结合实例深入理解 C++ 对象的内存布局
在前面 Bazel 依赖缺失导致的 C++ 进程 coredump 问题分析 这篇文章,因为二进制使用了不同版本的 proto 对象,对象的内存布局不一致导致读、写成员的内存地址错乱,进而导致进程 crash 掉。但是当时并没有展开细聊下面的问题:
- 对象在内存中是怎么布局的?
- 成员方法是如何拿到成员变量的地址?
这些其实涉及 C++ 的对象模型,《深度探索 C++对象模型:Inside the C++ Object Model》这本书全面聊了这个问题,非常值得一读。不过这本书读起来并不容易,有的内容读过后如果没有加以实践,也很难完全理解。本篇文章试着从实际的例子出发,帮助大家对 C++ 类成员变量和函数在内存布局有个直观的理解,后面再读这本书也会容易理解些。
简单对象内存分布
首先以一个最简单的 Basic 类为例,来看看只含有基本数据类型的对象是怎么分配内存的。
1 |
|
编译运行后,可以用 GDB 来查看对象的内存分布。如下图:

对象 temp 的起始地址是 0x7fffffffe3b0,这是整个对象在内存中的位置。成员变量a的地址也是 0x7fffffffe3b0,表明int a是对象temp中的第一个成员,位于对象的起始位置。成员变量b的类型为double,其地址是 0x7fffffffe3b8(a的地址+8),内存布局如下图:
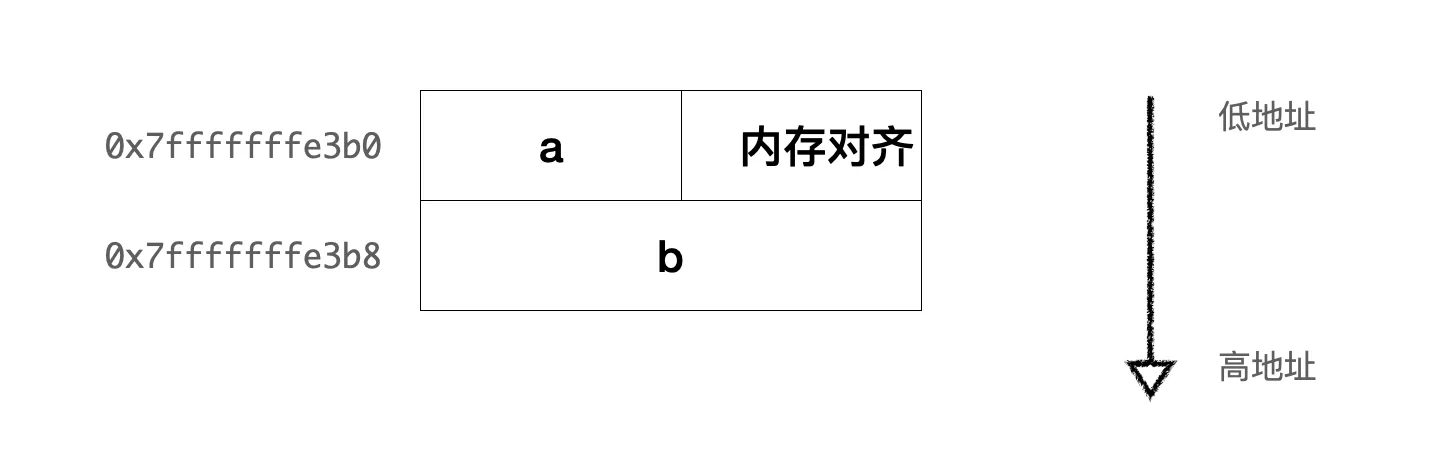
这里 int类型在当前平台上占用4个字节(可以用sizeof(int)验证),而这里double成员的起始地址与int成员的起始地址之间相差8个字节,说明在a之后存在内存对齐填充(具体取决于编译器的实现细节和平台的对齐要求)。内存对齐要求数据的起始地址在某个特定大小(比如 4、8)的倍数上,这样可以优化硬件和操作系统访问内存的效率。这是因为许多处理器访问对齐的内存地址比访问非对齐地址更快。
另外在不进行内存对齐的情况下,较大的数据结构可能会跨越多个缓存行或内存页边界,这会导致额外的缓存行或页的加载,降低内存访问效率。不过大多时候我们不需要手动管理内存对齐,编译器和操作系统会自动处理这些问题。
带方法的对象内存分布
带有方法的类又是什么样呢?接着上面的例子,在类中增加一个方法 setB,用来设置其中成员 b 的值。
1 |
|
用 GDB 打印 temp 对象以及成员变量的地址,发现内存布局和前面不带方法的完全一样。整个对象 size 依然是 16,a 和 b 的内存地址分布也是一致的。那么新增加的成员方法存储在什么位置?成员方法中又是如何拿到成员变量的地址呢?
成员方法内存布局
可以在 GDB 里面打印下成员方法的地址,如下图所示。
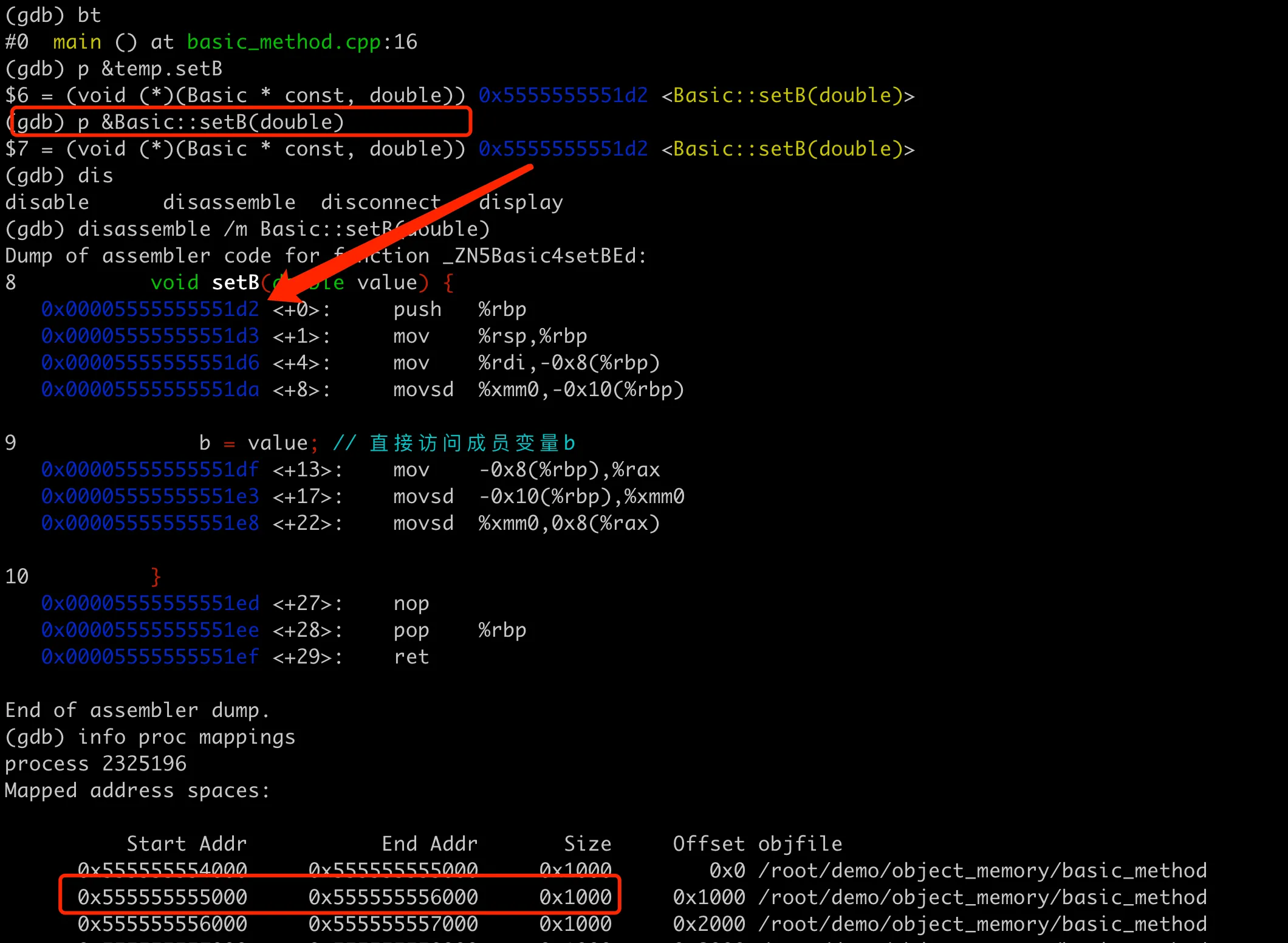
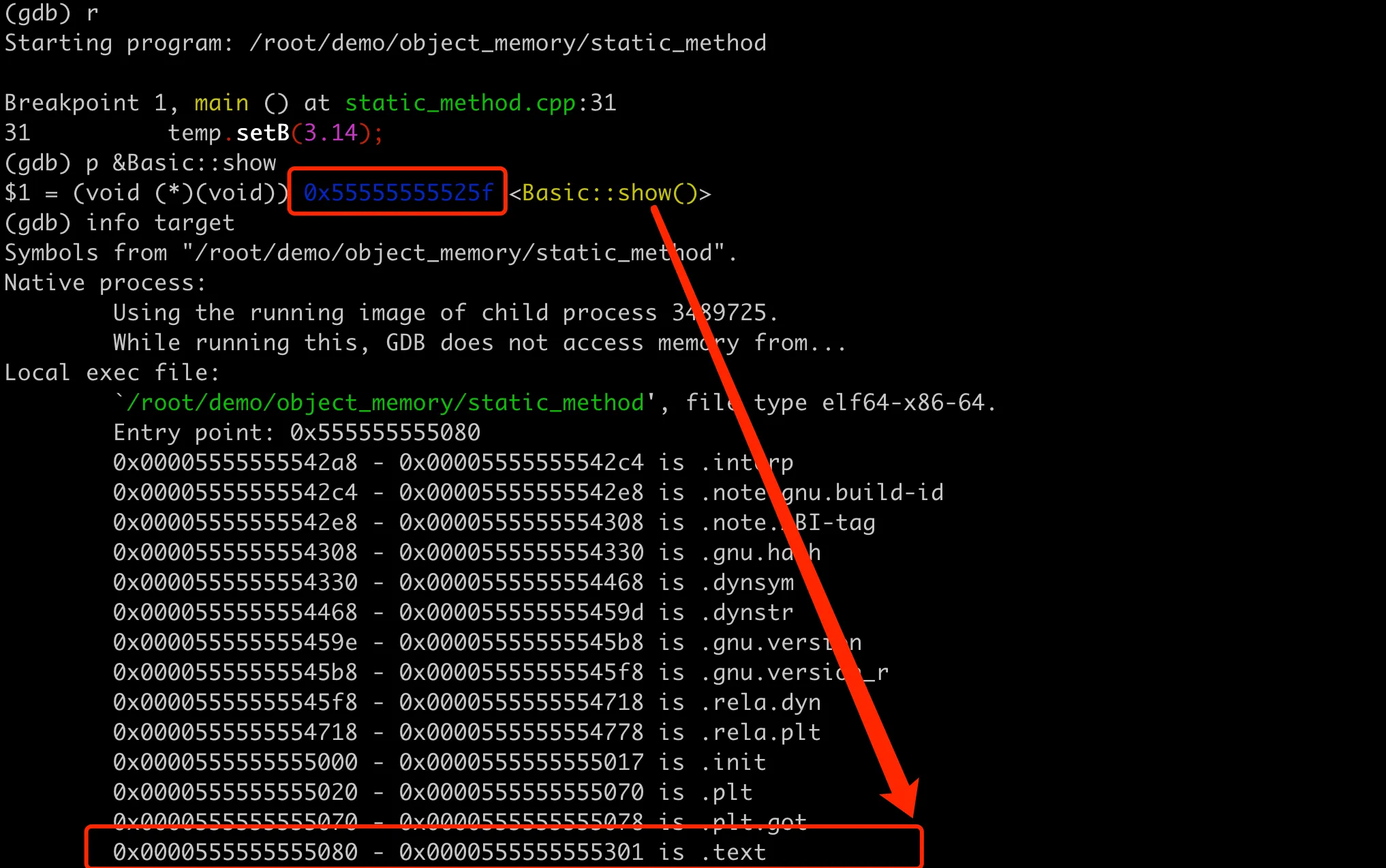
回忆下 Linux 中进程的内存布局,其中文本段(也叫代码段)是存储程序执行代码的内存区域,通常是只读的,以防止程序在运行时意外或恶意修改其执行代码。这里 setB 方法地址 0x5555555551d2 就是位于程序的文本段内,可以在 GDB 中用 info target 验证一下:
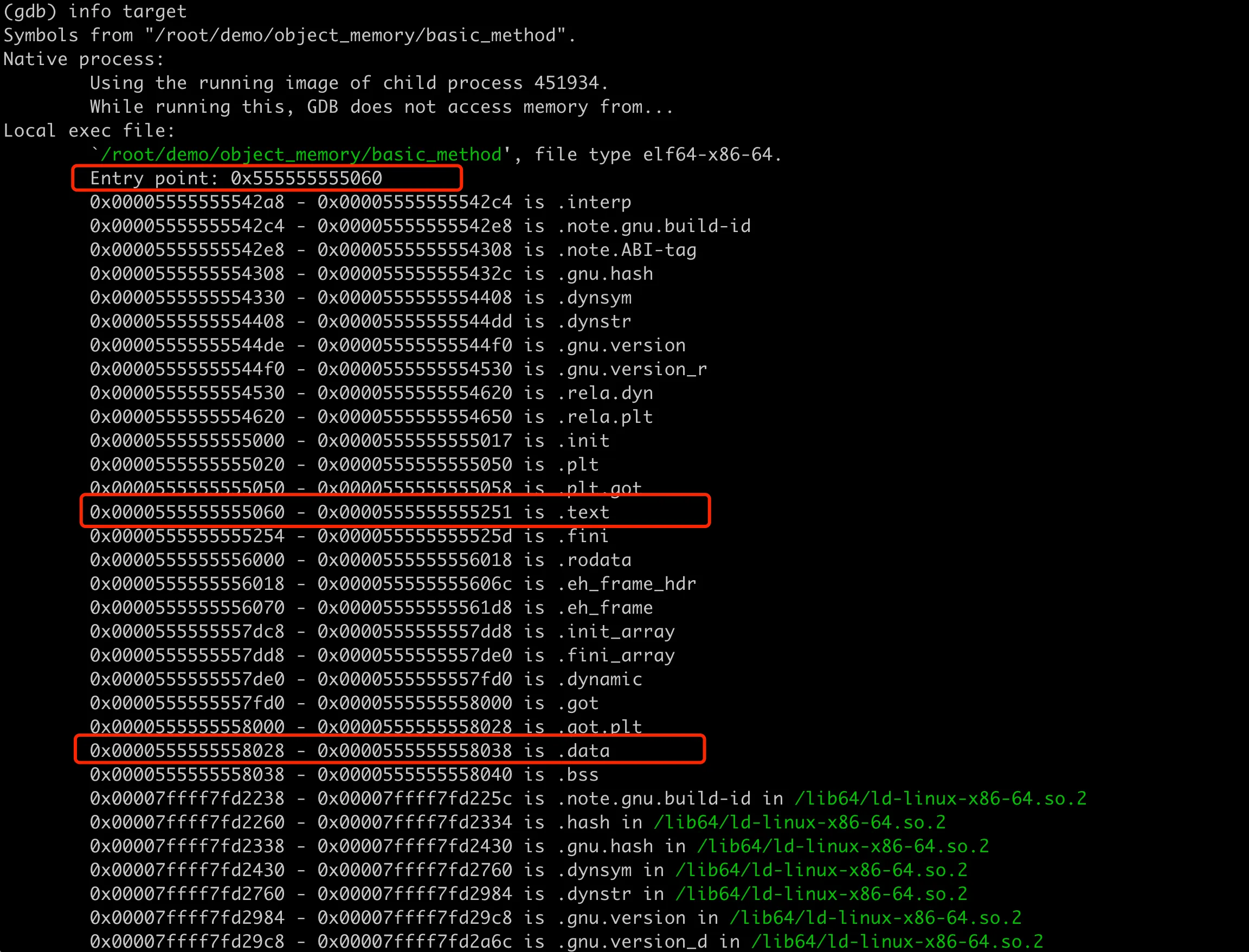
其中 .text 段的地址范围是 0x0000555555555060 - 0x0000555555555251,setB 刚好在这个范围内。至此前面第一个问题有了答案,成员方法存储在进程的文本段,添加成员方法不会改变类实例对象的内存布局大小,它们也不占用对象实例的内存空间。
成员变量寻址
那么成员方法中又是如何拿到成员变量的地址呢?在解决这个疑问前,先来仔细看下 setB 的函数原型(void (*)(Basic * const, double)),这里函数的第一个参数是Basic* 指针,而在代码中的调用是这样:temp.setB(3.14)。这种用法其实是一种语法糖,编译器在调用成员函数时自动将当前对象的地址作为this指针传递给了函数的。
1 | (gdb) p &Basic::setB(double) |
这里参数传递了对象的地址,但是在函数里面是怎么拿到成员变量 b 的地址呢?我们在调用 setB 的地方打断点,执行到断点后,用 step 进入到函数,然后查看相应寄存器的值和汇编代码。整个过程如下图:
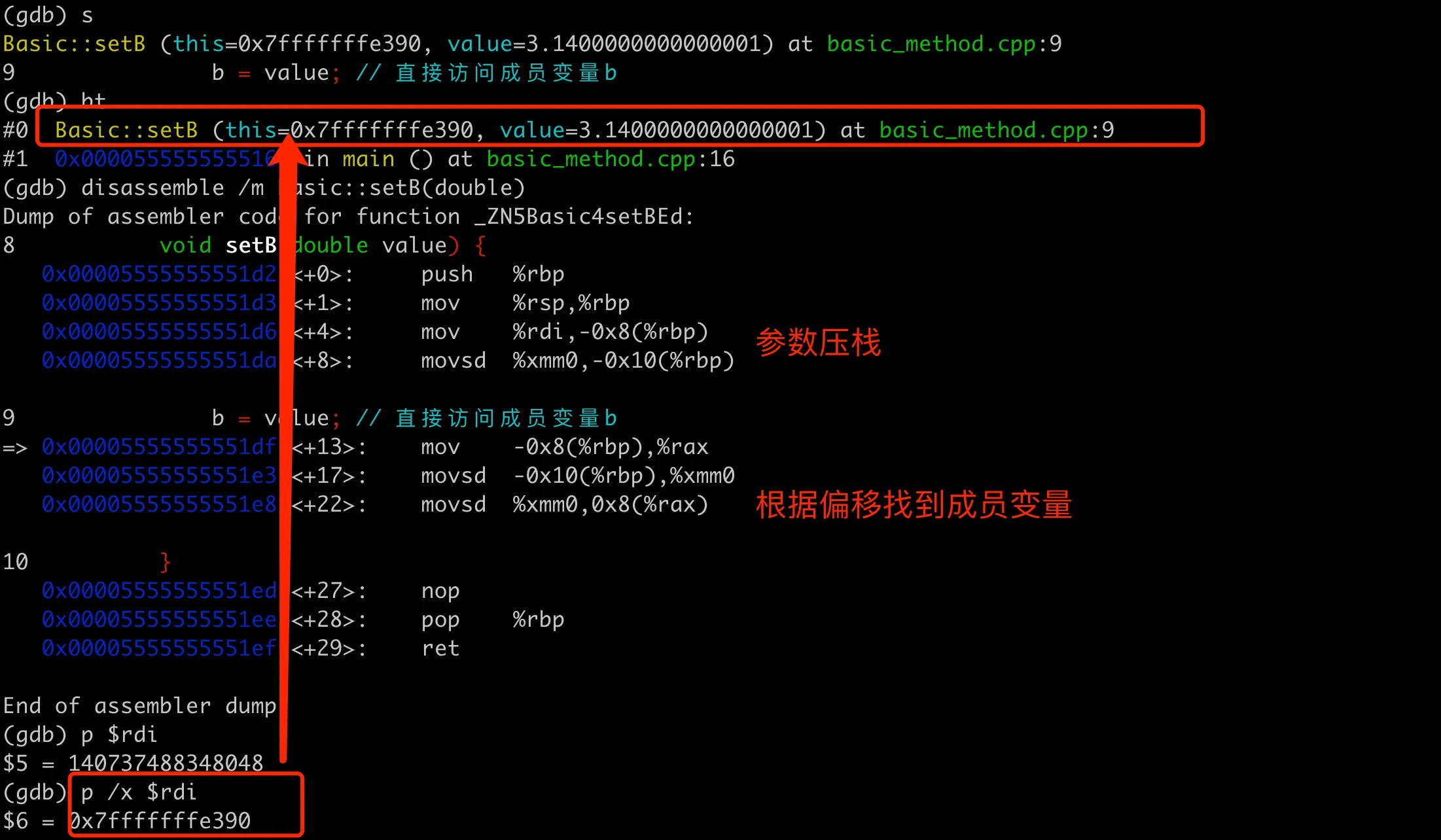
这里的汇编代码展示了如何通过 this指针和偏移量访问b。可以分为两部分,第一部分是处理 this 指针和参数,第二部分是找到成员 b 的内存位置然后进行赋值。
参数传递部分。这里mov %rdi,-0x8(%rbp)将 this 指针(通过rdi寄存器传入)保存到栈上。将 double 类型的参数value 通过xmm0寄存器传入保存到栈上。这是 x86_64 机器下 GCC 编译器的传参规定,我们可以通过打印 $rdi 保存的地址来验证确实是 temp 对象的开始地址。
对象赋值部分。mov -0x8(%rbp),%rax 将this指针从栈上加载到 rax 寄存器中。类似的,movsd -0x10(%rbp),%xmm0 将参数value从栈上重新加载到xmm0寄存器中。movsd %xmm0,0x8(%rax) 将value写入到this对象的 b 成员。这里 0x8(%rax) 表示rax(即this指针)加上8字节的偏移,这个偏移正是成员变量b在Basic对象中的位置。
这个偏移是什么时候,怎么算出来的呢?其实成员变量的地址相对于对象地址是固定的,对象的地址加上成员变量在对象内的偏移量就是成员变量的实际地址。编译器在编译时,基于类定义中成员变量的声明顺序和编译器的内存布局规则,计算每个成员变量相对于对象起始地址的偏移量。然后在运行时,通过基地址(即对象的地址)加上偏移量,就能够计算出每个成员变量的准确地址。这个过程对于程序员来说是透明的,由编译器和运行时系统自动处理。
函数调用约定与优化
上面的汇编代码中,setB 的两个参数,都是从寄存器先放到栈上,接着又从栈上放到寄存器进行操作,为什么要移来移去多此一举呢?要回答这个问题,需要先了解函数的调用约定和寄存器使用。在x86_64架构的系统调用约定中,前几个整数或指针参数通常通过寄存器(如rdi, rsi, rdx, 等)传递,而浮点参数通过 xmm0 到 xmm7 寄存器传递。这种约定目的是为了提高函数调用的效率,因为使用寄存器传递参数比使用栈更快。
而将寄存器上的参数又移动到栈上,是为了保证寄存器中的值不被覆盖。因为寄存器是有限的资源,在函数中可能会被多次用于不同的目的。将值保存到栈上可以让函数内部自由地使用寄存器,而不必担心覆盖调用者的数据。
接着又将-0x8(%rbp) 放到 rax 寄存器,然后再通过movsd %xmm0,0x8(%rax)写入成员变量b的值,为啥不直接从xmm0寄存器写到基于rbp的偏移地址呢?这是因为 x86_64 的指令集和其操作模式通常支持使用寄存器间接寻址方式访问数据。使用rax等通用寄存器作为中间步骤,是一种更通用和兼容的方法。
当然上面编译过程没有开启编译优化,所以编译器采用了直接但效率不高的代码生成策略,包括将参数和局部变量频繁地在栈与寄存器间移动。而编译器的优化策略可能会影响参数的处理方式。如果我们开启编译优化,如下:
1 | g++ basic_method.cpp -o basic_method_O2 -O2 -g -std=c++11 |
生成的 main 函数汇编部分如下:
1 | (gdb) disassemble /m main |
在 O2 优化级别下,编译器认定main函数中的所有操作(包括创建Basic对象和对其成员变量的赋值操作)对程序的最终结果没有影响,因此它们都被优化掉了。这是编译器的“死代码消除”,直接移除那些不影响程序输出的代码部分。
特殊成员内存分布
上面的成员都是 public 的,如果是 private(私有) 变量,私有方法呢?另外,静态成员变量或者静态成员方法,在内存中又是怎么布局呢?
私有成员
先来看私有成员,接着上面的例子,增加私有成员变量和方法。整体代码如下:
1 |
|
编译之后,通过 GDB,可以打印出所有成员变量的地址,发现这里私有变量的内存布局并没有什么特殊地方,也是依次顺序存储在对象中。私有的方法也没有特殊地方,一样存储在文本段。整体布局如下如:
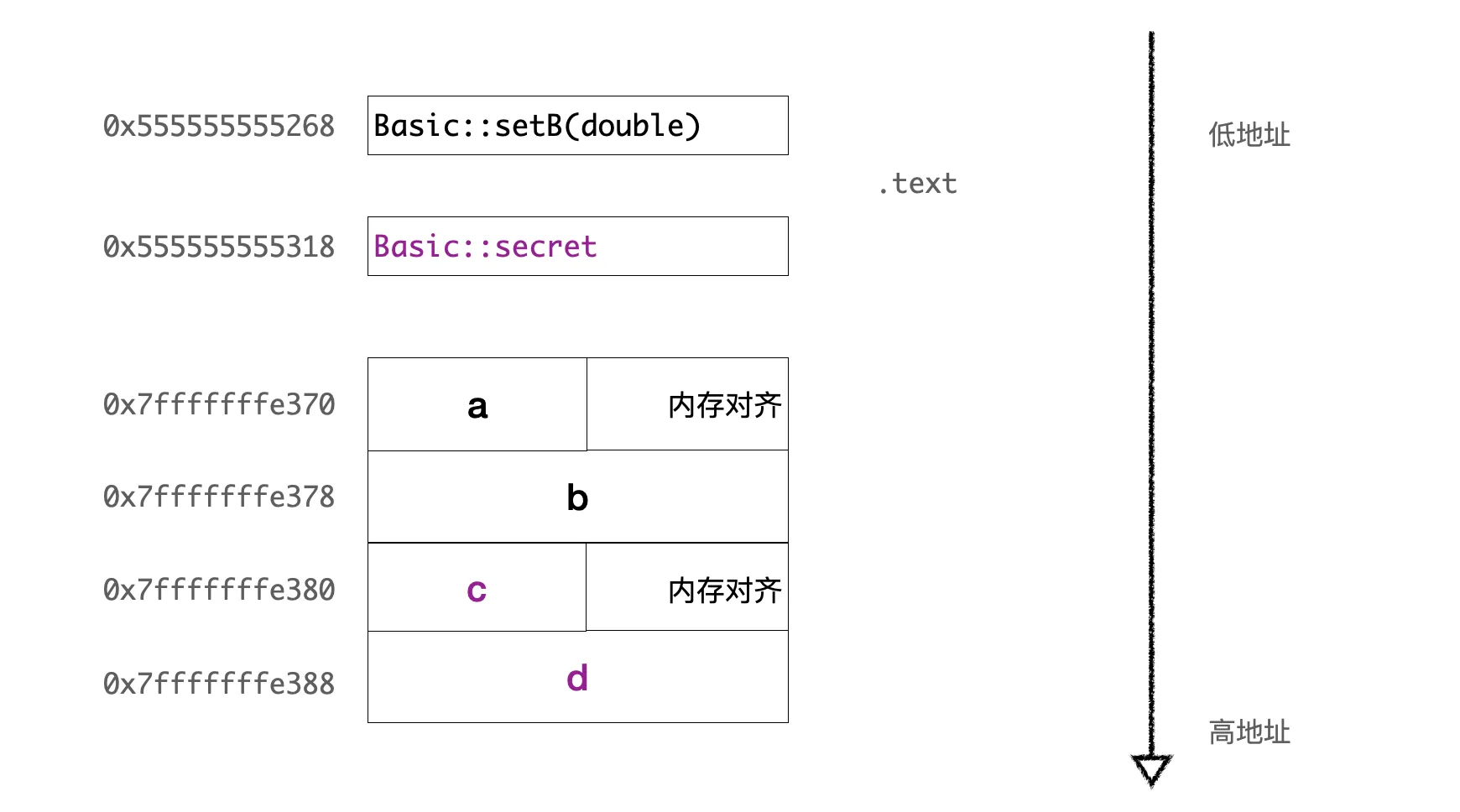
那么 private 怎么进行可见性控制的呢?首先编译期肯定是有保护的,这个很容易验证,我们无法直接访问 temp.c ,或者调用 secret 方法,因为直接会编译出错。
那么运行期是否有保护呢?我们来验证下。前面已经验证 private 成员变量也是根据偏移来找到内存位置的,我们可以在代码中直接根据偏移找到内存位置并更改里面的值。
1 | int* pC = reinterpret_cast<int*>(reinterpret_cast<char*>(&temp) + 16); |
这里修改后,可以增加一个show方法打印所有成员的值,发现这里temp.c 确实被改为了 12。可见成员变量在运行期并没有做限制,知道地址就可以绕过编译器的限制进行读写了。那么私有的方法呢?
私有方法和普通成员方法一样存储在文本段,我们拿到其地址后,可以通过这个地址调用吗?这里需要一些骚操作,我们在类定义中添加额外的接口来暴露私有成员方法的地址,然后通过成员函数指针来调用私有成员函数。整体代码如下:
1 | class Basic { |
上面代码正常运行,你可以通过 print 打印调用前后成员变量的值来验证。看来对于成员函数来说,只是编译期不让直接调用,运行期并没有保护,我们可以绕过编译限制在对象外部调用。
当然实际开发中,千万不要直接通过地址偏移来访问私有成员变量,也不要通过各种骚操作来访问私有成员方法,这样不仅破坏了类的封装性,而且是不安全的。
静态成员
每个熟悉 c++ 类静态成员的人都知道,静态成员变量在类的所有实例之间共享,不管你创建了多少个类的对象,静态成员变量只有一份数据。静态成员变量的生命周期从它们被定义的时刻开始,直到程序结束。静态成员方法不依赖于类的任何实例来执行,主要用在工厂方法、单例模式的实例获取方法、或其他与类的特定实例无关的工具函数。
下面以一个具体的例子,来看看静态成员变量和静态成员方法的内存布局以及实现特点。继续接着前面代码例子,这里省略掉其他无关代码了。
1 |
|
简单的打印 temp 和 alias 地址,发现两者之间差异挺大。temp 地址是 0x7fffffffe380,Basic::alias 是 0x555555558048,用 info target 可以看到 alias 在程序的 .data 内存空间范围 0x0000555555558038 - 0x000055555555804c 内。进一步验证了下,.data段用于存储已初始化的全局变量和静态变量,注意这里需要是非零初始值。
对于没有初始化,或者初始化为零的全局变量或者静态变量,是存储在 .bss 段内的。这个也很好验证,把上面 alias 的值设为0,重新查看内存位置,就能看到确实在 .bss 段内了。对于全局变量或者静态变量,为啥需要分为这两个段来存储,而不是合并为一个段来存储呢?
这里主要是考虑到二进制文件磁盘空间大小以及加载效率。在磁盘上,.data 占用实际的磁盘空间,因为它需要存储具体的初始值数据。.bss段不占用实际的存储空间,只需要在程序加载时由操作系统分配并清零相应的内存即可,这样可以减少可执行文件的大小。在程序启动时,操作系统可以快速地为.bss段分配内存并将其初始化为零,而无需从磁盘读取大量的零值数据,可以提高程序的加载速度。这里详细的解释也可以参考 Why is the .bss segment required?。
静态方法又是怎么实现呢?我们先输出内存地址,发现在 .text 代码段,这点和其他成员方法是一样的。不过和成员方法不同的是,第一个参数并不是 this 指针了。在实现上它与普通的全局函数类似,主要区别在于它们的作用域是限定在其所属的类中。
类继承的内存布局
当然,既然是在聊面向对象的类,那就少不了继承了。我们还是从具体例子来看看,在继承情况下,类的内存布局情况。
不带虚函数的继承
先来看看不带虚函数的继承,示例代码如下:
1 |
|
编译运行后,用 GDB 打印成员变量的内存分布,发现 Derived 类的对象在内存中的布局首先包含其基类Basic的所有成员变量,紧接着是 Derived 类自己的成员变量。整体布局如下图:

其实 C++ 标准并没有规定在继承中,基类和派生类的成员变量之间的排列顺序,编译器可以自由发挥的。但是大部分编译器在实现中,都是基类的成员变量在派生类的成员变量之前,为什么这么做呢?因为这样实现,使对象模型变得更简单和直观。不论是基类还是派生类,对象的内存布局都是连续的,简化了对象创建、复制和销毁等操作的实现。我们通过派生类对象访问基类成员与直接使用基类对象访问时完全一致,一个派生类对象的前半部分就是一个完整的基类对象。
对于成员函数(包括普通函数和静态函数),它们不占用对象实例的内存空间。不论是基类的成员函数还是派生类的成员函数,它们都存储在程序的代码段中(.text段)。
带有虚函数的继承
带有虚函数的继承,稍微有点复杂了。在前面继承例子基础上,增加一个虚函数,然后在 main 中用多态的方式调用。
1 |
|
上面代码中,Basic* ptr = &derivedObj; 这一行用一个基类指针指向派生类对象,当通过基类指针调用虚函数 ptr->printInfo();时,将在运行时解析为 Derived::printInfo() 方法,这是就是运行时多态。对于 ptr->printB(); 调用,由于派生类中没有定义 printB() 方法,所以会调用基类的 printB() 方法。
那么在有虚函数继承的情况下,对象的内存布局是什么样?虚函数的多态调用又是怎么实现的呢?实践出真知,我们可以通过 GDB 来查看对象的内存布局,在此基础上可以验证虚函数表指针,虚函数表以及多态调用的实现细节。这里先看下 Derived 类对象的内存布局,如下图:
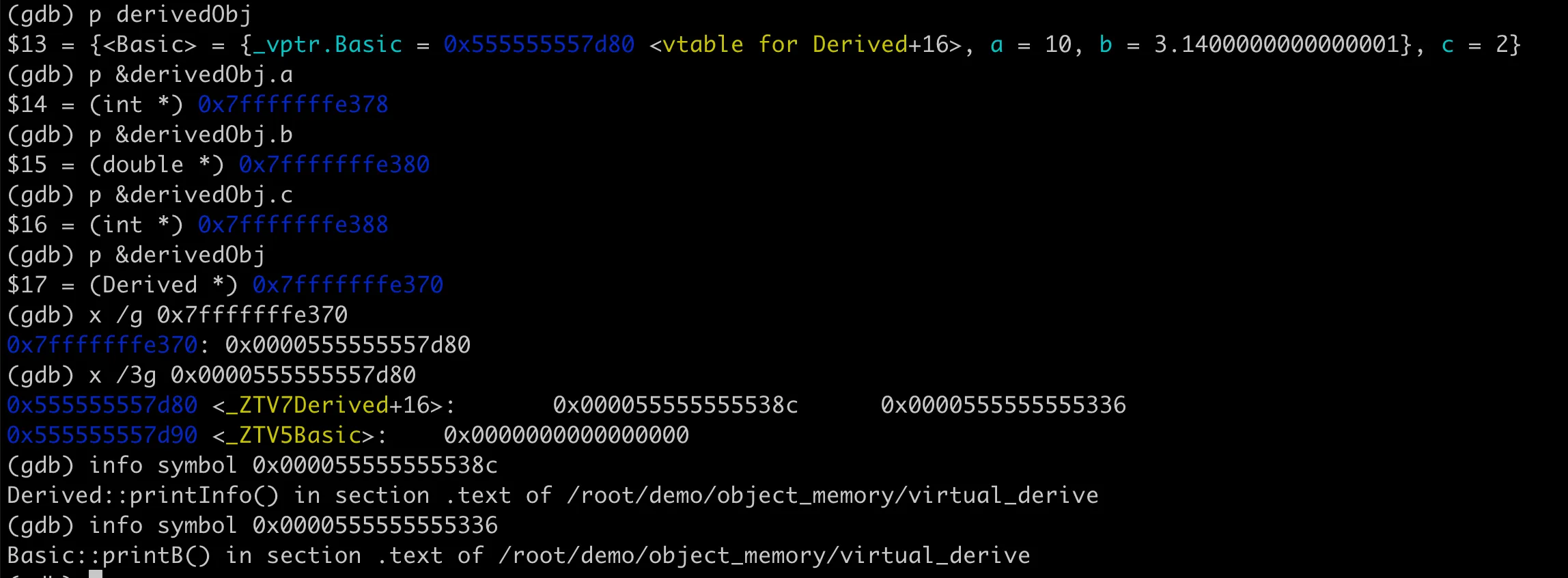
可以看到派生类对象的开始部分(地址 0x7fffffffe370 处)有一个 8 字节的虚函数表指针 vptr(指针地址 0x555555557d80),这个指针指向一个虚函数表(vtable),虚函数表中存储了虚函数的地址,一共有两个地址 0x55555555538c 和 0x555555555336,分别对应Derived 类中的两个虚函数 printInfo 和 printB。基类的情况类似,下面画一个图来描述更清晰些:
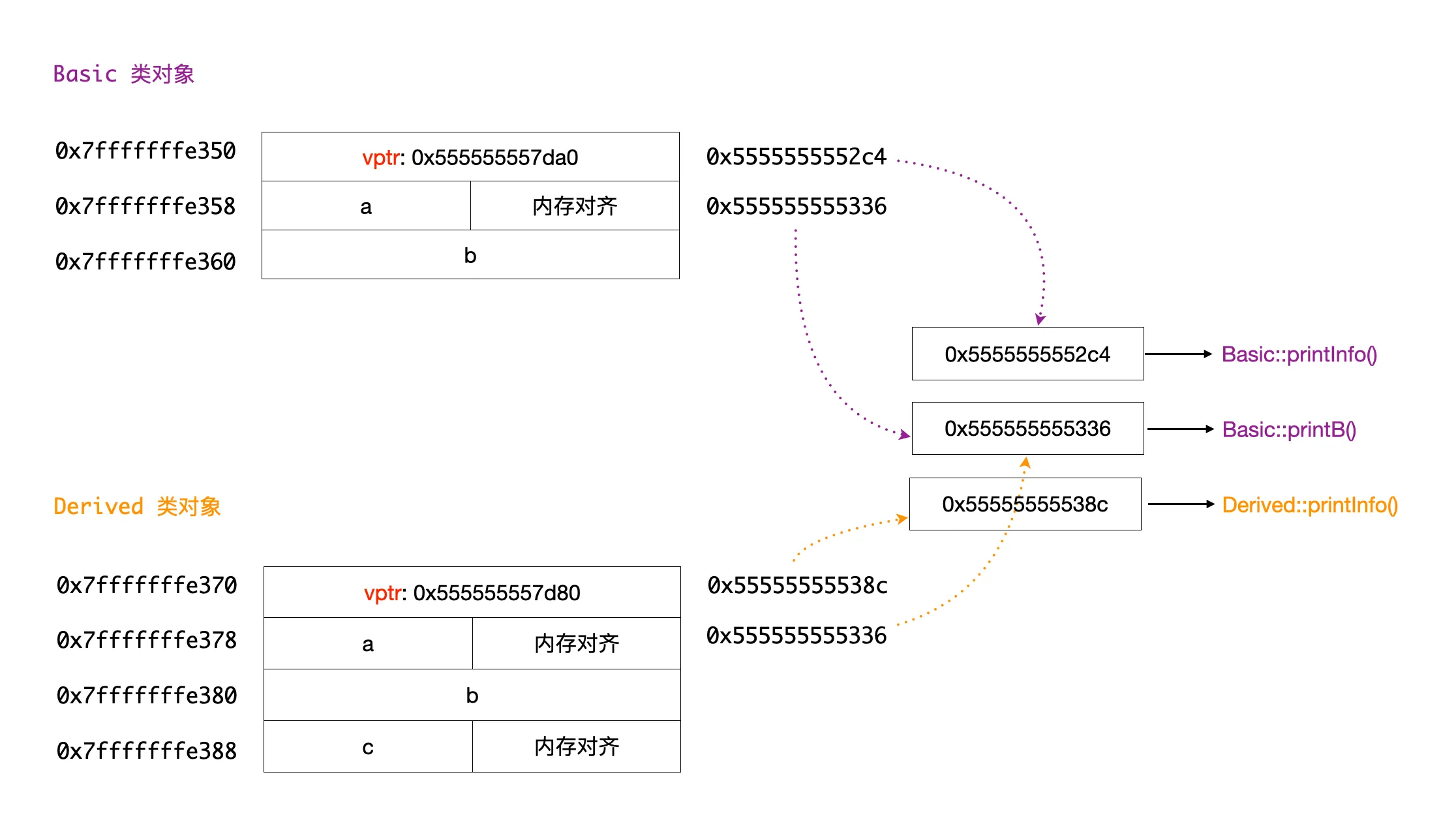
现在搞清楚了虚函数在类对象中的内存布局。在编译器实现中,虚函数表指针是每个对象实例的一部分,占用对象实例的内存空间。对于一个实例对象,通过其地址就能找到对应的虚函数表,然后通过虚函数表找到具体的虚函数地址,实现多态调用。那么为什么必须通过引用或者指针才能实现多态调用呢?看下面 3 个调用,最后一个没法多态调用。
1 | Basic& ref = derivedObj; |
我们用 GDB 来看下这三种对象的内存布局,如下图:
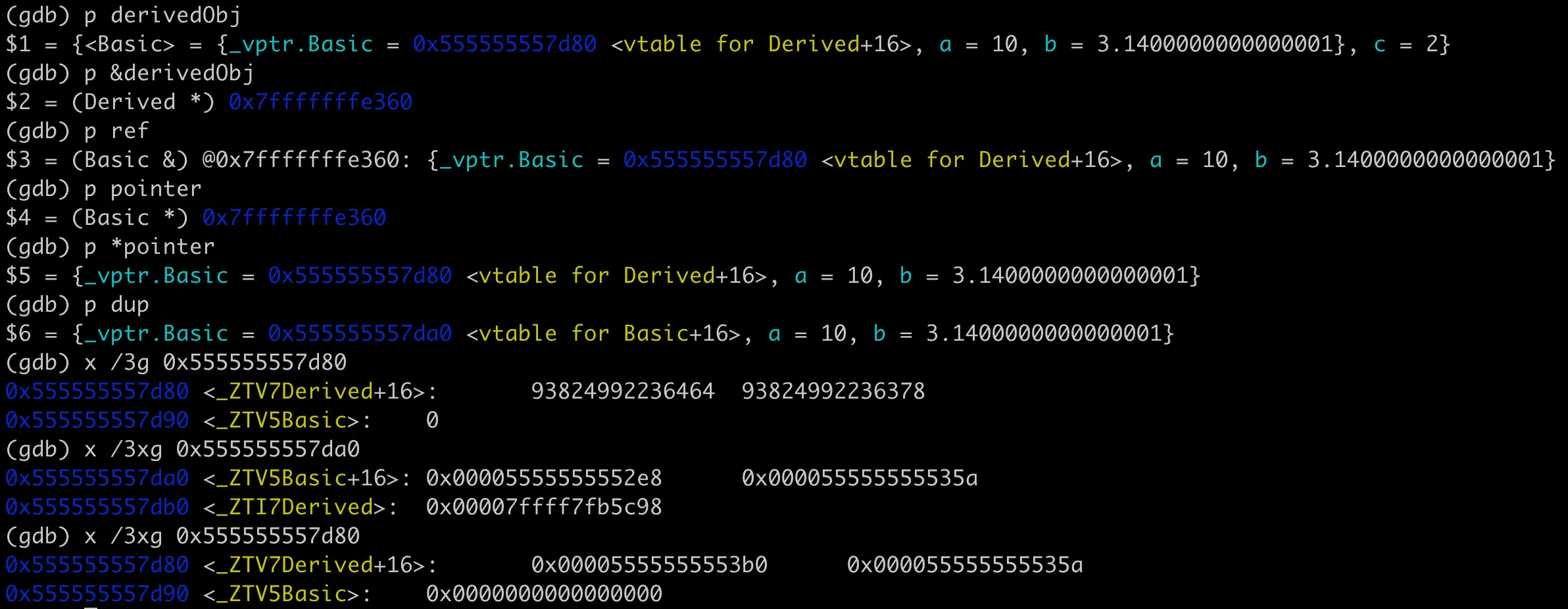
指针和引用在编译器底层没有区别,ref 和 ptr 的地址一样,就是原来派生类 derivedObj 的地址0x7fffffffe360,里面的虚函数表指针指向派生类的虚函数表,所以可以调用到派生类的 printInfo。而这里的 dup 是通过拷贝构造函数生成的,编译器执行了隐式类型转换,从派生类截断了基类部分,生成了一个基类对象。dup 中的虚函数表指针指向的是基类的虚函数表,所以调用的是基类的 printInfo。
从上面 dup 虚函数表指针的输出也可以看到,虚函数表不用每个实例一份,所有对象实例共享同一个虚函数表即可。虚函数表是每个多态类一份,由编译器在编译时创建。
当然,这里是 Mac 平台下 Clang 编译器对于多态的实现。C++ 标准本身没有规定多态的实现细节,没有说一定要有虚函数表(vtable)和虚函数表指针(vptr)来实现。这是因为C++标准关注的是行为和语义,确保我们使用多态特性时能够得到正确的行为,但它不规定底层的内存布局或具体的实现机制,这些细节通常由编译器的实现来决定。
不同编译器的实现也可能不一样,许多编译器为了访问效率,将虚函数表指针放在对象内存布局的开始位置。这样,虚函数的调用可以快速定位到虚函数表,然后找到对应的函数指针。如果类有多重继承,情况可能更复杂,某些编译器可能会采取不同的策略来安排虚函数表指针的位置,或者一个对象可能有多个虚函数表指针。
地址空间布局随机化
前面的例子中,如果用 GDB 多次运行程序,对象的虚拟内存地址每次都一样,这是为什么呢?
我们知道现代操作系统中,每个运行的程序都使用虚拟内存地址空间,通过操作系统的内存管理单元(MMU)映射到物理内存的。虚拟内存有很多优势,包括提高安全性、允许更灵活的内存管理等。为了防止缓冲区溢出攻击等安全漏洞,操作系统还会在每次程序启动时随机化进程的地址空间布局,这就是地址空间布局随机化(ASLR,Address Space Layout Randomization)。
在 Linux 操作系统上,可以通过 cat /proc/sys/kernel/randomize_va_space 查看当前系统的 ASLR 是否启用,基本上默认都是开启状态(值为 2),如果是 0,则是禁用状态。
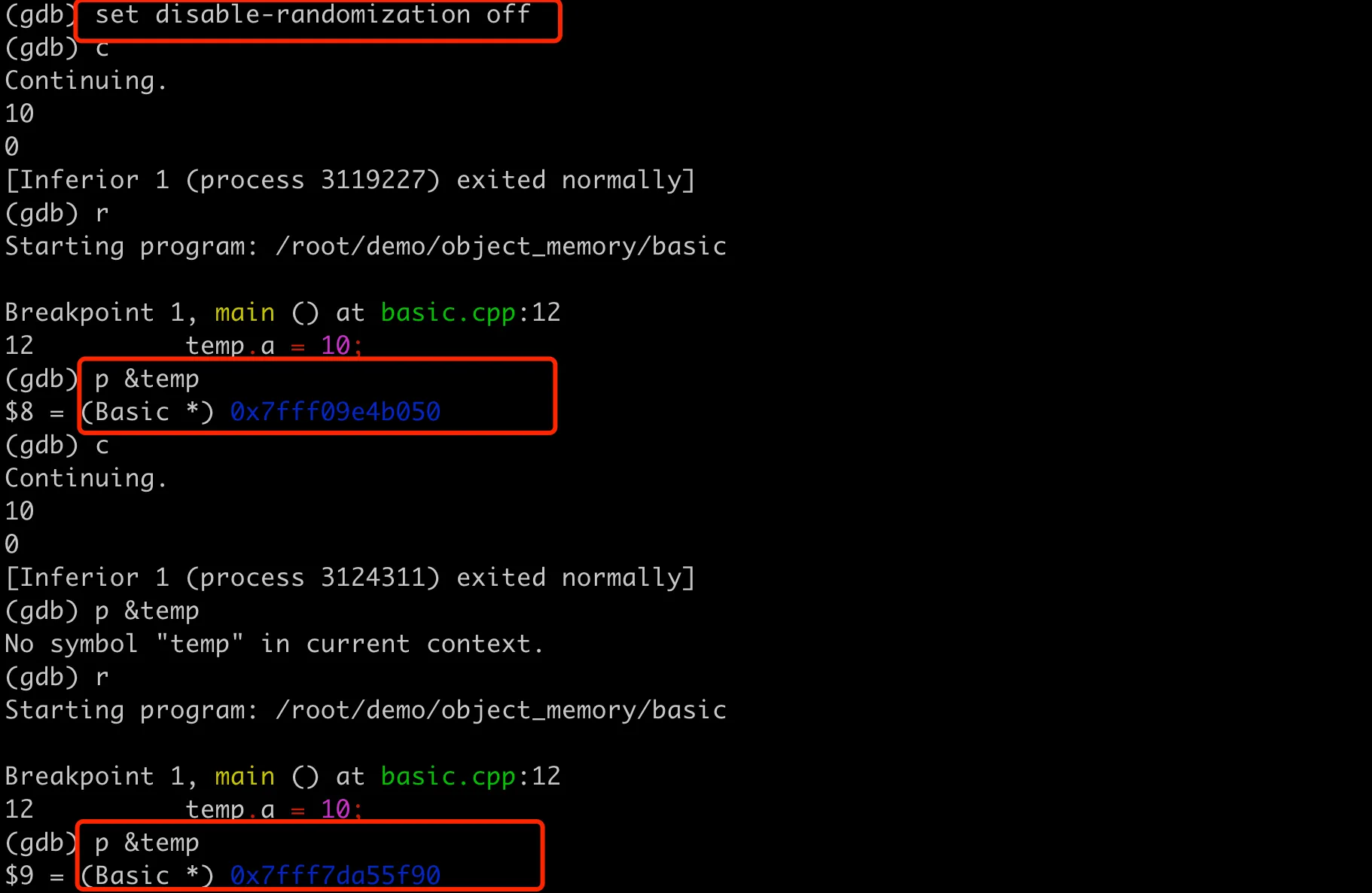
前面使用 GDB 进行调试时,之所以观察到内存地址是固定不变的,这是因为 GDB 默认禁用了ASLR,以便于调试过程中更容易重现问题。可以在使用 GDB 时启用 ASLR,从而让调试环境更贴近实际运行环境。启动 GDB 后,可以通过下面命令开启地址空间的随机化。
1 | (gdb) set disable-randomization off |
之后再多次运行,这里的地址就会变化了。
总结
C++ 的对象模型是一个复杂的话题,涉及到类的内存布局、成员变量和成员函数的访问、继承、多态等多个方面。本文从实际例子出发,帮助大家对 C++ 对象的内存布局有了一个直观的认识。
简单总结下本文的核心结论:
- 对象的内存布局是连续的,成员变量按照声明的顺序存储在对象中,编译器会根据类定义计算每个成员变量相对于对象起始地址的偏移量。
- 成员方法存储在进程的文本段,不占用对象实例的内存空间,通过 this 指针和偏移量访问成员变量。
- 私有成员变量和方法在运行期并没有保护,可以通过地址偏移绕过编译器的限制进行读写,但是不推荐这样做。
- 静态成员变量和静态成员方法存储在程序的数据段和代码段,不占用对象实例的内存空间。
- 继承类的内存布局,编译器一般会把基类的成员变量放在派生类的成员变量之前,使对象模型变得更简单和直观。
- 带有虚函数的继承,对象的内存布局中包含虚函数表指针,多态调用通过虚函数表实现。虚函数实现比较复杂,这里只考虑简单的单继承。
- 地址空间布局随机化(ASLR)是现代操作系统的安全特性,可以有效防止缓冲区溢出攻击等安全漏洞。GDB 默认禁用 ASLR,可以通过
set disable-randomization off命令开启地址空间的随机化。
当然本文也只是一个入门级的介绍,更深入的内容可以参考《深度探索 C++对象模型:Inside the C++ Object Model》这本书。

