ChatGPT 代码解释器:数据分析与可视化
OpenAI 在 2023 年 3 月份的博客 ChatGPT plugins 中介绍了插件功能,当时就提到了两个十分重要,并且 OpenAI 自己托管的插件 web browser 和 code interpreter,关于代码解释器(code interpreter),原文是这样说的:
We provide our models with a working Python interpreter in a sandboxed, firewalled execution environment, along with some ephemeral disk space. Code run by our interpreter plugin is evaluated in a persistent session that is alive for the duration of a chat conversation (with an upper-bound timeout) and subsequent calls can build on top of each other. We support uploading files to the current conversation workspace and downloading the results of your work.
也就是说,我们可以上传文件,用自然语言去描述具体的需求,然后由 ChatGPT 自行编写 Python 代码,并且在沙箱环境中执行,还可以下载结果文件。官方列出了几个比较好的使用场景:
- 解决定量和定性的数学问题
- 进行数据分析和可视化
- 转换文件的格式
从 2023.7.6 号起,OpenAI 开始逐步给 Plus 用户灰度代码解释器(code interpreter)功能,具体可以看 ChatGPT — Release Notes,可以在官方论坛中看到有关代码解释器的一些帖子。
代码解释器带来的最引人注目的功能之一就是数据可视化。代码解释器使 GPT-4 能够生成广泛的数据可视化,包括 3D 曲面图、散点图、径向条形图和树形图等。
接下来本篇文章给大家展示如何用代码解释器来做一些数据分析和可视化的工作,以及代码解释器目前的一些缺陷。

Airbnb 租金价格分析
New York City Airbnb Open Data 上面有一个Airbnb给的纽约在2019年的租房数据集,我们就用它来测试下 GPT4 的新能力。
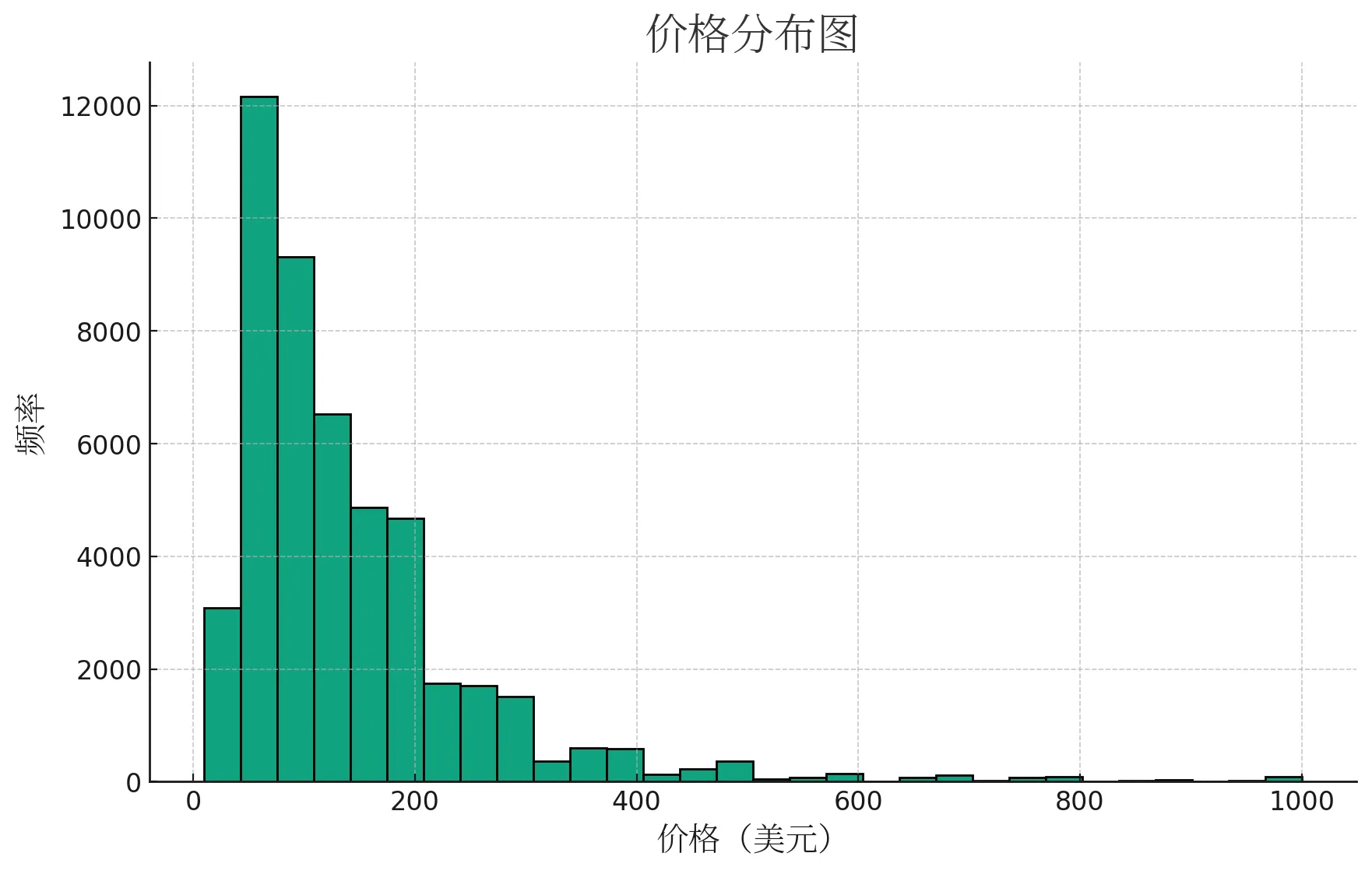
先上传文件,然后简单告诉 GPT4 分析下数据,GPT 会给出每个字段的含义,并询问我们对数据集进行什么样的分析。于是我让他清洗数据,去掉不合理值,然后绘制一个价格分布图。
GPT4 首先给出数据集中存在缺失值的列,发现和价格分布这个目标没关系,就忽略这里的异常。接着检查了价格列的数据,计算价格的一些统计量(如最小值,最大值,平均值等),然后将价格为 0 的记录和价格异常高的记录(例如,高于一个合理的上限,比如 1000 美元)视为异常值并将它们移除,接着给出了价格分布图:
影响价格因素
接下来让 GPT4 来分析下不同因素对价格的影响,先直接问 GPT4 觉得价格和什么因素相关,然后给出下面的几个因素:
- 房源类型(Room Type):一般来说,整套公寓或房子(Entire home/apt)的价格可能会比单独的私人房间(Private room)或共享房间(Shared room)更高。
- 地理位置(Neighbourhood):在旅游热点或市中心的房源可能会比较贵,而在郊区的房源可能会比较便宜。
- 可用性(Availability):如果一个房源一年中的可用天数很少,那么它的价格可能会比较高,因为房东可能会在少数的可用天数内尽量提高收入。
- 评论数量(Number of Reviews)和最近的评论日期(Last Review):如果一个房源有很多好评,并且最近还有客人留下评论,那么房东可能会提高房源的价格。
- 最少入住晚数(Minimum Nights):如果一个房源要求客人至少入住多个晚上,那么它的价格可能会比其他没有这个要求的房源更高。
为了验证这里的假设,进行了一些数据探索和可视化,结果如下:
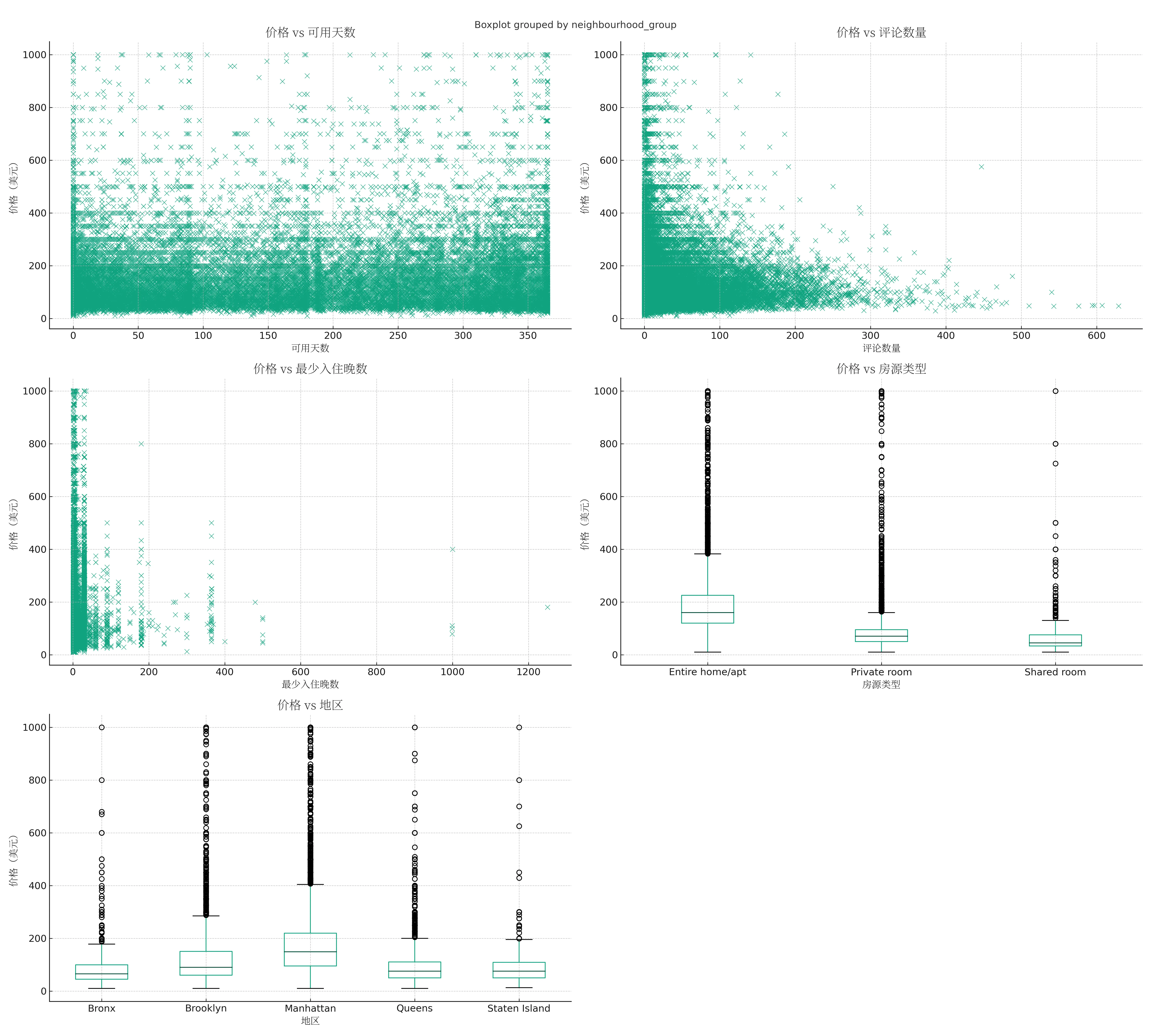
这里开始每种因素给了一张图片,不过可以让 AI 整合为一张图,并提供下载链接。结合这里的可视化来看,价格主要受房源类型和地区的影响,而与可用天数、评论数量和最少入住晚数的关系不大。这些分析结果符合我们的直觉和对租房市场的了解。
这里对可视化有不太懂的地方也可以随时问 GPT4,比如价格与地理位置绘制的箱线图(Boxplot),横坐标是地理位置(Neighbourhood Group),纵坐标是价格(Price)。每个地理位置对应一个箱子。箱子的底部(Q1)和顶部(Q3)分别表示该组价格的第一四分位数和第三四分位数,也就是说,50% 的房源价格位于这个箱子内。箱子中间的线表示该组价格的中位数。箱子上下的线(称为“胡须”)则延伸到该组价格的最小值和最大值,或者是离箱子一定距离的值。超过这个距离的点被视为异常值,用点来表示。我们可以看出 Manhattan 和 Brooklyn 的房源价格的中位数高于其他地区,也就是说,这两个地区的房源价格普遍较高。而 Staten Island 和 Bronx 的房源价格普遍较低。
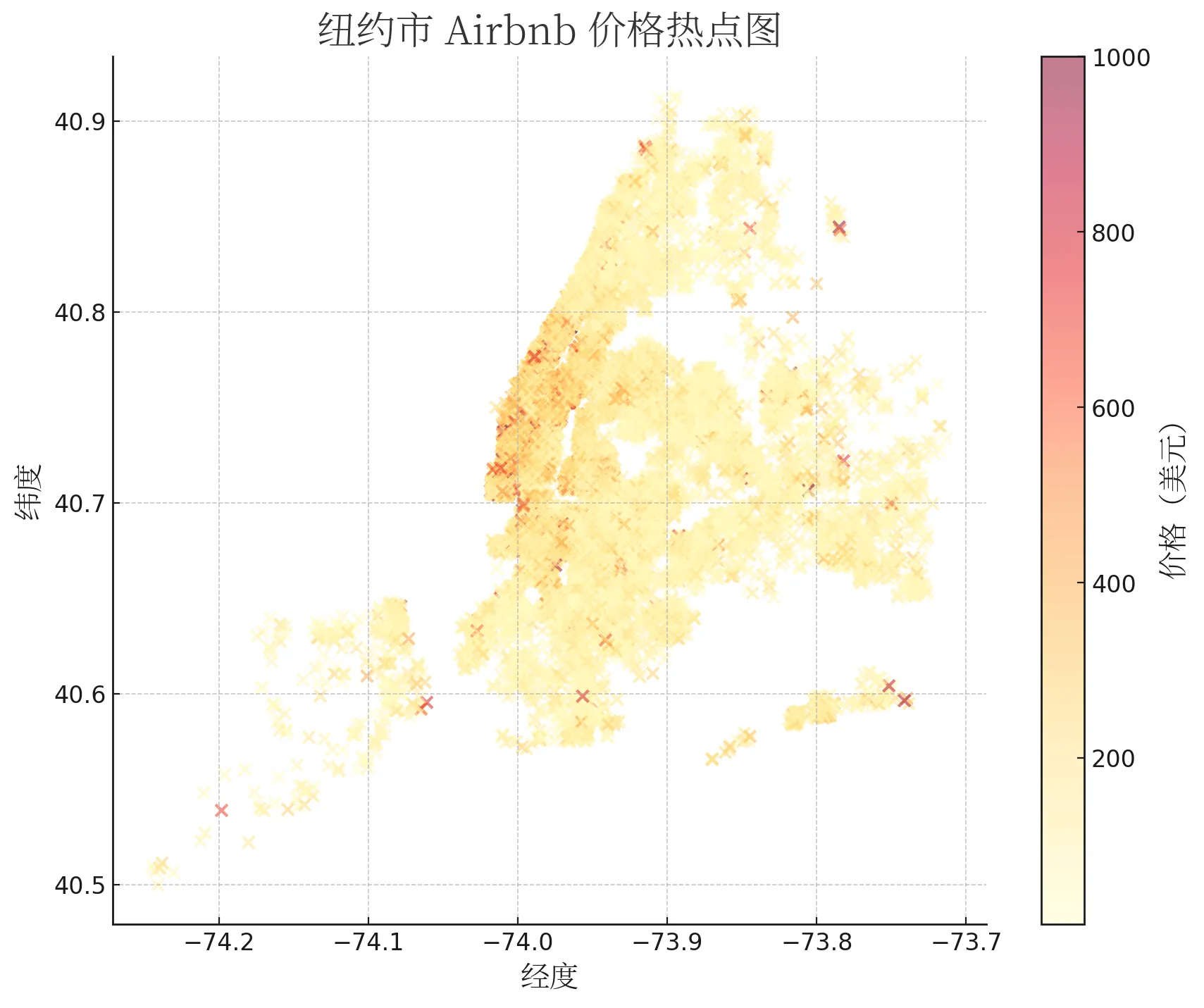
地理分布图
数据集中有地理位置坐标,可以让 GPT4 画出价格的地理位置分布图,如下:
抖音用户分析
上面的数据集其实不大,只有 7M,ChatGPT 目前最大支持 500M,我又找了一个比较大的 抖音用户数据集,来继续试试 GPT4 的能力。上传完文件,还是先简单提示:分析下这个数据集,然后 GPT4 就会先给出每个字段的含义和字段值的分布,还给了一些接下来可以分析的方向。接下来从用户观看习惯,视频播放分析这 2 个方面来试着分析下这份数据。
用户观看习惯
这里我们先看看用户的观看习惯,比如用户一天中的哪些时间更活跃,观看视频的频次等。分析的结果如下图:
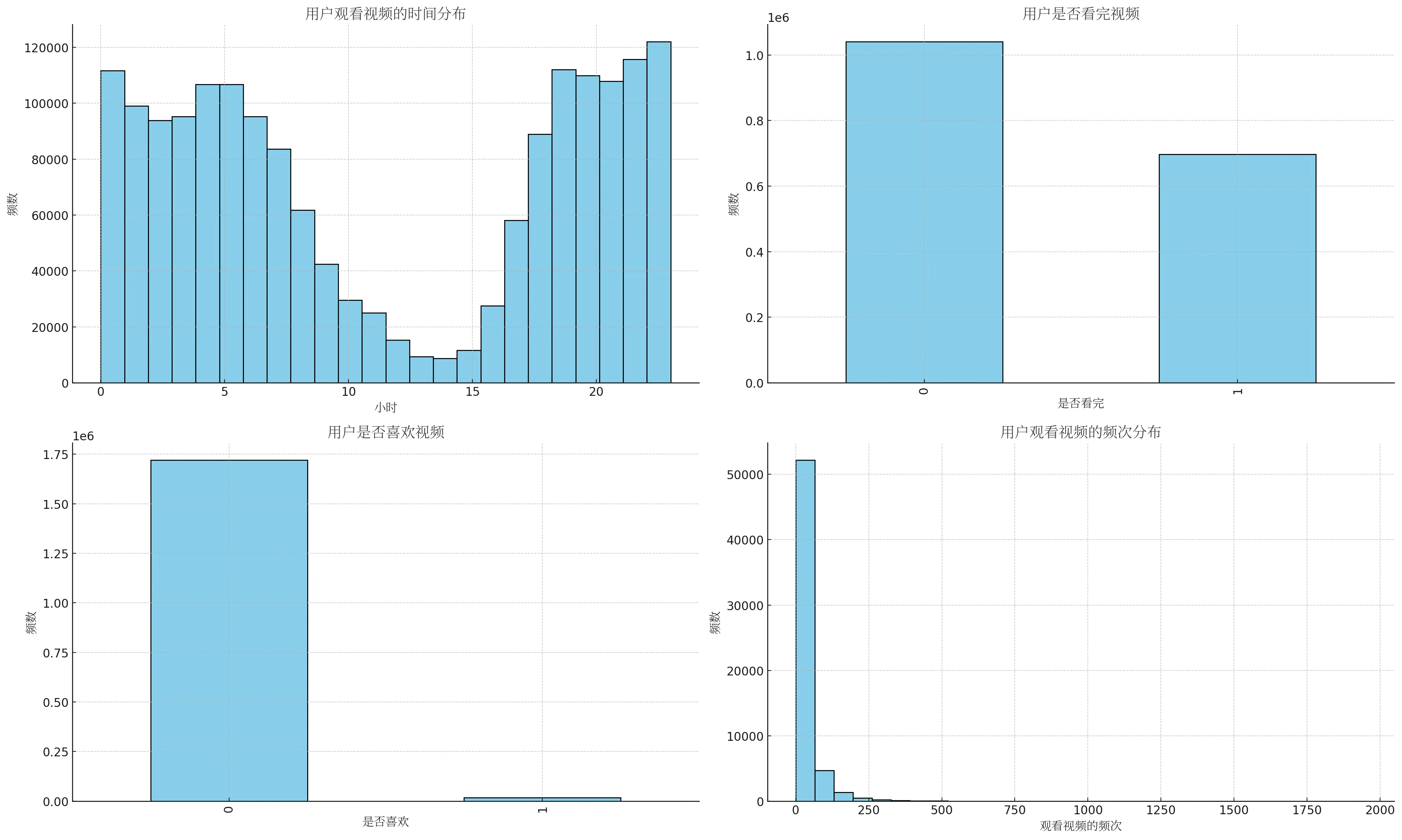
从图中我们可以看出,用户在晚上和午夜的时候观看视频较多,这里 5 点左右还这么高,有点出乎意料。大部分用户观看视频的频次在30次以下,但也有一些用户观看视频的频次非常高,超过200次。大多数用户会看完视频,说明抖音的视频内容可能很吸引人。大多数用户不会对视频进行点赞,这可能是因为点赞是需要引起很高的共鸣才行。
视频播放分析
先来看看视频的受欢迎程度,我们可以从以下几个方面来探索,视频被观看的次数,被用户看完的次数以及被用户点赞的次数。这里的分析很好地展示了长尾效应,即大部分视频的受欢迎程度(观看次数、被看完的次数和被点赞的次数)都比较低,但也有一小部分视频的受欢迎程度非常高,这是社交媒体平台上常见的现象,赢家通吃。为了显示长尾的数据,我们忽略掉观看次数、被看完的次数和被点赞的次数都比较低的视频。绘制了一个堆叠柱状图如下:
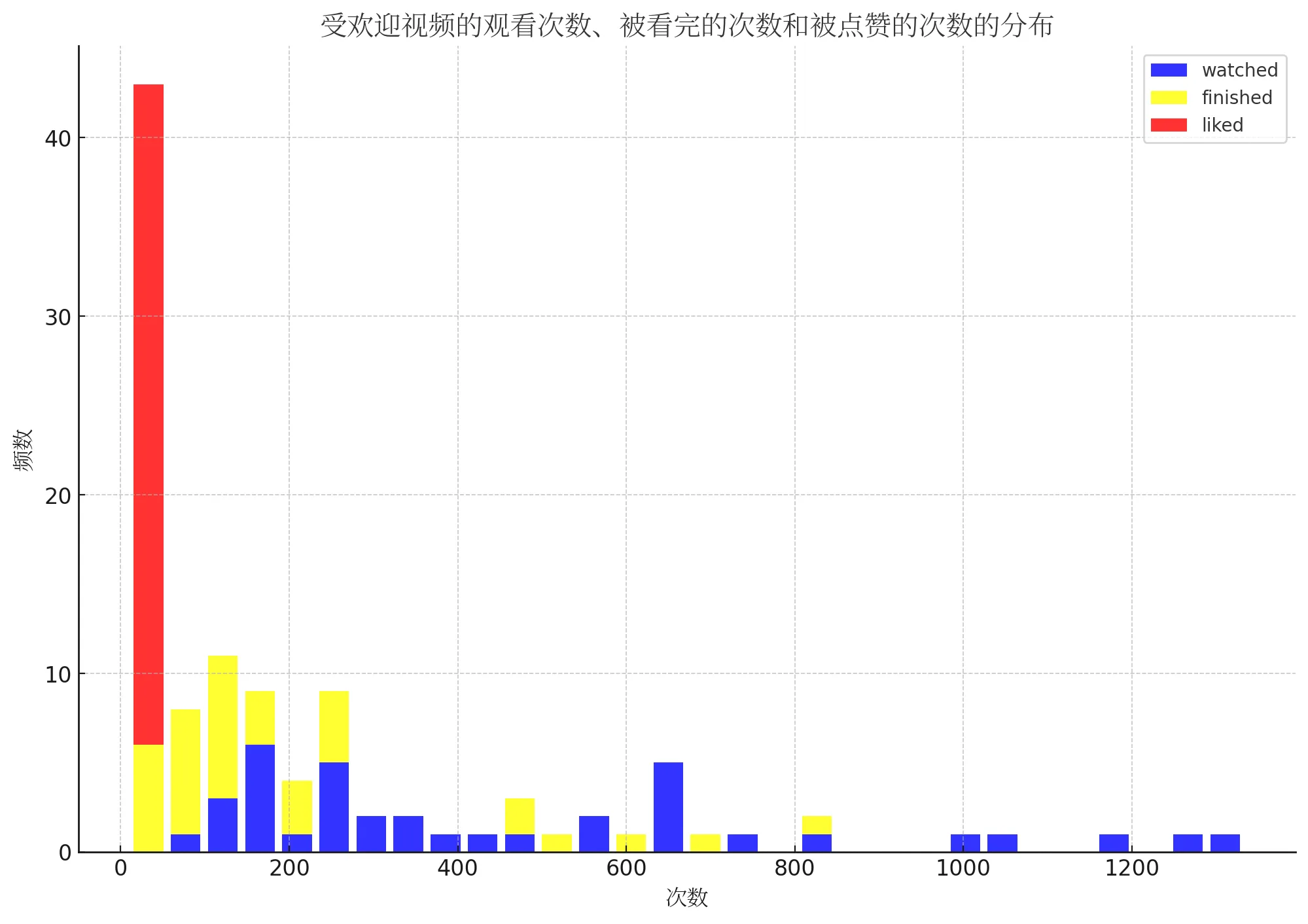
这个图表更好地突出了受欢迎程度高的视频在观看次数、被看完的次数和被点赞的次数上的分布。可以看出,尽管这些视频都非常受欢迎,但在观看次数、被看完的次数和被点赞的次数上仍然存在一定的差异。我们可以继续看下视频看完和点赞之间是否有相关性:
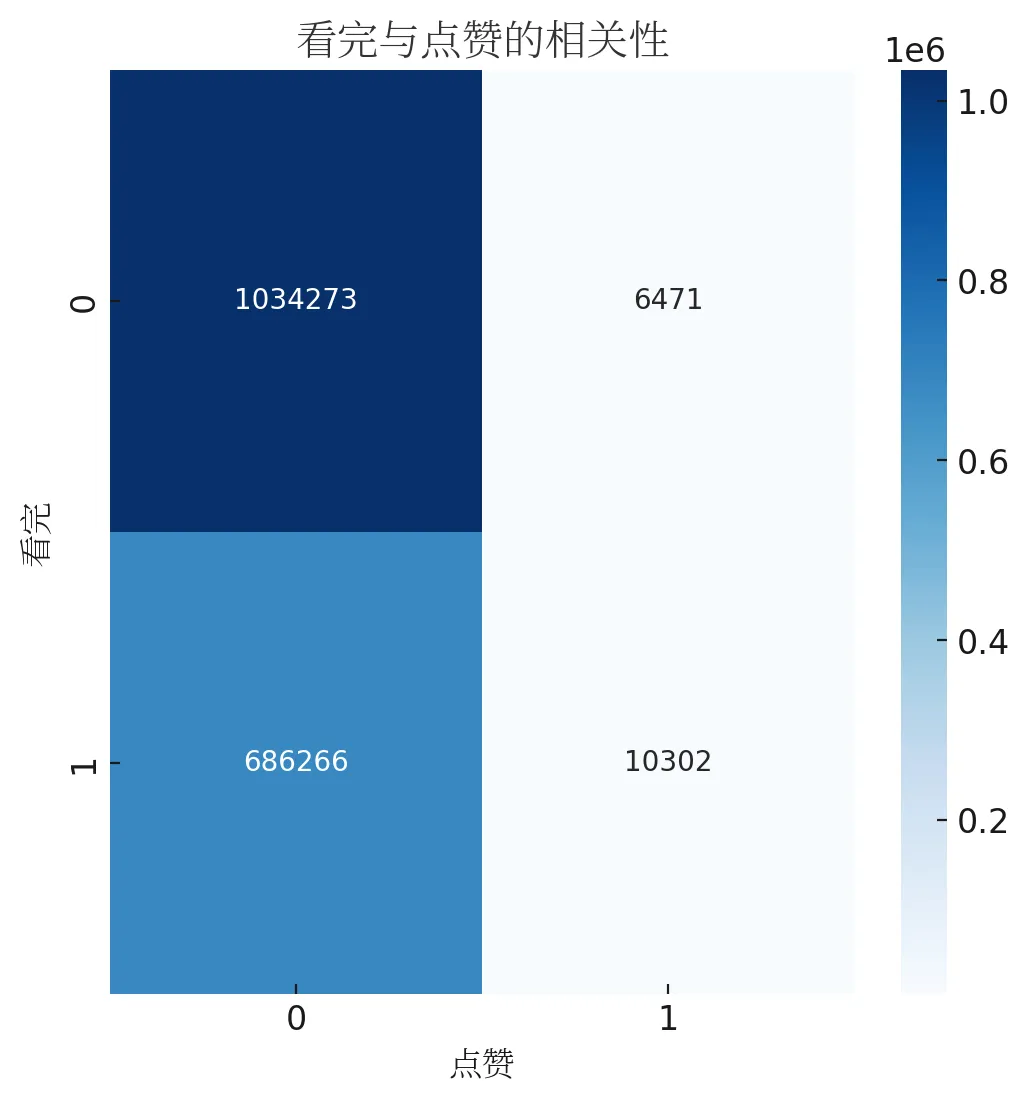
大多数情况下,用户既没有看完视频,也没有点赞。只有少数情况下,用户既看完了视频,也点赞了。’finish’和’like’之间的相关系数为0.043,这是一个非常低的值,表示这两个变量之间几乎没有线性关系。这可能是因为用户是否看完视频和是否点赞是两个相互独立的决策,一个不直接影响另一个。
数据分析师招聘分析
在 AI 的辅助下,做数据分析会容易很多,但是目前的 AI 还只能作为一个助手,没法替代数据分析师。实际上,数据分析师还是很有需求市场的,我在网上找到了一个公开的 2022 年数据分析岗位招聘数据,具体在 2022年数据分析岗位招聘数据可视化项目。我们可以让 GPT4 来分析下这份数据,看看数据分析师的市场需求情况。
技能需求词云
为了了解数据分析岗位的技能需求,先让 GPT4 生成一个词云图。词云图的大小表示该技能在岗位描述中出现的频率:词越大,表示该技能被提到的次数越多。从图中我们可以看出,一些关键技能,如”数据分析”、”SQL”、”Excel”、”Python”等,在数据分析岗位中非常受欢迎。同时,我们也可以看出,”数据挖掘”、”BI”、”商业”、”SPSS”等也是数据分析岗位常见的需求。

估计 2024 年的招聘需求里,就要写上会用 ChatGPT 等 AI 工具辅助分析了,可以期待下。
影响薪水的因素
接下来看看薪水具体受什么影响最大吧,这里我们最关心 工作经验,公司规模,城市,职位名称 对薪酬水平的影响。
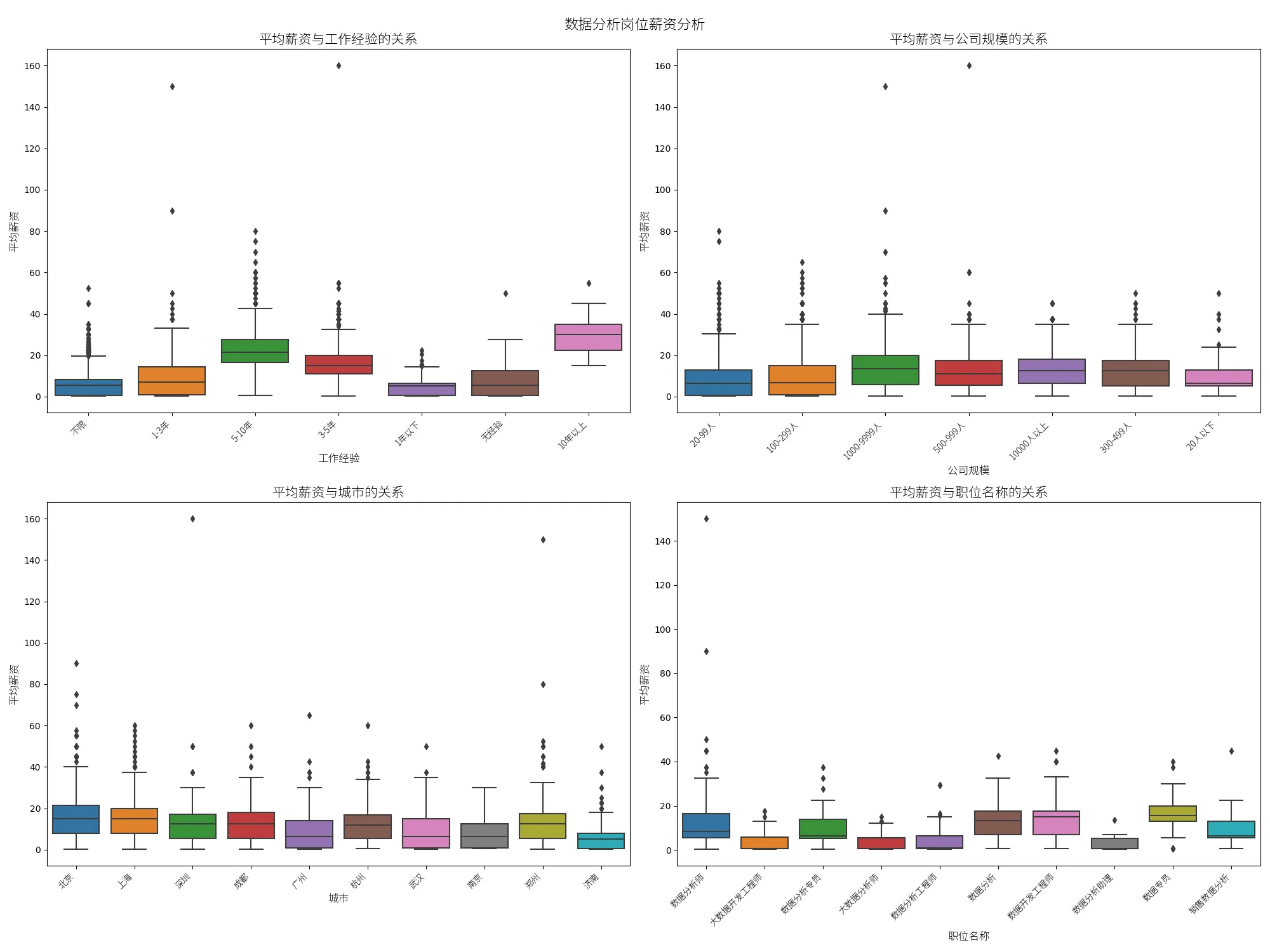
从四个箱形图可以看到:
- 工作经验越丰富,薪资的中位数和上下四分位数范围都在提高,也就是说工作经验越丰富,薪资普遍越高。
- 大公司的薪资中位数和上下四分位数范围普遍高于中小公司。
- 不同城市的薪资差异也较大,其中北京、上海、深圳的薪资中位数和上下四分位数范围相对较高。
- 由于职位名称的多样性,这里仅展示了职位数量最多的前10个职位名称的薪资分布,其中数据分析师和数据科学家的薪资中位数和上下四分位数范围相对较高。
这里分析的结果还是比较符合直观感觉的。
可能遇见的问题
中文字体缺失
上面的图片中正确显示了中文信息,其实是经过特殊处理的。默认情况下显示的图片中,无法正常显示中文,因为执行环境缺少中文字体。不过没关系,我们可以自己下载字体并让 GPT4 使用我们指定的字体即可。
这里 GPT4 给我推荐了一个开源的字体 思源黑体(Source Han Sans),在 Adobe 的 Github 页面上可以找到。开始的时候在这里选择了 TTF: Variable Simplified Chinese (简体中文),让 GPT4 加载字体时遇到了错误:”In FT2Font: Can not load face (error code 0x8)“
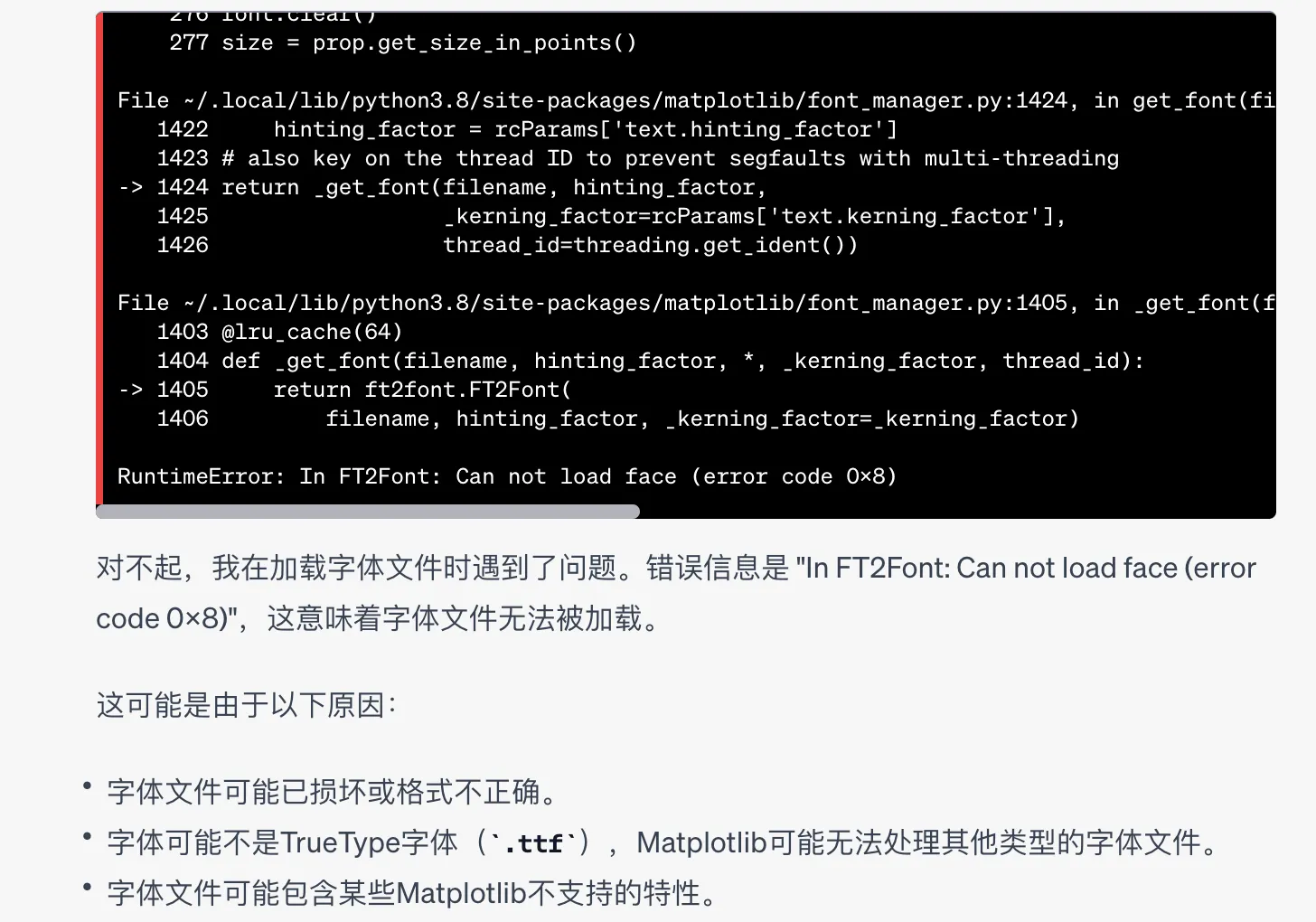
原因是我下载的是一种变体字体(variable font),变体字体是一种可以包含多种字体样式的新型字体格式,它们可以在一定范围内调整字体的各个属性,如字体宽度、粗细等。然而,matplotlib 并不支持变体字体,要换成一种非变体普通的 TrueType (.ttf) 字体。最后让 GPT4 重新推荐了下,我选的是简体中文的谷歌字体 NotoSerifSC-Light.otf。
这里的最佳实践是,如果会话中要用到中文字体绘图,可以在一开始就传入字体文件,然后让它用这里的字体来绘制一个随机图片,图片标题用中文。这样设置好后,后续不用再提供其他提示词,基本就会用自定义字体来绘制了。
会话持续性问题
如果关闭了页面隔一段时间 OpenAI 会关闭之前分配的解释器,下次再进入会话页面开始提问的话,会丢失之前的上下文,比如上传的文件等内容,并且进入的时候会有下面的提示:
如果一直停留在页面没有操作,隔一段时间也会丢失前面会话内容,然后再执行的时候,GPT4 可能就会变的很傻。可能会不断尝试重新加载数据和脚本,如下图:

这里的脚本其实已经返回了错误:
FileNotFoundError: [Errno 2] No such file or directory: ‘/mnt/data/2022年数据分析岗位招聘数据.xlsx’
但是还在不断尝试,希望后面 OpenAI 能修复这个 Bug。这时候最好是重新开一个会话,然后上传文件进行分析。
当然还要时刻注意 OpenAI 代码解释器的一些限制,具体可以看我的这篇文章:GPT4 代码解释器:资源限制详解。
备注:本文中的数据集可以在 Google Drive 下载。

