ChatGPT 代码解释器:自然语言处理图片
在 GPT4 代码解释器:数据分析与可视化 我们看到了 Code Interpreter 在数据处理方面的强大能力。按照官方的说法,这里在图片处理场景也是很有用的,这篇文章一起来探索下。
那么 ChatGPT 到底支持对图片进行一些什么操作呢?那就要看 OpenAI 在代码执行环境中预装了哪些图片处理的 Python 库。在 GPT4 代码解释器:资源限制详解 里我们已经知道如何打印执行环境的 Python 库,只需要从里面找出处理图像的库,主要有以下库:
- opencv-python: 它是一个用于处理图像的库,能进行图像处理和计算机视觉方面的很多操作。
- Pillow: 这是一个 Python 的图像处理库,提供了广泛的文件格式支持,以及强大的图像处理能力。
- imageio: 它是一个提供读写各种图像数据的库,包括动画和多维科学数据等。
- scikit-image: 这是一个用于图像处理的 Python 库,它包括图像分割、几何变换、颜色空间操作等。
- matplotlib: 这是一个用于绘制图形的库,可以用来生成各种静态、动态、交互式的图表。
因此,ChatGPT 处理图片的能力受限于这些库。下面我们通过实例来看看如何使用自然语言生成各种代码来处理图片。
基本图像处理
灰度处理
在图像处理的时候,经常需要先将彩色图像转换为灰度图像来降低图像的复杂性。因为在许多应用中,颜色信息可能并不重要,而亮度信息(例如形状、纹理)才是最关键的。在这些情况下,将图像转换为灰度可以减少计算量,并简化分析过程。
很多图像处理教材中都用一个 Lena 的图像来演示图片的灰度处理,这里我们让 GPT4 来把这张图转换为灰度看看。为了显示原图和灰度图区别,我们让 GPT 处理完之后,把原图和灰度图拼接起来,如下(这里只截了原图上半部分,去掉了漏点的内容):

在这里,我们使用了 PIL,numpy 和 matplotlib 库来解析图片,将其转化为灰度,然后进行拼接,并在上面添加文字说明。原始图像是一个四通道图像(红色,绿色,蓝色和透明度),而灰度图像是一个三通道图像(灰度,灰度和灰度)。因此,我们首先删除了原始图像的透明度通道,然后再将图像拼接在一起。我们最初在图片中间添加了文字注释,但后来将其调整到了左上角,于是得到了上面的结果。
最后可以让 GPT4 给出完整的处理代码(这里代码有很小的瑕疵,比如引入了没有用到的 imageio 库):
1 | import numpy as np |
其他处理
接下来对上面的图片,我们继续执行一些基本的图像处理操作,得到下面的六张图像,从左到右,从上到下分别是:
- 原图:这是未经任何处理的原图像。
- Sobel 边缘检测:这个图像显示了使用 Sobel 滤波器检测到的边缘。
- 阈值分割:这个图像是使用 Otsu 的方法进行阈值分割后的结果。
- 旋转:这个图像是原始图像旋转 45 度后的结果。
- 对比度拉伸:这个图像是对原始图像进行对比度拉伸后的结果。
- 高斯模糊:这个图像是对原始图像应用高斯模糊滤波器后的结果。
图片如下:

制作 GIF 动画
Python 的这些库还可以用来制作 GIF 动态图,下面就是具体的例子。
Lena 旋转图
用现在的这些预安装库,可以生成动态图像。例如,我们可以逐渐改变图像的颜色,对图像进行旋转,然后将这些帧合并成一个 GIF。具体步骤是:
- 使用 Pillow 将图像转换为 RGB。
- 创建一个循环,每次迭代时都会稍微旋转图像并更改其颜色。将每次迭代的结果保存为一个新的帧。
- 使用 imageio 将所有帧保存为一个 GIF。
为了得到一个好的效果,这里 GPT4 创建了 30 帧,每帧旋转 12 度,同时逐渐改变颜色。第一遍生成的图像大小比较大,有 23M,接着要求 GPT 压缩这个 GIF。具体压缩方法就是将图像的宽度和高度都减小到原来的一半,将帧数减半,于是得到了一个只有 3M 的动图,如下:

生成的代码如下(这代码需要导入依赖后才能在本机运行):
1 | # Parameters |
GDP 变化图
之前看到过一些比较酷炫的动态变化图,展示随时间变化的一些数据,matplotlib 和 imageio 模块就可以绘制这种图片。我们先从 国家统计局 拿到 2003 年到 2022 年各省份的 GDP 数据,完整数据在 Google Drive 可以下载,其中部分内容如下:
为了绘制动态变化的柱形图,可以用下面的提示词:
帮我画出随着时间变化,GDP最高的10个地区的动态变化图。从 2003 年开始,给出 GDP 最高的 10 个地区的 GDP 直方图,然后随着年份增加,给出不同年份的柱状图,随后制作一个 GIF 动态图,并提供下载链接。
可以把年份放大放到标题中,这样 gif 中变化的时候看的清晰
这里最开始用 imageio 绘制的图,可能是预装的版本太低,都不支持 fps 参数,然后用 duration 参数也改变不了帧的切换速度,并且在浏览器也不会自动循环播放。后来提示用 PIL 库来绘制,然后 GIF 图片能够在浏览器中循环播放了。得到的结果如下:
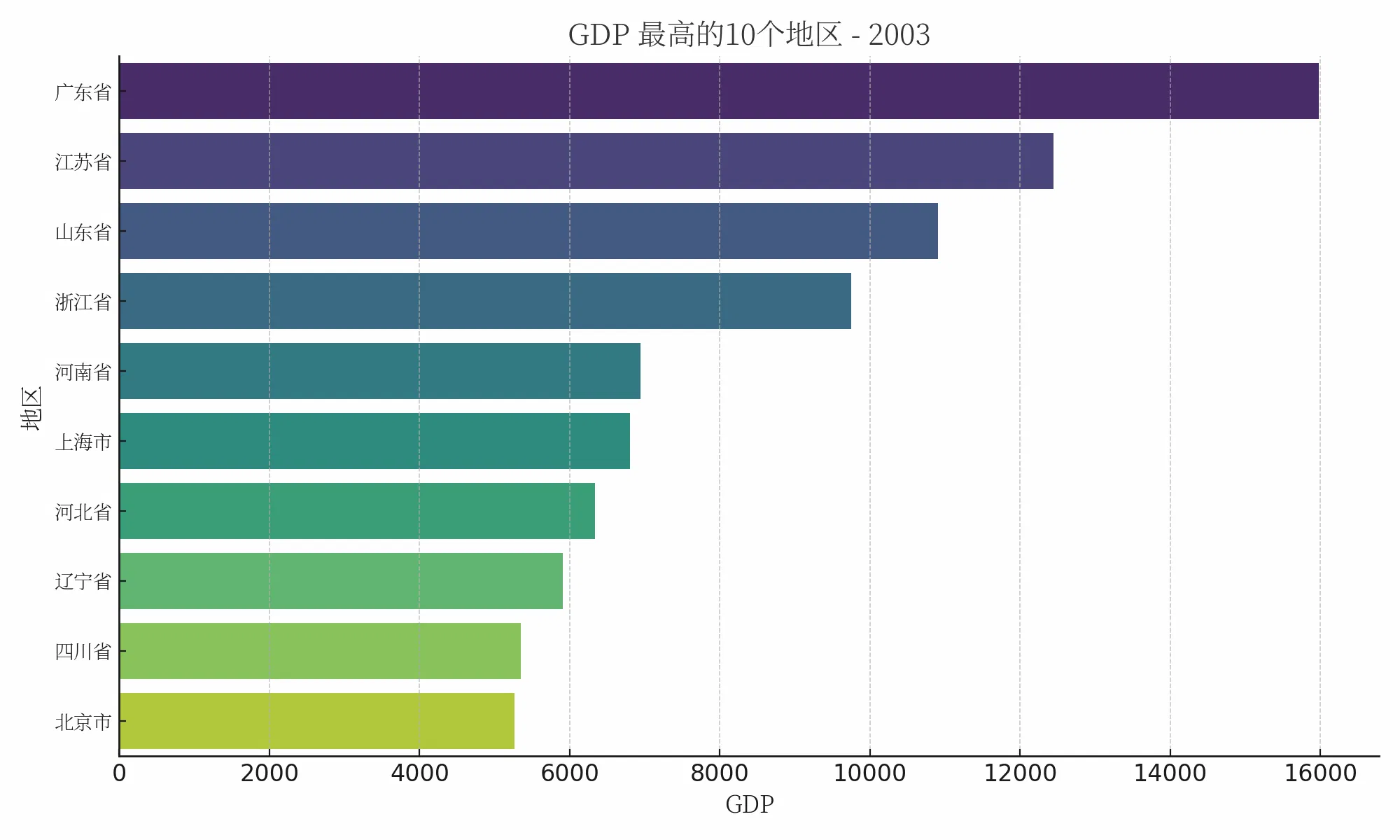
部分代码如下:
1 | from PIL import Image |
能力限制
这里的图像处理能力,完全依赖这些预置的 Python 库,所以不能完成一些复杂的图像处理或者图像识别。比如如果你让他去扣除图片中的背景,或者识别图片中的人脸区域,可能就做不到了,这需要更专业的模型。
机器学习模型
当我直接要求它把前面 Lena 照片中的背景扣除,只保留人像部分时。得到的结果告诉我要实现这个任务,通常需要使用计算机视觉技术来识别并分离图像中的人像部分。这个过程通常被称为图像分割或对象检测,这种类型的任务通常使用深度学习或机器学习技术来实现。
然而由于 ChatGPT 当前执行环境限制,无法在这个环境中运行深度学习模型来实现这个任务。这通常需要大量的计算资源,而且需要访问互联网来下载预训练的模型。
在这里,我们通常可以尝试使用像 OpenCV 这样的库,或者像 remove.bg 这样的在线服务来实现这个任务。这些工具和服务已经使用了预训练的深度学习模型,可以很好地实现人像分割。
不过可以尝试将预训练模型上传到解释器,然后交给 GPT4 用深度学习的库来加载模型并执行。还看到有人把数据集上传,然后在解释器训练模型,不过考虑到 GPT4 代码解释器:资源限制详解 里面提到的 CPU 和内存限制,这里的训练只能用来当做玩具用了。
执行环境缺陷
这里在做各种处理的时候,要生成代码,这里生成速度比较慢。更糟糕的是,就算你整理好了代码给它执行,它还要再输入一遍,输入过程也是很慢,有点傻。
另外如果一段时间不用 GPT,执行环境就会重置,各种文件和之前的代码就会丢失。这时候 GPT 很大概率会在那里各种尝试,不能正常执行,还会出各种奇葩的错误。最好的方法是,重新开一个会话上传文件,然后进行分析。

尽管 GPT 的 Code Interpreter 存在各种缺陷,但它仍然具有许多实用场景。它可以作为代码编写和调试的强大工具,通过理解和生成代码,为解决特定问题提供提示,实现高效编程。对于编程初学者来说,它能解释复杂的代码段,并展示代码示例,从而辅助他们学习。

