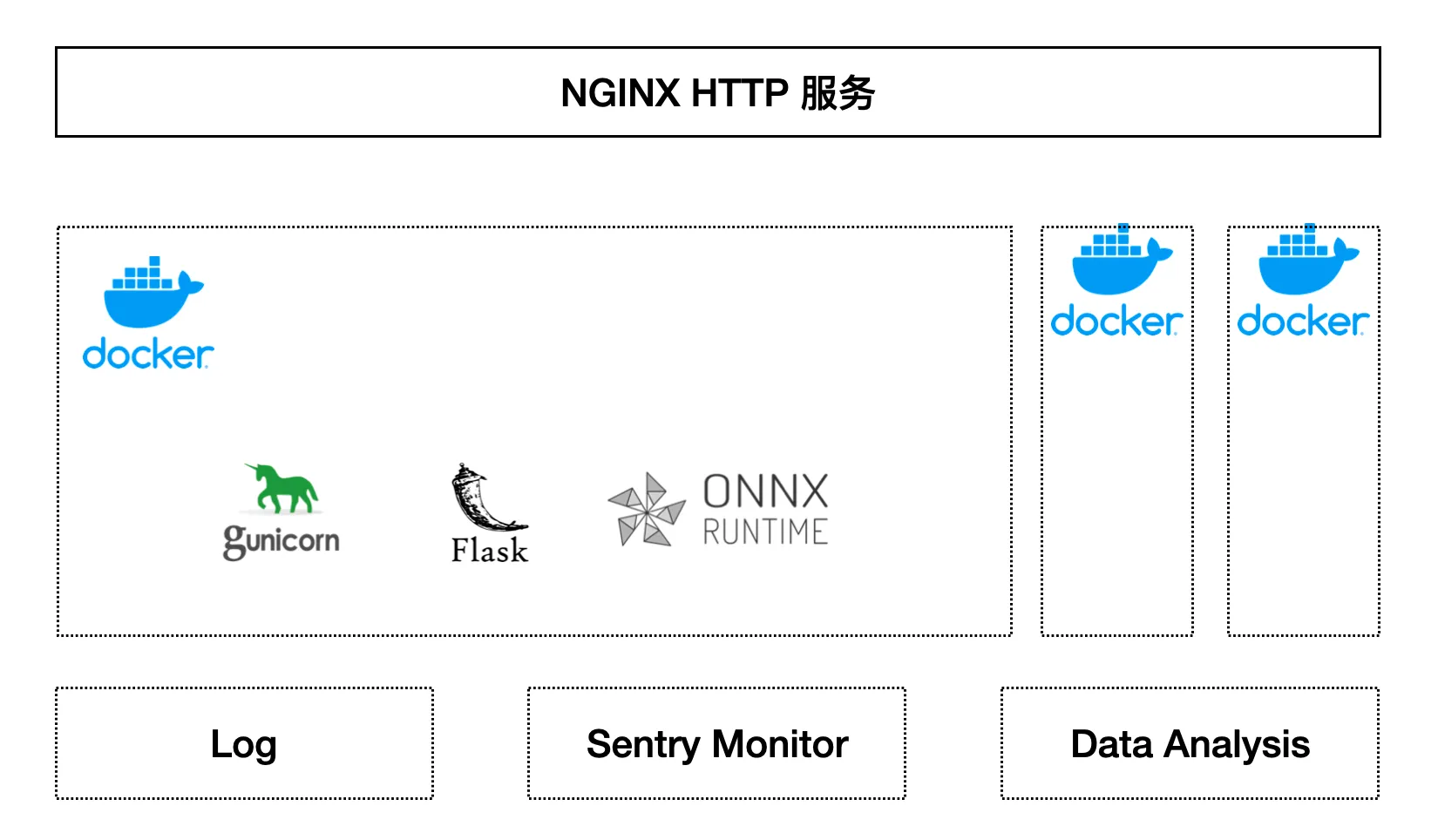
Nginx 接收到 HTTP 请求后,会转发给 Gunicorn,Gunicorn 会启动 Flask 服务,Flask 服务里用加载好的 ONNX 模型文件和推理环境,对请求的文本进行预测,最后返回预测结果。Flask 服务的核心代码很简单,如下:
1 | session = ort.InferenceSession('model.onnx') |
为了方便部署 Gunicorn,Flask以及各种依赖,这里用 Docker 来对其进行打包。Dockerfile 如下:
1 | FROM python:3.8-slim |
然后就可以用下面命令启动服务:
1 | docker build -t lawer_model . |
Nginx 反向代理的配置这里就不提了,至此,整个服务已经部署好了。不过为了更好地监控服务,可以用 Sentry 进行性能监控和错误跟踪。服务还可以适当增加一些日志,方便排查问题。
另外,这里我服务域名是 api.selfboot.cn,为了能够在博客页面中访问,还需要放开 CORS 限制,以便允许跨域访问。这里用的是 flask-cors,只需要在 Flask 服务中加上下面这行代码即可:
1 | CORS(app, resources={r"/*": {"origins": ["https://selfboot.cn"]}}) |
到这里为止,作为演示服务,上面基本够用了。不过要作为一个正式的线上服务,还需要考虑容灾等问题,可能需要引入 k8s 等集群部署方案,这里就不展开了。
一些不足
我用这个模型跑了一段时间,发现有些文本分类还不是很准确。比如下面这些也会被模型误判为法律咨询问题:
朋友问我借钱,我到底要不要借给他呢?
借钱
我想咨询下,怎么才能赚更多钱呢?
考不上大学,我该怎么办?
这个和数据集还是有很大关系的,在法律咨询的数据集中有很多类似内容,导致模型学习到了错误的特征。有些关键词在咨询中出现频次比较高,导致只要有这些关键词的内容,模型就会偏向于认为是法律咨询。比如只输入 “借钱“,”我想咨询下“,模型都会判定为法律咨询。为了看到训练集中法律咨询文本的一些关键词分布,用这部分数据生成了词云,如下图:

如果想优化这里的话,需要在数据集上下功夫,比如针对性地增加一些非法律咨询类的文本,或者对数据集进行一些清洗,去掉一些噪声数据。这里我就没有继续优化了,目前的分类效果已经满足使用了。
AI 带来的改变
模型的训练和部署过程,放在以前可能会耗费我大量时间。因为需要查各种资料和文档,然后才能写训练代码,写部署服务,写 docker 配置。但是现在有了 ChatGPT,整个过程没费太多时间。本文的大部分代码都是在 ChatGPT 帮助下完成的,一些配置和细节,也是 ChatGPT 帮我完成的。比如下图中的 onnx 模型推理部分:
甚至连数据集的爬取代码,本文体验的输入框前端代码,也都上是 ChatGPT 帮忙完成的。自己要做的就是拆分任务,描述清楚任务,对 ChatGPT 的回答进行验证。
在极大提高效率的同时,ChatGPT 也可以帮忙学习新的领域。。比如之前对深度学习的理解,就是一知半解,现在实际用到了 bert,过程中也不断加深了深度学习的理解。在学习一个领域过程中,ChatGPT 完全可以充当一个老师的角色,还是那种能因人施教,可以随时提供帮助的老师。
每个人都值得拥有一个 ChatGPT,并尽早和它磨合好,最大限度发挥 AI 的作用。

