ChatGPT Prompt 最佳指南二:提供参考文本
本文是 ChatGPT Prompt 最佳指南系列的第二篇,全部系列文章:
- ChatGPT Prompt 最佳指南一:写清晰的说明;
- ChatGPT Prompt 最佳指南二:提供参考文本;
- ChatGPT Prompt 最佳指南三:复杂任务拆分;
- ChatGPT Prompt 最佳指南四:给模型思考时间;
- ChatGPT Prompt 最佳指南五:借助外部工具;
- ChatGPT Prompt 最佳指南六:系统基准评测;
OpenAI 可以理解和生成人类语言,帮助我们解答问题,写文章,甚至编程。然而,即使是 GPT-4,也有其局限性,其中之一就是上下文长度的限制。GPT-4 的上下文长度限制是由其内部架构决定的,简单来说,GPT-4 在处理输入时,会将输入的文本转化为一系列的“令牌”(tokens)。然而,GPT-4 只能处理一定数量的令牌,这就是所谓的“上下文长度”。超过这个长度,GPT-4 就无法全面理解输入的内容,这可能会影响其生成的输出的质量。
目前 OpenAI 的 GPT4 有两个模型,最多分别支持 8K 长度和 32K 长度的Token。其中 32K 长度 Token 之对少量人开放,大部分用的都是 4K 长度,因为 GPU 算力不够。好在随着 AI 的发展,应该会支持越来越长的 Token。OpenAI 也把支持更长的 token 作为 2023 年的主要目标了,参考 OpenAI’s plans according to Sam Altman。
Longer context windows — Context windows as high as 1 million tokens are plausible in the near future.
引用文本的好处
为了更好使用 GPT4 这些有 token 限制的模型,我们可以提供引用文本(reference text)。这是因为引用文本可以帮助模型更好地理解你的问题,并提供更准确的答案。这里有几个原因:
- 明确性:引用文本可以帮助明确你的问题,例如,如果你在问一个关于特定法律条款的问题,提供该法律条款的文本可以帮助模型更准确地理解你的问题。
- 上下文:即使模型的上下文长度限制增加,它仍然需要理解你的问题的上下文,引用文本可以提供这种上下文。
- 准确性:引用文本可以帮助模型提供更准确的答案,模型可能会根据引用文本中的信息来生成答案,而不是仅仅依赖于它的训练数据。
- 效率:即使模型可以处理更长的上下文,提供引用文本仍然可以提高效率,这是因为模型不需要处理不相关的信息,而可以直接关注到你的问题和相关的上下文。
所以,即使 OpenAI 的上下文长度限制增加,提供引用文本仍然是一个有用的策略。其实目前像 Claude 的模型,已经最大支持 100K 长度,大概是 7.6 万个英语单词,可以一次输入整本书籍让它分析了。
短文本直接引用
对于文本比较短的引用,可以直接贴到提问里面即可,比如:
- 如果你有一段关于气候变化的文章,并希望模型使用这篇文章的信息来回答问题,你可以这样提问:“根据以下关于气候变化的文章,全球变暖的主要原因是什么?”然后附上文章的内容。
- 如果你有一份报告,并希望模型使用报告中的数据来回答问题,你可以这样提问:“根据以下的年度销售报告,我们的最畅销产品是什么?”然后附上报告的内容。
- 如果你有一段法律条款,并希望模型使用这段条款来解释某个概念,你可以这样提问:“根据以下的法律条款,什么是知识产权?”然后附上法律条款的内容。
目前使用 GPT4 的插件,也可以直接将网页链接里面的内容提供给 GPT 来作为引用文本。比如我可以直接让它总结我们第一篇GPT4 提问技巧一:写清晰的说明的内容,如下
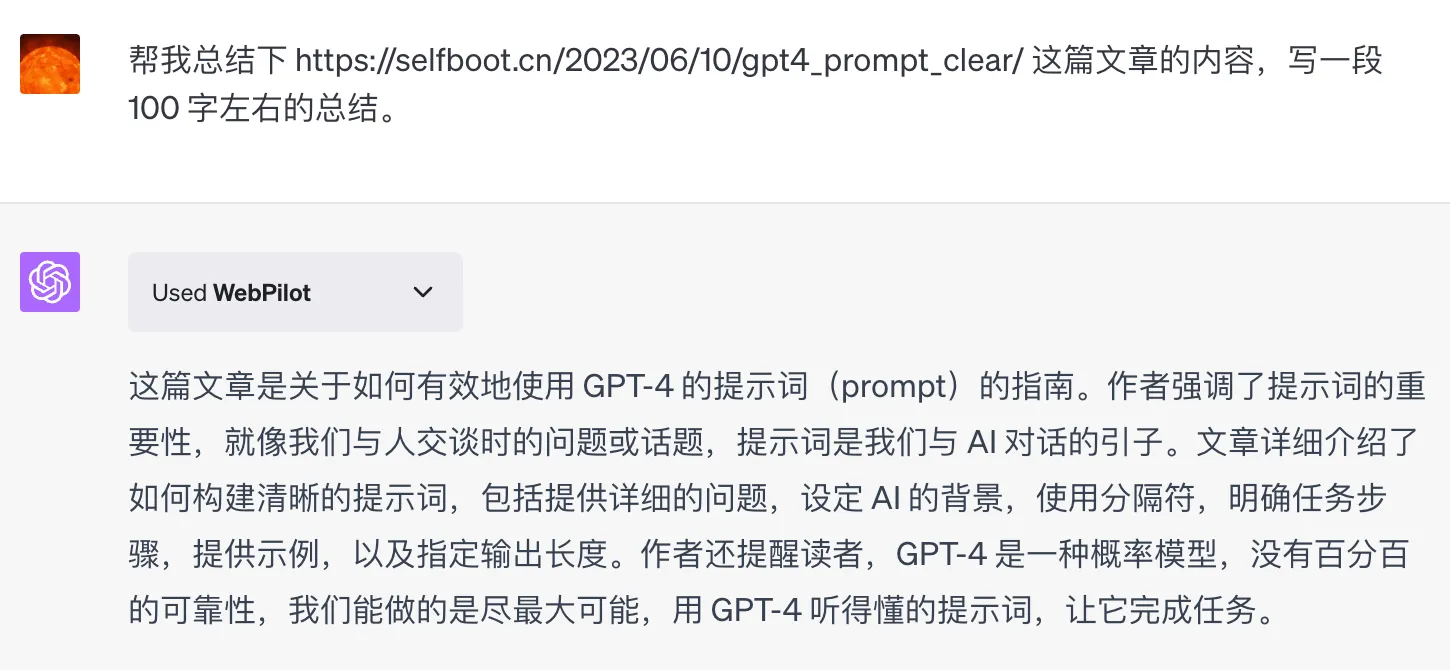
长文本引用相关部分
对于文本较长的引用,我们需要采取不同的策略。比如想让模型参考一本书或一篇长篇文章,可能需要选择最相关的部分,或者将关键信息提炼出来作为引用文本。如何从给定长文本找到和提问内容最相关的部分,最直观的方法就是关键词搜索。它通过在文本中查找与查询关键词完全匹配的词或短语来工作。这种方法的优点是简单易用,但缺点是它无法理解语义相似性。例如,如果你搜索”猫”,它不会返回包含”某种猫粮”或”宠物用品”的文档,除非这些确切的词在文档中出现。
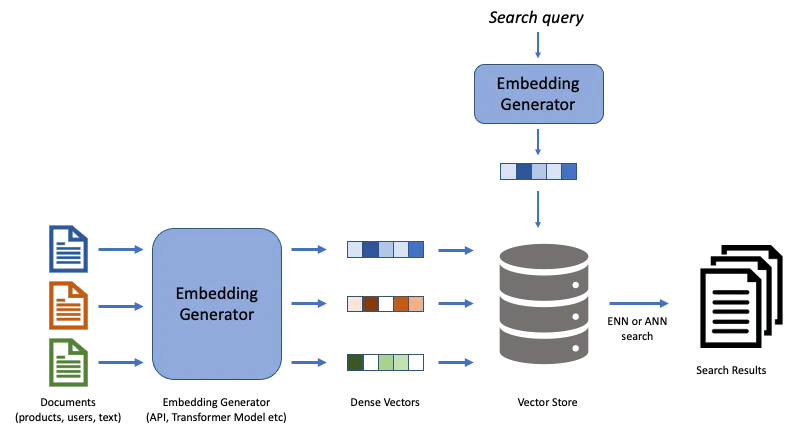
Embedding-based search
目前 OpenAI 推荐的是另一种方法,叫做语义搜索(Embedding-based Search)。在这种方法中,查询和文档都被转换为高维空间中的向量(也称为 Embedding,本质是一串数字)。这些 embedding 捕获了文本的语义信息,使得语义上相似但字面上不同的词能够被匹配。例如,”猫”和某种”宠物用品”可能会有相似的 embedding,因此即使文档没有明确提到”猫”,也可能被返回为搜索结果。
在进行语义搜索时,我们的目标是找到与我们的搜索查询在语义上最接近的文本。为了做到这一点,我们需要先将我们的文本和查询转换成一种可以比较的形式,这就是所谓的”嵌入(Embedding)”。
- 预计算阶段:首先,我们需要处理我们的文本语料库。这可能是一本书、一组文章,或者任何其他形式的文本。我们将这个大的文本分割成更小的块,每个块的长度都在我们的模型的处理能力范围内。然后,使用模型将每个文本块转换成一个嵌入,这是一个数字向量,可以捕捉文本的语义信息。最后,我们将这些嵌入存储在一个
向量数据库中,以便以后使用。 - 实时计算阶段:搜索查询时,先将搜索内容转换成一个嵌入(Embedding),然后,在向量数据库中查找最接近查询嵌入的文本嵌入,这些最接近的嵌入对应的文本块就是我们的搜索结果。
这就是语义搜索的基本过程。虽然这个过程可能涉及到一些复杂的技术,但其核心思想其实很简单:我们只是在尝试找到与我们的查询在语义上最接近的文本。
关于 Embedding-based search 的更多内容,可以参考下面的文章:
- Question answering using embeddings-based search
- The Beginner’s Guide to Text Embeddings
- Semantic Search With HuggingFace and Elasticsearch
丰富的工具箱
好在大多时候普通人不需要了解这些技术背景,可以直接使用市面上的现成工具,比如 ChatGPT 的 “Ask Your PDF” 插件,就可以针对自己上传的 PDF 文件进行提问。这个插件将文档的内容转化为一个知识丰富的对话伙伴,能够根据文档内的信息提供详细的回答。不过这个插件目前还是有不少缺点,包括上传的文件大小限制,没法给出具体从 PDF 哪部分内容得出的结论,以及有时候会给出奇怪的回答。
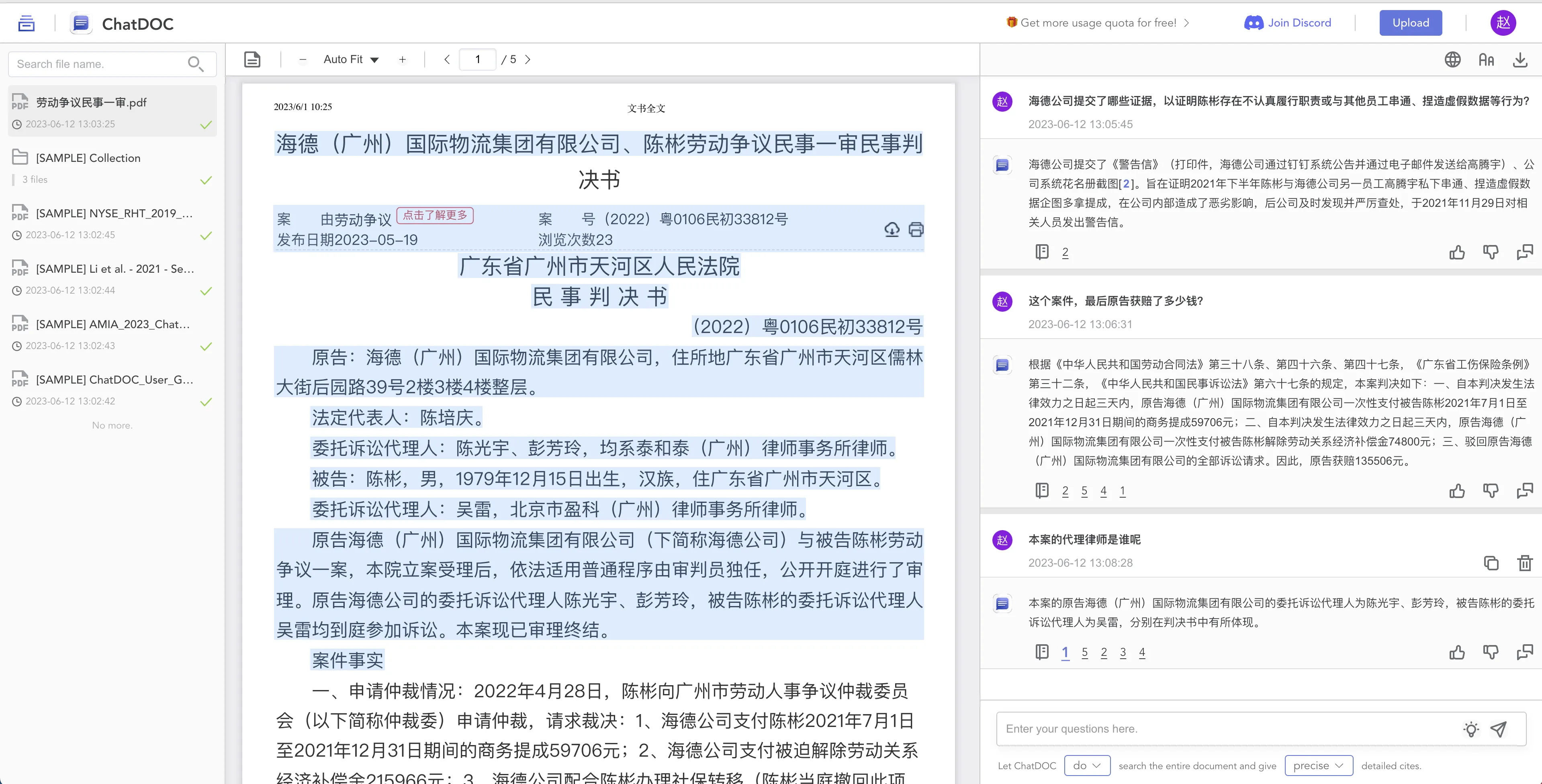
除了免费的 ChatGPT 插件,还有一些付费工具,用起来体验更好些。比如 chatdoc,可以提供文件提问,同时在解答中会给出依据,还能方便跳转。随便找了一个法律裁判文书的 PDF ,然后问了几个问题,整体感觉比插件稍微好些。
除了插件,专业工具,微软也提供了带有 browsing 功能的 GPT4,也就是 New bing。它不仅仅是搜索和返回结果,还能借助 GPT 理解你的问题,根据搜索到的网页,重新组织语言,提供完整的答案。
总的来说,尽可能的提供引用文本是一个很好的 Prompt 习惯,可以帮助我们在处理长篇文本的时候,更好地利用 GPT 的能力。

